
00. 데이터 정규화 vs 비정규화
일반적으로 SQL을 사용하는 사용자는 정규화된 데이터에 익숙할 것입니다. 하지만 빅쿼리는 데이터 비정규화를 지향하는 데이터 웨어하우스 서비스입니다. 이에 따라 데이터 정규화와 비정규화의 개념을 먼저 정리하고, 빅쿼리의 특징을 잘 보여줄 수 있는 데이터 타입인 배열과 구조체에 대해 알아보겠습니다.
데이터 정규화는 제1정규화, 제2정규화, 제3정규화로 크게 나뉩니다. 제1정규화는 한 칸에는 한 데이터만 넣는 것을 의미합니다. 즉, 한 컬럼에는 하나의 데이터만 존재하도록 하는 작업을 말하며 이러한 조건을 만족한 테이블을 제1정규형이라고 합니다. 제2정규화는 특정 테이블의 주제와 관련없는 컬럼 및 데이터를 다른 테이블로 옮기는 것을 의미합니다. 예를 들어, 고객의 주문 데이터를 정리하고 있는 테이블이 있다면 해당 테이블에는 고객의 여러 정보가 함께 있을 수 있습니다. 하지만 이러한 정보를 분리하여 회원정보 테이블과 주문정보 테이블을 나누는 것이 제2정규화입니다. 마지막으로 제3정규화는 일반 컬럼에만 종속된 컬럼을 다른 테이블로 관리하는 것을 의미합니다.
하지만 빅쿼리는 데이터 처리 성능을 높이기 위해 데이터 비정규화를 적극적으로 사용합니다. 일반적인 관계형 데이터베이스 (Mysql, MSSQL, PostgreSQL 등)에서는 데이터 무결성을 확보하기 위해 정규화를 수행하지만, 빅데이터 분석 환경을 제공하는 빅쿼리에서는 비정규화를 통해 데이터 처리 성능을 높이는 것입니다. 이러한 특징으로 인해 빅쿼리에서는 SQL에서 볼 수 없는 데이터 자료형인 배열과 구조체를 사용할 수 있게 되었습니다. 아래에서는 이러한 자료형에 대해 자세히 알아보겠습니다.
01. 배열(Array)
1) Array란?
먼저 배열(array)은 하나의 컬럼에 여러 데이터를 저장하는 자료형입니다. 파이썬에서 볼 수 있는 리스트와 유사한데 하나의 배열에는 동일한 자료형이 들어가야 하는 특징이 있습니다. 즉, ['로빈', '형석', '현철'] 는 가능해도 ['강훈', 29 ] 은 불가능하다는 것을 의미합니다.
SELECT
[1,2,3] AS array_sample, 1 AS int_value
UNION ALL
SELECT
[4,5,6] AS array_sample, 2 AS int_value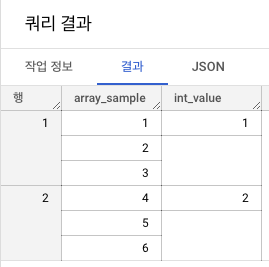
위 그림에서 array_sample을 보면 int_value에 비해 한 행에 여러 데이터가 들어가 있는 것을 확인할 수 있습니다. 이처럼 한 행에 여러 데이터가 들어가 있는 데이터 형식을 array 이라고 합니다.
2) Array를 생성하는 법
이러한 배열을 빅쿼리에서 생성하는 법에는 약 4가지가 있습니다.
- 직접
[]로 감싸서 배열을 생성하는 방법 - 데이터타입과
[]로 배열을 생성하는 방법 GENERATE_ARRAY로 생성하는 방법ARRAY_AGG로 생성하는 방법
아래는 생성하는 법의 실제 예시입니다.
-- 직접 `[]`로 감싸서 배열을 생성하는 방법
INSERT INTO table_name (array_column_name)
VALUES ([1, 2, 3]);
-- 데이터타입과 `[]`로 배열을 생성하는 방법
SELECT ARRAY<INT64>[1,2,3] AS int_array
-- `GENERATE_ARRAY`로 생성하는 방법
SELECT generate_array(1, 10, 2) AS even_numbers;
-- `ARRAY_AGG`로 생성하는 방법
SELECT ARRAY_AGG(name) as names
FROM my_table;
위에서부터 보면 데이터를 []로 감싸서 생성하는 방식입니다. 파이썬에서 리스트를 생성할 때와 동일한 형태를 보이며, 두 번째 방식도 배열 안에 들어가는 데이터 형식을 지정해주는 유사한 방식입니다. 세 번째 방식은 GENERATE_ARRAY(시작시점, 종료시점, 간격)으로 생성하는 형식으로 파이썬의 range(start, end, step)과 매우 유사합니다. 네 번째 방식은 테이블 내에 있는 데이터를 사용해서 array를 생성할 때 사용하는 방법입니다.
3) Array의 사용 예시
배열의 특정값에 접근하는 방법으로는 offset, ordinal을 사용하는 방법이 있습니다.
WITH example_array AS (
SELECT ["apple", "banana", "grape", "watermelon", "strawberry"] AS my_array
)
SELECT
my_array[offset(1)] AS second_element,
my_array[offset(4)] AS fifth_element,
my_array[ordinal(2)] AS second_element_ordinal,
my_array[ordinal(5)] AS fifth_element_ordinal
FROM
example_array;

offset은 순서가 0부터, ordinal은 순서가 1부터 시작되는 걸 확인할 수 있습니다
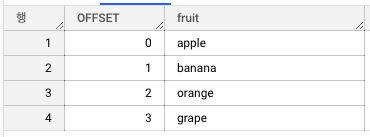
WITH data AS (
SELECT ['apple', 'banana', 'orange', 'grape'] AS fruits
)
SELECT OFFSET, fruit
FROM data, UNNEST(fruits) AS fruit WITH OFFSET
UNNEST 와 WITH OFFSET을 같이 사용하면 해당 배열의 순서를 확인할 수 있습니다.
이러한 기능 외에도 ARRAY_REVERSE를 사용해서 배열을 역순으로 생성할 수 있고 ARRAY_LENGTH를 사용해서 배열의 길이를 확인할 수 있습니다.
4) Array의 응용 예시
빅쿼리에서 array 자료형은 여러 개의 값들을 하나의 변수에 담아 처리할 수 있는 유용한 데이터 타입입니다. 예를 들어, 하나의 테이블 안에서 여러 개의 데이터 값을 모아서 저장하고 분석하는 작업을 할 때 매우 유용합니다.
예를 들어, 여러 개의 상품 카테고리가 있는 이커머스에서 각 카테고리별로 판매량을 계산하려고 할 때, 각 상품의 카테고리 정보를 배열로 저장하고 해당 카테고리의 판매량을 배열에 누적하는 방식으로 분석할 수 있습니다. 이렇게 배열을 사용하면 복잡한 쿼리 없이도 간단하게 원하는 데이터를 추출할 수 있습니다.
또한, 배열을 사용하면 여러 개의 값들 중에서 특정 값을 추출하는 작업도 매우 용이해집니다. 배열에서 특정 값을 추출하는 방법은 offset, ordinal, unnest와 같은 함수를 이용하여 가능합니다. 이를 응용하면 특정 조건에 해당하는 값을 추출하거나, 배열 안에서 최대, 최소값을 구하는 등 다양한 작업을 할 수 있습니다.
종합적으로, 배열은 여러 개의 값을 효율적으로 저장하고 분석할 수 있는 유용한 데이터 타입입니다. 데이터 분석 작업에서 여러 개의 값을 저장하고 처리해야 하는 경우에 활용하면 좋습니다.
02. 구조체(Struct)
01) struct란?
array가 파이썬의 리스트와 유사했다면 struct는 파이썬의 사전 자료형과 비슷한 특징을 가지고 있습니다.
SELECT
(1,2,3) AS struct_example
Struct는 array와 유사하게 한 행에 여러 데이터를 저장하는 형식이지만, 그 내부에 여러 하위 필드가 있는 복합 데이터 타입입니다. 위의 그림에서 보이는 것처럼, struct는 하나의 필드에 하위 필드 3개가 포함될 수 있습니다.
2) Struct를 생성하는 법
구조체는 배열과 동일하게 생성하는 방식이 다양합니다
- 직접
()로 감싸서 struct을 생성하는 방법 - 데이터타입과
()로 struct을 생성하는 방법 - 데이터타입을 바로 선언하며 struct을 생성하는 방법
- 데이터타입 선언 없이 하위 필드명만 선언하는 방법
아래는 생성하는 법의 실제 예시입니다.
-- 직접 `()`로 감싸서 배열을 생성하는 방법
SELECT (23, 'Robin', TRUE) AS my_struct;
-- 데이터타입과 `()`로 배열을 생성하는 방법
SELECT STRUCT<
id INT64,
name STRING,
is_active BOOL>
(23, 'Robin', TRUE) AS my_struct;
-- 데이터타입을 바로 선언하며 struct을 생성하는 방법
SELECT STRUCT<first_name STRING, last_name STRING, id INT64>('robin', 'hwangbo', 23) AS struct_test
-- 데이터타입 선언 없이 하위 필드명만 선언하는 방법
SELECT STRUCT('robin' as first_name, 'hwangbo' as last_name, DATE('1994-08-23') as birth_date);
아래는 struct를 생성하는 데 응용 방법입니다
- strcut 안 struct
- 테이블을 불러와서 struct을 생성하는 방법
-- strcut 안 struct
SELECT STRUCT<
id INT64,
name STRUCT<
first_name STRING,
last_name STRING
>,
is_active BOOL
>
(1, STRUCT('Robin', 'Hwangbo'), TRUE) AS my_struct;
-- 테이블을 불러와서 struct을 생성하는 방법
WITH my_table AS (
SELECT 1 AS id, 'Robin' AS name, TRUE AS is_active UNION ALL
SELECT 2 AS id, 'Hebe' AS name, FALSE AS is_active UNION ALL
SELECT 3 AS id, 'Rebe' AS name, TRUE AS is_active
)
SELECT STRUCT(id, name, is_active) AS my_struct
FROM my_table;3) Struct의 사용 예시
빅쿼리에서 struct 자료형은 다른 데이터 타입들과 함께 사용되어, 테이블의 특정 필드에 여러 데이터를 묶어서 저장하고자 할 때 주로 사용됩니다. 예를 들어, 특정 테이블에 고객의 정보를 저장하는 경우, 각 고객의 이름, 나이, 성별, 이메일 등의 정보를 각각 따로 저장하는 것이 아니라, 이러한 정보를 하나의 구조체로 묶어서 저장하고자 할 때 struct 자료형을 사용할 수 있습니다.
struct는 데이터 분석에서 매우 유용하게 활용됩니다. 예를 들어, 여러 개의 변수가 있는 데이터셋에서 특정 필드의 값을 비교하는 등의 작업을 수행할 때, struct를 사용하면 더 쉽고 간편하게 데이터에 접근할 수 있습니다.
struct를 사용하면 데이터의 가독성이 높아지고, 필드에 접근하는 것이 편리해집니다. 또한 struct를 활용하여 여러 필드를 하나의 필드로 묶어서 저장할 수 있기 때문에, 테이블의 구조를 간결하게 유지할 수 있습니다. 이를 통해 쿼리 작성 시 가독성이 높아지며, 복잡한 연산을 수행할 때도 효율적으로 처리할 수 있습니다.
특히나 json형식의 데이터를 읽는 경우에 struct가 유용하게 사용될 수 있습니다. json 문자열을 struct로 변환해서 데이터 분석을 더욱 용이하게 할 수 있습니다.
03. 배열과 구조체 활용하기
데이터 분석 작업을 수행하다 보면, array나 struct 자료형 전체가 아닌 내부에 들어있는 데이터에 대해 접근해야 할 경우가 있습니다. 이런 상황에서 유용한 함수 중 하나가 UNNEST입니다. UNNEST 함수는 array나 struct와 같은 복잡한 데이터 형식을 해제하여 데이터에 포함된 값을 별도의 테이블 형태로 반환합니다. 이를 통해, 데이터셋에서 내부 값에 대한 접근이 더욱 용이해집니다.
WITH example_table AS (
SELECT ['a', 'b', 'c'] AS array_column UNION ALL
SELECT ['d', 'e'] AS array_column UNION ALL
SELECT ['f'] AS array_column
)
SELECT
array_column_value
FROM
example_table,
UNNEST(array_column) AS array_column_value
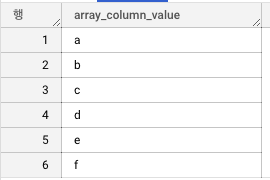
위를 실행하게 되면 UNNEST안에 있는 배열이 밖으로 나와서 일반적인 데이터 형식으로 변하게 됩니다. 이처럼 UNNEST는 배열, 구조체를 일반적인 데이터 형식으로 바꿔주는 함수인데 아래는 이러한 함수의 실제 활용 예시입니다.
WITH sample AS (
SELECT 1 as id, ['apple', 'banana', 'orange'] as fruit_list UNION ALL
SELECT 2 as id, ['grape', 'mango', 'papaya'] as fruit_list
)
SELECT id, fruit
FROM sample, UNNEST(fruit_list) as fruit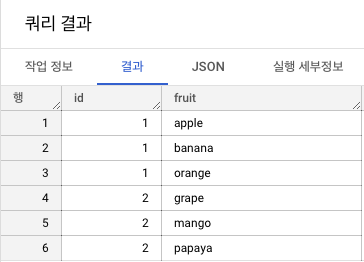
이렇듯 빅쿼리에서는 array나 struct와 같은 자료형을 사용할 수 있습니다. 이러한 자료형을 UNNEST 함수를 이용해 쉽게 조회할 수 있습니다. UNNEST 함수는 array나 struct를 각각 하나의 로우로 변환하여 반환합니다. 이러한 결과를 기존 테이블과 크로스 조인하여 데이터를 조회할 수 있습니다. 이렇게 UNNEST 함수를 사용하면 array나 struct 내부에 있는 데이터에 대해 조건을 걸어 조회할 수 있습니다.
빅쿼리에서는 이러한 자료형을 사용할 수 있기 때문에 빅쿼리에서 데이터를 더욱 효과적으로 다룰 수 있습니다.
Reference.
BigQuery Guide Book - 빅쿼리 가이드북
BigQuery UNNEST, ARRAY, STRUCT 사용 방법
구글 빅쿼리 완벽 가이드 - 발리아파 락쉬마난, 조던 티가니 저/변성윤, 장현희 역
