
INTRODUCTION
- Transformer 기반 언어모델은 AI 및 사회 전반적으로 큰 영향
- Scaling Law가 큰 역할
- MoE (Mixture of Experts)는 광범위하게 탐구됨
- 특히 Sparse-gated MoE가 Transformer 기반 LLM과 통합되며 활력을 불어넣음
- 간단하면서도 강력한 아이디어
- 모델의 각 component (전문가)가 데이터의 서로 다른 작업이나 측면에 특화되는 것
- 주어진 입력에 대해 관련 있는 전문가만 활성화가 되어, computational cost를 줄이고 방대한 지식을 활용할 수 있음
- 이는 efficient하게 scaling law를 준수하는데 기여함
- 우리는 MoE를 Algorithm, System, Application으로 나누어 포괄적인 survey를 제공하고자 함
Algorithm
- 트랜스포머 기반 LLM에서 FFN을 MoE로 대체하는 것을 집중적으로 탐구
- MoE는 여러개의 FFN을 통합하여, gating을 통해 선택된 일부 전문가만을 활성화 함
- 우리는 추가적인 MoE 관련 설계를 설명
- Token or Expert merging과 같은 soft MoE
- PEFT와 같은 MoPEs
- Dense와 Sparse 모델의 전환을 통한 학습 및 추론
- 다양한 파생 모델 등
System
- LLM 서비스 품질 개선을 위한 시스템 설계
- 계산, 통신, 저장소 개선 등
Application
- NLP, CV, RecSys, Multimodal 등에서의 응용 사례
BACKGROUND OF MIXTURE OF EXPERTS
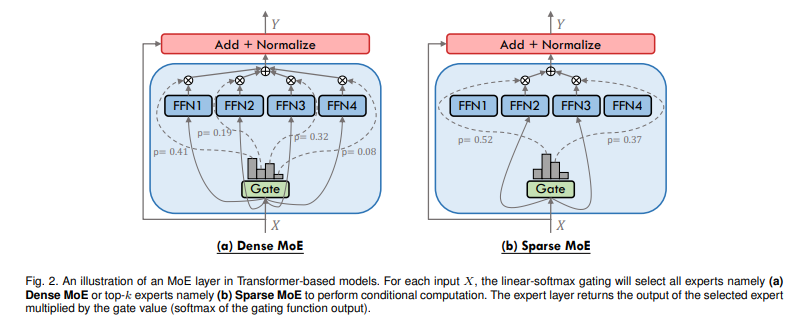
- MoE layer는 N개의 expert network와 gating network로 구성
- gating network는 softmax가 포함된 linear network로 Input을 expert로 분배하는 역할
- MoE layer는 FFN을 선택하도록 배치되며, self attention 다음에 위치하게 됨
- 이 배치는 계산 부담을 줄이기 위함으로, 중요함
- Expert network는 linear-relu-linear network
- Gating network는 linear-softmax network
- Gating network의 설계에 따라 Dense, Sparse로 나뉨
Dense MoE
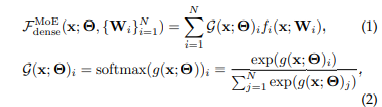
- 수식과 같이 모든 expert가 output에 기여
Sparse MoE
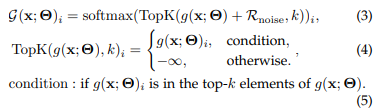
- Dense MoE의 경우 일반적으로 더 좋은 성능을 보이나, computational cost가 큼
- Sparse MoE의 경우 topK개의 Expert만 사용
- 이의 경우, 사용되는 expert가 고정되는 issue가 존재 (load balancing issue)
- 다음과 같은 loss를 추가하여 해결
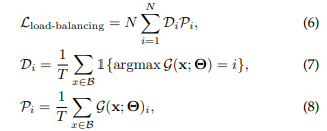
- 이 섹션 이후로 설명할 MoE는 Sparse MoE를 의미
TAXONOMY OF MIXTURE OF EXPERTS
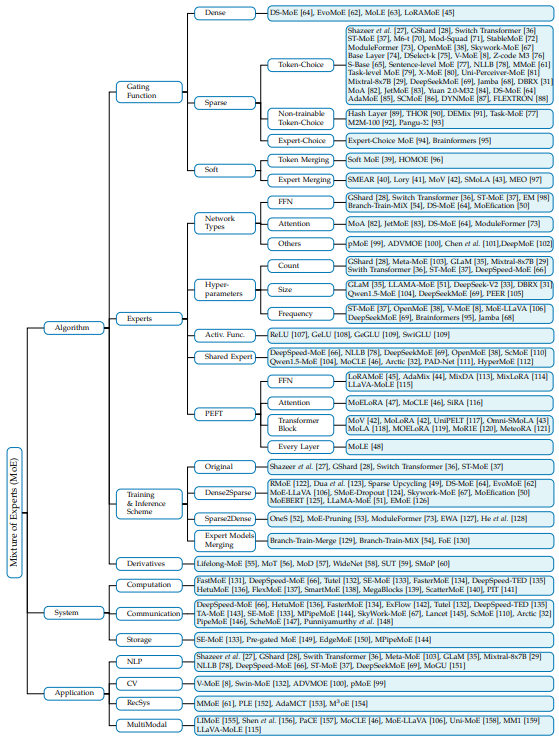
- MoE의 경우 expert를 동적으로 계산하는 (conditional computation)을 통해 계산 자원을 줄이며 parameter를 확장할 수 있음
- Mixtral 8x7b, DeepSeekMoE, Qwen1.5-MoE 등이 이를 통해 수혜 받음
- 이를 효율적으로 분류할 taxonomy를 figure와 같이 선정
ALGORITHM DESIGN OF MIXTURE OF EXPERTS
Gating Function
- 게이팅 함수는 MoE의 핵심! expert를 활성화 및 output 조율
- 3가지 유형에 따라 분류
- Sparse: 일부 expert 활성화
- Dense: 모든 expert 활성화
- Soft: Token merging, expert merging이 모두 미분 가능
Sparse

- Binary 혹은 sparse한 expert activate
- Top-K expertising을 통해 MoE의 효율성을 증가
- Pioneer한 연구는 각 expert의 기여를 가중합
- Switch Transformer에서는 K=1인 gating이 효과적임을 증명
Token-Chocie Gating
- 상위 k-expert gating
- Hierarachical MoE (계층적 MoE)
Auxiliary Loss for Token-Choice Gating
- 토큰 분배와 학습 안정성을 개선하기 위한 보조 손실
Expert Capacity for Token-Choice Gating
- Expert의 token 수에 상한선을 설정한다면, 적합한 expert에 처리되지 못하는 token인 token overflow 발생
- 랜덤 라우팅, BPR, Token drop 등 방법론을 통해 해결
- OpenMoE - MoE의 Routing 동작에서 나타나는 문제점을 탐구
- Drop-towards-the-End: 시퀀스 후반부의 토큰이 expert 용량 한계로 Drop되는 현상
- Instruction-Tuning 시 더 자주 발생
- Context-Independent Specialization: Token의 의미적 유사성에 기반해 라우팅 경향을 보임
- Early Routing Learning: 사전 학습 초기에 Routing pattern이 고정되는 현상
- Drop-towards-the-End: 시퀀스 후반부의 토큰이 expert 용량 한계로 Drop되는 현상
Other Advancements on Token-Choice Gating
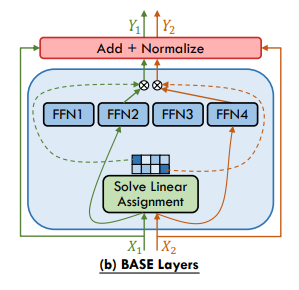
- Token Choice Gating에서 여전히 발생하는 부하 불균형 문제를 해결
- BASE는 Token-Expert 할당을 Linear Assingment Problem으로 재구성
- 각 전문가가 동일한 수의 토큰을 할당하도록 제약
- S-BASE는 optimal transport로 재구성
- Smooth Gating 및 Gradient Issue
- DSelect-K는 top-k 알고리즘을 smoothing
- Gradient descent 기반 학습의 수렴 및 통계적 성능 완화
- Sentence-Level Gating
- Sequence 내부의 token 평균값을 기반으로 representation을 생성해 이를 routing
- Representation Collapse
- Hidden Representation이 특정 expert기준으로 수렴하는 문제를 해결하기 위해 Representation을 저차원으로 투영하고, L2로 해결
