LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning (NeurIPS 2024)
Paper Review
목록 보기
50/51

Introduction
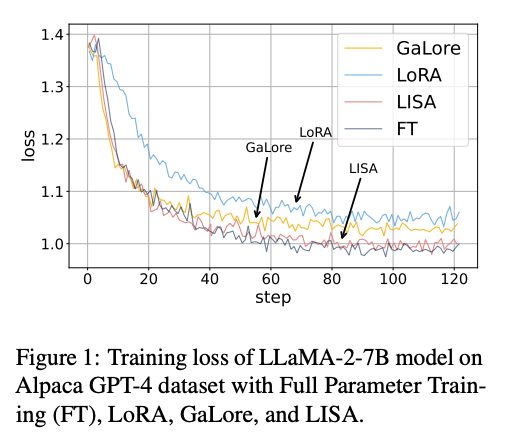
- LLM의 학습 코스트 때문에, LoRA와 같은 Parameter efficient finetuning (PEFT) 방법론이 대두
- 현 시점에서 LoRA가 대표적이지만, 여전히 full parameter setting을 따라 잡을 수는 없음
- 저자들은 LoRA의 layerwise weight norm이 차이나는 것을 발견하여, 이를 통해 새로운 peft 전략을 제안하고자 함
- Key Idea는 layer의 중요도에 따라 학습할 layer를 샘플링하고 나머지는 freeze하는 것
- 이를 Layerwise Importance Sampled Adam (LISA) algorithm이라고 명명
- 다양한 setting에서 기존 방법론을 outperform하고 full parameter setting과 대등함을 보여줌
Method
Motivation
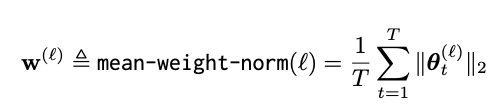
- Alpaca dataset을 통해 layerwise mean weight norm을 관찰
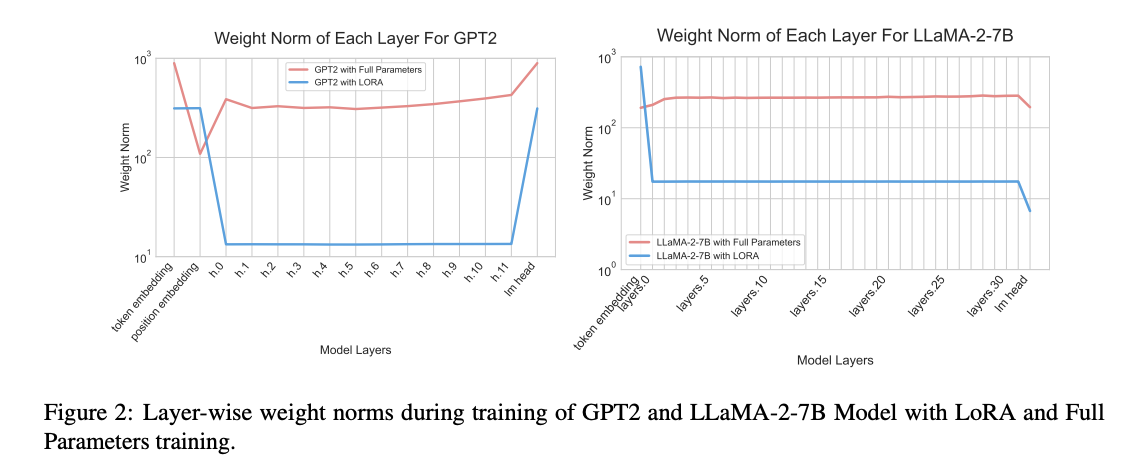
- LoRA와 Full parameter training이 다른 것을 보임
- LoRA는 비슷한 의미의 토큰을 embedding space에서 비슷한 위치로 투사
- LoRA는 비슷한 토큰을 그룹화하며 promptly identify하고, optimize함
- 다양한 해석이 가능하겠지만, LoRA의 layerwise value가 full parameter tuning과 다르다는 것은 확실
Layerwise Importance Sampled AdamW (LISA)
- 이 발견을 활용하기 위해, 우리는 LoRA의 updating pattern을 freeze할 layer를 샘플링 하는 것으로 활용하고자 함
- 이를 통해 LoRA의 본질적인 결핍인 limited row-rank representation을 해소하고, 빠른 학습 시간을 확보할 수 있음
- 직관적으로 global learning rate가 존재할 때 small weight norm을 가진 LoRA layer를 full parameter setting에서 작은 sampling prob로 샘플링해 학습해준다면 동일한 효과를 가질 것
- 이는 importance sampling의 key idea
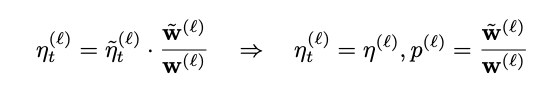

- LoRA 실험 시 중요한 layer 였던 Embedding layer와 lmhead는 항상 sampling ratio를 1로 설정
Discussions
Memorization and Reasoning
- LISA는 글쓰기, Image depict와 같은 memorization 기반 task에서 LoRA보다 높은 격차로 좋은 성능을 보임
- Code, Math와 같은 reasoning 기반 작업에서는 성능 격차가 훨씬 줄어듬
- 이는 LoRA가 Depth에 중점을 두고 layer의 representation을 제한하기에 꽤나 합리적인 결과
- Memorization에서는 width가 중요하고, reasoning에서는 depth가 중요하다는 것을 시사할 수 있음
- 이는 선행 연구의 직관을 반영하는 현상
- 이 두 방법론을 결합하여 더 나은 PEFT 방법론을 도출할 가능성이 존재하다는 것
