Linux 기준
1. JDK 설치
$ sudo apt-get install default-jdk
$ javac -version필자: jdk 1.82. 기타 패키지 설치
$ sudo apt-get install ssh rsync3. hadoop 설치
hadoop-3.3.1 url
$ sudo wget https://mirror.navercorp.com/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
$ sudo mv hadoop-3.3.1 /usr/local/hadoop-> 꼭 /usr/local 일 필요는 없음. hadoop을 설치하고자 하는 base directory 사용.4. 클러스터 구성
- master node: 클러스터를 관리하기 위한 기능을 가짐
- slave node: HDFS, MapReduce 등 데이터를 저장하고 처리하기 위한 기능을 가짐
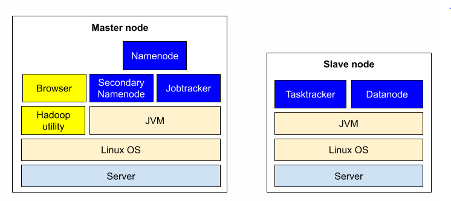
필자: eternitymaster(master node) eternity3(slave node) eternity5(slave node)
4.1. (편의를 위해) file permission 조정
/usr/local 에서 진행
$ ls -lh
$ sudo chown -R soo:soo hadoop-> hadoop 파일을 비롯한 모든 아래 항목들의 owner를 soo:soo로 변경5. hosts 구성
5.1. /etc/hosts 구성
port 번호와 server 설정
5.2. ssh key 설정
$ ssh-keygen -t rsa
$ cat id_rsa.pub >> $HOME/.ssh/authorized_keys-> master node와 slave node 간의 원활한 통신을 위함
모든 node에서 진행 후, 비밀번호 없이 ssh를 통해 node간 이동이 가능한지 확인5.3. hadoop 설정 (master node만 필요)
- hadoop 설정 파일 디렉토리로 이동
$ cd /usr/local/hadoop/etc/hadoop- masters 파일 열어서 secondary namenode 설정 - master node가 죽을 경우 백업해줄 node (필자의 경우 설정하지 않음)
$ vi masters- slaves 파일 열어서 slave node 설정
$ vi slaves
eternity3
eternity5- workers 등록
$ vi workers
eternity3
eternity56. *-site.xml 설정
위치: /usr/local/hadoop/etc/hadoop
6.1. hdfs-site.xml
- replication: 추가적으로 몇 개의 복사본을 둘 것인지 결정
Ex. 1 -> 만약 eternity3에다가 데이터를 저장했다면 거기에만 저장
Ex. 2 -> eternity3, 5에 복제가 되어서 저장
우리는 data node 가 지금 2개니까(eternity3, 5) replication은 2로 설정 - dfs.namenode.name.dir: namenode data directory
- dfs.datanode.data.dir: datanode data directory
-> 원하는 폴더에 지정, master node는 namenode data directory가, slave node는 datanode data directory가 필요 - port 50070, 50090: hadoop에서 기본적으로 많이 사용하는 port

6.2. mapred-site.xml
framework yarn 사용

6.3. yarn-site.xml
- yarn.resourcemanager.hostname: masternode ip 주소 사용

6.4. core-site.xml
- fs.default.name: hdfs://(masternode name):9000

6.5. hadoop-env.sh
- JAVA_HOME 에 java home directory 설정

7. hadoop directory를 eternity3, 5에 복사
7.1. 복사된 데이터를 받을 계정 권한 설정
$ ssh eternity3
$ cd /usr/local
$ sudo mkdir hadoop
$ sudo chown -R soo:soo hadoop
$ exit-> 모든 slave node에 수행7.2. master node에서 slave node로 data 복사
$ for i in 3 5; do scp -r /usr/local/hadoop/* soo@eternity$i:/usr/local/hadoop; done;8. bash 설정
$ cd ~
$ vi .bashrc
$ source .bashrc
9. namenode, datanode directory 설정
- master node
$ sudo mkdir /hadoop_datas
$ sudo mkdir /hadoop_datas/namenode
$ ls -la /hadoop_datas
$ sudo chown -R soo:soo /hadoop_datas
$ for i in 3 5; do ssh -t eternity$i "sudo mkdir -p /hadoop_datas/dn"; done;
$ for i in 3 5; do ssh -t eternity$i "sudo chown -R soo:soo /hadoop_datas"; done;-> namenode data directory 명: namenode
-> datanode data directory 명: dn 으로 설정 (뭘로 설정해도 상관 없음)
10. namenode format
$ hadoop namenode -format11. 실행
$ start-dfs.sh11.1. hadoop에 file 올려보기
$ hdfs dfs -put txt.1 /text
$ hdfs dfs -ls /
$ hdfs dfs -cat /text11.2. hadoop 멈추기
$ stop-dfs.sh유의사항
hadoop이 정상적으로 돌아가지 않은 경우, hadoop을 멈추고 hadoop namenode format을 해야한다.
이때, format 전에 namenode data directory와 datanode data directory 내의 모든 폴더 및 파일들을 삭제한 후에 format을 진행해야한다.
ex. 본인이 지정한 namenode/datanode data directory에서 진행
master node에서는,
$ cd /hadoop_datas/namenode
$ rm -rf (폴더 내에 존재하는 파일)
slave node에서는,
$ cd /hadoop_datas/dn
$ rm -rf (폴더 내에 존재하는 파일)
master node에서,
$ hadoop namenode -format
$