요약 : 파이썬 100문 day4, nested list 데이터 활용한 표준화 계산, histogram, confusion matrix, accuracy, abs, manhattan distance
Accuracy 모델 정확도 구하기
predictions = [0, 1, 0, 2, 1, 2, 0]
labels = [1, 1, 0, 0, 1, 2, 1]
n_correct = 0
for pred_idx in range(len(predictions)):
if predictions[pred_idx] == labels[pred_idx]:
n_correct+=1
accuracy = n_correct / len(predictions)
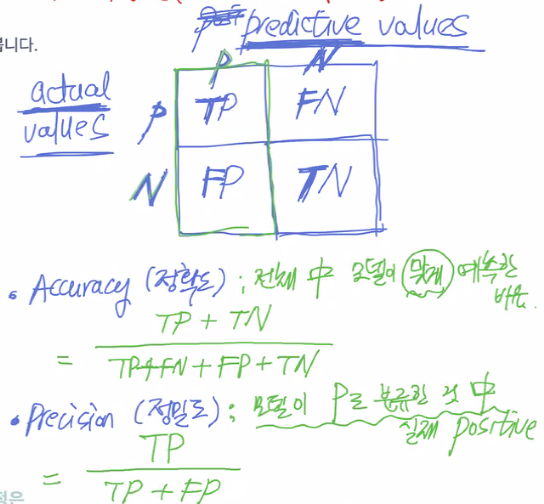
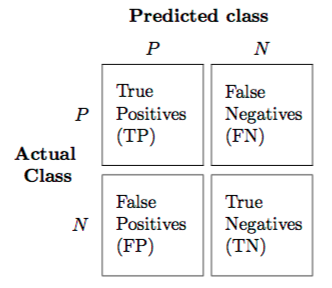
print("accuracy[%]: ",accuracy*100,'%')confusion matrix(confusion vector_임의명칭)
- 인공지능 성능평가때 쓰임
- 모델의 성능평가 지표
- x축 : predictive values(모델예측값)
- y축 : actual values(실제예측값)
- 이를 통해 도출할 수 있는 값
-accuracy(정확도) : 전체 중 모델이 맞게 예측한 비율
-precision(정밀도) : 모델이 positive로 분류한 것 중 실제 positive

#class별 accuracy를 구했다고 보면 됨
predictions = [0, 1, 0, 2, 1, 2, 0]
labels = [1, 1, 0, 0, 1, 2, 1]
n_classes = None
for label in labels:
if n_classes == None or label > n_classes:
n_classes = label
n_classes += 1 #n_classes는 2+1=3
print(n_classes)
class_cnts, correct_cnts, confusion_vec = list(), list(), list()
for _ in range(n_classes):
class_cnts.append(0)
correct_cnts.append(0)
confusion_vec.append(None)
for pred_idx in range(len(predictions)):
pred = predictions[pred_idx]
label = labels[pred_idx]
class_cnts[label] += 1 #0,1,2로 구성된 데이터라는걸 알아서 이렇게 하는거임?
if pred == label:
correct_cnts[label] += 1
print(class_cnts)
#밑에 계산이 이해가 안됨;;
for class_idx in range(n_classes):
confusion_vec[class_idx] = correct_cnts[class_idx] / class_cnts[class_idx]
print("confusion vector: ", confusion_vec)histogram
scores = [50, 20, 30, 40, 10, 50, 70, 80, 90, 20, 30]
cutoffs = [0, 20, 40, 60, 80]
histogram = [0, 0, 0, 0, 0]
for score in scores:
if score > cutoffs[4]:
histogram[4] += 1
elif score > cutoffs[3]:
histogram[3] += 1
elif score > cutoffs[2]:
histogram[2] += 1
elif score > cutoffs [1]:
histogram[1] += 1
elif score > cutoffs [0]:
histogram[0] += 1
else:
pass절대값 구하기 abs=absolute
numbers = [-2, 2, -1, 3, -4, 9]
abs_numbers = list()
for num in numbers:
if num < 0:
abs_numbers.append(-num)
else:
abs_numbers.append(num)
print(abs_numbers)
Manhattan Distance
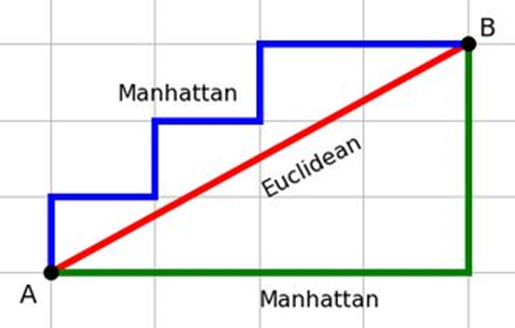
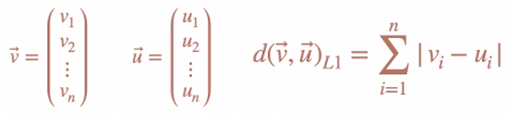
v1 = [1, 3, 5, 2, 1, 5, 2]
v2 = [2, 3, 1, 5, 2, 1, 3]
m_distance = 0
for dim_idx in range(len(v1)):
sub = v1[dim_idx] - v2[dim_idx]
if sub < 0:
m_distance += -sub
else:
m_distance += sub
print("Manhattan distance: ", m_distance)Nested List
- Nested List = list인 list -> 행렬형태
- 스칼라->list1개->list2개 = 행렬
- 지금부터는 특히나 더 중요함. 우리가 다루는 데이터들은 대부분 행렬
scores = [[10, 20, 30], [50, 60, 70]]
print(scores)
print(scores[0])
print(scores[1])
print(scores[0][0], scores[0][1], scores[0][2])
print(scores[1][0], scores[1][1], scores[1][2])
#for문으로 행렬에 접근하기
for student_scores in scores:
print(student_scores)
for score in student_scores:
print(score)평균계산
- 어려웠음!!!! 복습 잘하기, 코드 이해 다시하기
scores = [[10, 15, 20], [20, 25, 30], [30, 35, 40], [40, 45, 50]]
n_students = len(scores)
n_subjects = len(scores[0])
subject_score_sums = list()
subject_score_means = list()
##학생별 평균점수
student_score_means = list()
for student_scores in scores:
student_score_sum = 0
for score in student_scores:
student_score_sum += score
student_score_means.append(student_score_sum / n_subjects)
print("mean of students' scores: ", student_score_means)
##과목별 평균점수***
###set the sum of subject scores as 0
for _ in range(n_subjects):
subject_score_sums.append(0)
###calculate the sum of subject scores
for student_scores in scores:#리스트 안의 리스트 요소에 접근
for subject_idx in range(n_subjects):
subject_score_sums[subject_idx] += student_scores[subject_idx]
print("sum of subjects' scores: ", subject_score_sums)
###calculate the mean of subject scores
for subject_idx in range(n_subjects):
subject_score_means.append(subject_score_sums[subject_idx] / n_students)
print("mean of subjects' scores: ", subject_score_means)mean subtraction(앞 코드에 이어서)
- for student_idx in range(n_students):
for subject_idx in range(n_subjects):
-중첩 for문 : 단계적으로 인덱스에 접근한 것. 왜냐면 뒤에서 [student_idx][subject_idx]로 인덱스로의 접근이 필요하기 때문
for student_idx in range(n_students):
for subject_idx in range(n_subjects):
scores[student_idx][subject_idx] -= subject_score_means[subject_idx]
print("scores after mean subtraction: ", scores)
subject_score_sums = list()
subject_score_means= list()
#set the sum of subject scores as 0
for _ in range(n_subjects):
subject_score_sums.append(0)
#calculate the sum of subject scores
for student_scores in scores:
for subject_idx in range(n_subjects):
subject_score_sums[subject_idx] += student_scores[subject_idx]
print("sum of subjects' scores after mean subtraction: ", subject_score_sums)
#calculate the mean of subject scores
for subject_idx in range(n_subjects):
subject_score_means.append(subject_score_sums[subject_idx] / n_students)
print("mean of subjects' scores after mean subtraction: ", subject_score_means)분산, 표준편차, standardization
- 직접 코드 구성해보는 연습을 한 거라서 코드 매우 더러움...
scores = [[10, 15, 20], [20, 25, 30], [30, 35, 40], [40, 45, 50]]
n_students = len(scores)
n_subjects = len(scores[0])
subject_score_sums = list()
subject_score_means = list()
##과목별 점수의 합
###set the sum of subject scores as 0
for _ in range(n_subjects):
subject_score_sums.append(0)
###calculate the sum of subject scores
for student_scores in scores:#리스트 안의 리스트 요소에 접근
for subject_idx in range(n_subjects):
subject_score_sums[subject_idx] += student_scores[subject_idx]
print("sum of subjects' scores: ", subject_score_sums)
##과목별 점수의 평균
for subject_idx in range(n_subjects):
subject_score_means.append(subject_score_sums[subject_idx] / n_students)
print("mean of subjects' scores: ", subject_score_means)
#과목별 점수의 평균의 제곱
square_of_means = list()
for means in subject_score_means:
square_of_means.append(means**2)
print("square_of_means: ", square_of_means)
#과목별 점수의 제곱과 그것의 평균
square_scores=scores.copy()
for student_idx in range(n_students):
for subject_idx in range(n_subjects):
square_scores[student_idx][subject_idx] **=2
print("square_scores: ", square_scores)
print(scores) #copy함수 썼는데 원본 바뀜.....뭐가문제일까
square_score_sums=list()
for _ in range(n_subjects):
square_score_sums.append(0)
for student_scores in scores:
for subject_idx in range(n_subjects):
square_score_sums[subject_idx] += student_scores[subject_idx]
print("sum of subjects' square scores: ", square_score_sums)
square_score_means = list()
for subject_idx in range(n_subjects):
square_score_means.append(square_score_sums[subject_idx] / n_students)
print("mean of subjects' square scores: ", square_score_means)
#variance
variance = list()
for subject_idx in range(n_subjects):
variance.append(square_score_means[subject_idx]-square_of_means[subject_idx])
print("variance: ", variance)
#standard deviation
std = list()
for subject_idx in range(n_subjects):
std.append(variance[subject_idx]**0.5)
print("standard deviation: ", std)
#standardization
original_scores = [[10, 15, 20], [20, 25, 30], [30, 35, 40], [40, 45, 50]]
print(subject_score_means)
#폐기 print(original_scores[1][0]-int(subject_score_means[0]))
print(std)
for student_idx in range(n_students): #4번
for subject_idx in range(n_subjects): #3번
score = original_scores[student_idx][subject_idx]
mean = subject_score_means[subject_idx]
standard = std[subject_idx]
original_scores[student_idx][subject_idx] = (score - mean) / standard
#폐기 original_scores[student_idx]=((original_scores[student_idx][subject_idx]-int(subject_score_means[subject_idx])))/std
print("scores after standardization: ", original_scores)
#--------------------------------------------------------------------------
subject_score_sums = list()
subject_score_means = list()
##과목별 점수의 합
###set the sum of subject scores as 0
for _ in range(n_subjects):
subject_score_sums.append(0)
###calculate the sum of subject scores
for student_scores in original_scores:#리스트 안의 리스트 요소에 접근
for subject_idx in range(n_subjects):
subject_score_sums[subject_idx] += student_scores[subject_idx]
print("\nsum of subjects' scores: ", subject_score_sums)
##과목별 점수의 평균
for subject_idx in range(n_subjects):
subject_score_means.append(subject_score_sums[subject_idx] / n_students)
print("mean of subjects' scores: ", subject_score_means)
#과목별 점수의 평균의 제곱
square_of_means = list()
for means in subject_score_means:
square_of_means.append(means**2)
print("square_of_means: ", square_of_means)
#과목별 점수의 제곱과 그것의 평균
square_scores=original_scores.copy()
for student_idx in range(n_students):
for subject_idx in range(n_subjects):
square_scores[student_idx][subject_idx] **=2
print("square_scores: ", square_scores)
square_score_sums=list()
for _ in range(n_subjects):
square_score_sums.append(0)
for student_scores in original_scores:
for subject_idx in range(n_subjects):
square_score_sums[subject_idx] += student_scores[subject_idx]
print("sum of subjects' square scores: ", square_score_sums)
square_score_means = list()
for subject_idx in range(n_subjects):
square_score_means.append(square_score_sums[subject_idx] / n_students)
print("mean of subjects' square scores: ", square_score_means)
##variance
variance = list()
for subject_idx in range(n_subjects):
variance.append(square_score_means[subject_idx]-square_of_means[subject_idx])
print("variance: ", variance)
##standard deviation
std = list()
for subject_idx in range(n_subjects):
std.append(variance[subject_idx]**0.5)
print("standard deviation: ", std)
안녕하세요를레히