저번주 : Categorical descriptive feature(범주형)
오늘 : continuous descriptive feature(연속형), continuous일땐 같은 feature 다시 써도 됨
feature가 continuous
- 기본엔트로피 구하기
print((-2 * 2/7 * math.log2(2/7)) - (3/7 * math.log2(3/7)))- root node 후보 6개의 IG값 구해서 최대값으로 ROOT NODE 선정
elevation threshold(750, 1350, 2250, 4175 / class 바뀌는 거 기준으로),stream, slope
print(6/7 * (-1/6 * math.log2(1/6) - 1/2 * math.log2(1/2) - 1/3 * math.log2(1/3))) #750
print(2/7 * -math.log2(1/2) + 5/7 * (-1/5 * math.log2(1/5) -2*(2/5 * math.log2(2/5)))) #1350
print(3/7 * (-2/3*math.log2(2/3)-1/3*math.log2(1/3)) + 4/7*(-math.log2(1/2))) #2250
print(5/7 * (-2/5*math.log2(2/5)-3/5*math.log2(3/5))) #4175
print(4/7 * (-1/2*math.log2(1/2)-1/2*math.log2(1/4)) + 3/7*(-2/3*math.log2(2/3)-1/3*math.log2(1/3))) #stream
print(5/7*(-2/5*math.log2(1/5)-3/5*math.log2(3/5))) #slope- 하위노드의 기본엔트로피 구하기
print(-2/5*math.log2(2/5)-3/5*math.log2(3/5))- 하위노드 후보 5개의 IG값 구해서 최대값으로 다음 NODE 선정
elevation threshold(750, 1350, 2250), stream, slope
print(4/5*(-1/4*math.log2(1/4)-3/4*math.log2(3/4))) #750
print(2/5*(-math.log2(1/2)) + 3/5*(-1/3*math.log2(1/3)-2/3*math.log2(2/3))) #1350
print(3/5*(-2/3*math.log2(2/3)-1/3*math.log2(1/3))) #2250, stream
print(4/5*(-1/4*math.log2(1/4)-3/4*math.log2(3/4))) #slope- 그 다음 하위노드 기본 엔트로피 구하기
print(-2/3*math.log2(2/3)-1/3*math.log2(1/3))
- 하위노드 후보 2개 : 2250, stream
print(2/3*-math.log2(1/2))class가 continuous
- 앞에서까지 classification 했었고, 이제 target feature가 continuous한 경우 = regression tree
- regression은 분산 활용. 분산이 감소하는 방향으로 진행(언제 분산이 더 작아지는지 구하는 것)
- regression은 값을 추출하는 것. leaf node안 instance들의 mean ???????????
- 분산 = 편차제곱의 평균
- 모집단의 평균은 표본집단의 평균으로 대체 가능 but 분산은 달라짐
- 표본집단의 분산은 모집단의 분산을 과소평가함. n이 아니라 n-1로 나눠주는 것. 통계적측면
- 자유도 : ???????????
- 분기 이후 weight ???????????
#졸았음.....
#target feature값의 분산으로 ......
#season과 work day 중, 분기 이후의 분산이 더 작아지는 feature로 선택
실제 decision tree 구현해보기
DT_1 사전 실습 : DecisionTreeClassifier
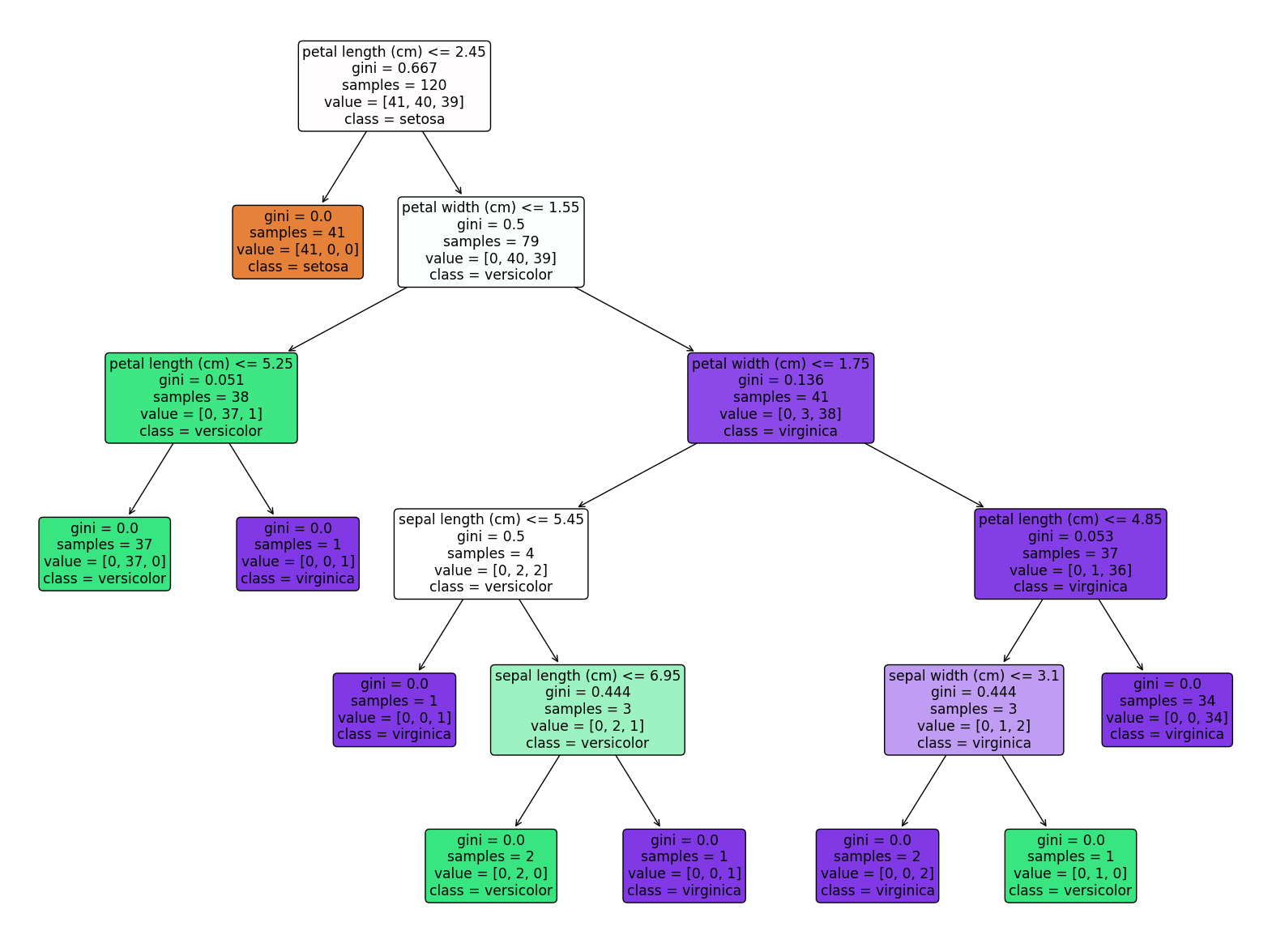
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
#머신러닝 학습시, dataset은 train과 test로 나눠짐. train이 잘 됐는지 test로 확인
#머신러닝은 7~80%가 데이터와 연관되어 있음
#아이리스 데이터 불러오기, dir함수를 통해 아이리스가 어떤 데이터를 가지고 있는지 확인가능
iris = load_iris()
data, targets = iris.data, iris.target
print(data.shape, targets.shape, '\n')
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target,
test_size = 0.2, random_state = 11)
#random_state : 랜덤하게 뽑힌 값을 고정해서 계속 쓰도록 설정
print(f"{type(X_train) = } / {X_train.shape = }")
print(f"{type(X_test) = } / {X_test.shape = }")
print(f"{type(y_train) = } / {y_train.shape = }")
print(f"{type(y_test) = } / {y_test.shape =}\n")
model = DecisionTreeClassifier()
#attribute(method) 뽑아내는 코드
for attr in dir(model):
if not attr.startswith("__"):
print(attr)
model.fit(X_train, y_train)
print("depth:", model.get_depth())
print("number of leaves", model.get_n_leaves)
accuracy = model.score(X_test, y_test)
#print(f"{accuracy = :.4f}")
#지니 이용했음.
import matplotlib.pyplot as plt
from sklearn import tree
plt.figure(figsize = (20, 15))
tree.plot_tree(model, class_names = iris.target_names,
feature_names = iris.feature_names,
impurity = True, filled = True,
rounded = True)
plt.show()DT_1 : DecisionTreeRegressor
- 이어서 해야함. 지금은 그냥 DecisionTreeClassifier -> DecisionTreeRegressor한 것뿐. 색만 바뀐듯
- regression에서 이용되는 모델학습평가지수는 R^2(결정계수), model.score값과 직접계산한 R^2(결정계수)값 일치하는지 확인
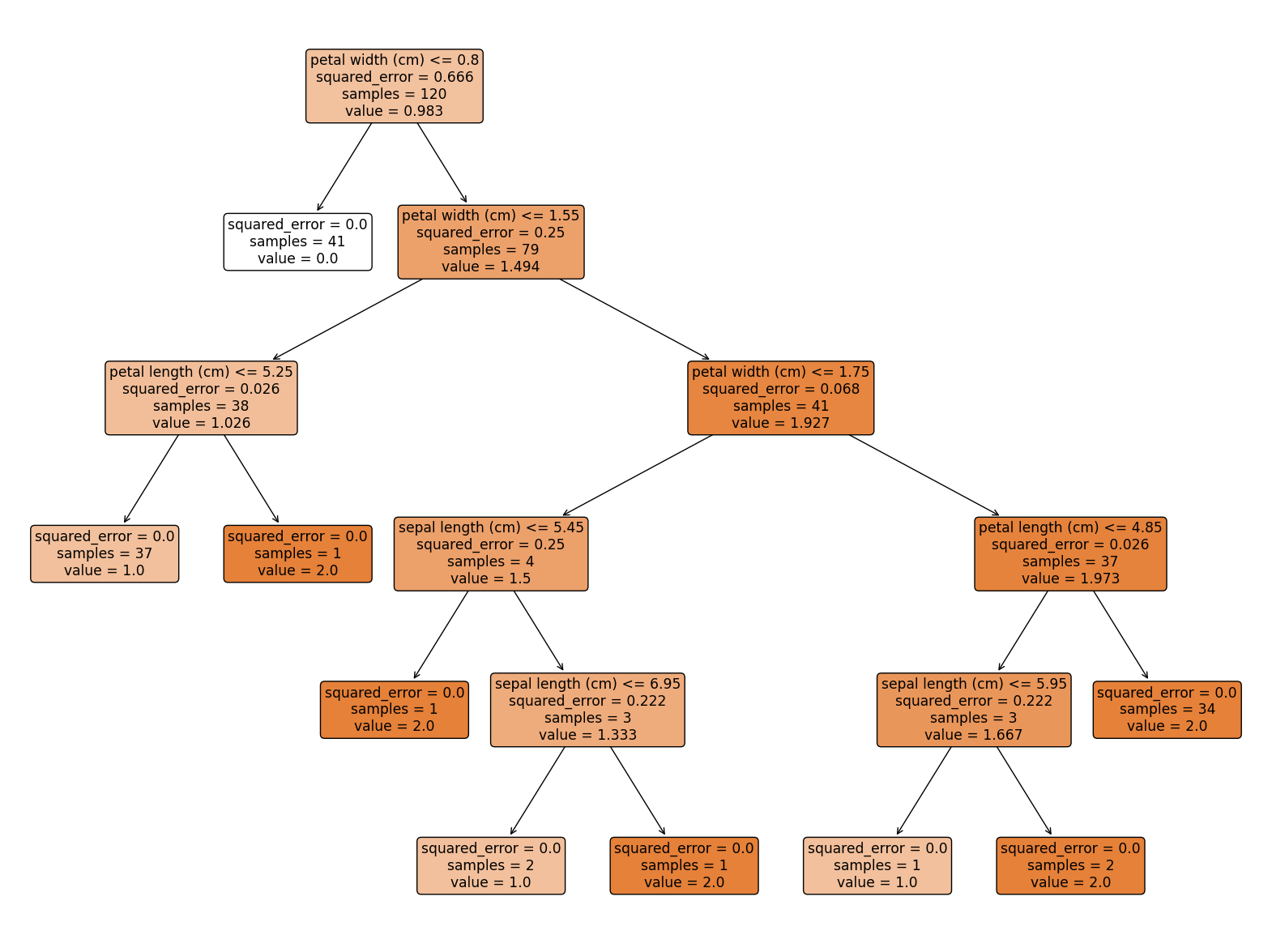
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
#머신러닝 학습시, dataset은 train과 test로 나눠짐. train이 잘 됐는지 test로 확인
#머신러닝은 7~80%가 데이터와 연관되어 있음
#아이리스 데이터 불러오기, dir함수를 통해 아이리스가 어떤 데이터를 가지고 있는지 확인가능
iris = load_iris()
data, targets = iris.data, iris.target
print(data.shape, targets.shape, '\n')
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target,
test_size = 0.2, random_state = 11)
#random_state : 랜덤하게 뽑힌 값을 고정해서 계속 쓰도록 설정
print(f"{type(X_train) = } / {X_train.shape = }")
print(f"{type(X_test) = } / {X_test.shape = }")
print(f"{type(y_train) = } / {y_train.shape = }")
print(f"{type(y_test) = } / {y_test.shape =}\n")
model = DecisionTreeRegressor()
#attribute(method) 뽑아내는 코드
for attr in dir(model):
if not attr.startswith("__"):
print(attr)
model.fit(X_train, y_train)
print("depth:", model.get_depth())
print("number of leaves", model.get_n_leaves)
accuracy = model.score(X_test, y_test)
#print(f"{accuracy = :.4f}")
#지니 이용했음.
import matplotlib.pyplot as plt
from sklearn import tree
plt.figure(figsize = (20, 15))
tree.plot_tree(model, class_names = iris.target_names,
feature_names = iris.feature_names,
impurity = True, filled = True,
rounded = True)
plt.show()
안녕하세요를레히