Keywords
- seq2seq
- Attention Function (Query, Key, Value)
- Attention Score / Attention Weight / Attention Value (Context Vector)
- Transformer
- MultiModal
Attention Mechanism
Attention Mechanism은 매 시점 (Time-step)의 출력을 예측할 때 Input Sequence가 전달된 모든 Encoder의 Hidden State를 참고하여 출력의 정확도를 높이는 메커니즘이다.
What the Attention component of the network will do for each word in the output sentence is map the important and relevant words from the input sentence and assign higher weights to these words, enhancing the accuracy of the output prediction.
출력 문장의 각 단어에 대해 Attention의 역할은 입력데이터의 중요하고 관련있는 단어를 찾아내고, 특별한 가중치를 부여하여 출력에 참고해야할 단어를 집중하기때문에 정확도를 개선 시킬수 있다
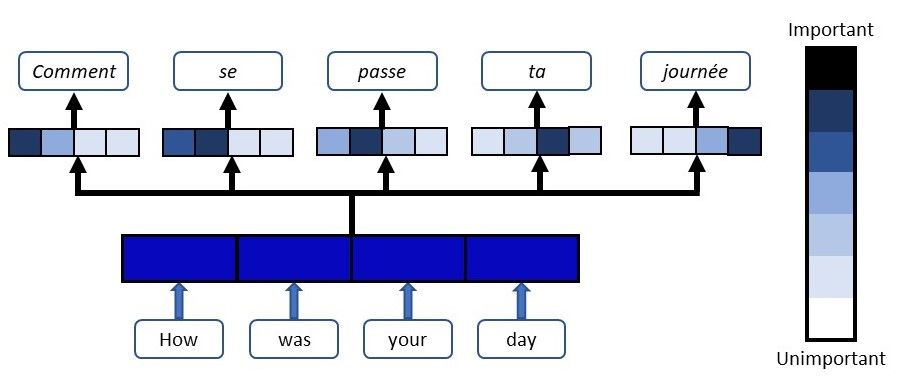
위는, Attention을 Seq2Seq을 차용한 기계번역 모델이다. 입력 시퀀스의 각 단어는, 출력 문장의 각 단어와의 관계에 따라 중요도를 표시하는 색으로 표현했다.
참고: 일반적인 seq2seq 모델은, Encoder의 Input Sequence를 Context Vector 라는 고정된 크기의 벡터에 정보를 압축하고, Decoder는 Context Vector를 통해 출력 시퀀스를 만들어 냈다.
Attention Function
Attention Value를 구하기 위한 함수이다.
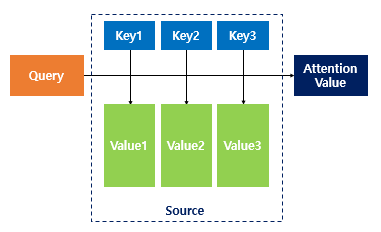
출처: https://wikidocs.net/22893
Attention Function(Q,K,V) = Attention Value
Q: Query (t시점에서 Decoder의 은닉 상태 based on Luang Attention)
K: Key (모든 시점 Encoder 셀의 은닉 상태)
V: Value (모든 시점의 Encoder 셀의 은닉 상태)Q와 K의 유사도(Attention Score)를 계산 하여 이를 압축된 정보인 Value에 적용한다.
해당 Value는 모든 입력 시퀀스에 대해서 가중치를 고려한 정보를 포함한 벡터가 된다. (Context Vector)
Attention Mechanism Process
다음과 같이, Decoder의 Hidden State인 가 모든 시점의 Encoder Hidden State를 참고하여 Attention Value를 구하는 과정을 살펴보자.
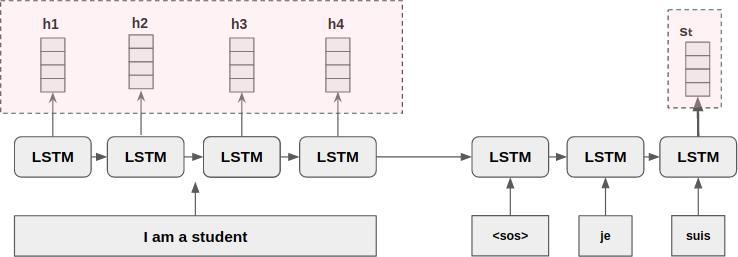
- = {h1,h2,h3,h4} 는 Encoder의 은닉상태.
- 는 디코더의 은닉상태.
Generating Attention Score
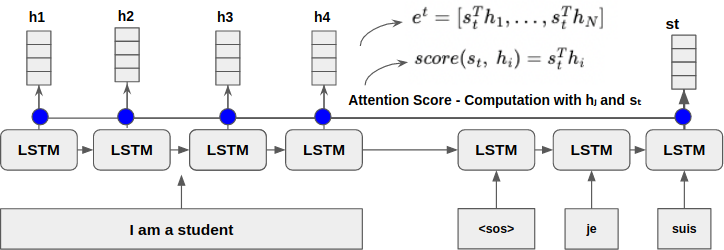
Attention Score는 Decoder로 전달된 Hidden State와 Encoder의 Hidden State와의 유사도를 구하여 추후 예측시 도움이 되도록 가공해야 한다.
해당 이미지에서 사용되는 Attention Score함수는 와 를 서로 내적하는 간단한 함수이다. ()
Get Attention Distribution and Weight
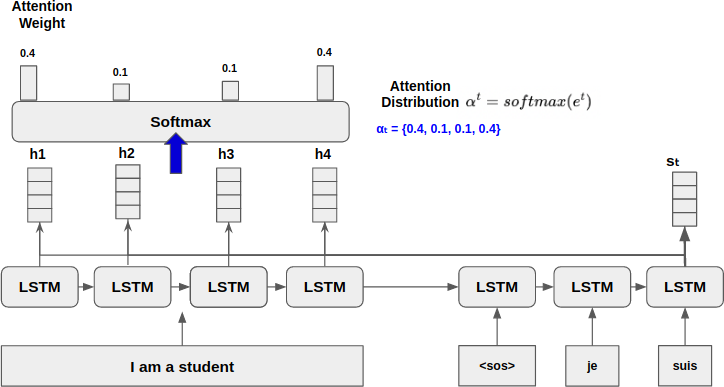
를, Softmax를 통과 시켜, Attention Distribution 를 구한다.
의 각 원소는 Attention Weight라고 하며, 굉장히 중요한 역할을 가진다. 해당 가중치에 따라, 예측값에 영향을 주는 입력 시퀀스의 중요도가 결정된다.
Get Attention Value
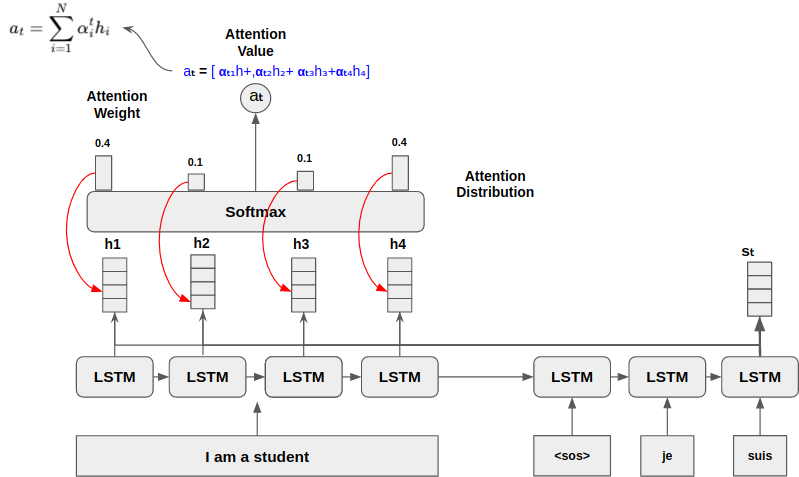
이제, 출력에 영향을 줄 각 입력 시퀀스의 중요도를 결정해야한다.
가 가지는 Attention weight를 각 Encoder의 Hidden State와 곱해주고 이를 가중합 (Weighted Sum)하여 Attention Value를 구한다.
Attention Value는 입력 시퀀스 정보를 가지는 벡터이기때문에, Context Vector라고 불린다.
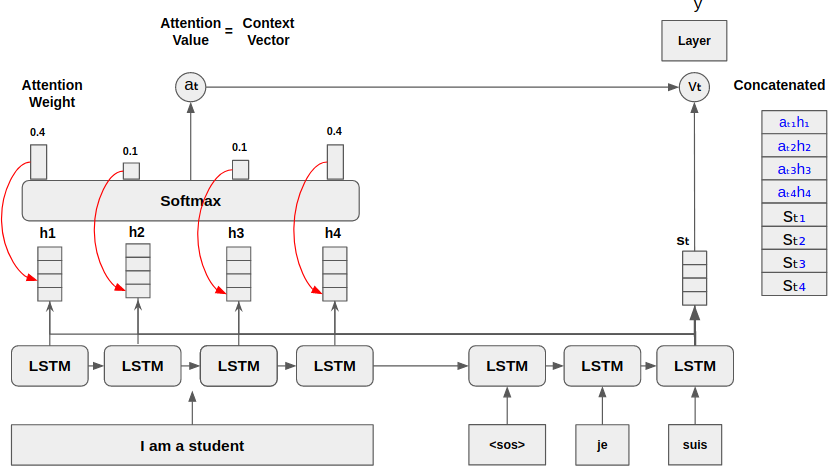
Concatenate Context Vector with Hidden State of Decoder
입력 시퀀스의 정보를 디코더의 Hidden State가 참고하기위해서는 벡터 2개를 서로 Concatenate 하고, 이를 출력층으로 보내 출력 값을 예측한다.
Variety of Attention Model
Attention Mechanism의 주요 모델은 Bahdanau 와 Luong에 의해 제안된 모델이다
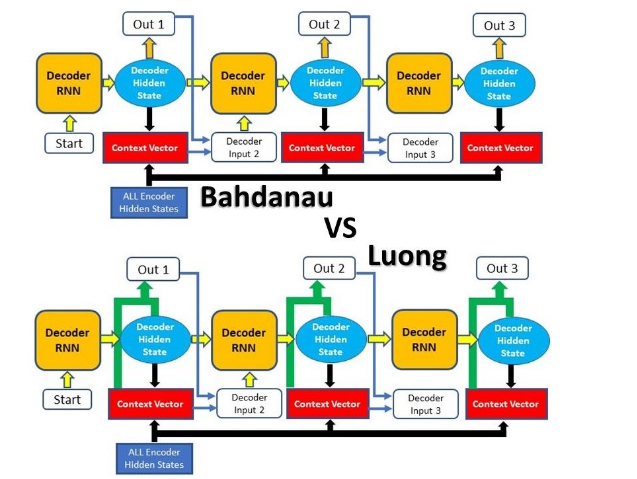
출처: https://blog.floydhub.com/attention-mechanism/#bahdanau-att-step4
주요 차이점은,
1. Attention Score를 계산하는 방법
- Dot Product,
- 하이퍼 볼릭 탄젠트:
- 어떤 시점(Time-Step)의 Decoder가 Encoder의 Hidden State를 참조하는지 (t시점 또는 t-1시점)
참고 페이지
