SC '21, November 14-19, 2021, St.Louis, MO, USA
Qing Zheng, Charles D. Cranor, Gregory R. Ganger, Garth A. Gibson, Geroge Amvrosiadis, Bradley W. Settlemyer, Gary A. Grider
Introduction
High-Performance Computing은 massive concurrency를 사용하지만, 이러한 concurrency에 따라 제대로 된 scaling 효과를 보지 못하고 있다. 오늘날의 HPC appliccation에서는 필요에 따라 atomic을 요청하는 방식을 따르지만, 공유 기반 병렬 파일 시스템을 통해 액세스되는 persistent state는 언제나 전역적으로 동기화를 실시한다. 이는 성능에 치명적인 저하를 초래하므로, 본 논문에서는 해결책으로 DeltaFS를 제시한다.
DeltaFS는 "분산 파일시스템 메타데이터의 새로운 패러다임"이다.
오늘날의 파일시스템의 문제로는 대표적으로 3가지가 있다.
1. client 동기화가 서버와 지나치게 자주 이루어진다. DeltaFS는 이러한 문제를 작업별 메타데이터 로그 레코드로 변환하여, 후속 작업이 요청할 경우 동적으로 병합하는 client logging을 사용하고 있다.
2. 모든 애플리케이션 tasks를 하나의 파일시스템 namespace로 매핑하고 있다. DeltaFS는 이러한 문제를 작업별로 동기화 범위를 스스로 관리하여, 관련 없는 응용 프로그램 작업은 통신할 필요가 없도록 한다. 즉, per-job namespace management를 위해 공유기반 스토리지를 제공한다. (글로벌 네임스페이스를 사용하는 대신, 필요할 때 최소한의 동기화를 위한 통신으로 이루어짐)
3. scaling은 주로 여러 분할된 메타데이터 서버에서 dynamic namespace partitioning을 통해 이루어진다. 이때, 파일시스템 메타데이터의 성능은 메타데이터 서버에 분할된 컴퓨터 리소스 양에 따라 근본적으로 제한된다. DeltaFS는 이러한 문제를 client 노드에서 파일 시스템 메타데이터 처리 기능을 동적으로 인스턴스함으로써 해결한다. (전용 메타데이터 서버를 필요로 하는 대신, 컴퓨팅 노드를 메타데이터 처리에 동적을 활용)
이러한 분산 파일 시스템 메타데이터를 관리하는 새로운 방법을 No Ground Truth라고 부른다.
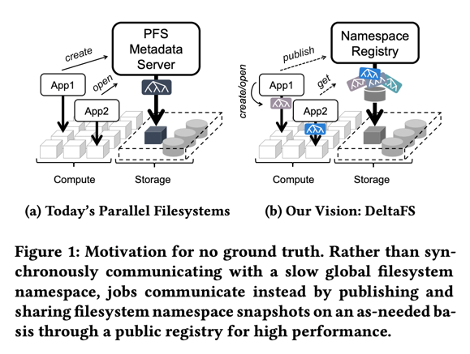
Figure 1은 구현하고자 하는 No ground truth를 나타낸 그림이다. (a)와 같이 global filesystem namespace를 이용하는 대신, (b)와 같이 jobs들 마다 각각의 filesystem namespace snapshot을 이용하여 namespace registry에 공유하는 방식을 사용한다.
Motivation
- 오늘날의 대규모 병렬 컴퓨팅 환경에서 강력한 consistency를 위한 높은 글로벌 동기화 비용을 요구한다.
병렬 파일 시스템은 대규모 객체 스토리지 장치 pool에 걸쳐 데이터를 striping 함으로써 파일 데이터에 대한 빠른 동시 액세스를 지원한다. (여러 node에 걸쳐 분포한 data 들을 묶어서 관리)
그러나 메타데이터 관리 측면에서는, 초기 네트워크 파일 시스템과 크게 다르지 않은 전략이 사용된다. 즉, 모든 client 메타데이터 mutation이 동기적으로 처리된다.
이는 오늘날의 대규모 병렬 컴퓨팅 환경에는 맞지 않기 때문에, 성능 병목 현상의 원인으로 작용하게 된다. - 다음으로 확장 가능한 병렬 메타데이터 성능에 대한 현재의 첨단 기술의 부적절성이다.
최신 병렬 메타데이터는 여러 메타데이터 서버에 dynamic namespace partitioning을 사용한다. 이는 애플리케이션에 필요한 resource 양을 사전에 파악하기 어려움에 따른 성능 저하로 이어질 수 있다.
혹은 오늘날의 병렬 파일시스템 메타데이터 서버의 프로세싱 딜레이를 숨기는 log-structured 메타데이터 포맷을 이용하는 것이다. 그러나 이러한 시스템은 server compute resource가 부족하거나, 백그라운드 프로세스가 insertion을 따라가지 못하는 경우에 문제가 생기게 된다. - 마지막으로 컴퓨터의 용량과 병렬성이 계속 증가됨에 따라, 단일 크기에 맞는 병렬 데이터 시스템이 없는 시점에 접근하고 있다. 오늘날의 병렬 애플리케이션은 대부분 non-interaction batch 작업들로 구성되어있기 때문에, 전역 동기화의 높은 비용을 굳이 필요로 하지 않는다.
따라서 non-interactive 병렬 컴퓨팅 workload를 위한 완화된 “no ground truth” 병렬 파일 시스템을 보장하게 되는 것이다.
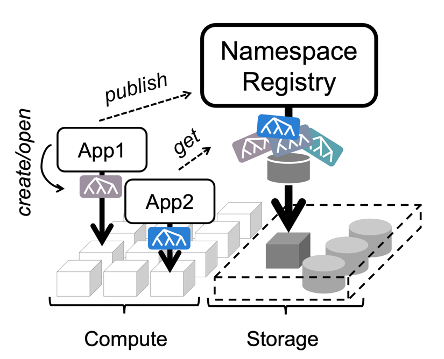
DeltaFS의 핵심은 DeltaFS에서는 전역 동기화 없이 filesystem namespace snapshot을 단순 게시 및 공유하여 순차적인 데이터 공유를 지원하는 것이다.
각 작업은 snapshot 중 일부를 입력으로 선택하고, 작업의 모든 출력을 포함하는 새 snapshot을 공용 namespace registry에 게시하여 종료한다.
이때 namespace snapshot은 이전에 실행된 파일 시스템 메타데이터 변경사항 집합에 대한 포인터이다.
(각 작업은 필요한 namespaces에 대한 snapshot을 가지고 와서, 변경사항에 따라 새로운 파일시스템 view를 구성하는 방식을 따름)
System Overview
(OSD Storage : object storage device, 데이터를 오브젝트로 관리하는 컴퓨터 데이터 스토리지 아키텍처)
DeltaFS는 공유기반 객체 저장소 위에 확장 가능한 병렬 파일 시스템 메타데이터 액세스를 제공하는
라이브러리 루틴 및 데몬 프로세스의 모음이다.
Architecture of DeltaFS
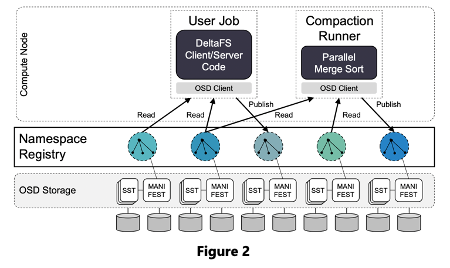
Figure 2와 같이, DeltaFS의 주요 구성 요소로는 User Job, Compaction Runner, Namespace Registry가 있다.
- 각 user job에서 실행되는 DeltaFS 라이브러리 코드는 DeltaFS 메타데이터 서버 및 클라이언트의 역할을 한다. (DeltaFS client/server 인스턴스)
- Compaction runner는 user-scheduled DeltaFS log compaction code로, 향후 빠른 액세스를 위해 스토리지 내 DeltaFS 메타데이터의 지정된 subset을 재구성한다. (filesystem namespace snapshot을 읽고 병합하여 공용 registry에 게시)
- Namespace registry는 사용자가 사용 가능한 DeltaFS namespace snapshot을 효율적으로 추적하고 검색할 수 있도록 지원하는 장시간 실행되는 데몬들이다. (snapshot 데이터와 snapshot 이름을 매핑)
Jobs : 컴퓨팅 노드에서 실행하기 위해 제출되는 병렬 프로그램 또는 스크립트
- 오늘날의 병렬 파일 시스템 : 단일 글로벌 파일 시스템 네임스페이스를 모든 작업에 제공하고 이를 관리하기 위해 전용 메타데이터 서버를 배치함. 메타데이터 서버(들)에서 namespace 정보와 통신함.
- DeltaFS : 작업은 자체 파일 시스템 메타데이터의 관리자 역할을 함, namespace registry에서 정보를 가져와서 자체 서버를 구축하고, 그것과 통신 후 해당 메타데이터 정보 registry로 릴리스함.
각 작업은 해당 filesystem namespace를 자체 정의하는 것으로 시작한다. (이전 작업에서 게시한 namespace snapshot을 찾아보고 잠재적으로 병합하는 방식으로 수행)
그런 다음 클라이언트 및 서버 인스턴스를 인스턴스화하여 namespace를 처리한다. (클라이언트 – 작업 – 서버를 묶음)
이러한 일들은 컴퓨팅 노드의 작업 프로세스 내에서 실행되며,
작업이 끝나면 namespace를 다른 작업에서 검색 및 병합할 수 있는 공개 snapshot으로 release한다.
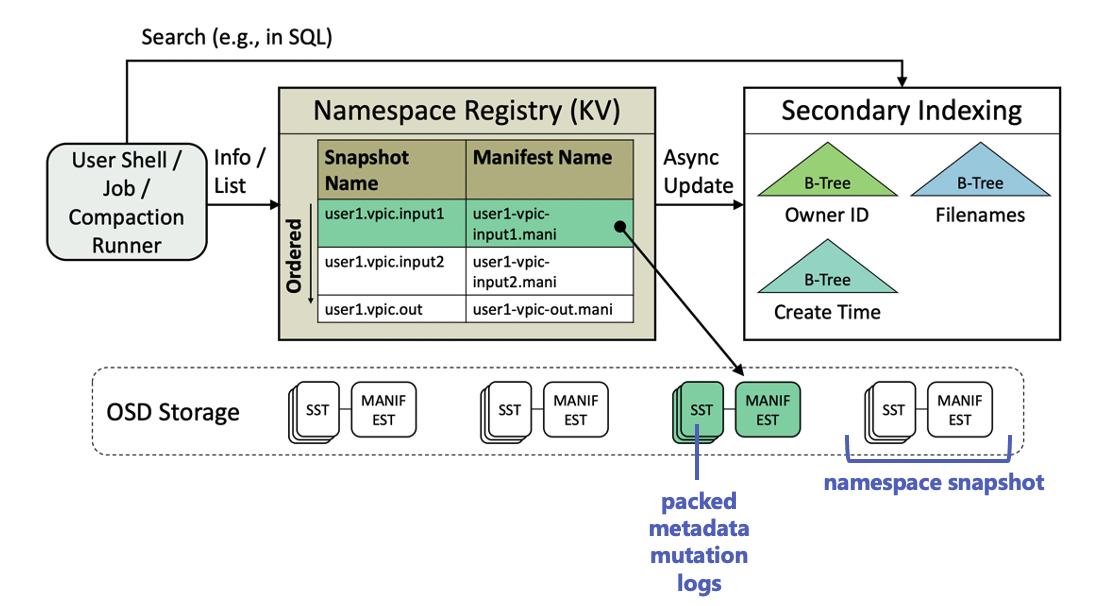
registry들은 게시된 모든 DeltaFS namespace snapshots의 keeper이다.
각 registry는 snapshot 이름(K)을 포인터(V)에 매핑하는 간단한 KV 테이블로 생각할 수 있다.
- pointer : 공유기반객체저장소에 저장된 snapshot들의 manifest 객체에 연결
- manifest file : 컴퓨팅에서 집합의 일부 또는 논리정연한 단위 파일들의 그룹을 위한 메타데이터를 포함하는 파일
위의 Figure에서 볼 수 있듯이, 각 DeltaFS namespace snapshot은 storage에 SSTable로 저장된 압축된 메타데이터 mutation logs로 구성된다.
여기에서 manifest는 루트 인덱스로 사용하기 위해 스냅샷에 삽입되는 특수 메타데이터 객체로, snapshot의 모든 구성원 로그(SSTables) 이름과 각 로그의 키 범위가 포함된다.
Compaction runner는 컴퓨팅 노드에서 사용자가 동적으로 시작하는 parallel log compaction 작업으로, 하나 이상의 이전 작업에서 생성된 메타데이터 mutation logs(SSTables)를 병합하고 다시 분할하여 후속 작업의 효율적인 쿼리를 위해 filesystem namespace의 읽기 최적화된 소형 view를 형성한다.
Publishing namespace as a snapshot
DeltaFS는 관련 없는 작업끼리 통신할 필요가 없다. 한편, 관련 작업끼리의 통신은 이전 작업에서 namespace를 snapshot으로 게시한 다음, 나중에 snapshot을 조회하는 후속 작업으로 수행된다.
namespace를 snapshot으로 게시하려면 작업은
1. 메모리 내 상태를 저장소에 flush하고
2. manifest를 작성한 다음
3. manifest의 객체 이름과 snapshot 이름을 registry에 전송한다.
DeltaFS에서, 작업들은 – 오늘날의 파일시스템에서 파일들이 애플리케이션에 의해 이름 지어지는 것과 같이 – namespace snapshot의 이름을 지정한다. (uniqueness 검사도 수행)
마찬가지로 오늘날의 응용 프로그램이 파일 이름을 알아야 작동되는 것처럼 DeltaFS 작업 또한 registry에서 찾기 위해 snapshot의 이름을 알고 있어야 한다. 이를 위해 DeltaFS는 작업들이 작업 지정 prefix string에 따라 snapshot들을 나열할 수 있도록 하고 있다. (snapshot 이름이 문자열 순서로 인덱싱됨)
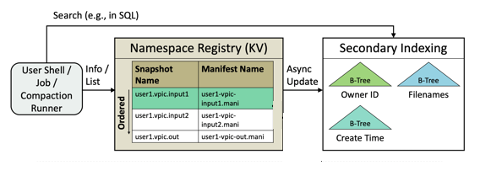
위의 그림에 표시된 것처럼, DeltaFS 레지스터리들은 이름 이와의 특성으로 스냅샷을 인덱싱하는 secondary indexing tier와 쌍을 이룰 수도 있다.
No Ground Truth
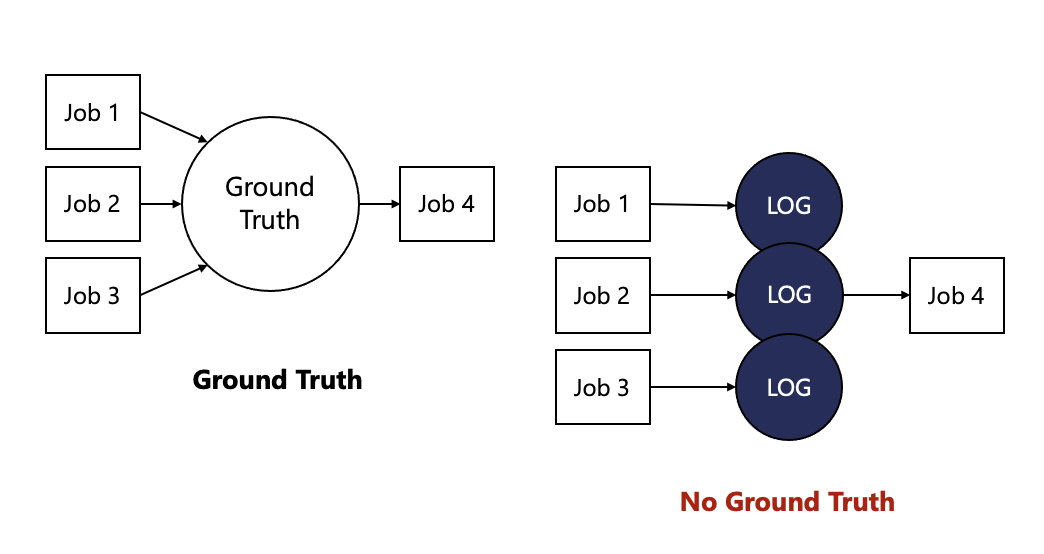
DeltaFS는 사용자에게 글로벌 파일 시스템 네임스페이스를 제공하는 대신 각 작업이 생성하는 메타데이터 mutation을 공유 기반 객체 저장소에 불변 로그로 기록한다. 후속 작업에서는 이러한 로그들을 그들의 자체 파일 시스템 네임스페이스를 구성하기 위한 fact로 독립적으로 사용한다.
즉, DeltaFS는 로그에 글로벌 순서를 적용하지 않고, 모든 로그를 병합하지도 않는다. 이렇게 불필요한 동기화 방지를 통해 전체 메타데이터 성능을 향상 시킬 수 있다. 이를 No Ground Truth라 한다.
A Log-Structured Filesystem
DeltaFS에서 파일 시스템 메타데이터 정보는 로그로 유지된다.
- 메타데이터 쓰기 작업 – 스토리지에 새 로그 항목을 기록
- 메타데이터 읽기 작업 – 저장소에서 관련 로그 항목 검색하고 읽어 파일 정보를 가져옴
(로그 형식은 동일)
DeltaFS는 작업의 private한 base namespace를 정의하며 작업을 시작한다.
- 시작 - 이전 작업의 데이터 출력에 액세스해야하는 경우, 이전 작업에서 생성된 로그를 사용
- 끝 – 모든 메타데이터 mutation을 새 로그 entries로 기록하고 publish
Publish된 Log entries는 a change set이라고 불린다.
Log publication 시에 작업 네임스페이스 상태를 snapshot이라고 한다.
따라서 각 DeltaFS job은 big log append oppration이라고 볼 수 있다.
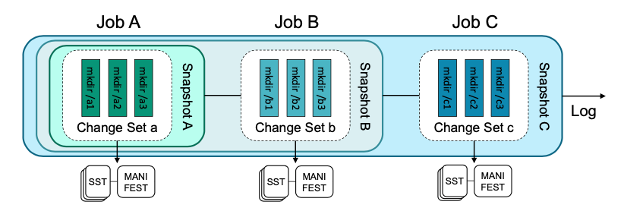
위의 그림에서 볼 수 있듯이, 각 작업에서 해당 작업의 change set를 input snapshot에 추가하고 새 snapshot을 생성한다.
Multi-Ingeritance & Name Resolution
DeltaFS 작업이 base를 인스턴스화할 때, 이는 여러 input snapshot들을 이용할 수 있다.
작업 내에서 일관성을 유지하기 위해 작업은 모든 input snapshot의 우선순위를 지정하여 우선순위가 더 높은 snapshot의 레코드가 우선하도록 한다.
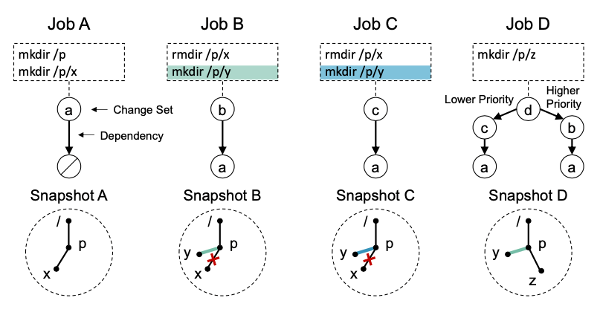
위의 그림은 작업 A, B, C, D가 각각 새 snapshot을 생성하는 예시이다.
Job A의 경우, null을 입력으로 사용하고 snapshot A를 생성한다.
Job B의 경우, 작업 A의 출력 snapshot을 입력으로 가져와서 snapshot B를 생성한다.
Job C의 경우, 작업 A의 출력 snapshot을 입력으로 가져와서 snapshot C를 생성한다.
Job D의 경우, 작업 B와 작업 C의 출력 snapshot을 모두 입력으로 가져와서 snapshot D를 생성한다.
작업 B와 C는 각각 snapshot에서 /p/y 를 생성했지만, D에서 B가 C보다 우선순위가 높기 때문에, D는 C에서 생성된 /p/y를 보게 된다.
Custom client filesystem namespace view는 UnionFS나 OverlayFS와 같은 시스템에서도 사용할 수 있다. DeltaFS가 그것과 다른 점은, 필요에 따라 컴퓨팅 노드에서 동적으로 호출할 수 있는 병렬 압축 매커니즘을 통해 복잡한 클라이언트 네임스페이스 뷰를 효율적으로 구현하여 빠른 읽기를 수행할 수 있다는 것이다.
동시에, DeltaFS의 로그 구조화된 메타데이터 형식을 사용하여 쓰기 시에 copy-on-write 및 다른 overlay filesystem 기법에 제한되지 않고 클라이언트 메타데이터 mutation을 효율적으로 기록할 수 있다.
마지막으로, DeltaFS는 병렬 파일 시스템으로, 워크로드를 분산 작업 프로세스로 분산하여 scaling을 달성할 수 있는 반면, 로컬 오버레이 파일시스템의 성능은 근본적으로 로컬 컴퓨터의 용량에 의해 제한된다.
Per-Job Log Management
Log Format
DeltaFS 작업은 메타데이터 operation을 storage에 로그로 기록하여 실행한다.
고성능을 얻기 위해 DeltaFS는 각 파일 시스템 메타데이터 mutation이 LSM 트리로 구성된 테이블에 KV 쌍으로 기록되는 로그 형식을 사용한다.
이때, tree 데이터는 작업별 change set의 manifest 객체에 의해 인덱스된 SSTable 이름이다.
Log Format는 아래 그림과 같다.
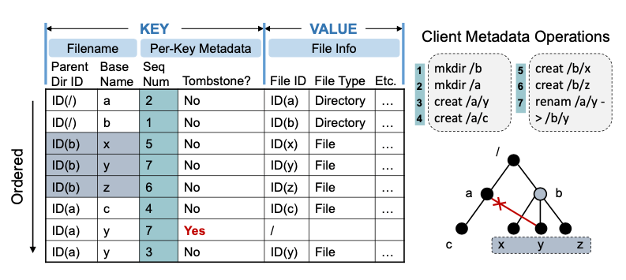
DeltaFS는 실행된 각 파일시스템 메타데이터 mutation에 대해 KV 쌍을 기록한다.
- Key는 mutation에 관련된 파일의 이름을 저장하고
- Value에는 변경 후 파일의 메타데이터 정보를 저장한다.
기록된 mutation이 삭제인지 여부를 표시하기 위해 각 key에 특수 삭제 bit (tombstone)이 기록된다.
또한 각 key는 시퀀스 번호와 연결되어, 시퀀스 번호가 높은 키가 낮은 키보다 우선되고, 새로 기록된 변경사항이 이전 변경 사항보다 우선된다. 작업별로 모든 키는 high performance DeltaFS-modified LevelDB realization of an LSM-Tree로 구성된 테이블에 삽입된다.
--> 보다 구체적으로,
파일 이름을 나타내기 위해서는 상위 디렉토리 ID와 파일의 기본 이름을 사용한다.
전체 경로 이름 대신 상위 디렉토리 ID를 key prefix로 사용하면 DeltaFS가 파일의 상위 경로를 따라 디렉토리 이름을 변경할 때 파일 키를 업데이트할 필요가 없어진다.
각 파일에 대해 저장하는 메타데이터 정보에는 파일 ID, 파일 형식, 계층적 액세스 제어를 위한 파일 권한 및 작은 파일에 대한 파일 데이터가 포함된다.
효과적인 파일 시스템 메타데이터 조회 및 디렉토리 검색을 위해 DeltaFS key들은 정렬된다.
On-Storage Log Management
각 작업 마다 change set을 구성하는 LSM-Tree 구조는 아래와 같다.
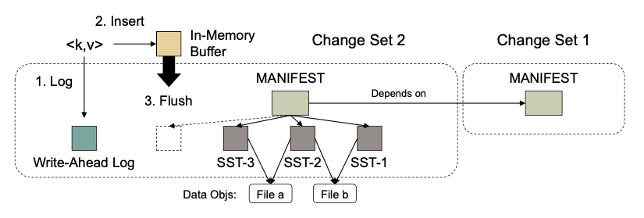
change set를 위해 LSM 트리를 초기화할 때,
1. 작업은 change set에 대한 high level 정보를 기록하기 위해 객체 storage에 manifest 객체를 먼저 생성한다. manifest 객체 안에는 change set의 이름과 모든 작업 입력 snapshot의 root change set으로 정의된 모든 종속성의 이름이 포함된다.
2. 다음으로 작업 프로세스에 메모리 내 버퍼 공간을 할당하여, 작업 실행 시에 incoming 메타데이터 변경사항을 버퍼링한다. 이러한 변경 사항은 KV 쌍으로 포맷되고, 메모리 내 쓰기 버퍼가 가득 찰 때마다 버퍼의 모든 KV 쌍이 정렬되어 storage에 SSTable로 기록된다.
3. 그런 다음 테이블의 키 범위와 함께 SSTable의 이름이 후속 쿼리에서 사용할 수 있도록 manifest에 기록되게 된다.
- 데이터 손실 방지를 위해 write-ahead log가 저장소에 생성되고, KV 쌍은 메모리 내 버퍼에 삽입되기 전에 wal에 먼저 기록된다.
- Change set는 더이상 필요하지 않을 때 삭제할 수 있다.
(각 change set는 자신과 각각의 의존성에 대한 참조를 보유했다가, 사용자가 change set를 삭제하면 참조가 제거되어, 매니페스트, wal, SSTable에 대한 참조가 없는 모든 멤버 객체는 삭제됨)
Log Compaction
읽기 성능을 향상시키기 위해 DeltaFS는 겹치는 SSTable들을 병합하여 키를 공유할 수 있는 Sstable 수를 줄이는 컴팩션을 실행한다. 이를 통해 SSTable이 병합되면서 새로운 SSTable이 생성되고 오래된 SSTable은 삭제된다.
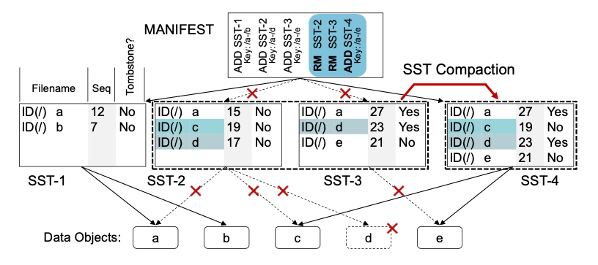
위의 그림은 SSTable 2와 3이 컴팩션되어 SSTable 4를 형성하는 예를 보여준다.
컴팩션 이전에는 /c key를 조회하기 위해 SST 3과 2, 총 두 개의 SSTable을 검색해야했지만,
컴팩션 후에는 SSTable 4 하나만을 조회하여 찾을 수 있으므로 읽기 성능이 향상됨을 알 수 있다.
테이블이 병합될 때, 동일한 파일 이름 prefix를 공유하는 레코드가 병합되어 시퀀스 번호가 가장 높은 레코드만 새 테이블에 복사되고 나머지는 버려지게 된다.
그리고 새로 생성된 테이블의 정보가 manifest에 기록되며, 이전 테이블에 대한 참조가 삭제된다.
Dynamic Service Instantiation
DeltaFS는 전용 메타데이터 서버를 두는 대신, 작업 프로세스에서 DeltaFS 클라이언트 및 서버 인스턴스를 동적으로 인스턴스화하여 해당 작업에 대해 전용 병렬 파일 시스템 메타데이터 액세스를 제공한다.
또한 Scalable 읽기 성능 달성을 위해 namespace를 작업 서버에 걸쳐 적극적으로 분할하고, 클라이언트 로깅을 사용하여 급증하는 쓰기를 빠르게 레코딩한다.
클라이언트는 private LSM tree에 대해 백그라운드 로그 컴팩션을 수행하여 읽기 성능을 향상시킬 수 있다.
그러나 클라이언트에서 만든 파일이 쓰기 전용인 것으로 알려져 있고, 작업이 완료될 때까지 읽기 위해 열리지 않는 경우 DeltaFS 클라이언트는 로그 압축을 연기하고 나중에 후속 병렬 로그 압축 프로그램을 작업이 프로세스별 로그에 변화를 기록하더라도, 이와 무관한 읽기 요청은 계속 제공될 수 있다.
또한, 작업 네임스페이스 분할에 따른 서버가 워크로드에 적합하지 않다면 별도의 컴퓨팅 노드를 할당할 수도 있으며 이렇게 별도로 할당된 서버는 여러 작업에 의해 재사용될 수 있다.
마지막으로, 관리자는 긴 시간 동안 돌아가는 서버를 위해 계산 노드들의 집합을 영구 할당 요청할 수도 있다.
이러한 읽기 전용, 작업별, 잠재적으로 장기간 실행되는 DeltaFS 서버들을 namespace curator라고 부른다.
Cross-Job Parallel Log Compaction
모든 로그 구조화된 파일 시스템은 우수한 읽기 성능을 달성하기 위해 compaction이 필요하다.
오늘날의 병렬 파일 시스템을 컴팩션 활동을 전용 메타데이터 서버로만 제한하지만, DeltaFS를 사용하면 사용자가 컴퓨팅 노드에서 compaction을 동적으로 시작할 수 있다.
사용자는 후속 작업에서 읽기로 알려진 job change sets에 대해서만 compaction을 진행하면 되므로 compaction 당 데이터 공간을 최소화하여 compaction 지연을 더욱 줄일 수 있다.
앞서 얘기한 바와 같이 작업별 로그 컴팩션은 암시적으로 수행되는 데에 반해 작업간 로그 컴팩션은 사용자가 명시적으로 예약해야 한다.
일반적으로 작업간 로그 컴팩션은
- 효율적인 쿼리를 위해 복잡한 작업 change set 계층을 평평하게 만들어야한다던가,
- 빠른 검색을 위해 작업 change set 내에 기록된 대규모 클라이언트 별 SSTable set를 병렬 정렬해야한다던가,
- 주어진 change set 또는 이들 계층이 후속 작업의 작업 프로세스 간에 충분한 load balancing을 위해 너무 적은 파티션을 포함할 경우에 필요하다.
DeltaFS는 작업 간 로그 압축에 확장 가능한 병렬 병합 정렬 파이프라인을 사용한다.
각 pipeline process는 입력 SSTable의 하위 집합에 대한 mapper 역할을 하며
동시에 target change set의 파티션을 담당하는 reducer로 작용합니다.
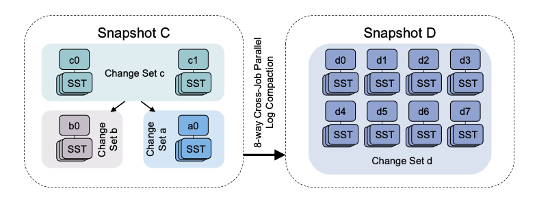
위의 그림은 c가 루트인 change set a, b, c로 구성된 snapshot C가 병렬로 압축되어 snapshot D를 형성하는 예를 보여준다.
parallel compaction을 통해 스냅샷 D에서 각 key lookup은 하나의 change set 파티션만 검색을 필요로 하며, 기존의 change set a, b, c는 파티션이 1, 1, 2개만 있었으나, change set d의 경우에는 8개의 파티션으로 확장됨을 알 수 있다. 8개의 작업 프로세스가 있는 후속 작업은 각 프로세스별 서버에 파티션을 할당하여 읽기 작업을 완전히 밸런싱할 수 있다.
Experiments
Experimental Setup
- A Prototype of DeltaFS in C++
- A modular design to be layered on top of different object storage backends such as Ceph RADOS, PVFS, HDFS, and other POSIX parallel filesystems
Test cases
- Jobs are related and use the filesystem for sequential data sharing
- Jobs are unrelated and do not read each other's files
Workload
use mdtest to generate test workloads
Comparison
- IndexFS for scalable parallel metadata performance
(+ Special IndexFS mode that allows clients to log metadata mutation for later bulk insertion) - PLFS for ultrafast client-based metadata logging
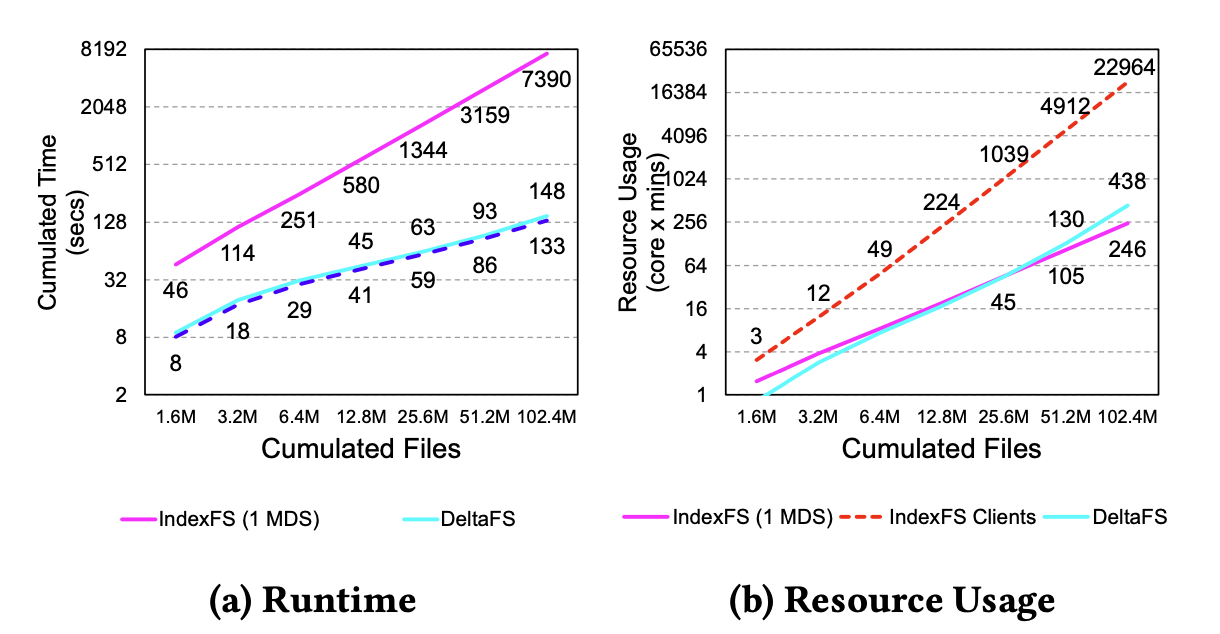
Single-Job Performance
Dynamic Namespace Partitioning
IndexFS-like configuration of DeltaFS
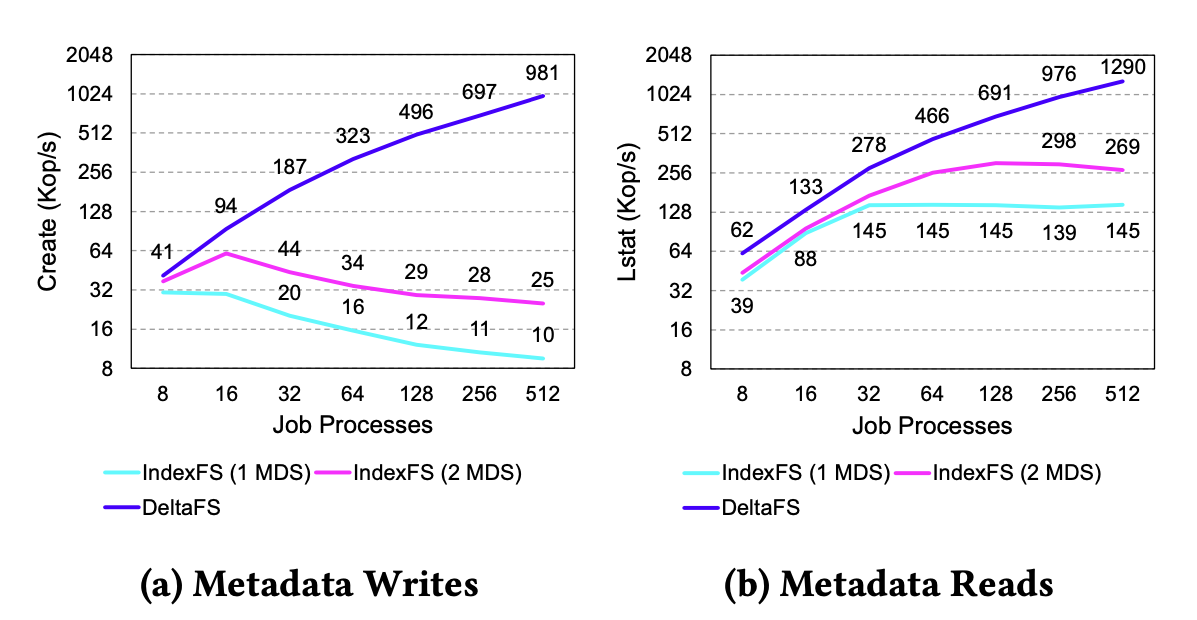
IndexFS
- limited by the # of dedicated metadata servers
- Performance reduces as job size grows
DeltaFS - Decouples per-job metadata performance from dedicated resources
- Scalable Performance that increases as job size grows
Client Logging
Combining client logging with post-wirte client log compaction
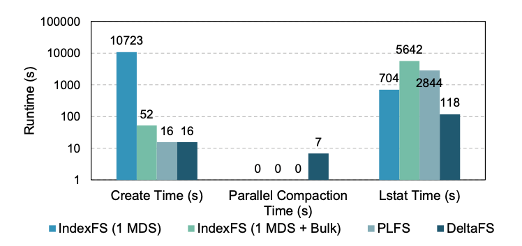
- All of IndexFS, PLFS, and DeltaFS performance significantly improves
- IndexFS and PLFS shows lower performance than DeltaFS
Multi-Job Performance
No Ground Truth
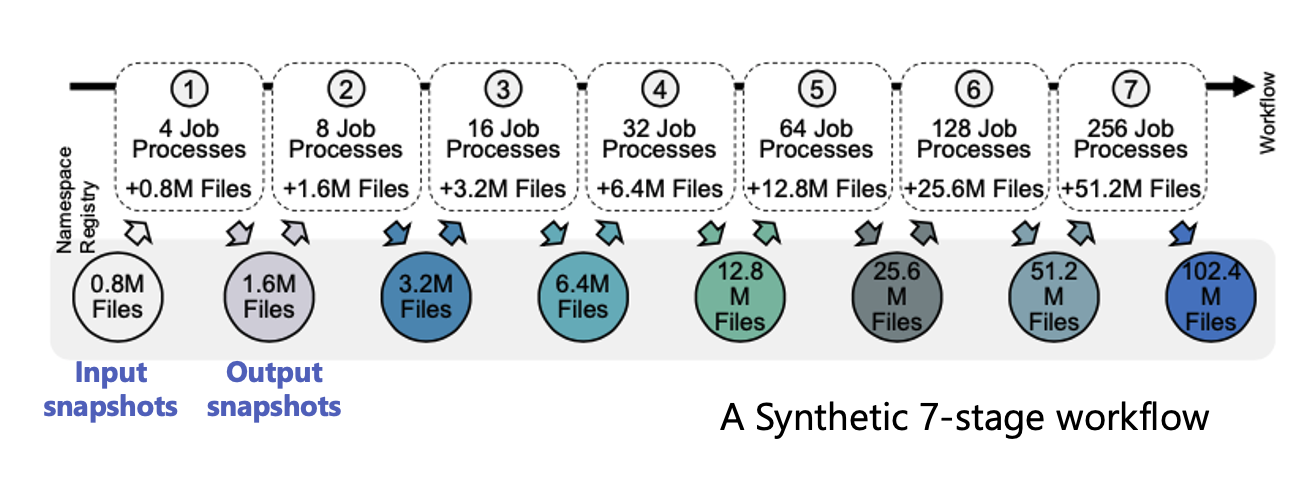
- IndexFS - All new files are directly inserted into the global namespace
- DeltaFS - Newly created files are first logged through the DeltaFS instance and later merged into a unified job-wide namespace
Two main factors of performance
1. Awareness of workflow
2. Minimize compaciton time by using parallelism