📄 목차
- Beautiful Soup
- HTML
- Beautiful Soup in vscode
- 크롬 개발자 도구 활용
- 실습
a. 네이버 금융 실습 (환율 정보)
b. 위키 백과 실습 (주요 인물)
c. 시카고 맛집 실습 (메뉴, 가게 이름, 주소, 가격)
1. Beautiful Soup
- Beautiful Soup documentation
Beautiful Soup is a Python library for pulling data out of HTML and XML files.
- HTML은 태그로 이루어져 있으며, bs는 이러한 태그를 이용해 데이터를 불러올 수 있음
HTML
- HTML documentation
- HTML의 태그 등 관련 내용이 담긴 사이트
- 태그는 항상 <content> 로 열리고, </content>로 닫힘 (pair) except <!doctype>
- <!DOCTYPE html> >> declaration
The declaration is not an HTML tag. It is an "information" to the browser about what document type to expect.
- <html>
The <html> tag represents the root of an HTML document.
The <html> tag is the container for all other HTML elements (except for the <!DOCTYPE> tag). - <head>
The <head> element is a container for metadata (data about data) and is placed between the <html> tag and the <body> tag.
Metadata is data about the HTML document. Metadata is not displayed.
Metadata typically define the document title, character set, styles, scripts, and other meta information.
The following elements can go inside the <head> element:
<title> (required in every HTML document), <style>, <base>, <link>, <meta>, <script>, <noscript> - <body>
The <body> tag defines the document's body.
The <body> element contains all the contents of an HTML document, such as headings, paragraphs, images, hyperlinks, tables, lists, etc.
Note: There can only be one <body> element in an HTML document. - <p>
The <p> tag defines a paragraph.
Browsers automatically add a single blank line before and after each <p> element. - <b>, <i> : bold, Italic
- <a>
The <a> tag defines a hyperlink, which is used to link from one page to another.
The most important attribute of the <a> element is the href attribute, which indicates the link's destination.
Beautiful Soup in vscode
- html 파일 열고, 코드 확인
- 변수1 = open("파일 위치", "r").read()
- 변수2 = BeautifulSoup(변수1, "html.parser")
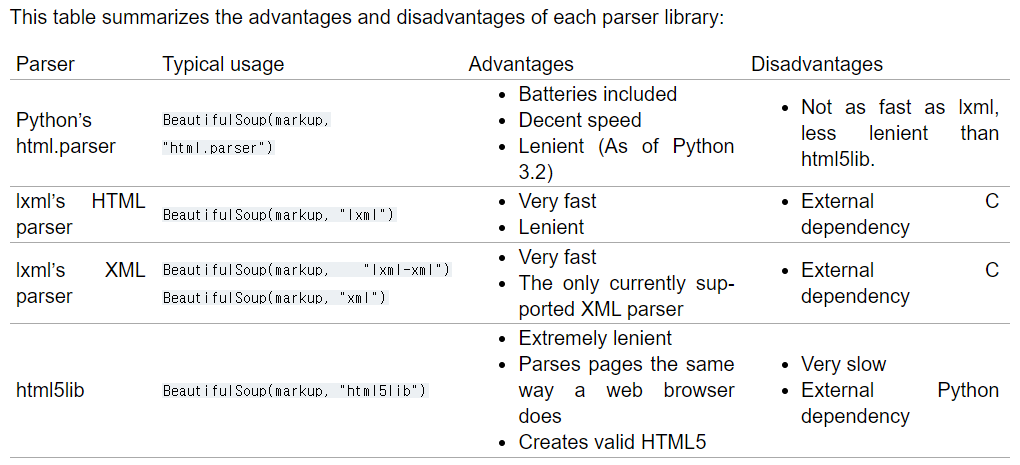
- print(변수2.prettify())
The prettify() method will turn a Beautiful Soup parse tree into a nicely formatted Unicode string, with a separate line for each tag and each string
- 위에서 bs, parser를 먹인 변수를 이하 soup라고 계속 지칭하겠음
- soup.태그로 해당 태그 내용 출력
- e.g. soup.p, .head, .body...
- .find("태그") >> 동일한 기능
- 그러나 가장 첫번째로 읽히는 태그만 출력함
- .find("태그", class_="클래스") 로 상세하게 태그 추적 가능
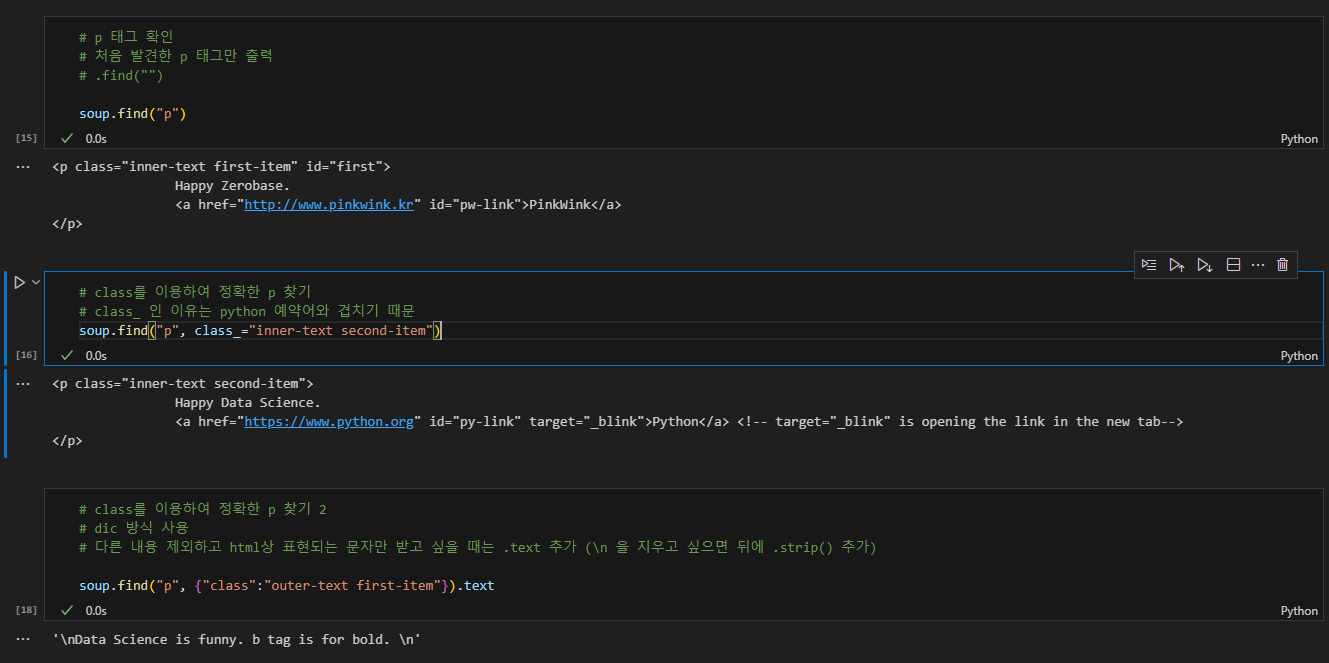
- dic 내부에 여러 key와 value를 추가하여 다중 조건을 줄 수 있음. (클래스와 id...)
- .find_all(조건) >> 모두 찾음, list 형식 반환
- 태그, class, id가 조건 안에 들어갈 수 있음 (다중 조건 가능)
- list 형식 반환이기 때문에, .text를 사용하려면 .find_all(조건)[idx].text
- for문 사용 가능
- .text, .get_text() >> 동일 기능
- hyperlink만 뽑아내고 싶을때
- soup.find_all("조건")[idx].get("href")
- soup.find_all("조건")[idx]["href"]
- select_one, select는 find, find_all과 비슷한 기능
- 사용하는 방법은 조금 다름
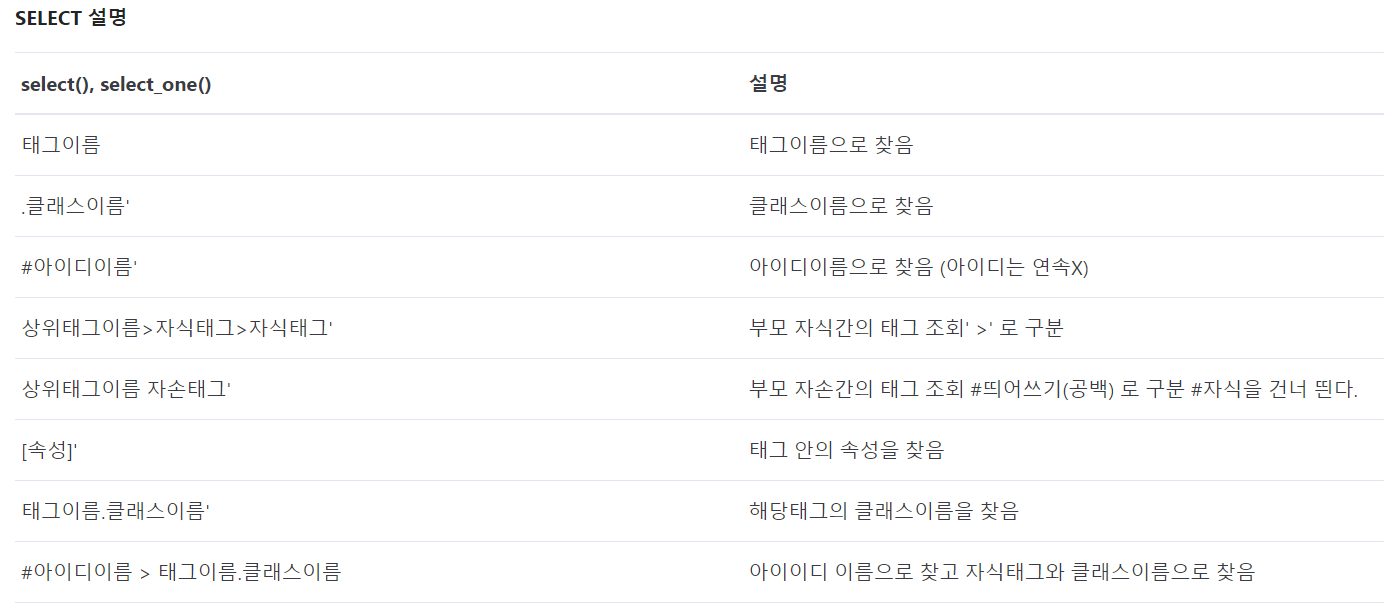
- reference: https://pythonblog.co.kr/coding/11/
- 사용하는 방법은 조금 다름
크롬 개발자 도구 활용
- Chrome web에서 ctrl + shift + i 혹은 F12 키를 누르면 우측에 개발자 도구가 나옴.
- 여기에 표시되는 html 내용을 이용/참고하여 웹페이지 데이터 활용이 가능함.
- 태그에 커서를 대면 어떤 내용을 보여주는지도 표시됨. (개발자 도구 좌측 상단 = element selector)
- 필요 코드
- urllib.request의 urlopen import
- var1 = "웹페이지 주소"
- var2 = urlopen(var1)
- var3 = BeautifulSoup(var2, "parser", from_encoding="cp949")
- 인코딩은 다른 것으로 해도 상관 없음
- HTTP 상태 코드
- urlopen(웹페이지).status >> 상태 코드 반환함
- 100번대 : informational response
the request was received, continuing process
- 200번대 : success
the request was successfully received, understood, and accepted
- 300번대 : redirection
further action needs to be taken in order to complete the request
- 400번대 : client errors
the request contains bad syntax or cannot be fulfilled
- 500번대 : server errors
the server failed to fulfil an apparently valid request
- requests 모듈을 다운로드 받아 사용하는 방법도 있음 (urllib.request.Request와 기능적으로 비슷)
- var1 = requests.get(url)
- var1 부르면 상태 코드 출력해줌
- var1.text 로 html 내용 불러올 수 있음
- bs 사용하고 싶으면 var1.text 사용해야 됨
2. 실습
a. 네이버 금융에서 환율 정보 가져오기
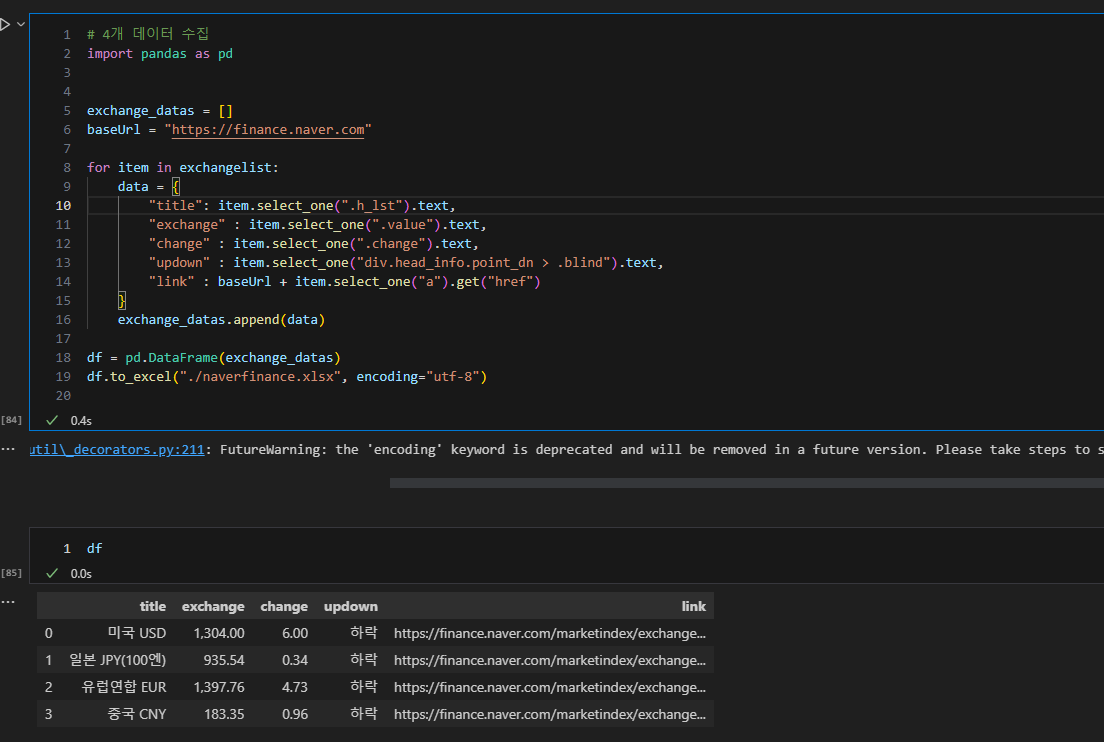
- 크롬 개발자 도구에서 어떤 태그, id로 무슨 정보를 보여주고 있는지 확인하고 특정 정보만 가져올 수 있음
b. 위키 백과에서 원하는 정보를 가져오기
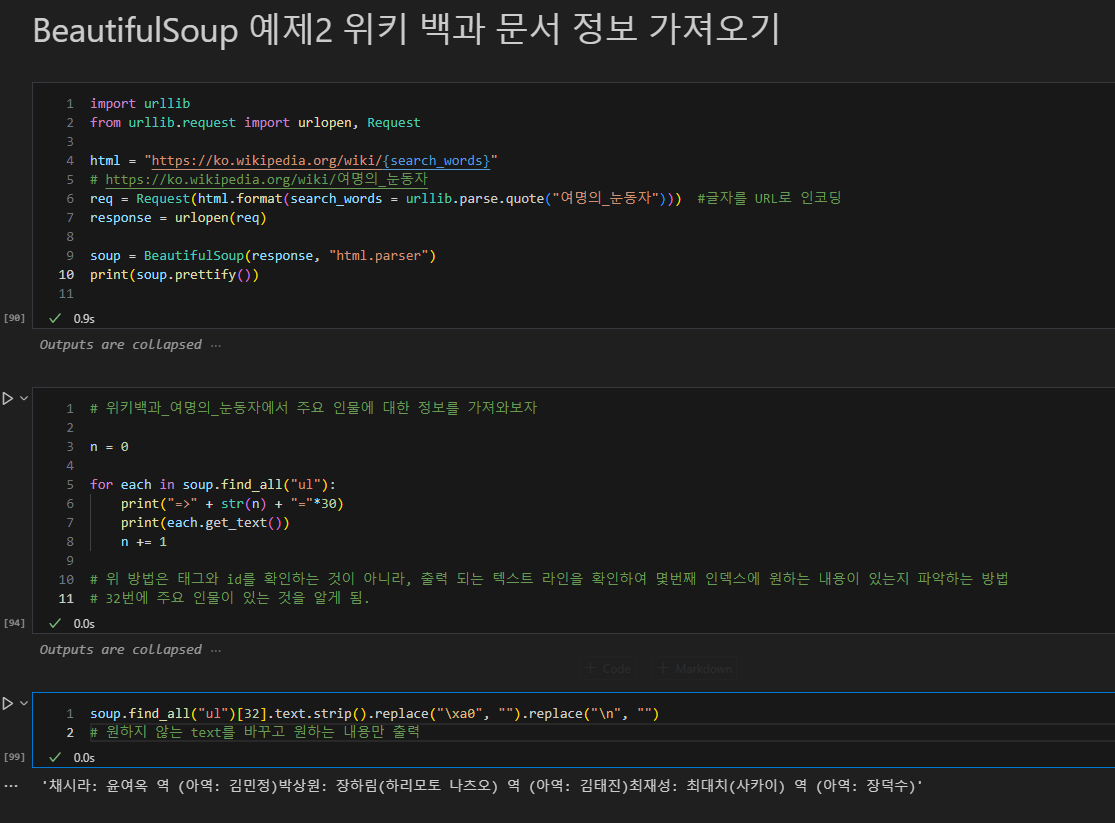
c. 시카고 맛집 분석
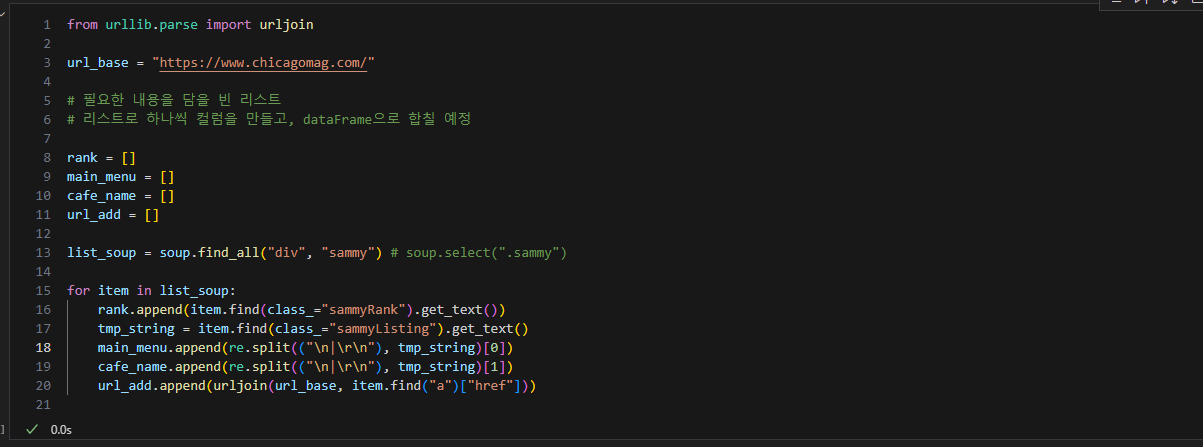
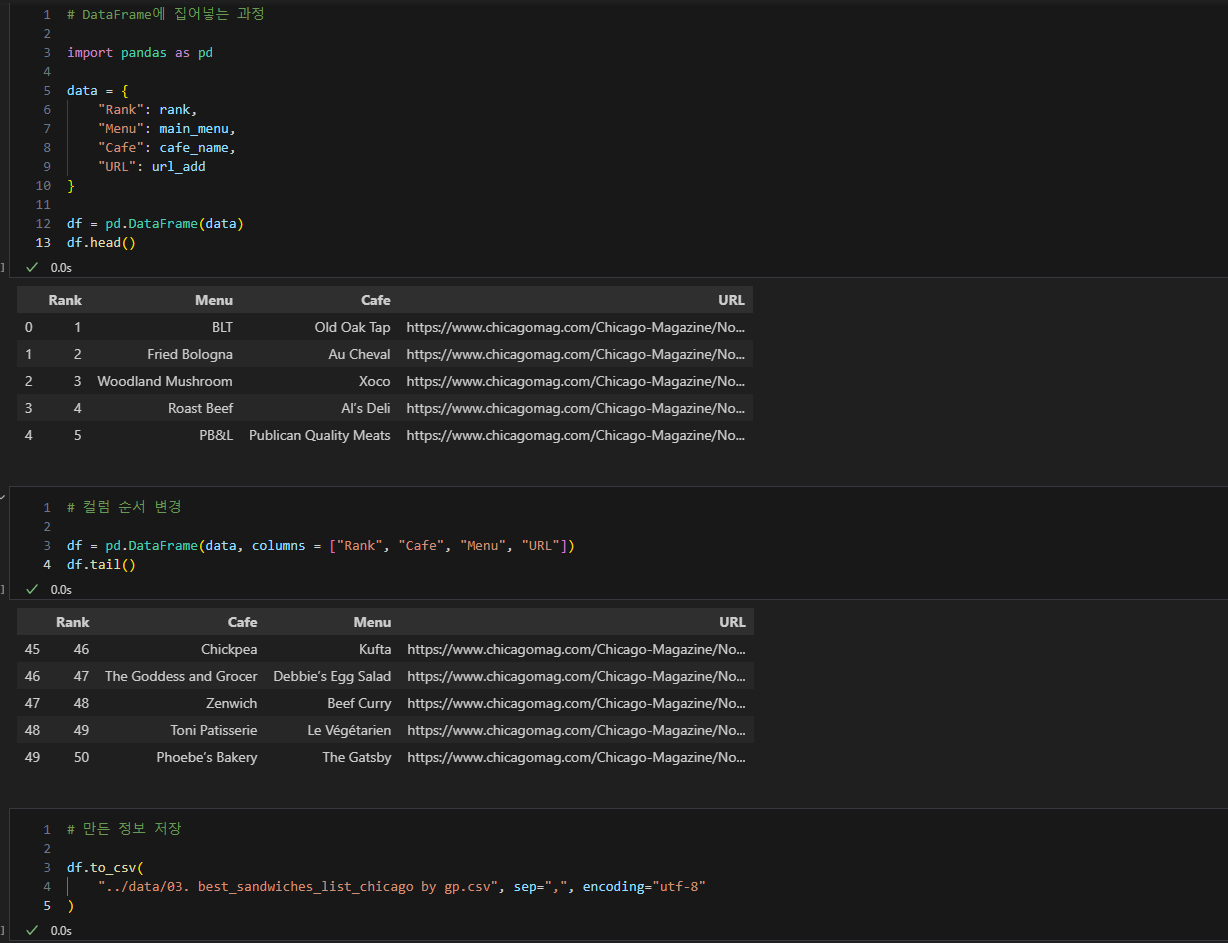
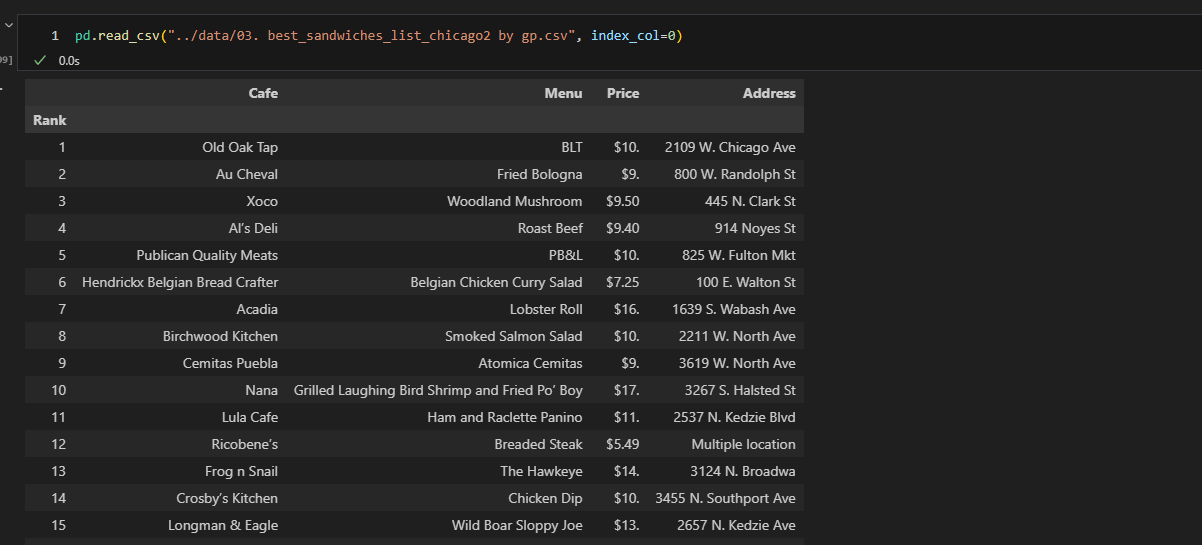
1. 데이터 프레임 구상
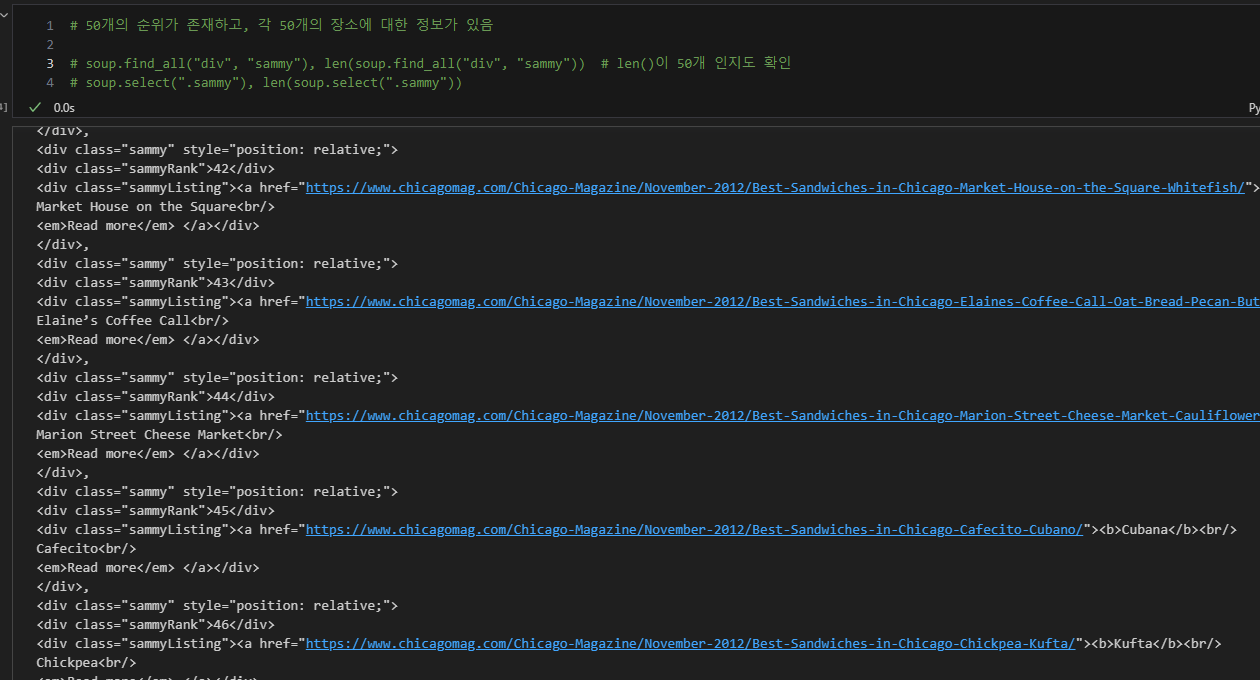
- 50가지 순위가 존재
- 50가지의 메인 메뉴, 가게 이름, url, 순위를 담을 예정
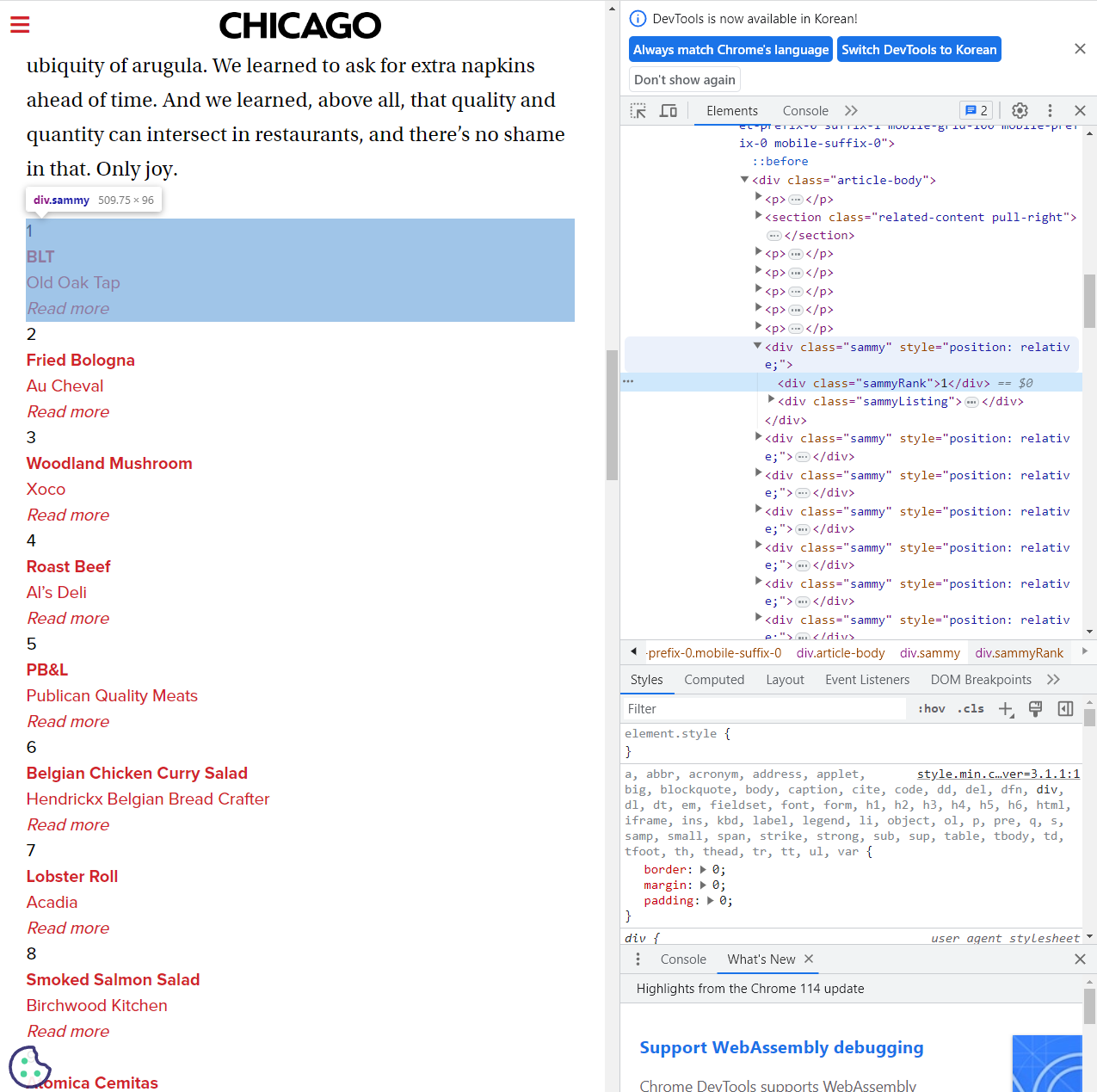
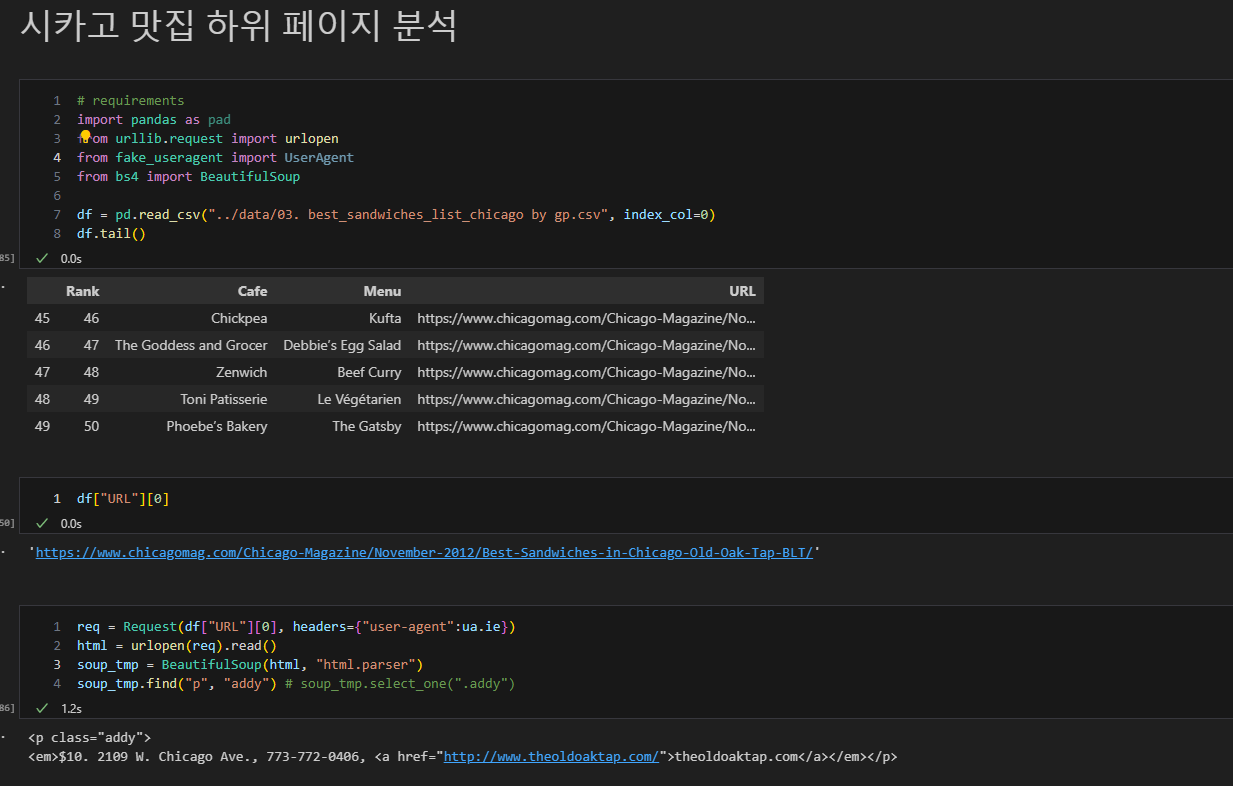
2. 해당 url 연결 가능한지 확인
- headers 문제로 안되는 경우 있음
- fake_useragent 모듈 사용하거나
- 크롬 개발자 도구 통해 요구 사항 확인
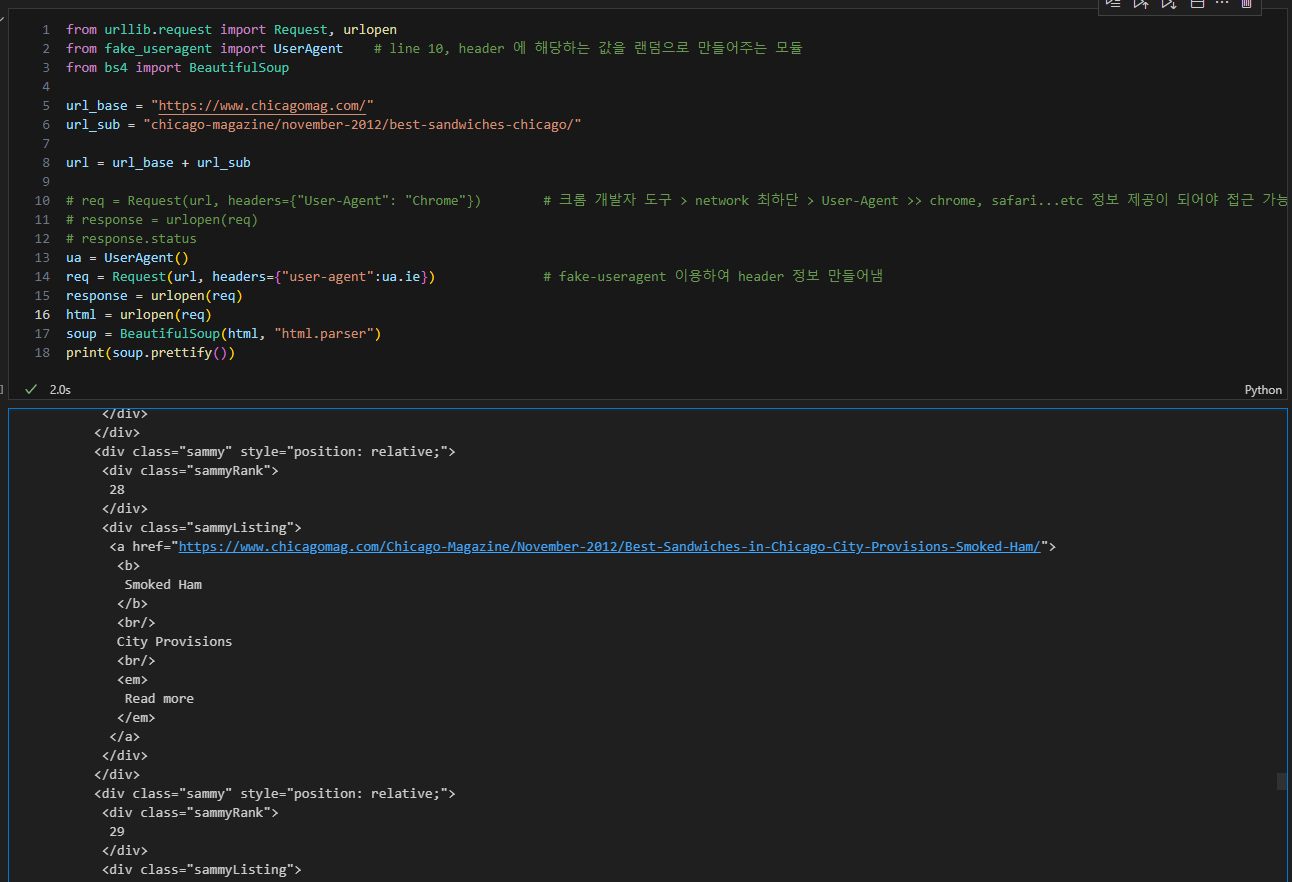
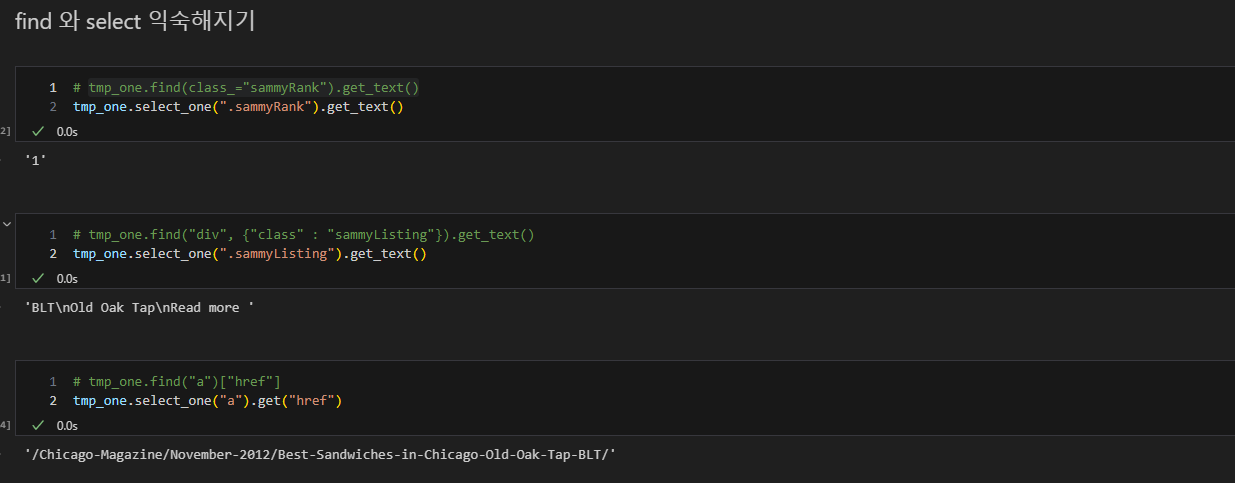
3. 원하는 정보를 가져올 수 있는 태그 확인
- 태그, class, id 등 확인
- 이때 임시 코드 라인을 작성하여, 원하는 내용만 가져올 수 있도록 테스트 지속 진행
- 순위
- 메뉴
- 가게 이름
- url


4. 데이터 프레임화, 정렬, 저장
5. 디테일 추가하기
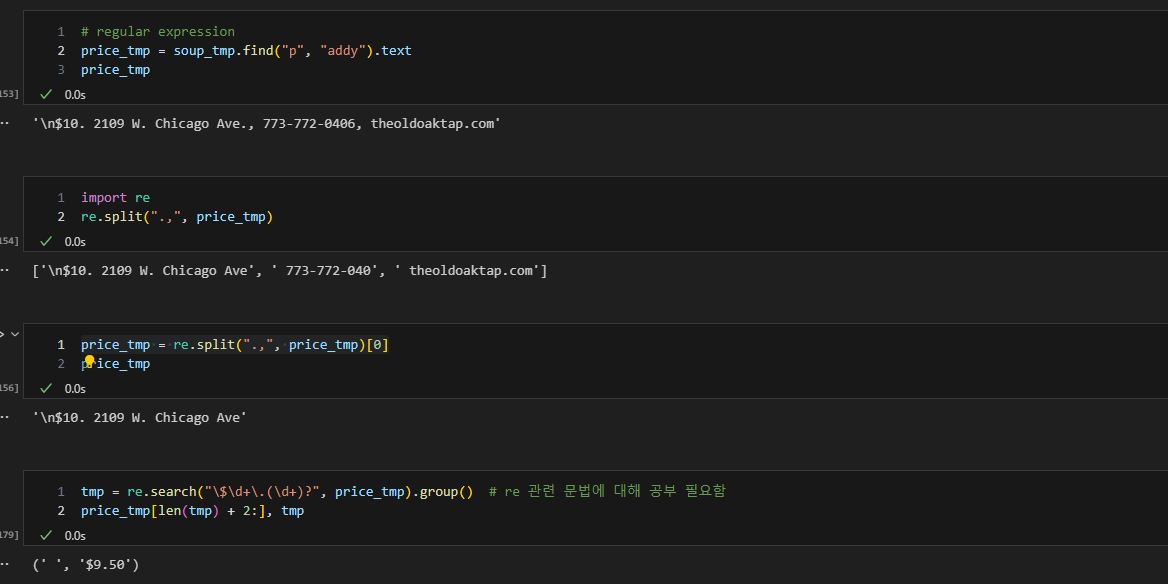
- 위에서 진행한 순서대로 해당 맛집 관련 하위 페이지에 반복하여 가격과 주소를 가져오면 됨.
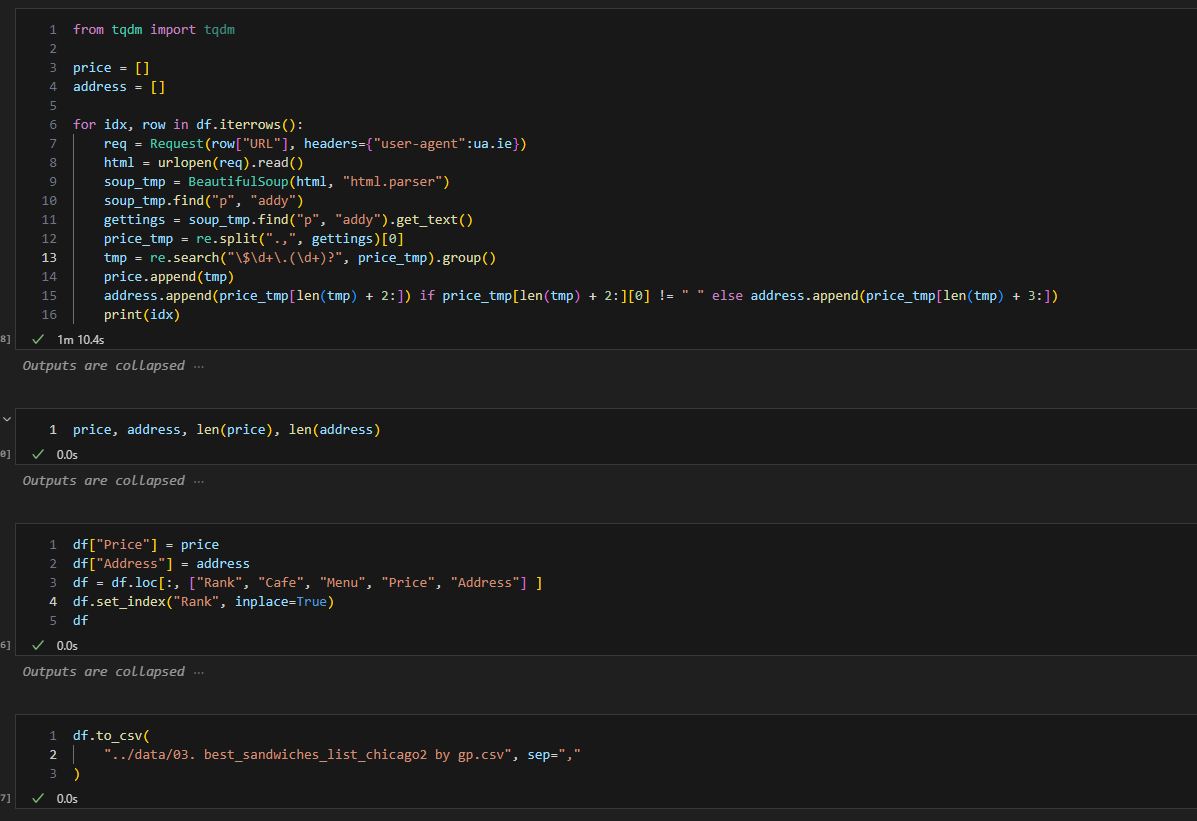
- 데이터가 많아져서 for문의 진행 정도를 중간 중간 확인하고 싶을 때는 tqdm 이라는 모듈을 사용하면 됨.
웹페이지 방문 등으로 인해 속도가 일반 코드를 실행하는 것보다 오래 걸림.- tqdm
- tqdm in detail
- tqdm으로 중간 중간 print 되는 것을 확인하고 싶은데, 출력이 안되는 문제가 있음. 추가 확인 필요
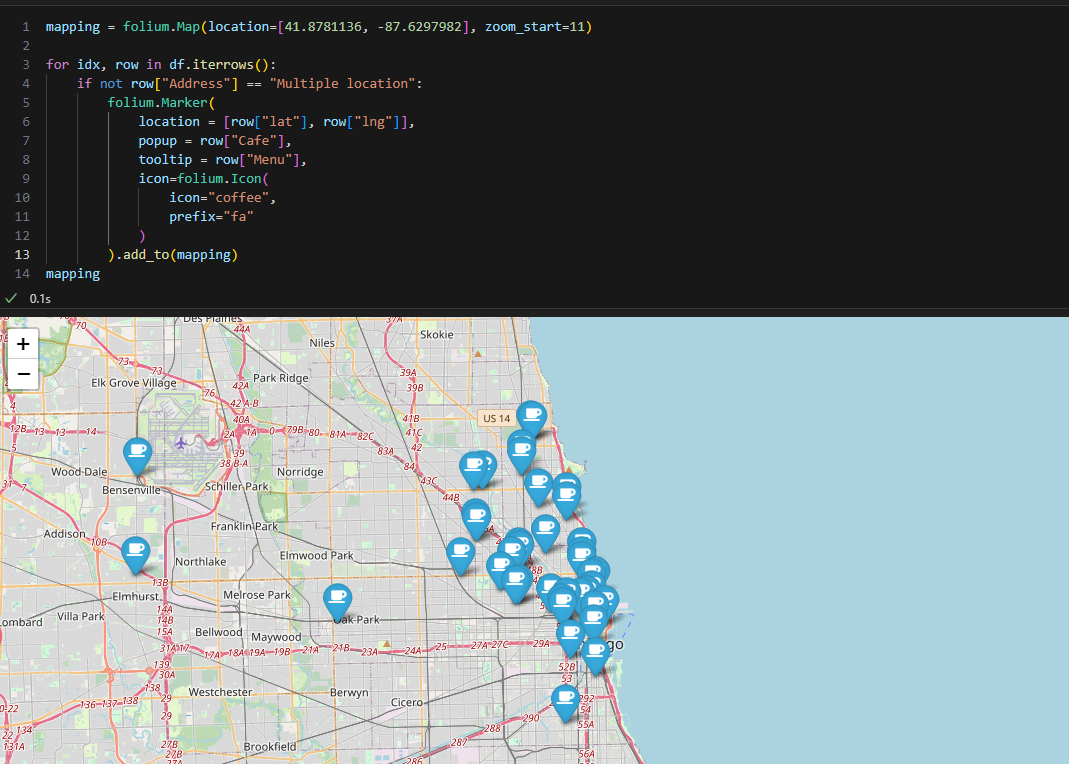
6. 지도 시각화
- 각종 필요한 모듈 import
(folium, pandas, numpy, googlemaps)- 가게 이름이 있는 자료 불러올 것
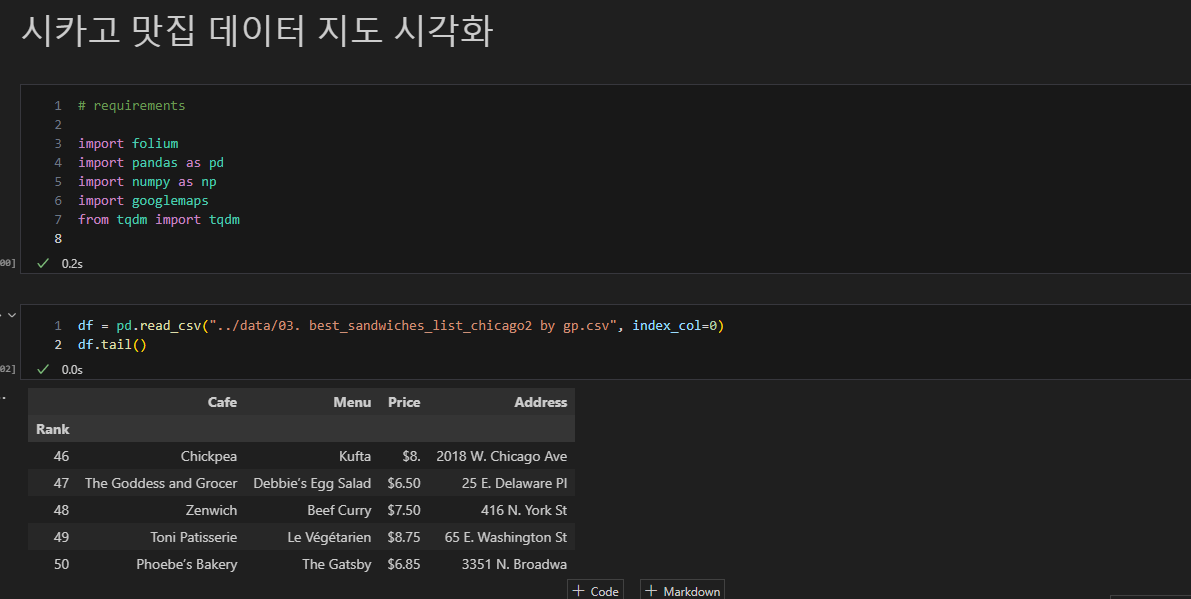
- 가게 이름이 있는 자료 불러올 것
- gmaps key 이용하여 구글맵 api 접근 허용
- for문을 이용하여 위도 경도 정보 데이터에 추가
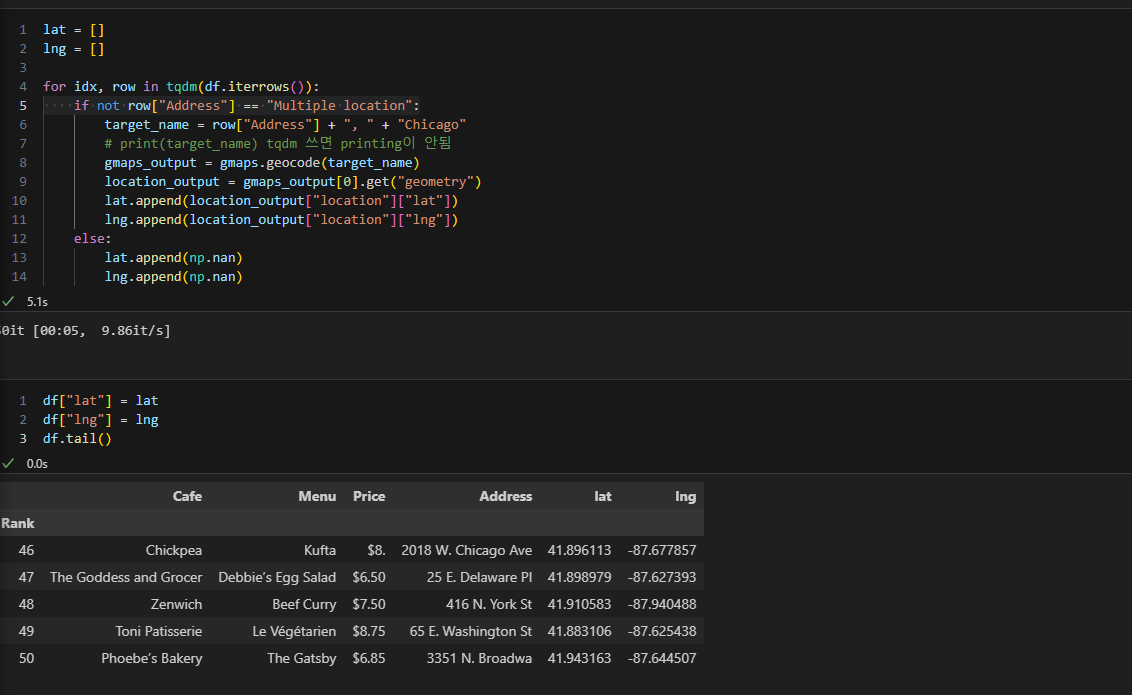
- for문을 이용하여 해당 location에 팝업 띄우기