모델 앙상블의 대표적인 3가지 방법과 각 하위개념들에 대해 포괄적으로 설명합니다.
모델 앙상블 이란
모델 앙상블 이란 다양한 머신러닝 문제의 정확도를 향상시킬 수 있는 매우 효과적인 기법입니다. Ensemble (앙상블)기법이란 여러 개의 분류기를 생성하고 그 예측을 결합합으로써 보다 정확한 예측을 도출하는 기법을 말합니다. 이는 강력한 하나의 모델을 사용하는 대신, 보다 약한 모델 여러 개를 조합하여 더 정확한 예측에 도움을 주는 방식입니다. 앙상블 기법은 일반적으로 Bagging, Boosting,Stacking 이 3가지 유형으로 나눌 수 있습니다.
그 외에도 Voting(Complement of Bagging), Blending(subtype of Stacking)등이 있습니다. 두 방법은 기존 방법의 하위 방법이지만 앙상블 학습에 많이 활용되므로 위 3가지 방법을 설명하면서 각 하위 방법을 설명하겠습니다. 이후 앙상블의 장점과 단점을 간단히 설명하겠습니다.
모델 앙상블 1 – Bagging(배깅)
모델 앙상블 을 위해 대표적인 방법으로는 Bagging(배깅)이 있습니다. Bagging은 Boostrap Aggregating의 약자입니다. 이름에서 알 수 있다시피 부트스트랩을 이용합니다. 부트스트랩은 주어진 데이터셋에서 무작위 샘플링을 통해 새로운 데이터셋을 생성하는 것을 의미합니다. 부트스트랩으로 생성된 여러 데이터셋을 이용해 weak learner를 훈련시키고, 그 결과를 Voting하여 최종 예측을 만듭니다.
여기서 voting이란?
“단순한 투표방식”이라고 접근하면 쉽습니다. voting(보팅)이라는 표현에서 알 수 있듯이, 서로 다른 알고리즘을 가진 분류기 중 투표를 통해 최종 예측 결과를 결정하는 방식입니다. 알고리즘에는 흔희 알고 있는 결정 트리(Decision Tree)나 KNN(K-Nearest Neighbor), 로지스틱(Logistic) 같은 걸 의미합니다. 보팅은 최종 결과 선정 방식에 따라 Hard Voting (하드 보팅), Soft Voting(소프트 보팅) 두 가지로 나뉩니다.
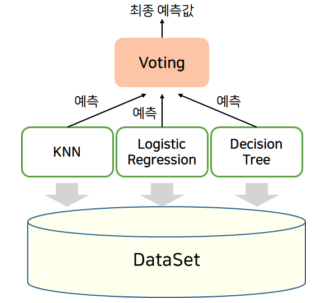
- Hard Voting: 다수결의 원칙을 따르는 방식으로, 각각의 분류기의 결과값 중 가장 많은 걸 따릅니다.
- Soft Voting: 분류기의 확률을 더하고 각각 평균을 내서 확률이 제일 높은 값을 결과값을 선정합니다.
하나의 예시를 들겠습니다.
우주에 관한 임무를 실행할 때에는 모든 신호(signal)들이 순서대로 잘 배치되는것이 중요합니다. 우리가 가진 신호가 다음과 같은 이진 문자열이라 해봅시다.
1110110011101111011111011011
만약 신호가 다음과 같이 망가졌다면, (두번째 1 한 개가 0으로 바뀐 상태):
1010110011101111011111011011
하나의 생명을 잃을 수도 있습니다. 에러 수정 코드에서 해결책을 찾을 수 있습니다. 가장 단순한 방법은 repetition-code입니다. 이 방법은 신호를 동일한 크기의 덩어리로 여러 번 반복하고, 다수결 투표 방식을 적용하는 것입니다.
Original Signal: 1110110011
Encoded: 10,3 101011001111101100111110110011
Decoding: 1010110011 # 두번째 자리 0 주목
1110110011 # 두번째 자리 0이 1로 바뀐 상태
1110110011 # 두번째 자리 0이 1로 바뀐 상태
Majority Vote: 1110110011 # 바뀐 1이 유지되는 상태신호가 손상되는 경우는 흔하지 않습니다. 따라서 다수결 투표방식이 오히려 신호를 손상 시킬 가능성은 더욱 낮습니다. 이 방법으로 신호 손상을 100% 예측할 수는 없지만, 이러한 방식으로 손상된 신호를 원래 신호로 복구할 수 있습니다.
머신러닝에서의 예시
우리가 10개의 샘플을 가지고 있다고 가정해봅시다. 이 샘플들의 실제 정답(ground truth)은 모두 1입니다.
1111111111
세 개의 이진 분류기(binary classifiers)가 있으며, 각각의 모델은 70%의 정확도를 가지고 있습니다. 이 모델들은 70% 확률로 1을 예측하고, 30% 확률로 0을 예측하는 난수 생성기로 볼 수 있습니다. 이러한 랜덤 모델들도 다수결 투표 방식을 통해 78%의 정확도를 달성할 수 있습니다. 이를 수학적으로 설명하면 다음과 같습니다: 3명의 분류기가 다수결 투표를 할 때 4가지 결과를 예상할 수 있습니다.
- 세 개 모두 정답일 확률: 0.7 0.7 0.7 = 0.3429
- 두 개만 정답일 확률: 0.7 0.7 0.3 + 0.7 0.3 0.7 + 0.3 0.7 0.7 = 0.4409
- 한 개만 정답일 확률: 0.3 0.3 0.7 + 0.3 0.7 0.3 + 0.7 0.3 0.3 = 0.189
- 세 개 모두 오답일 확률: 0.3 0.3 0.3 = 0.027
여기서 우리는 약 44%의 경우에서 다수결 투표가 오답을 정답으로 고칠 수 있다는 것을 알 수 있습니다. 이러한 투표는 정답률을 78%로 올려줍니다. (0.3429 + 0.4409 = 0.7838)
다시 Bagging으로 돌아와서, 대표적인 예시로 Random Forest가 있습니다.
- Random Forest(랜덤 포레스트)
모델 앙상블 2 – Boosting(부스팅)
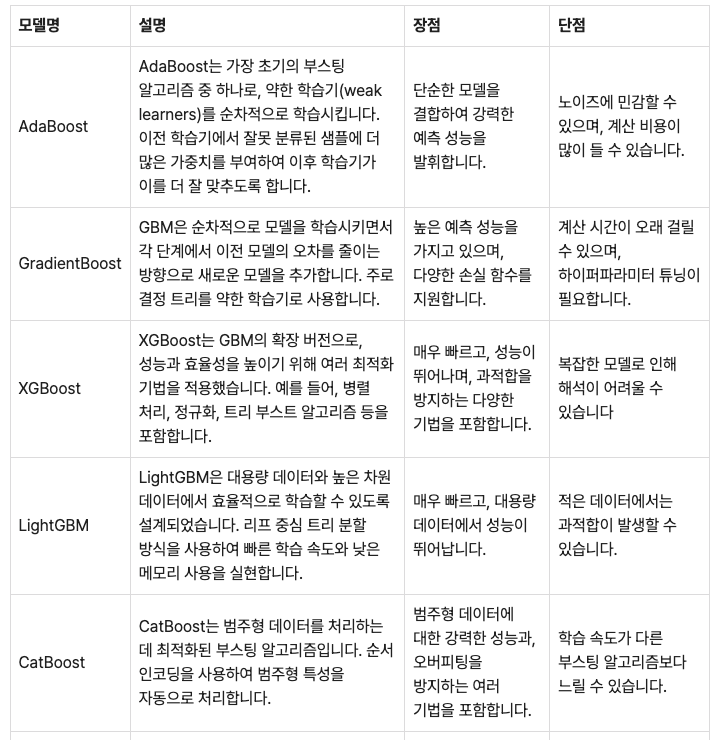
모델 앙상블 을 위한 대표적인 방법으로는Boosting(부스팅)이 있습니다. Boosting(부스팅)은 순차적으로 모델을 학습시키고, 이전 모델이 잘못 예측한 부분을 다음 모델이 개선할 수 있도록 하는 방법입니다. 각 모델의 예측 결과를 가중 평균하여 최종 예측을 만듭니다. Boosting 기법은Adaptive Boosting(AdaBoost, 아다부스트)와 Gradient Boosting Model (그라디언트 부스팅, GBM) 계열로 나눌 수 있습니다.

모델 앙상블 3 – Stacking(스태킹)
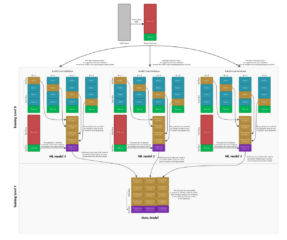
모델 앙상블 을 위해 대표적인 방법으로는Boosting(부스팅)이 있습니다. 스태킹(Stacking), 또는 스태킹 제너럴라이제이션(Stacking Generalization)은 1992년 David H.Wolpert in 1992가 제안한 방법입니다. 이 기법은 여러 개의 서로 다른 모델(베이스 모델)을 학습시키고, 그 예측 결과를 조합하여 최종 예측을 만드는 방식입니다. 이 방법의 핵심 요소는 메타 모델(Meta-model)입니다.
다음은 이 방법을 더 직관적이고 깔끔하게 설명한 내용입니다:
- 스테이지 0 (베이스 모델 학습):
- 여러 개의 다른 모델(베이스 모델)을 k-폴드 교차 검증을 이용해 학습시킵니다.
- 각 폴드에서 베이스 모델은 검증 세트에 대한 예측을 수행합니다.
- 이러한 예측 결과를 모아 새로운 데이터셋을 만듭니다. 이는 메타 모델이 베이스 모델이 학습한 데이터를 직접 보지 않도록 하여 과적합을 방지하는 데 도움을 줍니다.
- 스테이지 1 (메타 모델 학습):
- 베이스 모델의 예측 결과로 구성된 새로운 데이터셋을 사용하여 메타 모델을 학습시킵니다.
- 메타 모델은 이 예측 결과를 조합하여 최종 출력을 만듭니다.
스태킹의 장점은 다양한 모델의 강점을 활용하여 전체적인 성능을 향상시킬 수 있다는 것입니다. 스테이지 0에서 k-폴드 교차 검증을 사용함으로써 과적합을 방지하고 견고한 성능을 보장할 수 있습니다.
그 외 – Blending
모델 앙상블 을 위한 위 3자기 방법외에 Blending이라는 방법이 있습니다. 이 방법은 Stacking에서 사용하는 k-fold 교차 검증을 생략하고, 데이터를 훈련-검증-테스트 세트로 나누어 각 ML 모델을 한 번씩 훈련시킨 후, 예측된 값을 사용하여 메타 모델을 학습하는 방식으로, Stacking보다 단순합니다. Blending의 장점은 비교적 단순하고, Stage 0 모델이 학습하는 데이터와 Stage 1 모델이 학습하는 데이터가 달라 정보 누출 가능성이 적으며, 시간 절약 효과가 있다는 것입니다. 단점으로는 사용되는 데이터 양이 적고, 검증 세트에 과적합될 가능성이 있다는 점이 있습니다.

장점과 단점
장점
- 향상된 성능: 여러 모델의 예측을 결합함으로써 단일 모델보다 더 높은 정확도를 달성할 수 있습니다. 이는 특히 다양한 데이터셋과 조건에서 일관된 성능 향상을 기대할 수 있습니다.
- 과적합 방지:여러 모델을 결합함으로써 특정 데이터 포인트에 지나치게 최적화되는 문제를 효과적으로 방지할 수 있습니다.
- 다양성을 기반으로 한 안전성: 모델의 다양성이 증가함에 따라 개별 모델의 약점을 상쇄하여 예측의 변동성을 줄이고 일관성을 높일 수 있습니다. 이는 예측의 안정성이 높아지는데 효과적이며 특히 노이즈가 많은 데이터에서 성능 향상으로 이어질 수 있습니다.
- 유연성: 다양한 모델을 결합함으로써 복잡한 데이터에 대한 대응력을 높일 수 있습니다.
단점
- 복잡성 증가: 여러 모델을 결합하다 보니 시스템의 복잡성이 증가하여 구현과 유지보수가 어려워질 수 있습니다.
- 계산 비용: 다수의 모델을 훈련하고 예측을 결합하는 과정에서 많은 계산 자원이 필요할 수 있습니다.
- 해석의 어려움: 앙상블 모델은 단일 모델보다 결과를 해석하기가 어려워질 수 있으며, 이를 통해 얻은 통찰력을 설명하는 데 한계가 있을 수 있습니다.
