Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model (KDD 2008)
Paper Review
목록 보기
13/51

MF + Neighboorhood model
bias와 여러 기법을 곁들인..
Abstract
- 개인화된 추천을 제공해주는 Recommender System은 때때로 CF(Collaborative Filtering 에 의존)
- 이 CF는 user와 item을 profile하는 latent factor model과 user item의 similarities를 분석하는 neighborhood model로 나뉨
- 본 논문에서는 두 가지 접근을 결합하여 더 정확한 모델을 만들고자 함
- 더 나아가 Implicit Feedback Data까지 활용하여 성능을 높이고자 함
- 본 모델의 실험은 Netflix 데이터를 통해 실험되었으며, top-K Recommendation task를 위한 새로운 평가지표 또한 제시
Introduction
- CF는 domain knowledge를 필요로 하지 않고, side information을 필요로 하지 않는 다는 점에서 자주 사용됨
- 이 CF는 Neighboorhood Method, Latent Factor model로 나뉨
- Neighboorhood method는 아이템 사이의 관계, 유저 사이의 관계를 계산
- Latent Factor model(SVD와 같은) item과 user를 동일한 latent factor space에 mapping하여 비교 가능케 함
- 이 latent factor space는 별점을 유저와 아이템의 특성에 따라 설명하도록 함
- Netflix 대회의 교훈은 어떤 두 모델중 최적은 없다 임
- Neighboorhood 모델은 국소적인 관계를 포착하는데 매우 효과적임
- 왜냐면 중요한 이웃 관계만 학습하여 방대한 유저의 별점을 무시할 수 있기 때문
- 다만 역설적으로 이로 인해 작은 신호는 포착하지 못함
- Latent Factor Model은 전체적인 Item, User 구조를 포착하는데 능함
- 다만 적은 Set의 강한 관계는 포착하지 못한다는 단점이 존재
- Neighboorhood 모델은 국소적인 관계를 포착하는데 매우 효과적임
- 우리는 이 두 모델을 합하여, 장점을 극대화 하고 단점을 보완할 것 (최초의 시도)
- 기존에도 결합한 경우가 있었지만, 결과를 결합한 것 이지 학습 단에서 결합한 적은 없었음
- Netflix 대회에서 다른 교훈은 User의 다른 정보를 결합하는 것이 중요하다는 것
- 상대적으로 수집하기 용이한 Implicit Feedback (구매 이력, 마우스 움직임 등)을 사용하면 모델의 성능을 향상시킬 수 있음
- 따라서 우리의 모델은 이를 이용할 것
- 따라서 본 논문은 다음과 같은 흐름으로 진행될 것
* Section 2에서는 기존 모델 소개- Section 3에서는 더 정교한 Neighboorhood 모델 소개 (Latent Factor 모델과 결합 가능한 형태)
- Section 4에서는 SVD-based latent Factor 모델에 실용적인 기법을 적용함
- Section 5에서는 두 모델을 하나의 framework로 결합
- Section 6에서 실험
PRELIMINARIES
- 기호 설명
Baseline estimates
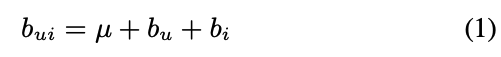
- 이전 논문에서 서술하였던 global bias, user bias, item bias 추가
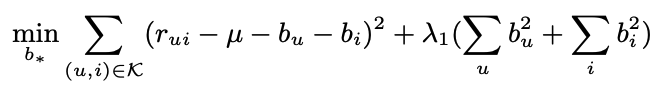
- 이전 논문의 수식과 동일
Neighborhood models
- 기존 Neighborhood model은 user-based 였음
- 그러나 최근에는 Item-based model이 인기
- 한 유저가 평가한 비슷한 아이템들을 기반으로
- 더 좋은 확장성과 설명 가능성, 성능 향상이 있음
- 유저가 비슷하게 평가한 아이템들은 명확하게 기억에 남지만, 비슷한 유저들은 명백하게 설명할 수 없음
* 따라서 우리는 item-based로 model을 설계할 것이지만, user와 item을 전환하면 동일하게 user-based로 model을 설계할 수 있을 것
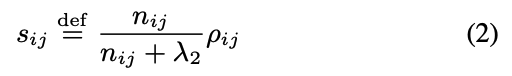
- 피어슨 상관계수를 기반으로 아이템의 유사도를 평가할 것인데, 더 많은 유저가 평가할수록 유사도가 높다고 판단하여 다음과 같은 식을 도출
- nij는 i와 j를 동시에 평가한 유저의 수, hyperparam lambda2는 100
- 우리의 goal은 rui를 찾는 것
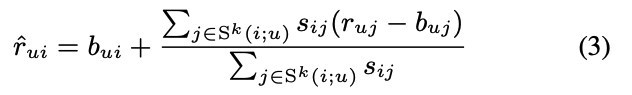
- 기존 식은 i와 유사하며 user가 평가한 k개의 아이템 집합 S^k를 통해 실제 값에서 편향을 뺀 값에 유사도만큼 가중합
- 매우 직관적이고 쉬운 만큼 인기있는 방법론
- 다만 두 여러 비관적인 관점이 제시
- 유사도 척도가 전체 관계가 아닌 두 아이템 사이의 관계에 한정 됨
- 유저의 평가 항목이 적을 경우 (유저가 유사 아이템을 평가하지 않은 경우)에도 이웃에 의존하게 만듬 (베이스라인에 의존하는게 합리적일 것)
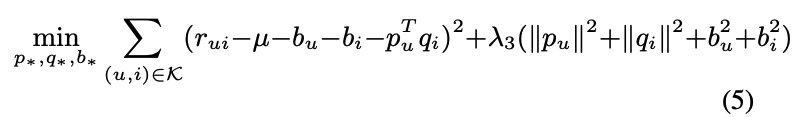
- 따라서 새로운 interpolation weight로 theta ij를 제안
Latent factor models
- 거시적 관점에서 데이터를 잘 설명
- SVD는 물론 높은 확장 가능성을 가지지만, missing value가 많으면 잘 작동하지 않음 (overfitting 등)
- 결측치 보간은 매우 높은 비용을 요구되고, 데이터 왜곡될 가능성 존재
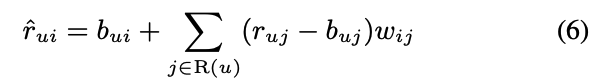
- 따라서 다음과 같이 Gradient descent를 이용한 모델이 구현 됨
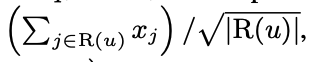
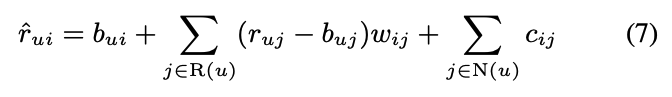
- Paterek은 user feature를 없애고, item vector 구성을 qi, xi로 만듬
- 여기서 user feature를 상호작용한 아이템의 x vector의 합으로 이용하였고 우리도 이 방법론을 추후에 응용할 예정
The Netflix data
- 약 100 million movie rationg에 달하는 netflix data를 이용할 것
- 1.4million의 validation data도 이용할 것
- 이 데이터들은 실무에 가까운 데이터 (old rating을 바탕으로 새로운 것을 예측, heavy rater 뿐만이 아닌 rater 들도 잘 예측해야 함)
- 기존 netflix system인 Cinematch는 0.9514의 rmse를 기록했으며, 10% 향상을 이룬 우승자의 rmse는 0.8563
Implicit feedback
- 앞서 말했듯, Implicit feedback을 이용할 것인데 netflix data로 따지면 rental 이력 등이 있겠으나 아쉽게도 제공되지 않음
- 우리는 유저가 점수를 매겼으면 1, 아니면 0으로 Implicit 하게 feedback을 정의할 수 있음
- 엄밀히 말하면 Explicit data에 존재하는 정보이지만, 이를 추가했을 때 성능이 향상 됨
- R(u)는 유저 u의 rating, N(u)는 유저 u의 Implicit으로 정의
A NEIGHBORHOOD MODEL
- 새로운 이웃 기반 모델 소개
- 더 향상된 성능 (Implicit data를 포함하고 다양한 요소를 포함함으로써)
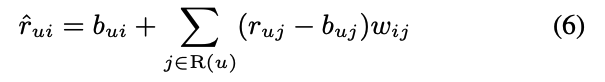
- User Specific한 유사도인 sij를 버리고, wij라는 learnable param을 도입
- 또한 user u가 평가한 모든 아이템을 예측에 사용
- 이 weight는 interpolation coefficient가 아닌, baseline estimat의 offset
- gloal offset역할을 하며 결측치에 대한 영향력을 강조할 수 있기에
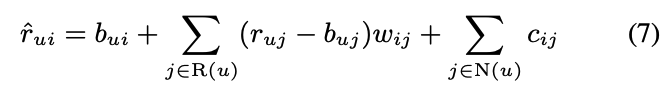
- 여기에 offset 역할의 implicit feedback을 추가하여 최종 모델을 완성 (cij 또한 parameter)
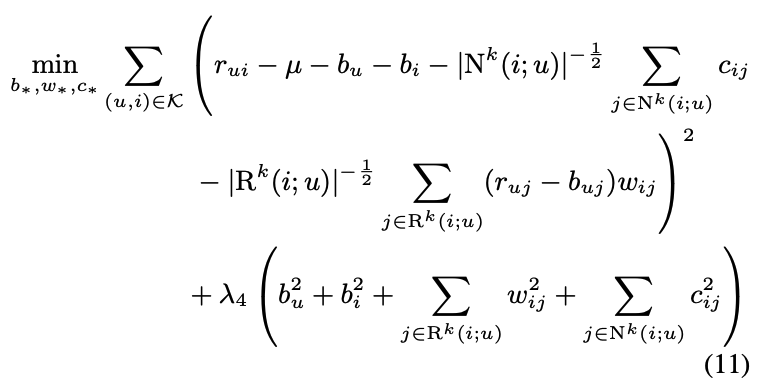
- Implicit term과 Explicit term 모두 상호작용한 아이템이 많아지면 예측값이 커지는걸 대비해, ^-1/2승을 통해 크기를 줄여줌
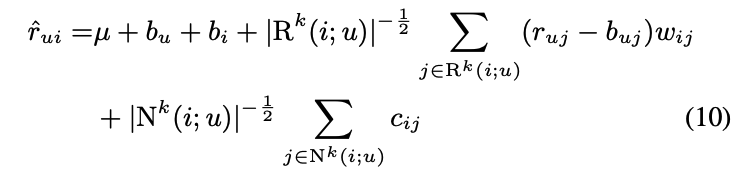
- 또한 model의 계산복잡도를 줄이기 위해 아이템 i와 유사하고, user u가 평가한 set만 예측에 사용
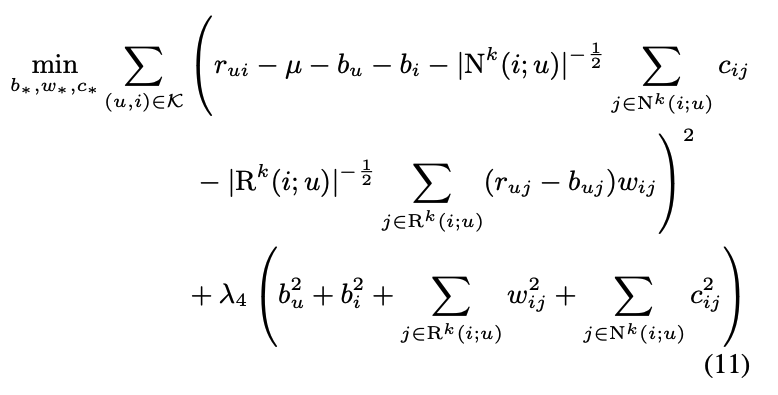
- 최종적으로 다음 식을 최적화 함으로써 이전 neighborhood 모델이 달성하지 못한 global optimization procedure를 가능케 함
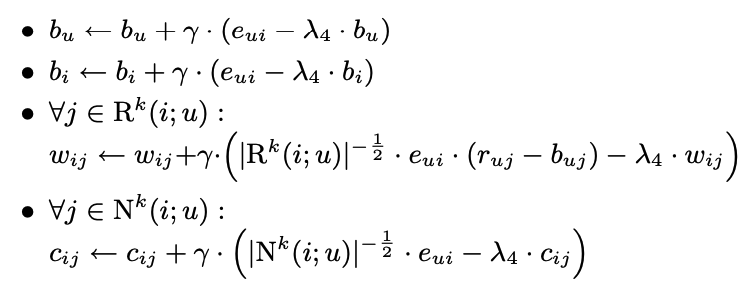
- Prediction Error가 rui - rui_hat = eui 일 때 다음과 같이 gradient descent로 update할 수 있음 (Least Square로 solve할 수 있으나 시간이 오래 걸림)
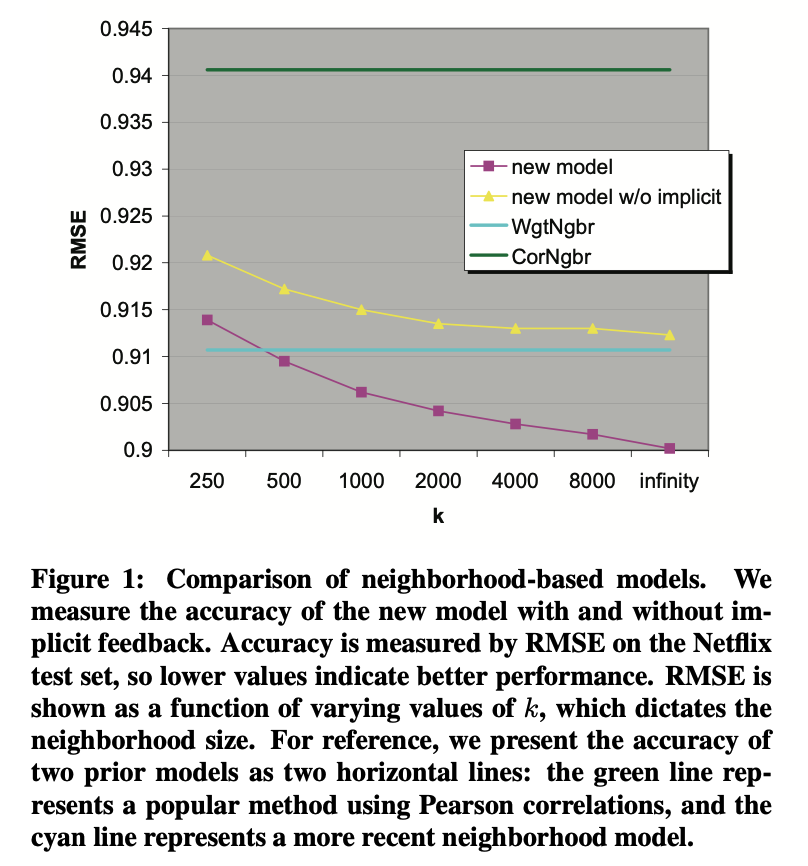
- 성능은 본 모델이 제일 우수하며, running time은 k에 비례하여 다음과 같이 증가
LATENT FACTOR MODELS REVISITIED
- 우리는 SVD 모델을 Implicit data를 추가함으로써 발전시킬 것
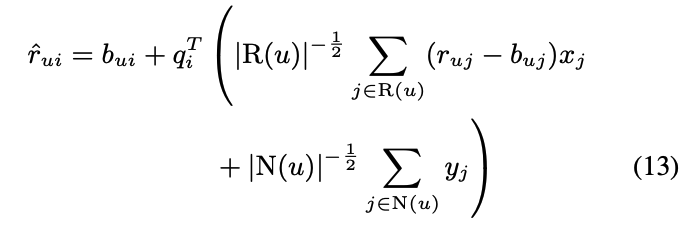
- 이 식은 기존의 user factor pu가 상단의 수식으로 변화 한 것
- qi, xi, yi는 item과 관련된 factor vector 이며 모두 동일한 f 차원을 가짐
- 이 모델은 Asymmetric-SVD로 명명
- 더 적은 파라미터
- 보통 item보다 user가 많은 경우가 대부분이기에, user와 item의 parameter를 교환한다면 복잡성 차원에서 이점일 경우가 대부분
- 새로운 유저
- Asymmetric-SVD는 user를 parameterize 하지 않기에, 새로운 유저에 대해 handling이 손쉬움 (또한 비슷하게 online update가 가능) (이는 Item-Based Neighborhood model에서 동일한 장점)
- 설명력
- 기존 SVD 모델의 단점은 낮은 설명력, 본 Asymmetric-SVD는 기존 유저의 이력을 가지고 추천해주기에 어떤 유저의 이력이 본 추천에 큰 영향을 미쳤는지 확인할 수 있음 (이 또한 Item-Based Neighborhood model에서 동일함)
- Implicit feedback의 효과적인 통합
- Implicit Feedback을 통합하였고, Explicit Feedback과의 중요도 차이는 xj, yj를 통해 학습될 것
- 더 적은 파라미터
- 다만 Asymmetric-SVD는 상기된 장점을 얻는 대신, prediction accuracy를 일부 포기함 (SVD보다 조금 좋은 성능)
- Better Quality의 Implicit Feedback을 통해 장점과 성능 모두 챙길 수 있을 것
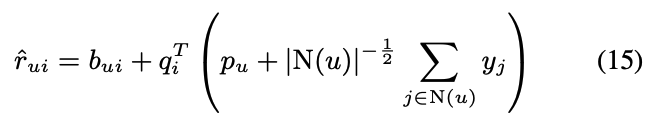
- 상기된 것과 같이, pu를 다시 도입하고 Implicit Feedback을 추가했을 경우 accuracy는 가장 높았음
- 이 모델은 'SVD++'로 명명
AN INTERGRATED MODEL
- Introduction에서 말했든, neighborhood model과 latent factor model은 상호 보완
- 우리는 수식 (10) (new neighborhood model)과 수식 (15) (SVD++)를 합칠 것
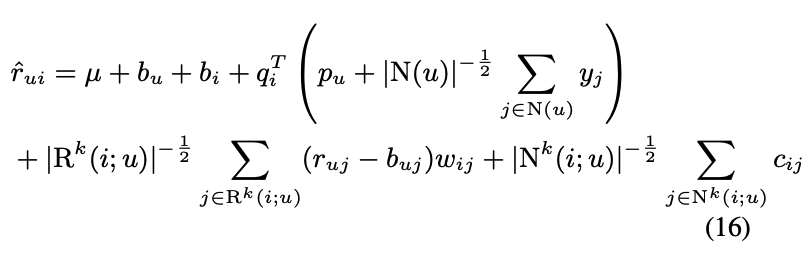
- 이 모델은 3-tier model
- 첫째로 mu+bu+bi
- item, user, global의 general propertie를 의미
- 둘째로, Factorization tier
- user profile과 item profile의 interaction을 의미
- 셋째로, Neighborhood tier
- profile 하기 힘든, 국소적 정보를 의미
- 첫째로 mu+bu+bi
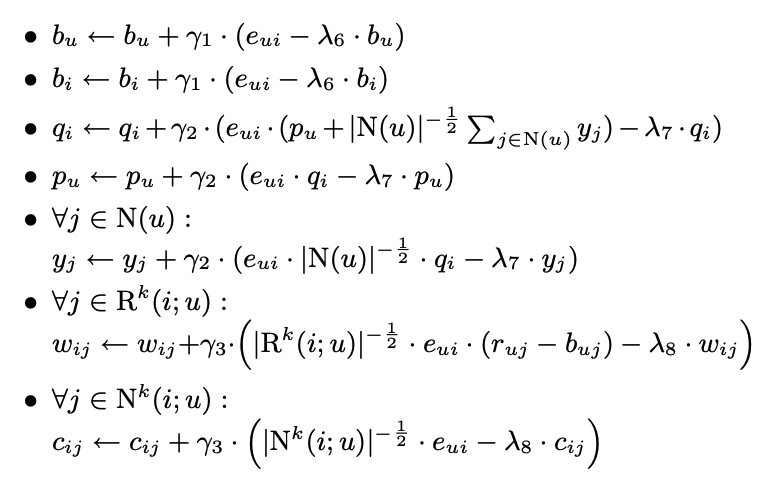
- error term을 다음과 같이 update
- 다만 여기서는 neighborhood size k를 상승시키는 것에 성능 차이는 존재하지 않음 (latent factor가 충분히 포착 )
- 기존 모델에 비해 RMSE 대폭 향상
- Asymmetric-SVD의 장점을 채용하고 싶다면 Factorization tier의 수식을 변경하면 됨
