HBase 소개
Hadoop의 HDFS 위에 만들어진 분산 데이터베이스
• HDFS의 데이터에 대한 실시간 임의 읽기 / 쓰기 기능을 제공
• 사용자는 HBase나 HDFS에 직접 데이터를 저장할 수 있고, 데이터를 읽고 접근하는 것은 HBase를 통함
• 선형 확장성을 가지고 있음
• 읽기와 쓰기의 일관성을 제공
• cluster를 통한 데이터의 복제 제공
HBase 동작 환경 및 데이터 저장 방식
HBase의 데이터 저장 방식
- Stand-alone mode
HBase 서버 하나만 사용하는 경우로, 로컬 파일 시스템을 사용
-> HBase 데몬과 zookeeper는 모두 하나의 JVM (Java Virtual Machine) 상에서 동작 - Distributed mode
Hadoop을 파일시스템으로 사용하여 분산 구성이 가능
• Pesudo-distributed mode
-- 물리적으로 하나의 서버 위에 여러 HBase가 사용되는 경우
-- 각각의 데몬이 하나의 노드에서 독립적으로 동작
-- 테스트 환경으로 사용
• Fully-distributed mode
-- HBase가 물리적으로 분리된 여러 서버에 나뉘어 동작하는 경우
-- 하나의 데이터가 각각의 분산된 서버에 나뉘어 저장
-- 각각의 데몬도 분산되어 동작
Master / Slave
분산 구성 시 HBase는 Masterd와 Slave로 나뉘어 동작
-
Master = HMaster
HDFS의 NameNode에서 실행
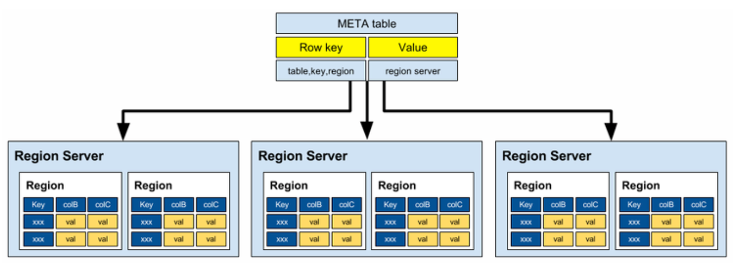
Region을 region server에 할당 및 region server 관리
Region server에 퍼져있는 region들의 load balancing을 수행
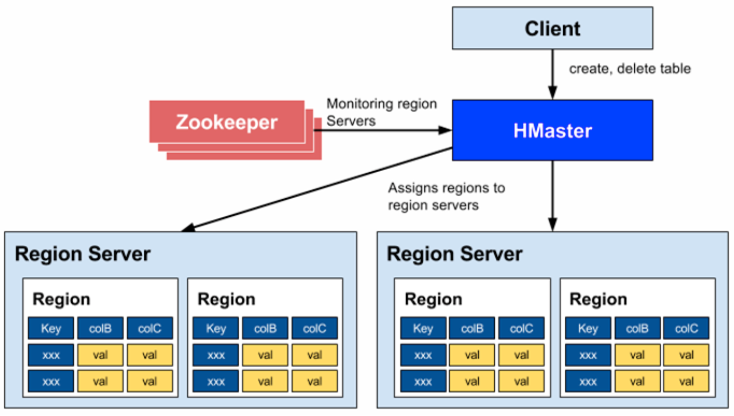
스키마의 변화나 Metadata 연산을 책임
-
Slave = Region Server
Client와 직접 통신
Region 관리 및 호스팅
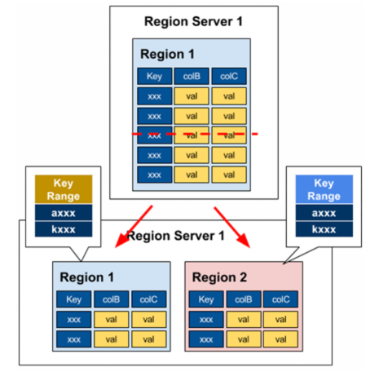
Region 자동 분할
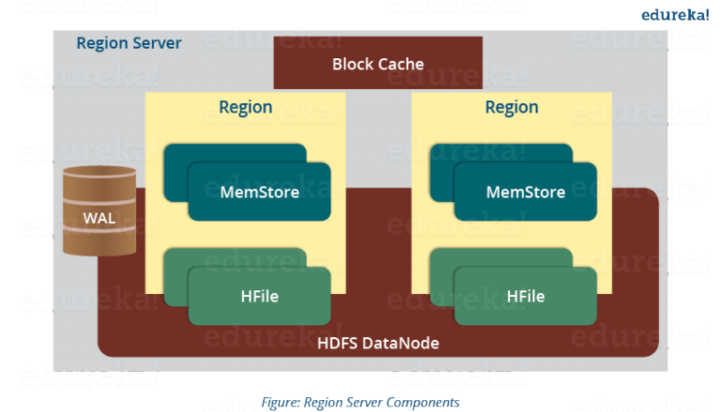
Write Ahead Log
Block cache – read cache 로 자주 읽은 데이터를 저장
Memstore – write cache로 Region에 있는 모든 Column Family는 memstore가 있음
HFile – 실제 storage file로 row 들이 정렬된 key value로 쌓여있음. Disk에 존재
-
Zookeeper
분산형 코디네이션 서비스
HMaster에 속한 모든 region server가 일정 간격으로 heartbeat를 zookeeper에 보냄으로써 서버가 정상동작임을 감지
설정 정보 유지
pseudo와 standalone 모드에서는 hbase 자체가 zookeeper의 기능도 담당
데이터 저장 방식
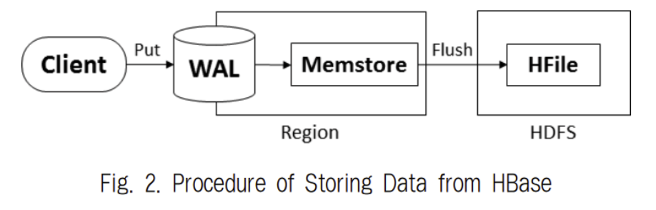
Client는 PUT, DELETE 등의 명령어로 데이터를 추가/수정/삭제
-> 결과는 HFile에 저장
데이터가 업데이트 될 때마다 Region Server는 데이터를 Memstore(Memory)에 저장
Memstore에 Write한 데이터 크기가 ‘hbase.hregion.memstore.flush.size’ 속성에 지정한 Memstore의 크기를 초과하거나, Memstore 크기의 합이 ‘hbase.regionserver.global.memstore.upperLimit/lowerLimit’ 속성에 지정한 값에 도달하면, Memstore에 저장된 데이터들이 디스크(HFile)에 저장(Flush)된다.
이러한 Memstore와 HFile은 Column Family 당 하나씩 존재
메모리에 저장되는 데이터는 휘발성이므로 데이터가 유실될 수 있다.
-> 추가(수정)된 데이터는 memstore에 저장되기 전 WAL에 저장

데이터 모델
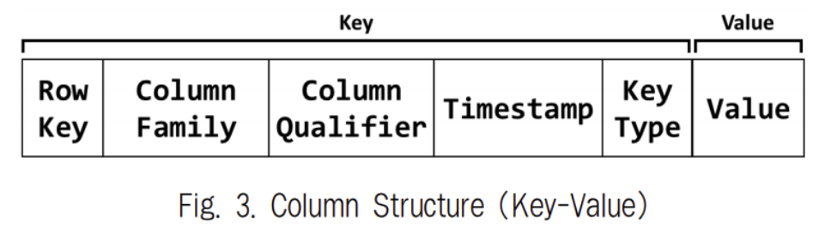
HBase는 기본적으로 Key와 Value의 쌍으로 이루어진 데이터를 Column 단위로 저장

Write Mechanism
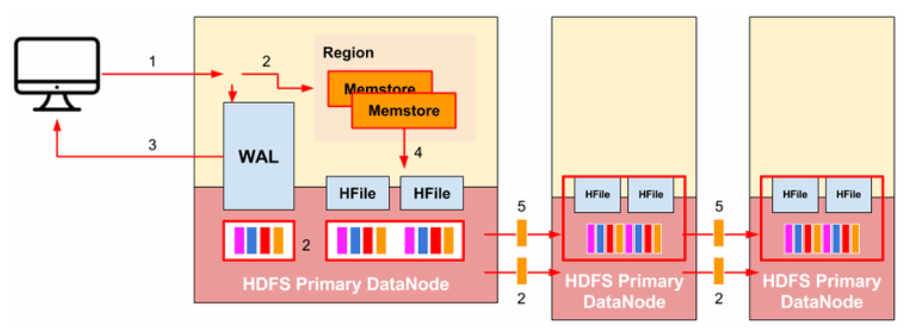
- Client가 데이터를 쓰기 전에 region server를 통하여 region과 통신
- WAL 파일에 append
- region server는 데이터를 복구할 때 (replay) WAL 파일을 사용A
- WAL 에 쓰여진 데이터는 memstore에 복사
- 한 번 memstore에 위치하게 되면, client에게 데이터를 받았다고 알림
- Memstore의 threshold에 이르게 되면, 가지고 있던 데이터들을 HFile에 dump 하거나 commit (flush)
Read Mechanism
- Client가 읽기 요청
- Scanner가 먼저 block cache 에서 row cell을 찾음
(최근에 읽은 key-value pair가 저장되어 있음) - Scanner가 실패하면, memstore로 이동
(아직 dump 되지 않았다면 memstore에 있음) - Memstore에서 찾지 못할 경우, bloom filter와 block cache를 이용해서 HFile 로부터 데이터를 가지고 옴
