
00. SQL 101
구글 빅쿼리에서 사용하는 대부분의 문법은 일반 RDBMS SQL과 매우 유사합니다. 이번 글에서는 이러한 SQL의 기초적인 사용법에 대해서 정리를 하도록 하겠습니다. 갑자기 SQL을 정리하게 된 이유는 회사에서 이를 정리해야 하는 일이 있었기 때문입니다 😂
01. SQL에서 데이터를 검색하는 법
1. 데이터베이스와 테이블의 개념과 구조
1.1 데이터베이스와 테이블
- 데이터베이스와 테이블은 MS SQL Server와 같은 RDBMS에서 가장 기본적인 구성 요소임
- 데이터베이스에는 여러 테이블이 속해 있으며 테이블은 데이터를 저장하는 행과 열로 구성됨
- 열(column)은 데이터의 종류를 정의하고 행(row)은 데이터의 실제 값을 포함함
- 행은 테이블 안에서 식별자를 가지며 이 식별자를 통해 데이터를 검색할 수 있음
1.2 엑셀에 비유
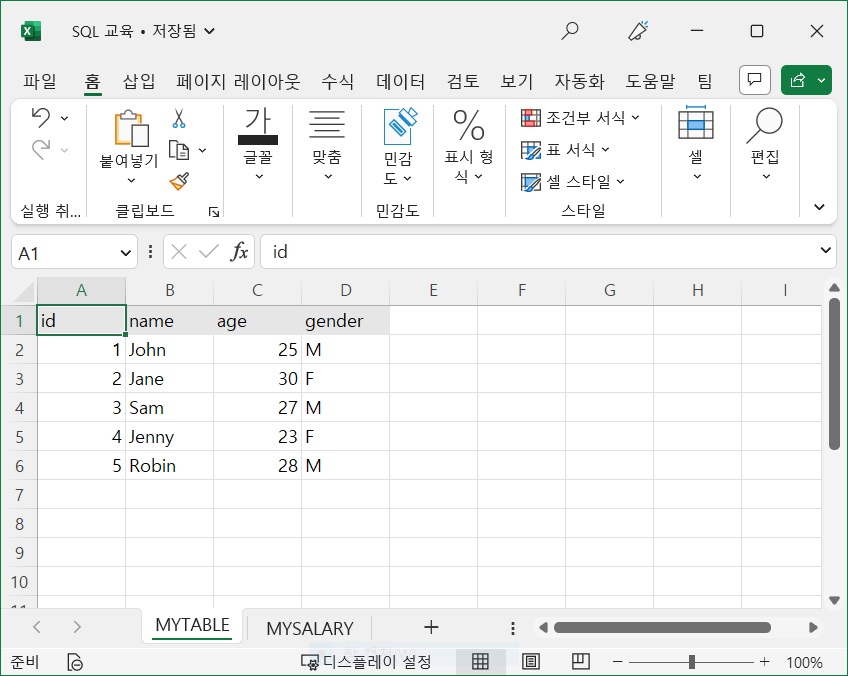
- 엑셀 파일에는 여러 시트가 포함될 수 있으며 이는 데이터베이스와 테이블의 관계와 유사함
- 시트에는 다른 데이터가 저장되어 있지만 각 시트는 서로 복사하거나 연결될 수 있듯이, 데이터베이스에서도 테이블은 서로 다른 테이블끼리 복사하거나 연결될 수 있음
- 엑셀 시트는 행과 열로 구성되어 있고 이는 테이블과 매우 유사함
- 우리가 보통 사용하는 데이터베이스는 거의 엑셀과 같은 형식을 가지고 있다고 생각하면 편함 (다 그런건 아님)
2. SELECT문의 구성과 기본적인 문법
2.1 SELECT문
SELECT문은 데이터를 검색하고 추출할 때 사용하는 가장 기본적인 구문임- 데이터베이스에서 하나 이상의 테이블에서 데이터를 가져오고 반환함
SELECT [열1], [열2], ... [열n] FROM [테이블 이름] WHERE [조건]
SELECT: 가져올 열(column)을 지정합니다. *을 사용하면 모든 열을 선택합니다.FROM: 데이터를 가져올 테이블 이름을 지정합니다.WHERE: 가져올 데이터의 조건을 지정합니다. WHERE절은 선택적으로 사용할 수 있습니다.
- 위 엑셀을 데이터베이스라고 가정하면 아래와 같은 SELECT문을 작성할 수 있음
-- 임시 테이블 생성
CREATE TABLE #MYTABLE (
id INT,
name VARCHAR(50),
age INT,
gender CHAR(1)
);
INSERT INTO #MYTABLE (id, name, age, gender)
VALUES (1, 'John', 25, 'M')
INSERT INTO #MYTABLE (id, name, age, gender)
VALUES (2, 'Jane', 30, 'F')
INSERT INTO #MYTABLE (id, name, age, gender)
VALUES (3, 'Sam', 27, 'M')
INSERT INTO #MYTABLE (id, name, age, gender)
VALUES (4, 'Jenny', 23, 'F');
INSERT INTO #MYTABLE (id, name, age, gender)
VALUES (5, 'Robin', 28, 'M')
CREATE TABLE #MYSALARY (
id INT,
salary INT
);
INSERT INTO #MYSALARY (id, salary)
VALUES (1, 50000)
INSERT INTO #MYSALARY (id, salary)
VALUES (2, 60000)
INSERT INTO #MYSALARY (id, salary)
VALUES (3, 55000)
INSERT INTO #MYSALARY (id, salary)
VALUES (4, 45000);SELECT NAME, AGE
FROM #MYTABLE
---
SELECT NAME, AGE
FROM #MYTABLE
WHERE GENDER = 'M'- 위 SELECT문은 이름과 나이를 추출하는 구문임
- 아래 SELECT문은 성별이 M인 사람들의 이름과 나이를 추출하는 구문임
3. WHERE 조건절 이용하기 - IN, LIKE
3.1 IN 연산자
- WHERE절은 특정한 데이터만을 가져오기 위해 사용됨
- WHERE절에 여러 조건을 조합해서 사용할 수 있으며 그 중 IN, LIKE는 자주 사용되는 연산자임
IN연산자는 WHERE절에서 여러 개의 값을 비교할 때 사용됨
SELECT * FROM employees WHERE department IN ('Sales', 'Marketing')- 위처럼 작성하게 되면 employees 테이블에서 department가 Sales나 Marketing에 속한 데이터를 반환함
SELECT * FROM employees WHERE department NOT IN ('Sales', 'Marketing')- 위처럼 작성하게 되면 반대로 Sales나 Marketing에 속하지 않는 데이터만을 반환함
3.2 LIKE 연산자
LIKE연산자는 WHERE절에서 문자열 비교를 할 때 사용함- '='과 다르게 문자열 비교에만 사용되고 와일드카드 문자를 사용할 수 있음
SELECT * FROM employees WHERE employee_name LIKE '%an%'- 와일드카드 % 을 사용했는데 이는 0개 이상의 문자를 나타냄. 즉 위 쿼리의 결과는 이름 중에 an이 포함된 모든 데이터를 반환함 (
Ian,~~~an~~~~)
SELECT TOP 5 * FROM item WHERE item_nm LIKE N'%생수%'- MSSQL에서 한글을 LIKE를 이용해서 조회할 때는 N을 붙여야 함. 이는 MSSQL에서는 ASCII 문자를 사용하지만 한글은 유니코드 문자를 사용해야 하기 때문. 그냥 외워야 함
- 위 쿼리를 수행하면 상품명에
생수란 단어가 포함되어 있는 데이터를 반환함
4. DISTINCT, TOP, ORDER BY 사용하기
4.1 DISTINCT
DISTINCT는 중복된 값을 제거하여 유일한 값을 반환하는 키워드임. 쿼리 결과에서 중복된 값을 제거하고 한 번만 나타나는 값을 반환함
SELECT DISTINCT NAME FROM #MYTABLE- 위와 같은 쿼리는 #MYTABLE에서 NAME 컬럼의 값들을 중복을 제거한 후 반환함
DISTINCT를 사용하면 쿼리 성능에 문제가 있을 수 있음, 지나치게 쿼리 수행시간이 길어질 수 있음
SELECT문 안에서 사용되는 컬럼에만 영향을 미침. 다른 컬럼에 중복이 있어도 이는 무시함
NULL값 고려 안 함. NULL값이 중복된 경우에도 하나의 값으로 취급되지 않음
JOIN과 같이 사용하는 경우 결과를 확인해야 함
4.2 TOP
TOP은 쿼리 결과에서 상위 N개의 값을 반환하는 키워드임. 비슷한 키워드로 LIMIT가 있음 (빅쿼리에서는LIMIT사용)
SELECT TOP 5 * FROM item WHERE item_nm LIKE N'%생수%'- 위 구문은 item 에서 중간에 '생수'가 포함된 ITEM_NM을 반환하는 쿼리임
- 이 때 TOP 5의 의미는 이 중 상위 5개의 값만 반환하라는 의미임
- 큰 테이블의 구성을 파악할 시 이를 사용할 수 있음
- 이러한 TOP과 같이 자주 같이 사용되는 구문이
ORDER BY임
4.3 ORDER BY
ORDER BY는 SELECT 쿼리 결과의 정렬 순서를 지정하는 키워드임
SELECT NAME FROM #MYTABLE ORDER BY AGE DESC- 위 쿼리는
#MYTABLE에서AGE가 높은 순서대로NAME을 반환함 ORDER BY뒤에 붙은 컬럼명으로 데이터를 정렬하여 반환하며 디폴트는 오름차순, 컬럼명 뒤에 DESC가 붙으면 내림차순임- SELECT 문에 없는 컬럼으로도 정렬할 수 있음
- SELECT 문에 있는 컬럼으로 정렬하는 경우에는 숫자로 컬럼명을 대신할 수 있음
SELECT NAME, AGE FROM #MYTABLE ORDER BY 2 DESC- SELECT 에서 두번째 컬럼이 AGE 이므로 ORDER BY 2 DESC라고 적으면 AGE로 내림차순 정렬한 결과를 반환함
- TOP과 같이 사용하면 우선 데이터를 정렬한 후, 상위 N개의 값을 반환할 수 있음
02. JOIN
1. JOIN의 개념과 종류
1.1 JOIN 개념
JOIN은 두 개 이상의 테이블을 연결하여 데이터를 검색하는 방법임- JOIN은 크게
INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN등이 있음
1.2 INNER JOIN
- 두 개의 테이블에서 공통된 값을 기준으로 데이터를 연결함
- 교집합과 같이 공통된 값을 가진 데이터만을 가져올 수 있음
- INNER를 생략하고 JOIN만 작성할 수 있음
SELECT *
FROM 테이블1
JOIN 테이블2
ON 테이블1.컬럼1 = 테이블2.컬럼21.3 LEFT OUTER JOIN
- 왼쪽 테이블의 모든 레코드와 오른쪽 테이블에서 공통된 값을 기준으로 레코드를 연결함
- 오른쪽 테이블에서 공통된 값이 없는 경우 NULL 값을 반환함
SELECT *
FROM 테이블1
LEFT OUTER JOIN 테이블2
ON 테이블1.컬럼1 = 테이블2.컬럼21.4 RIGHT OUTER JOIN
- 오른쪽 테이블의 모든 레코드와 왼쪽 테이블에서 공통된 값을 기준으로 레코드를 연결함
- 왼쪽 테이블에서 공통된 값이 없는 경우 NULL 값을 반환함
SELECT *
FROM 테이블1
RIGHT OUTER JOIN 테이블2
ON 테이블1.컬럼1 = 테이블2.컬럼22. 특이한 JOIN 사용해보기
2.1 CROSS JOIN
CROSS JOIN은 두 테이블의 모든 가능한 조합을 반환함- CARTESIAN PRODUCT라고 칭하기도 함
- 테이블이 작고 행 수가 적을 때는 유용하지만, 대규모 테이블의 경우에는 너무 많은 조합이 생성되어 성능 문제를 일으킬 수 있음
SELECT *
FROM table1
CROSS JOIN table22.2 SELF JOIN
SELF JOIN은 하나의 테이블 내에서 자체적으로 조인하는 것을 의미함- 부모-자식 관계나 계층적 데이터 구조에서 많이 사용됨
SELECT a.column1, b.column2
FROM table a
JOIN table b ON a.column3 = b.column3- 위처럼 같은 테이블을 두 번 사용하여 조인을 수행하게 됨
03. 함수 1
1. 집계함수에 대한 소개 및 사용 방법
1.1 집계함수 소개
- 집계함수는 특정한 데이터의 집합을 하나의 값으로 반환하는 함수임
COUNT, SUM, AVG, MAX, MIN등이 존재함COUNT함수는 지정한 열에서 NULL 값을 제외한 행의 개수를 반환함
SELECT COUNT(*) FROM 테이블SUM함수는 지정한 열의 모든 행의 값을 더한 총합을 반환함
SELECT SUM(SALES) FROM 테이블AVG함수는 지정한 열의 모든 행의 값을 평균화한 결과를 반환함
SELECT AVG(SALES) FROM 테이블MAX함수는 지정한 열의 모든 행 중 가장 큰 값을 반환함
SELECT MAX(SALES) FROM 테이블MIN함수는 지정한 열의 모든 행 중 가장 작은 값을 반환함
SELECT MIN(SALES) FROM 테이블- 이러한 집계 함수는
GROUP BY절과 함께 사용하여 특정 열 기준으로 데이터를 그룹화한 후 그룹 별로 결과를 반환할 수 있음
SELECT id, COUNT(order)
FROM ord
GROUP BY id2. GROUP BY, HAVING 이해하기
2.1 GROUP BY, HAVING 사용하기
HAVING절은 WHERE 절과 비슷하지만, GROUP BY 절에 의해 그룹화된 결과 집합에서 행을 필터링하는 역할을 함
SELECT title, AVG(salary) as avg_salary
FROM employees_table
WHERE title = 'manager'
GROUP BY title
HAVING AVG(salary) > 50000- 위처럼 WHERE은 employees_table에서 직급이 manager인 로우를 대상으로 하겠단 의미이고, HAVING은 title로 그룹화된 여러 그룹 중 AVG(SALARY)가 50000 이상인 경우를 보겠다는 의미임
2.2 유의사항
- GROUP BY 절에는 SELECT 문에서 지정된 열 이외에도 그룹화 대상 열을 추가로 지정할 수 있음
- HAVING 절에서 지정하는 조건은 집계 함수를 사용한 결과에 대해 필터링함. 즉, HAVING 절에서 참조하는 열은 SELECT 문 열이거나 집계 함수로 계산된 값이 대상임
04. 서브쿼리, CTE
1. 서브쿼리 구성하기
1.1 Subquery 설명
- 서브쿼리는 다른 쿼리의 일부로 사용되는 쿼리임
- 메인쿼리보다 먼저 수행되며, 서브쿼리 수행 후 메인쿼리의 결과가 반환됨
- 다양한 절에서 사용될 수 있음
SELECT column1, column2, column3
FROM table1
WHERE column1 IN (SELECT column1 FROM table2 WHERE column2 = 'value')
--------------------
SELECT column1, column2, column3
FROM (SELECT column1, column2, column3 FROM table1 WHERE column1 = 'value') AS subquery
--------------------
SELECT column1, column2, (SELECT COUNT(column3) FROM table2 WHERE column2 = 'value') AS count
FROM table1- 순서대로 WHERE 절, FROM 절, SELECT 절에서 서브쿼리를 사용했는데 이처럼 다양한 방법으로 사용할 수 있음
- 서브쿼리는 32개까지 중첩할 수는 있으나 성능저하를 고려해야 함
1.2 WHERE 절에서 사용할 때 유의사항
- WHERE에서 사용할 경우 결과가 하나 이상의 값이 반환될 수 있는데 이 때는 IN, EXIST, ANY, ALL 등의 연산자를 사용해야 함
SELECT column1, column2, column3
FROM table1
WHERE EXISTS (SELECT * FROM table2 WHERE table1.column1 = table2.column1)
--------------------
SELECT column1, column2, column3
SELECT column1, column2, column3
FROM table1
WHERE column1 = ANY (SELECT column1 FROM table2 WHERE column2 = 'value')
--------------------
SELECT column1, column2, column3
FROM table1
WHERE column1 = ALL (SELECT column1 FROM table2 WHERE column2 = 'value')- 순서대로
EXIST, ANY, ALL의 사용 예시임. EXIST는 서브쿼리가 반환하는 결과가 존재하는지 여부를 검사함. 서브쿼리에서 반환된 값이 존재하면, 참을 반환함ANY는 서브쿼리에서 반환된 값 중 하나라도 메인쿼리의 조건식과 일치하면 참을 반환함ALL은 서브쿼리에서 반환된 모든 값이 메인쿼리의 조건식과 일치하면 참을 반환함
1.3 JOIN과 비교
-
서브쿼리는 작은 데이터 집합을 추출할 때 사용함. 반면 JOIN은 더 큰 데이터 집합을 추출하는 데 사용함
-
서브쿼리는 다음과 같을 때 사용하기에 더 적합함
- 메인 쿼리와 별개로 작은 데이터 집합을 추출해야 할 때
- 메인 쿼리의 실행 결과에 영향을 미치지 않으면서 데이터를 추출해야 할 때
- 복잡한 조건식을 사용해야 할 때
-
JOIN은 다음과 같을 때 사용하기에 적합함
- 두 개 이상의 테이블을 조인해서 더 큰 데이터 집합을 추출해야 할 때
- 테이블 간 관계를 명확하게 이해하고 있어야 할 때
- 여러 개의 조건식이 필요한 경우
2. CTE 구성하기
2.1 CTE 설명
CTE는 Common Table Expression, 즉 공통 테이블 표현식을 의미함- CTE를 사용하면 복잡한 쿼리를 작성 시 중간 결과를 저장하고 재활용할 수 있으며, 가독성 높아짐
- CTE에서는 하나의 SELECT 문에서만 사용할 수 있으며, WITH 절 뒤에 오는 SELECT 문에서만 참조할 수 있음
WITH cte AS (
SELECT column1, column2, ...
FROM table_name
WHERE condition
)
SELECT *
FROM cte;- 위처럼 쿼리를 작성하면 cte라는 CTE를 생성하게 되고 이를 SELECT문에서 참조하여 결과를 반환하게 됨
- 서브쿼리를 사용하는 것처럼 이를 활용할 수 있음
2.2 유의사항
- CTE에서 정의한 열은 CTE 내에서만 사용할 수 있으며, 다른 쿼리에서는 참조할 수 없음
- CTE를 사용할 때는 성능에 대한 고려가 필요함
2.3 서브쿼리와 비교하기
- CTE는 중간 결과를 재사용하거나 쿼리의 가독성을 높일 때 좋고, 서브쿼리는 데이터 서브셋을 필터링하거나 조인할 때 유용함
-- 1. CTE
WITH sales_info AS (
SELECT
customer_id,
SUM(sale_amount) AS total_sales
FROM sales
GROUP BY customer_id
)
SELECT
customer_id,
total_sales
FROM sales_info
WHERE total_sales > 10000;
-- 2. Subquery
SELECT
customer_id,
total_sales
FROM (
SELECT
customer_id,
SUM(sale_amount) AS total_sales
FROM sales
GROUP BY customer_id
) AS sales_info
WHERE total_sales > 10000;- 위 두 쿼리는 결과적으로는 동일하지만, 사용한 방식이 각각 다름
- CTE를 사용하면 중복 코드를 줄이고 가독성을 높일 수는 있지만, 대용량 데이터 처리에는 부적합함
- 서브쿼리는 대용량 데이터 처리에는 유리하지만, 복잡한 쿼리의 경우 가독성이 떨어질 수 있음
05. 함수 2
1. WINDOW FUNCTION
1.1 WINDOW FUNCTION 설명
- 집계함수처럼 데이터 집계 및 분석 작업을 수행하는 함수임
- 윈도우 함수는 일반적으로
OVER()절을 사용하여 정의됨
<윈도우 함수> OVER ([PARTITION BY <열>]
[ORDER BY <열> [ASC|DESC], ...]) - PARTITION BY : 윈도우를 분할할 열을 지정함. 해당 절을 사용하면 각 윈도우 함수가 분할된 데이터 집합에서 별도로 계산됨
- ORDER BY : 윈도우를 정렬할 열을 지정함. 해당 절을 사용하면 ROWS BETWEEN 절을 사용하여 특정 범위 내 행에 대한 계산을 제한할 수 있음
1.2 WINDOW FUNCTION 예시
ROW_NUMBER(): 각 행에 대해 일련 번호를 지정함RANK(): 순위를 지정함. 동일한 값을 가진 행은 같은 순위를 갖게 됨DENSE_RANK(): 순위를 지정함. 동일한 값을 가진 행은 같은 순위를 갖게 되지만, 순위 사이에 빈 순위는 없음.NTILE(): 결과 집합을 동일한 크기의 그룹으로 분할함.LAG(): 이전 행의 값을 가져옴.LEAD(): 다음 행의 값을 가져옴.FIRST_VALUE(): 윈도우 내 첫 번째 행의 값을 반환함.LAST_VALUE(): 윈도우 내 마지막 행의 값을 반환함.
SELECT name, score,
ROW_NUMBER() OVER(ORDER BY score DESC) AS rank,
RANK() OVER(ORDER BY score DESC) AS rank2,
DENSE_RANK() OVER(ORDER BY score DESC) AS rank3,
NTILE(3) OVER(ORDER BY score DESC) AS group,
LAG(score, 1) OVER(ORDER BY score DESC) AS prev_score,
LEAD(score, 1) OVER(ORDER BY score DESC) AS next_score,
FIRST_VALUE(score) OVER(ORDER BY score DESC) AS first_score,
LAST_VALUE(score) OVER(ORDER BY score DESC) AS last_score
FROM students
SELECT
ROW_NUMBER() OVER (ORDER BY Salary DESC) AS RowNum,
FirstName,
LastName,
Salary
FROM
Employees
SELECT
RANK() OVER (ORDER BY Sales DESC) AS Rank,
FirstName,
LastName,
Sales
FROM
Salespeople
SELECT
DENSE_RANK() OVER (ORDER BY Sales DESC) AS DenseRank,
FirstName,
LastName,
Sales
FROM
Salespeople
SELECT
department,
name,
salary,
AVG(salary) OVER(PARTITION BY department) as avg_salary_per_dept
FROM employees;- 위처럼 PARTITION BY 절을 사용하게 되면 부서별 평균 급여를 계산하도록 지정됨
- 즉, PARTITION BY 는 데이터를 분할하는 역할을 하며, 해당 컬럼 기준으로 데이터를 분할하여 분할된 그룹 단위로 윈도우 함수가 적용됨
1.3 유의사항과 응용
- 윈도우 함수는 일반적으로 복잡하고 처리 속도가 느릴 수 있기 때문에 성능이 중요하거나 빅데이터 처리를 할 때는 다른 방안을 고려해봐야함
- 윈도우 함수는 중첩해서 사용할 수 있음
- 윈도우 함수를 이용해서 이동 평균, 누적 합계 등을 계산할 수 있음
