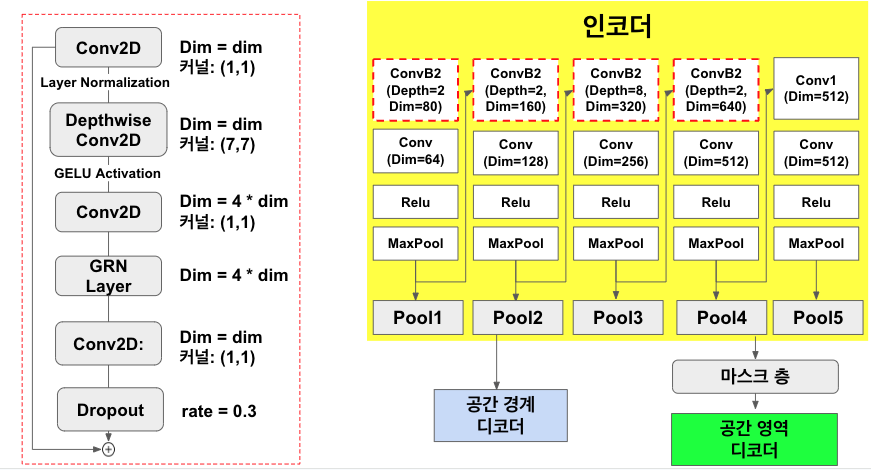
연구의 방향을 잡기위해서 아래와 같이 고민했다.
기존의 Deep Floor Plan Recognition Using a Multi-Task Network with Room-Boundary-Guided Attention은 2014년도에 소개 된 VGG-16을 사용하여 Encoder - Decoder 모델로 설계하였기에, 다소 오래된 아키텍쳐이다. 따라서, 최신 네트워크를 참고하여 이를 Encoder - Decoder 아키텍쳐를 설계하고, 지도생성 결과를 도출했다.
- 선정 네트워크: ConvNext V2
- 기준:
- 최신 네트워크이며, 엔코더와 디코더 아키텍쳐를 통해 이미지 특징 추출 및 복원에 특화되어야한다.
- 관련 코드
- 관련 자료:
- 논문리뷰1 (블로그): https://kimjy99.github.io/논문리뷰/convnext-v2/
- 논문리뷰2 (블로그): https://ostin.tistory.com/149
- 논문리뷰3 (유튜브): https://youtu.be/dO7DlJ6KwMI?si=M5mO7JpR67lTSpkT
- 원작자 소개 (유튜브): https://youtu.be/wXuC7iDZI2M?si=3xwbyYkJtMbC616E
- 코드: https://github.com/facebookresearch/ConvNeXt-V2.git
Overall Network Architecture
- 마스크층: 입력 이미지의 마스크 생성
- 인코더: 마스크된 이미지의 특징 추출
- 공간 경계 디코더: 방 경계 (점유영역, 회색 영역) 패턴 복원
- 공간 유형 디코더: 공간 유형 (점유영역, 자유 영역) 패턴 복원.
주목할점으로, 입력 단계에서 마스크 층을 통과하게 되는데, 여기서 ConvNextV2의 FCMAE 개념을 빌렸다.
입력(Input)
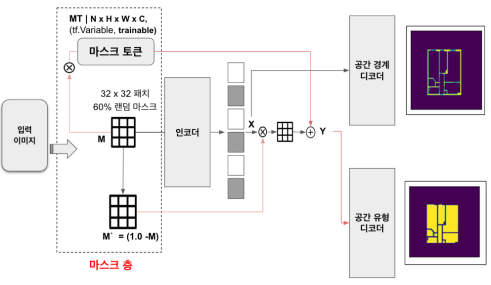
입력 이미지는 마스크 층을 통과하며, 32x32 크기의 패치로 전체 이미지의 60%를 무작위로 마스크하여 인코더로 전달하고, 평면도가 지니는 특징을 추출한다. 이후, 공간 경계 디코더와 공간 유형 디코더에 추출된 특징이 각각 전달되는데, 공간 경계 디코더에는 인코더의 출력을 그대로 넘겨주고, 공간 유형 디코더에는 학습가능한 마스크 토큰 Y를 전달한다. 본래 두개 디코더 모두 마스크 토큰을 적용하려 했으나, 오히려 성능이 떨어지는 문제가 있어 경험적 접근 방법으로, 공간 경계 디코더에는 인코더의 출력에 마스크 토큰을, 공간 유형 디코더에는 인코더 출력을 그대로 전달하였다.
인코더
평면도의 특징을 추출하는 인코더의 구조는 다음과 같다.
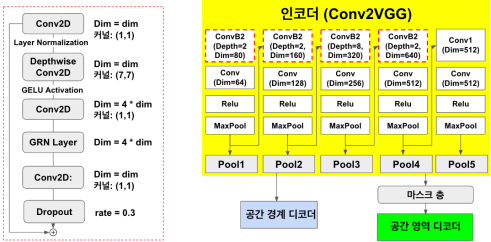
인코더의 출력은 64, 128, 256, 512 채널로 구성되며, 이는 각 단계별로 다양한 깊이와 차원으로 구성된 Conv2B 블럭에서 특징을 전달받는다. 여기서 ConvB2 블럭은 기존 파이토치(Pytorch)로 작성된 ConvNextV2 아키텍처를 모방하여 텐서플로우에서 구현했으며, 깊이(Depth) [2, 2, 8, 2], 차원(Dim) [80, 160, 320, 640]으로 구성하였다.
어텐션 가중치를 주기 위해 Pool1, Pool2, Pool3, Pool4, Pool5를 디코더에 전달한다.
디코더
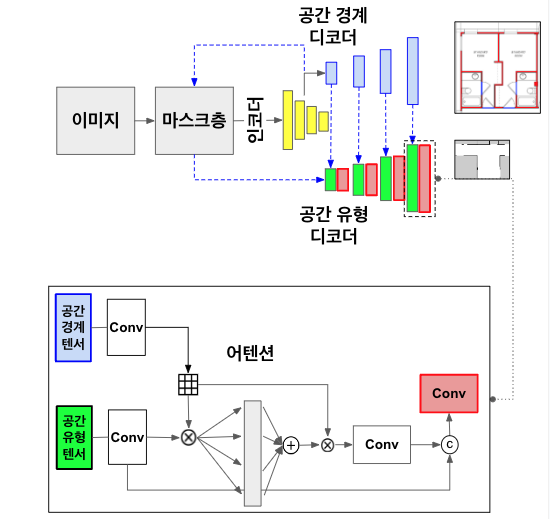
디코더는 공간 경계와 공간 유형을 생성하는 2개의 다중 네트워크로 구성된다.
공간 경계 디코더
공간 경계 디코더는 인코더가 전달한 다양한 차원의 특징 맵(pool)들을 입력으로 받아 점진적으로 업샘플링하고, 각 단계에서 특성을 결합하여 최종적으로 공간 경계를 예측하고 공간 유형에 특징을 전달하는 구조이다.
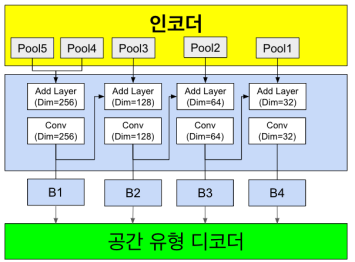
공간 유형 디코더
공간 유형 디코더는 인코더의 출력과 공간 경계 디코더의 출력으로 부터 전달 받은 다양한 해상도의 특징 맵(pool)들을 입력으로 받아 점진적으로 업샘플링하고, 각 단계에서 특성을 결합하여 최종적으로 공간 유형을 예측하는 구조이다.
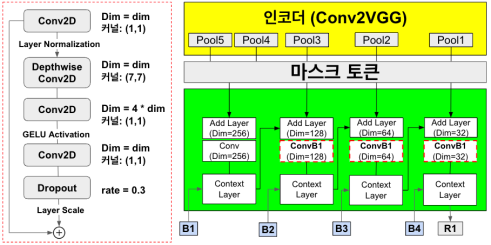
마스크 토큰이 적용된 Pool1, Pool2, Pool3, Pool4, Pool5를 입력으로 받으며, 공간 경계 디코더로부터 전달받은 경계 특징맵인 B1, B2, B3, B4를 함께 입력으로 전달받는다. 첫 번째 단계에서는 Pool5와 Pool4를 결합하여 중간 결과를 생성한 후 컨볼루션 층을 통과하고, 이 중간 결과는 B1과 함께 Context Layer로 입력되어 공간 영역을 예측한다. 컨텍스트 레이어는 두 개의 입력 텐서를 받아 공간적 문맥 정보를 결합하는 역할을 한다.
결론
정확한 FCMAE구조와 ConvNextV2 구조가 아닌 이를 모방한 구조이기때문에, 기대한 모델의 아키텍쳐와는 다소 차이가 있다. 하지만, 결론적으로 기존의 VGG 아키텍처에만 의존하는게 아닌 더 깊은 네트워크와 입력데이터를 다루는 메커니즘을 적용하여 성능에 개선한것으로 의의를 둔다. 실험에 대한 결과는 이후 실험 및 결과 페이지에서 다룬다.
