
셀프 주유소 가격 분석
1) 데이터 확보하기 위한 작업
셀프 주유소의 가격은 정말 저렴한가??
- 데이터 가져온 경로 : https://www.opinet.co.kr/user/main/mainView.do
- 사이트 구조 확인
- 목표 데이터
- 브랜드
- 가격
- 셀프주유 여부
- 위치
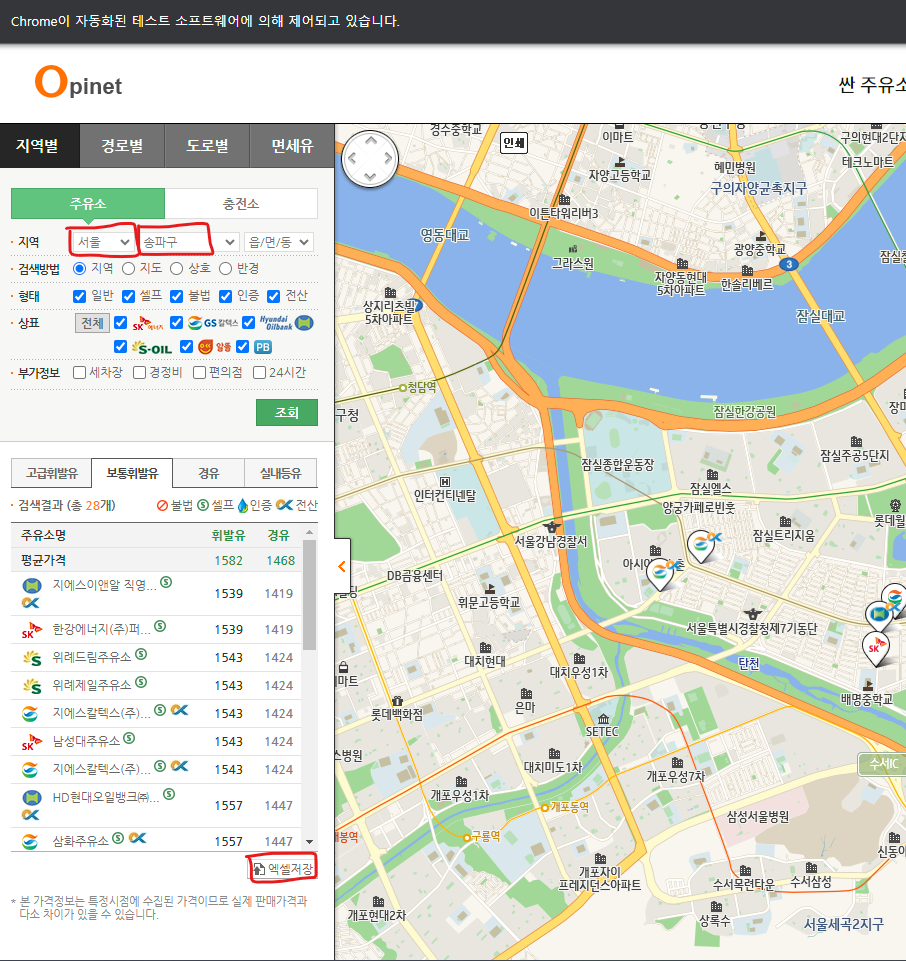
- 데이터 가져 올 드라이버 창
- 시/도, 구 를 선택
- 액셀 저장버튼 누르면 해당 내용 액셀로 저장
- selenium을 이용해 서울 지역의 모든 행정구역의 주유소 정보 가져오면 되겠다.
- 모듈 가져오기 및 드라이버 창 불러오기
from selenium import webdriver from selenium.webdriver.common.by import By url = "https://www.opinet.co.kr/searRgSelect.do" driver = webdriver.Chrome("../driver/chromedriver.exe") driver.get(url)
1_1 시/도 에서 서울 선택하기
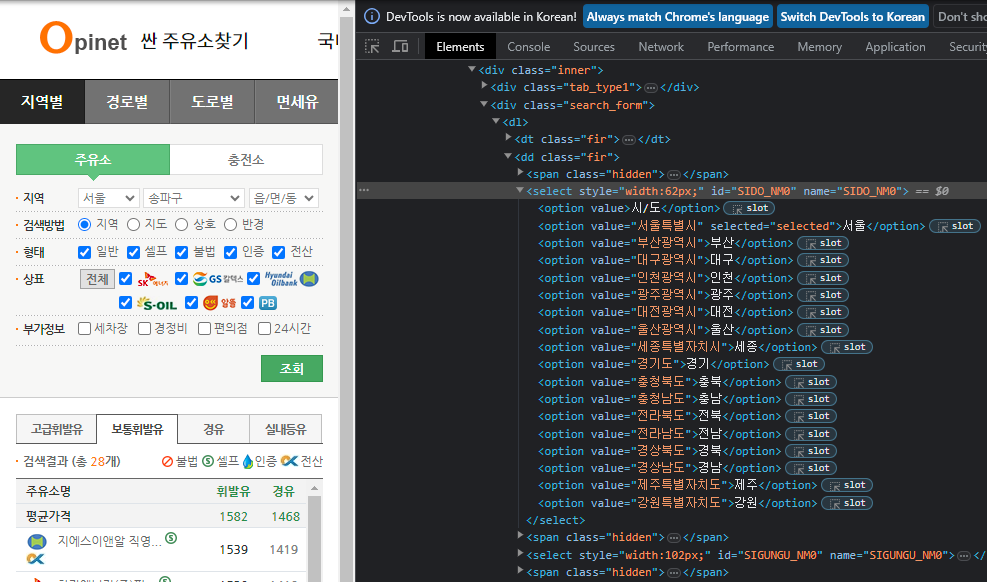
- ID 가 있다면 편리해진다.
- ID로 요소 찾아서 문자열로 반환
sido_list_raw = driver.find_element(By.ID,"SIDO_NM0")
sido_list_raw.text
전처리가 필요
먼저 하나의 값을 가져와보고 가져와 진다면 그것을 이용해 반복문으로 원하는 전체 데이터 가져오기
- 위 창에서 볼 수 있듯 option태그를 찾아 문자로 반환하면 지역명을 얻을 수 있다.
- option태그의 두번째 값 가져오기
sido_list = sido_list_raw.find_elements(By.TAG_NAME,"option") sido_list[1].text
'서울'
- 단축되어있는 지역명 보다는 풀네임이 좋다.
- 개발자 도구에서 보니 option태그의 value값들이 지역명의 풀네임이다.
- value 두번째값 가져오기
- 태그안의 값을 가져오려면 get_attribute("가져올 정보")
sido_list[1].get_attribute("value")
'서울특별시'
- 반복문을 이용해 모든 지역명 가져오기
sido_names = [] for option in sido_list: sido_names.append(option.get_attribute("value"))한줄로 작성한다면
sido_names = [option.get_attribute("value") for option in sido_list]
['', '서울특별시', '부산광역시', '대구광역시', '인천광역시', '광주광역시', '대전광역시', '울산광역시', '세종특별자치시', '경기도', '충청북도', '충청남도', '전라북도', '전라남도', '경상북도', '경상남도', '제주특별자치도', '강원특별자치도']
- 반환받은 리스트의 가장 첫번째 값이 ''이므로 지워주자(슬라이싱)
sido_names = sido_names[1:] sido_names
['서울특별시', '부산광역시', '대구광역시', '인천광역시', '광주광역시', '대전광역시', '울산광역시', '세종특별자치시', '경기도', '충청북도', '충청남도', '전라북도', '전라남도', '경상북도', '경상남도', '제주특별자치도', '강원특별자치도']
- 드라이버 창에서 시.도를 변경하는 명령어
- 그 중에서 서울특별시를 고르기 위해서는 첫번째 값을 선택
sido_list_raw.send_keys(sido_names[0])

1_2 구 선택하기
- 위의 시/도 선택하는 방법과 동일하다.
gu_list_raw = driver.find_element(By.ID,"SIGUNGU_NM0")
gu_list = gu_list_raw.find_elements(By.TAG_NAME,"option")
gu_names = [option.get_attribute("value") for option in gu_list]
gu_names = gu_names[1:]
gu_names, len(gu_names)(['강남구',
'강동구',
'강북구',
'강서구',
'관악구',
'광진구',
'구로구',
'금천구',
'노원구',
'도봉구',
'동대문구',
'동작구',
'마포구',
'서대문구',
'서초구',
'성동구',
'성북구',
'송파구',
'양천구',
'영등포구',
'용산구',
'은평구',
'종로구',
'중구',
'중랑구'],
25)1_3 액셀저장 버튼 클릭해서 액셀로 저장하기
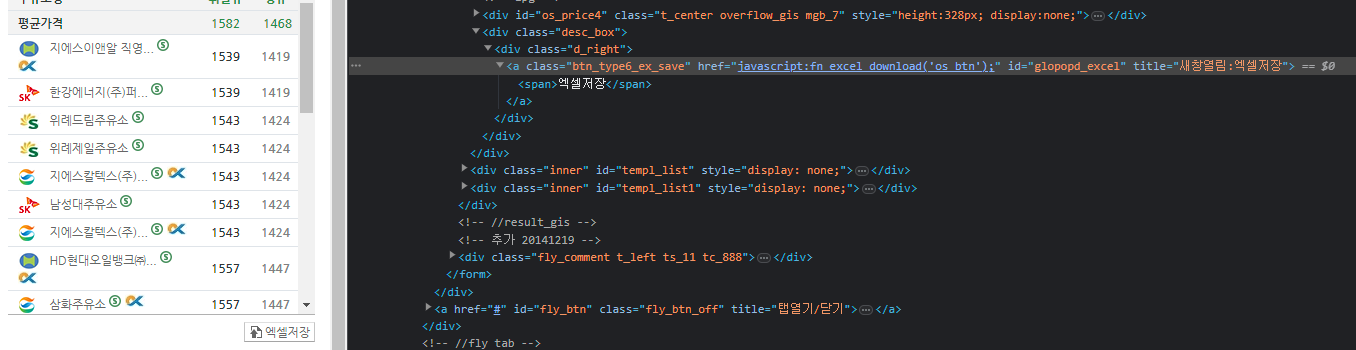
- 여러가지 방법으로 "액셀저장" 버튼 클릭
#ID값으로 driver.find_element(By.ID,"glopopd_excel").click() #CSS_SELECTOR로 #driver.find_element(By.CSS_SELECTOR,"#glopopd_excel").click() #XPATH로 #driver.find_element(By.XPATH,'//*[@id="glopopd_excel"]').click()
- 반복문으로 서울시의 모든 구 주유소정보 액셀파일로 저장
- 구 를 하나씩 선택 후 액셀저장 버튼을 클릭해주면 된다.
- selenium은 너무 빠른 작업을 하게 되면 미처 작업을 마치지 못하고 넘어가 오류가 뜬다.
- time 모듈을 가져와서 작업 중간에 time.sleep(멈출 시간_sec) 를 넣어줘야 한다.
- tqdm은 저장되어가는 과정을 %로 보여준다.
import time
from tqdm import tqdm_notebook
for gu in tqdm_notebook(gu_names):
element = driver.find_element(By.ID,"SIGUNGU_NM0")
element.send_keys(gu)
time.sleep(3)
element_get_excel = driver.find_element(By.ID,"glopopd_excel").click()
time.sleep(3)
2) 데이터 정리
glob은 파일의 목록을 한번에 가져오는 모듈
- 모듈 가져오기
import pandas as pd from glob import glob
- 파일 목록 한번에 가져오기
- "지역*.xls" 는 "지역"으로 시작하는 모든 .xls 파일
- 리스트 형식으로 저장
station_files = glob("../data/지역_*.xls")

- 확인 차 파일 한개 읽어보기
- header = 2를 주는 이유는 원본액셀을 보면 최상단 2열이 제목이 들어가있다.
tmp = pd.read_excel(stations_files[0], header = 2) tmp.tail(2)

- 반복문으로 모든 주유소 정보 읽어와서 리스트에 저장
tmp_raw = [] for file_name in stations_files: tmp = pd.read_excel(file_name, header = 2) tmp_raw.append(tmp)
concat()
형식이 동일하고 연달아 붙이기만 하면 되는 경우 concat을 사용해서 모든 데이터 하나의 데이터프레임으로 결합
- 모든 서울시 구 주유소정보 결합
stations_raw = pd.concat(tmp_raw) stations_raw
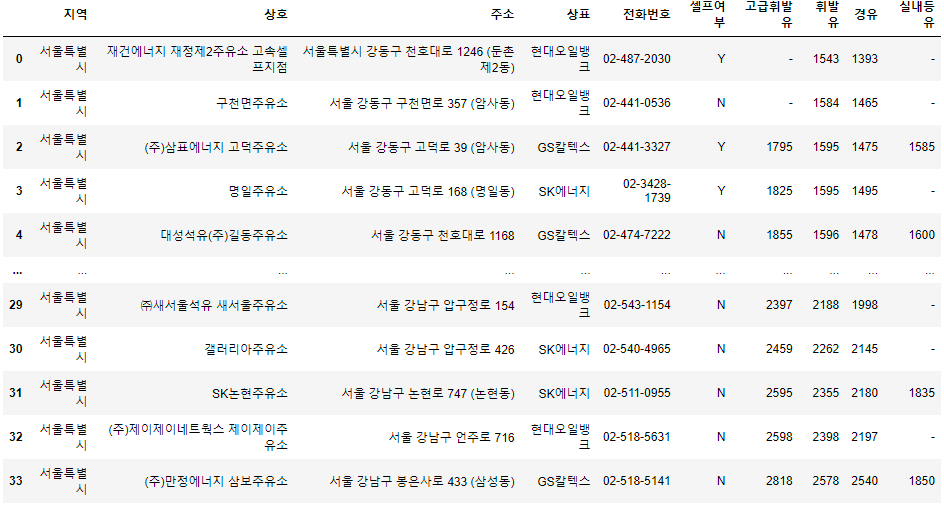
- 정보 확인
stations_raw.info()
- 모두 443개의 정보 확인
- 모두 문자열 확인
- 인덱스가 0~33?? 인덱스 재정렬이 필요하겠다.

- 데이터 분석에 필요한 정보들만 가져와서 데이터프레임 만들기
stations = pd.DataFrame({ "상호" : stations_raw["상호"], "주소" : stations_raw["주소"], "가격" : stations_raw["휘발유"], "셀프" : stations_raw["셀프여부"], "상표" : stations_raw["상표"] }) stations.tail()
- "주소" 컬럼 기준으로 주유소 구 가져오기
# 주소 컬럼 기준으로 어떤 구 인지 정리 # 주소 컬럼 한열 씩 띄어쓰기 기준으로 2번째 가 구이름 for eachAddress in stations["주소"]: print(eachAddress.split()[1])

- "구"컬럼을 추가
stations["구"] = [eachAddress.split()[1] for eachAddress in stations["주소"]] statioins.tail()
- 구 컬럼의 unique값을 구해 길이를 알아보자
- 서울시 행정구역은 총 25개 이므로 25가 나와야 정상
stations["구"].unique(), len(stations["구"].unique())

- "가격" 컬럼을 float(실수)형으로 변경
stations["가격"] = stations["가격"].astype("float")ValueError: could not convert string to float: '-'
- 오류가 뜬다.
- 데이터 프레임에 가격정보가 안들어가있어 "-" 로 처리된 구간이 있다는 뜻
- 가격이 들어가있지 않는 주유소가 어딘지 찾아보자
stations[stations["가격"] == "-"]
- 이 한곳 때문에...

- 가격 정보가 있는 곳만 다시 stations 에 넣어주자
stations = stations[stations["가격"] != "-"] stations.tail()
- 다시 가격컬럼을 실수형으로 변경
stations["가격"] = stations["가격"].astype("float")
- 정보 확인
stations.info()
- stations
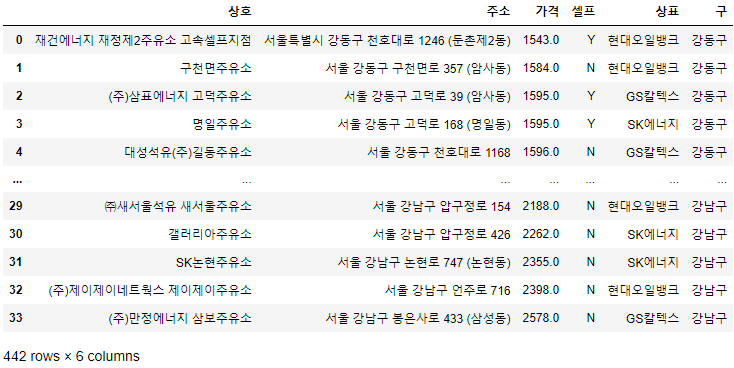
- index 재정렬
stations.reset_index(inplace=True) stations.tail()
- index 컬럼 삭제
del stations["index"] stations.tail()
이제 사용할 정보들을 깔끔하게 정리 완료했따.
3) 시각화
- 모듈 가져오기
import matplotlib.pyplot as plt import seaborn as sns import platform from matplotlib import rc #마이너스 기호 깨짐 처라 plt.rcParams["axes.unicode_minus"] = False #한글 깨짐 처리 rc("font", family="Malgun Gothic")
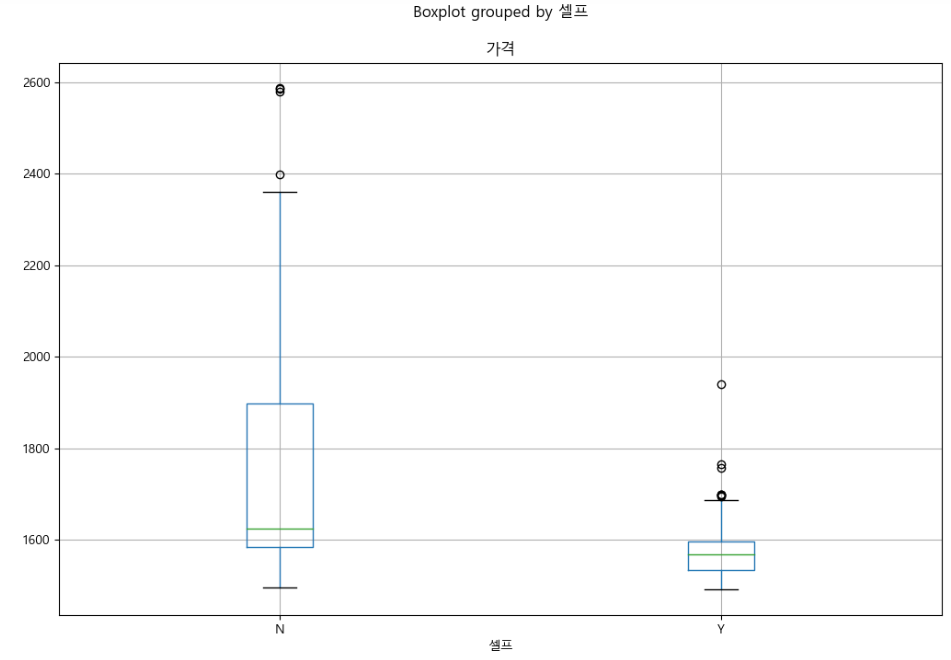
- pandas를 이용한 boxplot 그리기
stations.boxplot(column="가격", by="셀프", figsize=(12,8))
- seaborn을 이용해 boxplot 그리기
plt.figure(figsize = (12,8)) sns.boxplot(x="셀프",y="가격", data=stations, palette="Set3") plt.grid(True) plt.show()
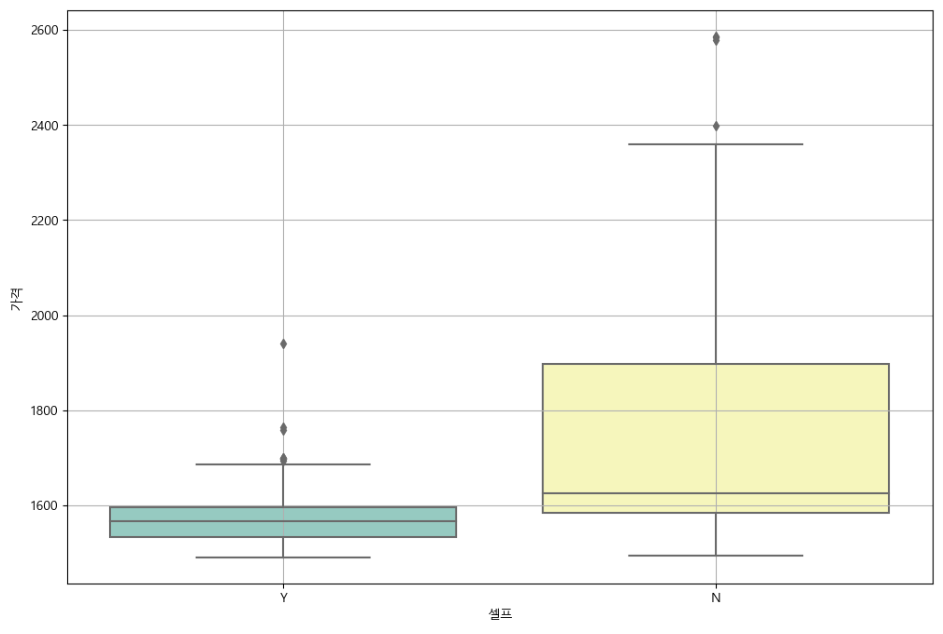
위의 시각화 정보를 보면 보는 방법을 모르더라도 눈치껏 셀프주유소가 Y인 것이 가격이 싸다.
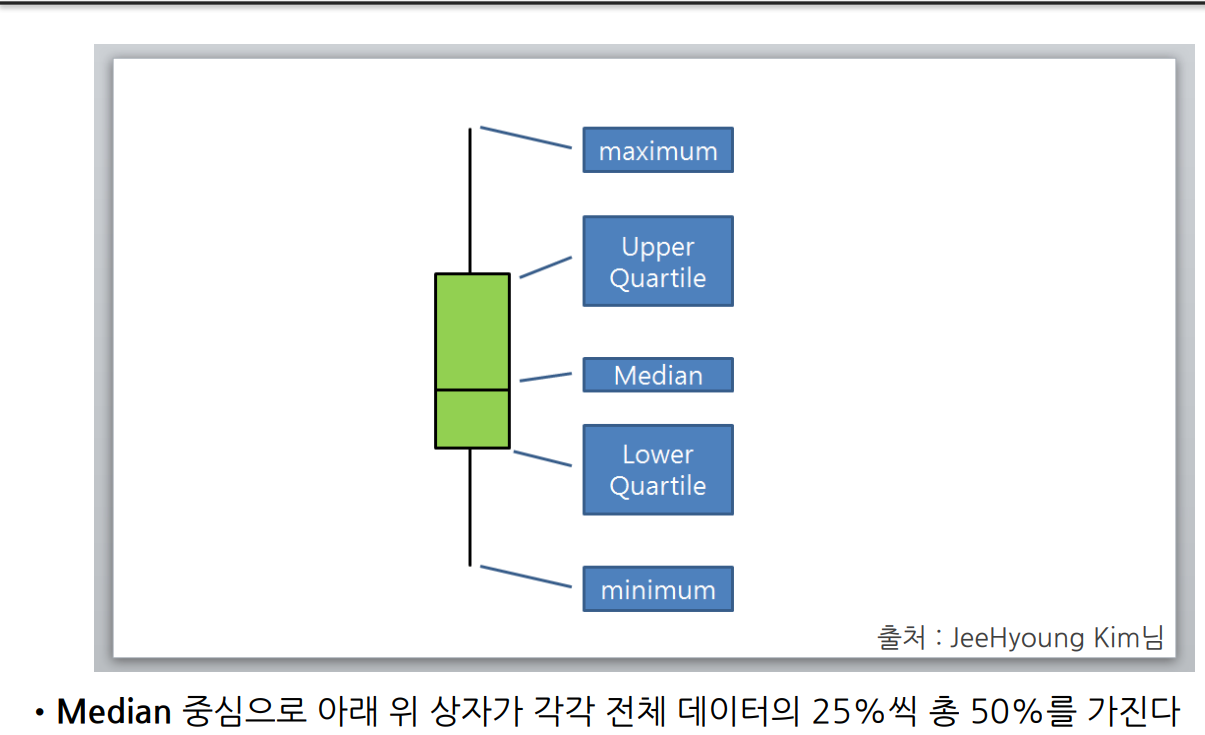
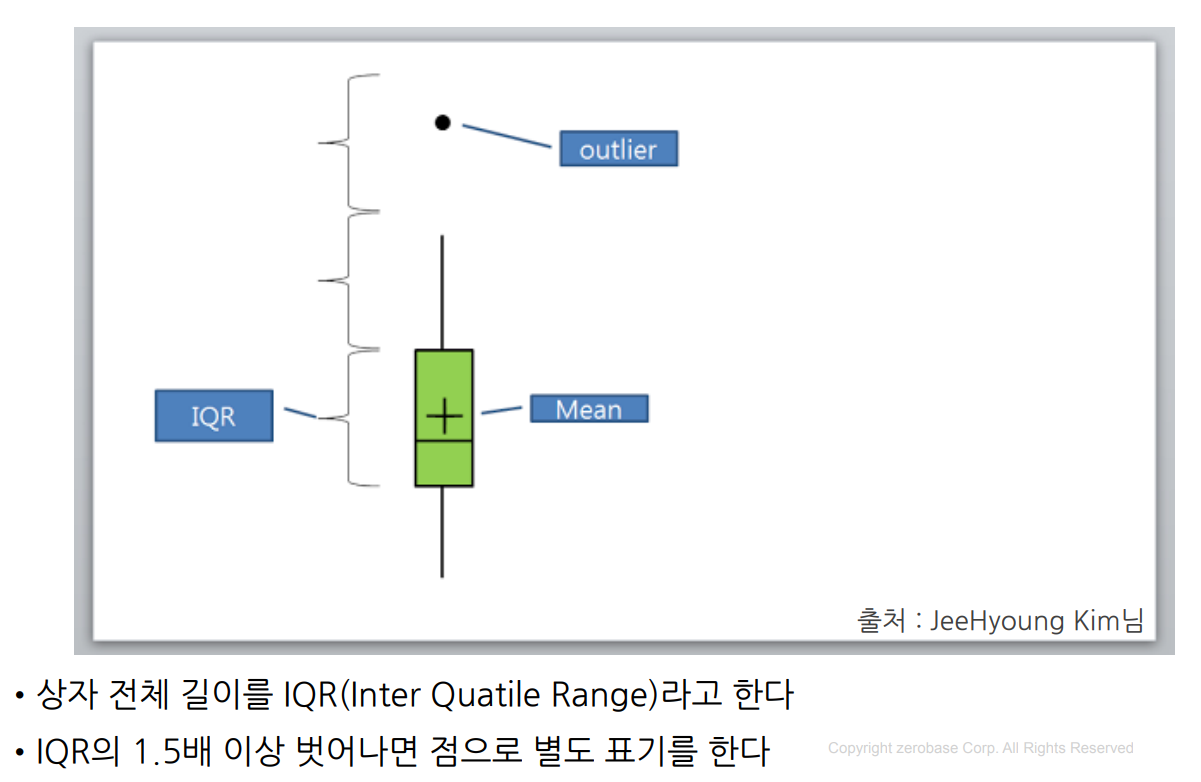
- boxplot읽는 법을 요약해보면
- 상표 별 셀프 주유소의 여부별 가격을 시각화 해보자
plt.figure(figsize =(12,8)) sns.boxplot(x="상표",y="가격",hue="셀프", data=stations, palette = "Set2") plt.grid(True) plt.show()
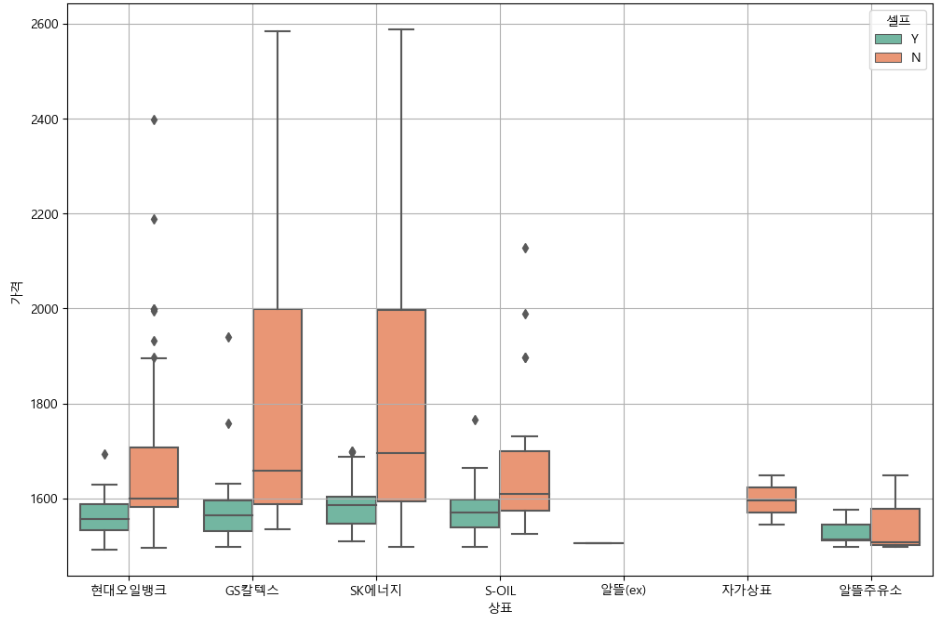
오늘 기준 GS칼텍스, SK에너지 주유소가 대체적으로 휘발유값이 비싸고
전체적으로 셀프주유소들은 가격이 대체적으로 싸다
이전에 범죄분석에서 사용했던 서울시 행정구역 경계선의 .json파일을 이용해서 지도에 행정구역 평균가를 시각화해보자
- 모듈 가져오기
import json import folium import numpy as np # FutureWarning을 뜨지 않게 import warnings warnings.simplefilter(action="ignore",category = FutureWarning)
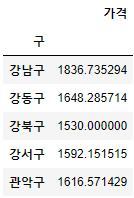
- pivot_table을 이용해 index가 "구"이고 가격 구 별로 가격컬럼의 평균값들을 넣어보자
gu_data = pd.pivot_table(data = stations, index="구", values ="가격", aggfunc=np.mean) gu_data.head()
- json파일을 불러와 지도에 시각화
geo_path = "../data/02. skorea_municipalities_geo_simple.json" geo_str = json.load(open(geo_path, encoding="utf-8")) my_map = folium.Map(location=[37.5502, 126.982], zoom_start= 10.5, tiles="Stamen Toner") my_map.choropleth( geo_data = geo_str, data = gu_data, columns = [gu_data.index, "가격"], key_on ="feature.id", fill_color = "PuRd" ) my_map
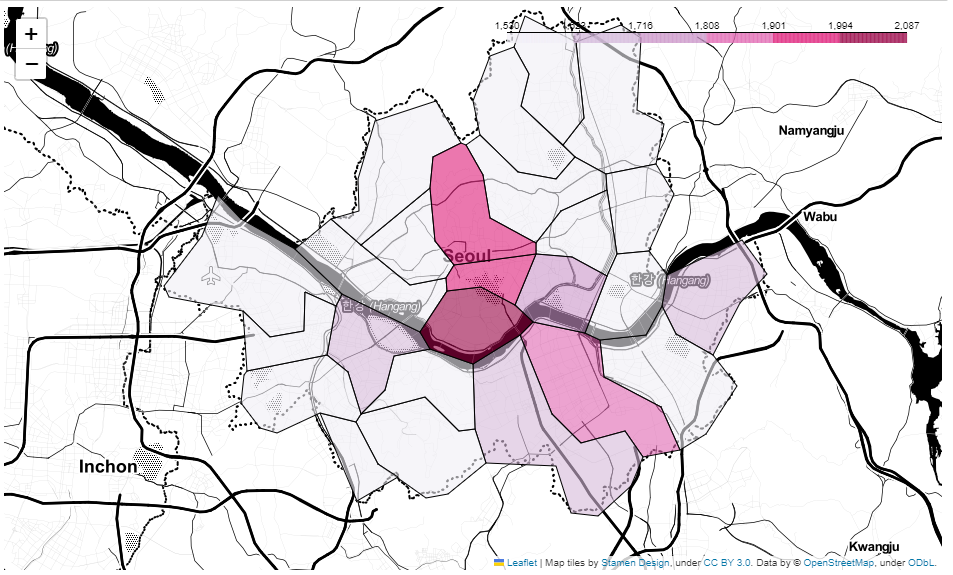
한눈에 어느 구역이 다른구역 대비 비싼지 알 수 있다.

취업공부