USENIX 13th (OSDI '18)
Pengfei Zuo, Yu Hua, and Jie Wu,
Huazhong University of Science and Technology
Introduction
DRAM technology는 density scaling과 power leakage라는 심각한 문제들에 직면하고 있다. 따라서 미래의 memory system 후보로 non-volatile momory (NVM) technology가 떠오르게 되었다. 그러나 NVM은 제한된 내구성과 낮은 write performance의 문제점에 직면하고 있으며, 더 심각한 점은 기존 방식으로 data를 indexing 하는 것의 비효율성이다.
이를 해결하기 위해 그동안의 연구들은 tree-based index structure들을 고안하였지만 그것은 평균적인 time complexity가 O(log(N))으로, data 구조의 크기인 N에 영향을 받는다. 그와 달리 hashing-based index structure은 flat data structure로, constant lookup time complexity, 즉 O(1)을 만족시킬 수 있다. 따라서 이 논문에서는 hashing 기반의 index structure에 대해 연구를 진행하였다.
Hashing index structures in persistent memory는 3가지 문제점에 직면하게 된다.
1. High Overhead for Consistency Guarantee
NVM이 memory bus에 directly accessed 하게 되어 발생한다.
2. Performance Degradation for Reducing Writes
NVM의 메모리 쓰기는 제한된 내구성을 소모하며 읽기보다 더 높은 latency와 energy를 유발하고, cache line flush나 memory fence, 혹은 logging 또는 CoW 작업도 늘어나 시스템 성능이 크게 저하되므로 wirte reduction이 필요하다.
3. Cost Inefficiency for Resizing Hash Table
Load factor 가 threshold 에 도달하거나 insertion failure 이 발생하면 resizing 필요한데, 이때 기존의 방식대로라면 O(N)만큼의 시간이 걸리고 N번의 추가적인 Insertion operation을 수행해야한다. 이때 N은 기존 hash table의 크기이다.
이러한 문제들의 해결하기 위해 이 논문에서는 a write-optimized and high-performance hashing index scheme with low-overhead consistency guarantee and cost-efficient resizing for persistent memory 인 level hashing을 제안한다.
Level hashing의 속성으로는 Low-overhead Consistency Guarantee, Write-optimized Hash Table Structure, Cost-efficient Resizing, 그리고 Real implementation and Evaluation이 있다.
Background and Motivation
Persistent systems도 일반적으로 CPU cache와 같은 volatile storage component들을 가지고 있기 때문에, data consistency에 문제가 발생할 수 있다.
NVM에서 data consistency를 보장하기 위해서는 memory write의 순서를 지켜야하는데, CPU와 메모리 컨트롤러가 이들을 reorder할 가능성이 있으므로 cache line flush 또는 memory fence가 필요하다. 그러나 이들은 system performance overhead를 발생시키므로 write를 줄이는 것이 중요하다.
더 나아가서 atomic memory write 기준보다 큰 data를 넣을 때는 logging이나 CoW가 필요하고 각 update마다 2번씩 write 하므로 이 또한 system의 성능을 해친다.
- CLFLUSH : dirty cache line을 cache에서 제거하고 NVM에 writes
- FENCE : memory fence를 발행하여 그 후에 memory에 access하려고 하는 instructions 들을 fence가 끝날 때까지 막는 역할
기존의 hashing schemes로는 chained hashing과 open addressing, 그 중에서도 bucketized cuckoo hashing (BCH) 가 있다.
- BCH는 f개의 hashing functions와 f 개의 bucket locations 를 가지고 있고, 각 bucket은 여러 slot들을 가지고 있다. 여기 논문에서는 f = 2를 사용하여 2개의 hash function을 이용한다.
- Chained hashing은 modifications of pointers로 인해 추가적인 NVM write를 발생시키고 BCH의 경우 insertion operation 시의 빈번한 evicting과 rewriting으로 인한 cascading NVM write를 발생시킨다.
무엇보다 기존의 hashing scheme들은 data consistency를 고려하지 않는다.
그 외에도 NVM write를 줄이는데 중점을 둔 PCM-friendly Hash Table (PFHT)와 Path hashing이 있다.
- PFHT는 insert 시에 단 한번의 eviction만을 하도록 BCH를 변형한 것으로, 이를 통해 NVM writes를 줄일 수 있다. 하지만 PFHT는 item insert에 실패할 경우 stash에 그것을 넣게 되고, 따라서 hash table에서 item을 찾는 것에 실패할 경우 Linear하게 search 해야한다.
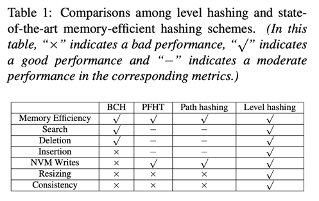
Table 1 은 level hashing을 state-of-the-art hashing schemes (BCH, PFHT, path) 비교한 것이다.
Resizing에 관해 간략하게 이야기하자면, 기존의 resizing 기법은 out-of-place resizing으로 O(N)만큼의 시간을 소요하며 search나 deletion을 할 경우 old와 new hash table을 모두 봐야하는 문제점이 있었다. 따라서 이 논문에서는 이러한 문제점을 해결하기 위한 방법을 제시한다.
일반적으로 새로운 hash table은 기존의 2배인데, 그 이유는 initial size가 2의 지수승이며, 이를 통해 shift 연산으로 간단하게 modulo operation을 수행할 수 있기 때문이다.
The Level Hashing Design
Design Decision
먼저 Level Hashing Design은 write-optimized hash table structure로, 4개의 design decision들을 가지고 있다.
- 첫번째 decision는 각 bucket 당 여러개의 slot을 가지고 있는 것으로, 이는 실제로 쓰이는 workload들의 특성을 고려한 것이다. 이를 통해 cache의 효율성을 높이고 메모리 접근의 수를 줄일 수 있다.
- 두번째 decision은 각 key 마다 2개의 hash location을 가지는 것이다. Low load factor의 문제점을 해결하기 위해 고안된 것으로, 새로운 kv item은 2 개의 location 중 더 적게 load된 bucket으로 들어간다.
- 세번째 decision은 공유 기반의 2 level 구조이다. Top level과 Bottom level로 구분되며 top level은 hash function을 통해 접근될 수 있는 level이고 bottom level은 top level에서 collision이 발생했을 때 추가로 저장할 수 있는 standby position이다. 하나의 bottom bucket은 두개의 top bucket에게 공유되며 따라서 bottom level 의 크기는 top level의 절반이다.
- 네번째 decision은 성공적인 Insertion 을 위해 최대 한번의 movement만을 필요로 하는 것이다. Insert 과정을 보면, 먼저 2개의 top level 중 비어있는 자리가 있는지 확인한다. 만약 없다면, 그 중 하나를 다른 top level로 옮길 수 있는지 확인하여 가능하다면 한번의movement를 발생시키고 옮겨간 기존의 자리에 새로운 item을 넣는다. 만약 옮길 수 없다면, bottom level에 남은 공간이 있는지 확인한다. 마찬가지로 없다면 그 중 하나를 다른 bottom level로 옮길 수 있는지 확인하여 가능하다면 한번의movement를 발생시키고 옮겨간 기존의 자리에 새로운 item을 넣는다.
결론적으로 insertion이 성공한다면 한번의 movement만이 필요하고, 이 모든 과정을 거쳤지만 공간이 부족하다면 hash table은 resized된다.
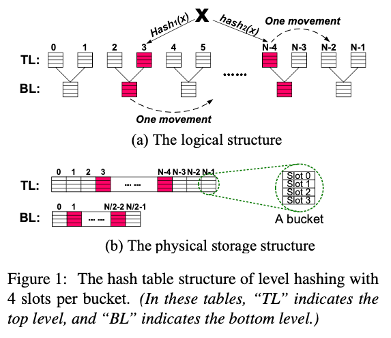
이것이 Level hashing design 구조이다. a는 logical 구조이고 b가 physical 구조이다.
이러한 디자인의 강점으로는 write-optimized, high-performance, memory-efficient가 있다.
해당 디자인은 cascading writes를 발생시키지 않고 insertions시 최대 한번의 movement만을 발생시키며, 그 movement 또한 적은 수준의 insertions을 발생시킨다.
Search/deletion/update는 최대 4개의 Bucket만을 탐색하면 되고, insertion의 경우 대부분 최대 4개의 bucket 탐색으로 가능하지만 아주 드물게 하나를 옮겨야하는 경우가 생긴다. 따라서 결론적으로는 constant-scale worst-case time complexity 를 달성할 수 있다.
각 key 마다 2개의 hash function이 있으므로 top level은 대체로 분산되어 있고, 하나의 bottom이 두개의 top에게 공유되므로 Bottom 또한 고르게 분산되어있다고 볼 수 있으며 이는 곧 memory를 효율적으로 쓸 수 있도록 한다.
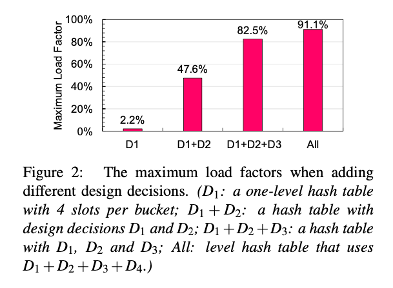
Figure 2를 통해 해당 디자인으로 load factor가 최대 90%라는 것을 확인할 수 있다.
Cost-Efficient in-place Resizeing Scheme
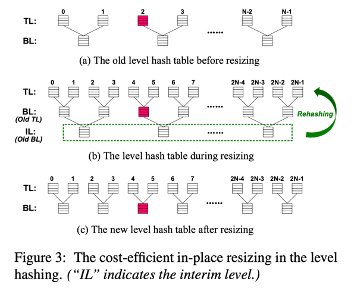
다음으로 소개할 기법은 cost-efficient in-place resizing scheme 이다.
요약하자면 새로운 Level을 기존의 hash table top level 위에 올리고 bottom level 의 값들을 새로운 level로 rehash 하는 기법이다. 따라서 resizing 과정 중에는 hash table은 3 level 구조가 된다.
먼저 전반적인 과정을 보면,
2N buckets를 new top level에 할당한다. 이때 3번째 level(=기존의 bottom level)을 interim level이라고 한다. 이 interim level의 값들을 top-two level들로 rehash 하게 되고, IL의 모든 Item이 rehash 되면 IL은 반환된다.
이러한 과정을 통해 새로운 hash table은 정확히 2배의 크기가 되며, bottom level 만 rehash 하므로 전체 중 1/3 을 rehash 하는 것만으로도 resizing을 수행할 수 있다. 또한 이 모든 과정이 하나의 hash table 안에서 이루어진다.
Resizing이 끝나고 난 후, bottom level의 Bucket들이 대부분 차 있으므로 insertion failure이 발생할 수 있다. 이를 해결하기 위해 a bottom-to-top movement를 사용한다.
Insertion 과정에서, 그동안은 bottom까지 full하면 resizing을 했지만, 이 movement를 통해 이제는 bottom level의 item을 대체 가능한 top-level로 옮길 수 있다.
또한, resizing이 끝나고 난 후, search performance가 감소할 가능성이 높다. 2/3의 item이 bottom에 있기 때문이다. 이를 해결하기 위해 dynamic search scheme 를 도입하여, bottom과 top 중 item이 더 많은 level을 먼저 search 하도록 한다.
Level hashing은 low overhead consistency guarantee를 위해 token을 도입한다. Token은 slot이 비어있는지 여부를 표현하는 것으로 1bit flag이다. Slot이 8개 이하일 경우, 총 token은 1byte로 atomic write으로 수정이 가능하다.
따라서 이 token을 이용하여 deletion/insertion/resizing할 때 log 없이도 consistency를 보장할 수 있도록 하고, update의 경우 확률적으로 log 없이도 가능하도록 한다.
좀 더 자세히 보자.
- log free deletion은 단순하게 atomic write로 token의 값만 수정하며 수행가능하다.
- Log free insertion 은 두가지 경우를 생각해볼 수 있는데,
a) 먼저 Movement가 없는 경우, new item을 먼저 slot에 쓰고, 그 후에 token의 값을 변경한다. 이때 둘의 순서는 MFENCE로 보장된다. 이를 통해 8bytes 보다 큰 item이더라도 token이 valid를 판단해주므로 logging/CoW 없이 수행가능하다.
b) 다음으로 movement가 있는 경우, 존재하는 item을 대체 가능한 bucket으로 옮기고 난 후에 token을 수정해준다. 만약 도중에 system failure이 일어나서 2개의 중복된 값이 있더라도 data consistency에 영향을 주지는 않는다. 그 후에는 a의 과정으로 간다. - Log free resizing은 먼저 copy kv를 new로 복사하고 New의 Token을 수정한 다음, old의 token을 수정하여 수행 가능하다.
- Opportunistic Log-free Update는 두가지로 경우가 있다.
a) 하나는 update 하려는 item이 있는 Bucket에 empty slot이 있는 경우이다. 이때는 logging 없이 update 가 가능하다.
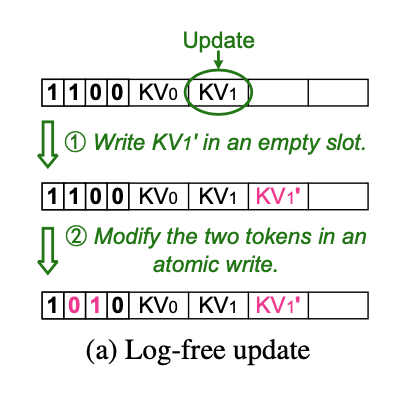
b) 그렇지 않은 경우에는 logging이 필요하다.
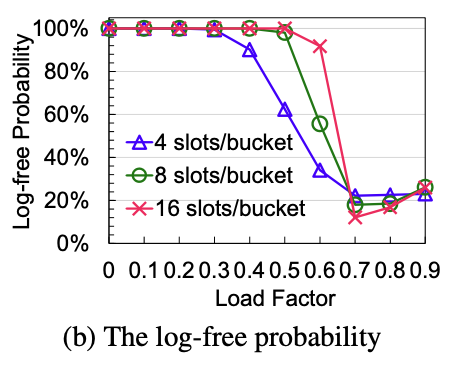
이때 확률을 계산해본 것이 아래 그래프이다. 확률은 slot의 수와 load factor로 인해 정해진다.
Level hash table은 pointers를 쓰지 않고 cascading writes를 하지 않으므로 fine-grained locking을 이용하여 쉽게 multi-reader/writer이 가능하다.
Performance Evaluation
Experimental Setup
Linux server (kernel version 3.10.0)
- Four 6-core Intel Xeon E5-2620 2.0GHz CPUs
- (each core with 32KB L1 instruction cache, 32KB L1 data cache, and 256KB L2 cache)
- 15MB last level cache and 32GM DRAM
Instead of NVM:
Hewlett Packard's Quartz
DRAM-based performance emulator for persistent memory
Compared with:
the state-of-the art NVM-friendly scghemes; PFHT and path hashing
the memory-efficient hashing scheme for DRAM; BCH
Else:
16-byte key | value <= 15bytes
1-bit token for each slot
two slots align a cache line (64B)
each hash table is sized for million key-value items - 3.2GB memory space
Use YCSB to evaluate concurrent performance of the concurrent level hashing.
Maximum Load Factor
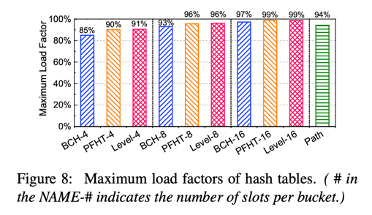
- over 90% of maximum load factor
- more slots - higher load factor
- Same # of slots:
PFHT = level hash table > BCH
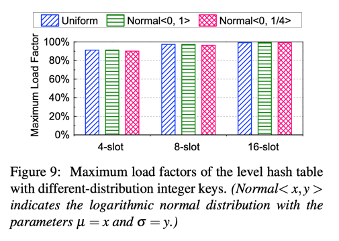
With different-distribution integer keys in level hash table: approximate load factor
Insertion Latency
Conditions:
4 slots per buckets for BCH, PFHT and level hashing
DRAM read write latency = 136ns
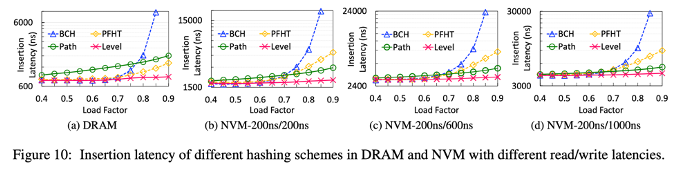
- insertion latency of persisten memory > DRAM
- best insertion performance : level hashing
Update Latency
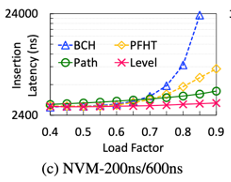
- read/write latency of NVM = 200ns/600ns
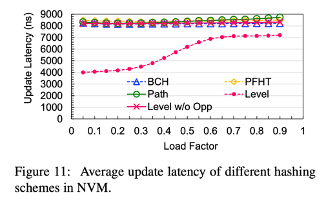
- In low load factor, BCH, PFHT, path hashing update latency > insertion latency
- Level hashing efficiently resuces the update latency by 14% ~ 52%, speeding up to 1.2 ~ 2.1
Search Latency
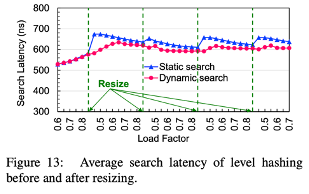
- higher load factor -> higher search latency
- negative search latency > positive search latency
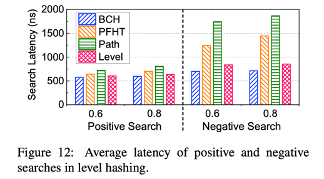
Worst-case time complexity:
- BCH, level hash - constant
- PFHT - O(N1)
(N1 = the number of items in the stash) - path hash - O(log(N2))
(N2 = total number of buckets)
Deletion Latency
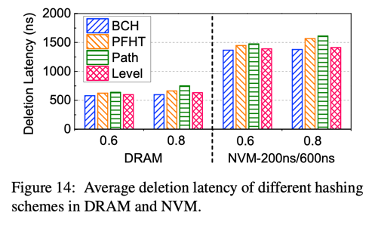
- in DRAM, small set null latency
- in PM, set null is consistency guarantee -> high latency
- BCH, level hashing latency < PFHT, path hashing latency
Resizing Time
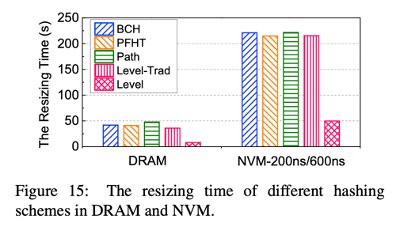
- Level hashing - decrease of resizing total time, speeding up by 4.3
Concurrent Throughput
Compared with:
state-of-the-art concurrent hash table in DRAM (Libcuckoo)
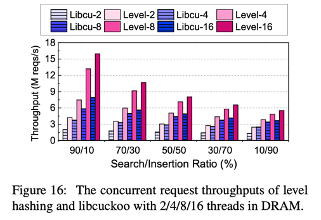
- Concurrent threads 16
- Different search/insertion ratio workload
- Zipfian request distribution
- Concurrent level hashing shows 1.6 - 2.1x higher throughput than libcuckoo
