
Received messages are authentic
이라는 문장은 다음과 같은 의미를 지닙니다.
- 메시지의 내용이 변조되지 않았다. (not altered)
- 메시지를 보낸 사람을 증명할 수 있다. (verify)
- 메시지가 딜레이나 리플레이 되지 않았다. (no delay and replay)
- 순서에 문제가 없다. (sequence)
- 부인 방지(Non-repudiation) = 보낸 사람이 보낸 것을 부인하지 못한다.
목적은 크게 두 가지 입니다.
Data Integrity(데이터 무결성)
메시지가 전송되는 동안 변경(수정) 되어서는 안됩니다.Data origin authentication(데이터 원본 인증)
받는 사람은 메시지의 소스를 확인할 수 있어야 합니다.
이 때 우리가 사용할 것은 바로 HASH 입니다!
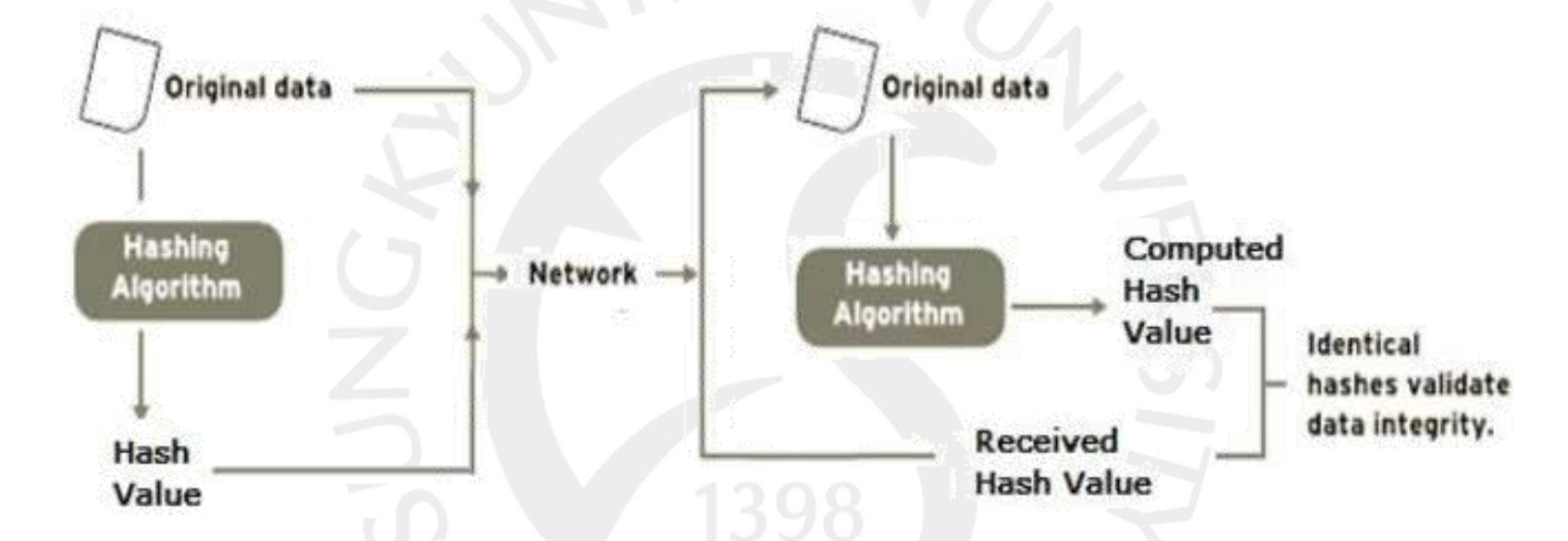
전체적인 그림은 위와 같습니다. 먼저 보내려는 데이터에 해시 알고리즘을 돌려 해당되는 해시 값을 만들어 냅니다. 그 다음에 네트워크를 통해 전송할 때 이 두개를 한번에 모두 보내는 것입니다. 그러면 받는 쪽에서도 마찬가지로 받은 데이터를 해시 알고리즘에 돌려보고 나온 해시 값과 받은 해시값을 비교하여 일치하면 데이터가 변경되지 않은 Data Integrity 를 확보했다 할 수 있는 겁니다.
그렇다면 또 이런 해시 값을 안전한게 전송하는 것이 중요할 텐데 이 때 사용되는 방식에는 아래의 두 가지가 존재합니다.
Message Authentication Code(MAC)Digital Signature
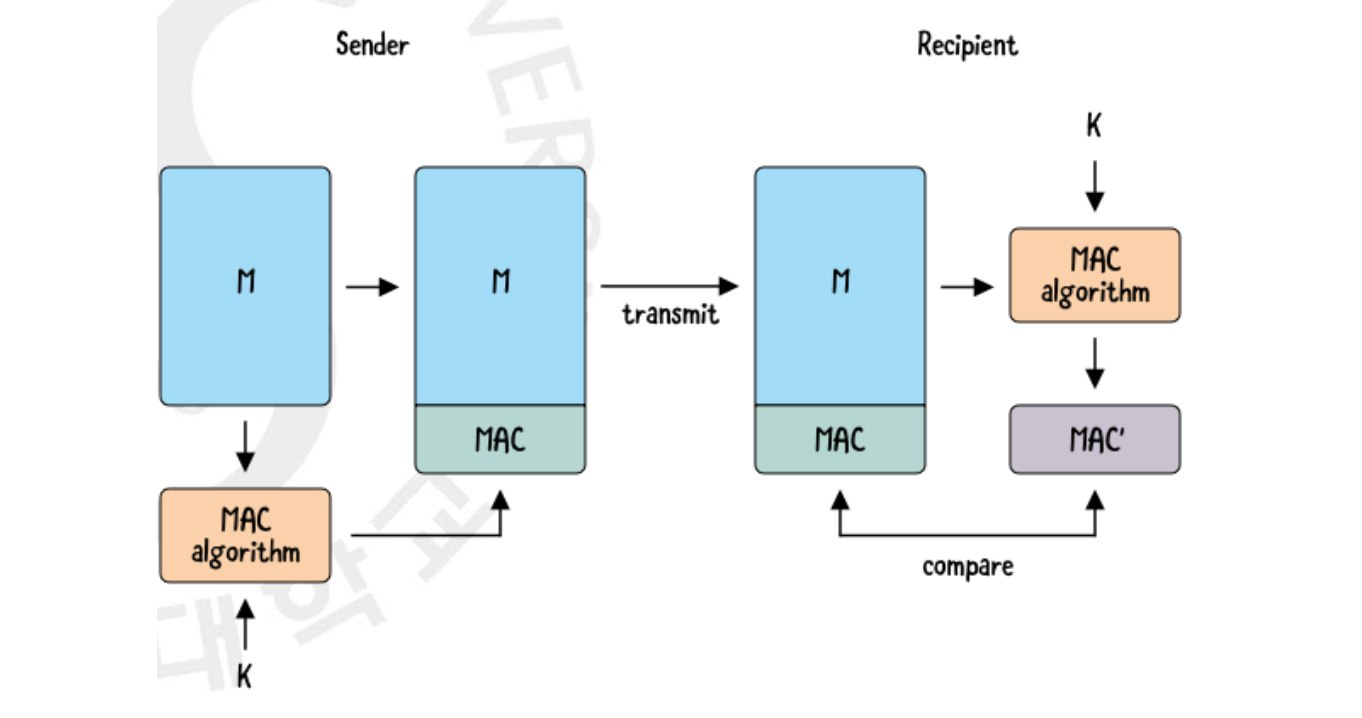
MAC 은 먼저 양쪽에서 메시지를 암복호화 하기 위해 공유한 비밀 키에서 새로운 비밀 키인 를 파생시킵니다. 그 다음에 보내는 쪽에서 공개된 MAC 알고리즘에 이 값을 넣어 MAC 값을 만들고 이를 같이 보내면 반대쪽에서도 같은 로 똑같이 만들어 MAC 값을 비교하는 방식입니다.
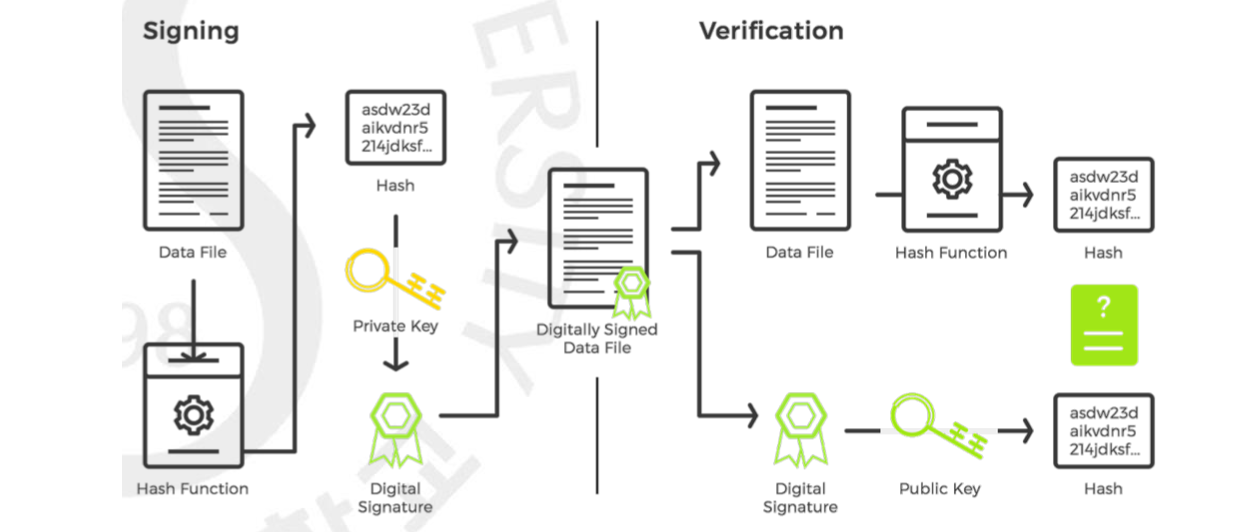
그 다음은 이전 글에서도 설명 드렸던 Digital Signature 방식입니다. 만들어진 해시 값을 자신의 비밀 키로 디지털 서명으로 바꾸어 같이 보냅니다. 받은 쪽에서는 이 서명을 공개 키로 풀어서 해시 값을 확인할 수 있으니 이 값을 자신이 돌려본 해시 값과 비교합니다. 자신이 아닌 그 누구도 이 서명값을 만들 수 없으니 입증이 되는 것이지요.
Hash Function
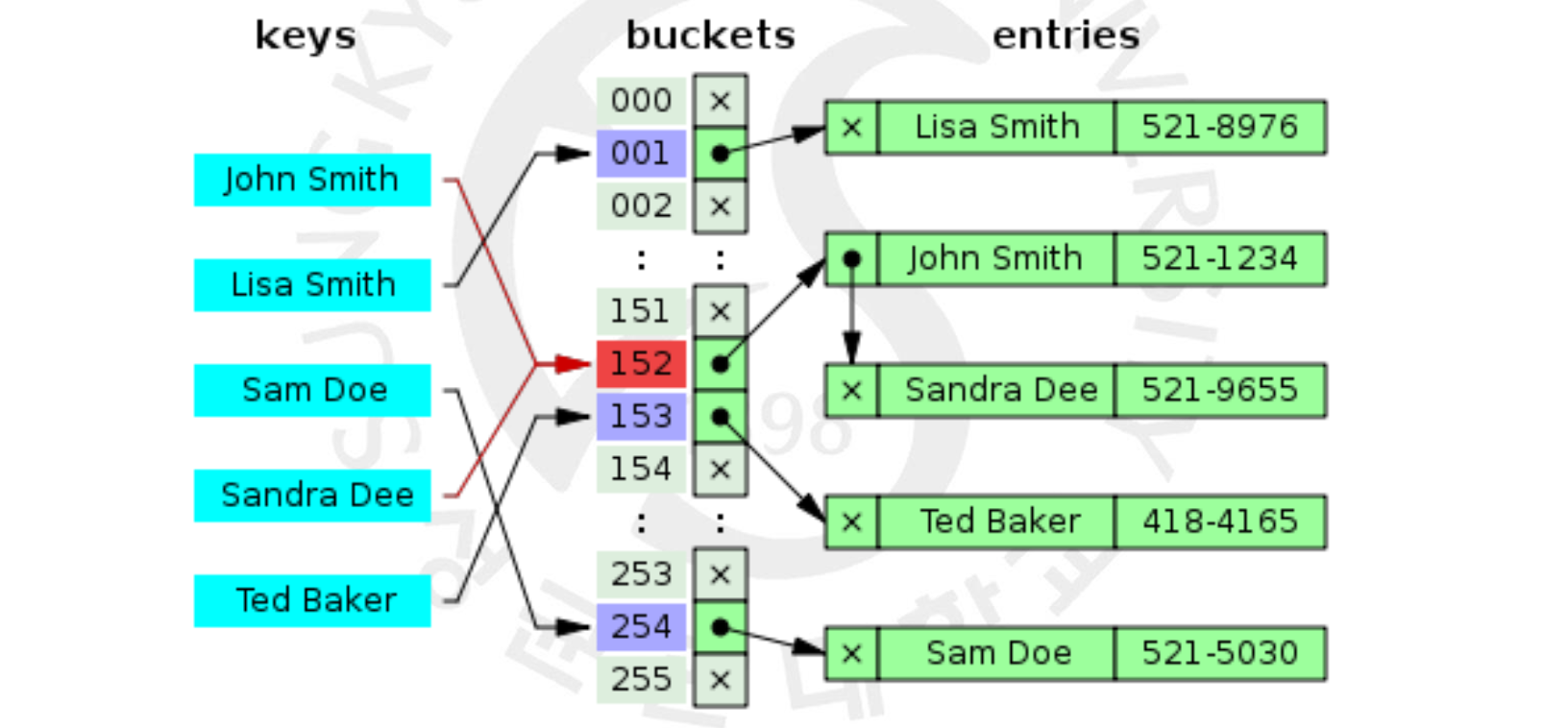
우리가 알고있는 Hash Function(해시 함수) 이라 함은 대게 위와 같은 모양을 하고 있습니다. 어떤 문자열 값을 해시에 넣으면 담길 bucket 의 인덱스에 해당하는 값이 나오고, 각각의 bucket 들은 여러 키 값들을 저장하기 위해 주로 연결 리스트로 이루어져 있지요. bucket 의 값은 제한적이기 때문에 주로 해시 함수에는 나머지 연산이 들어갑니다.
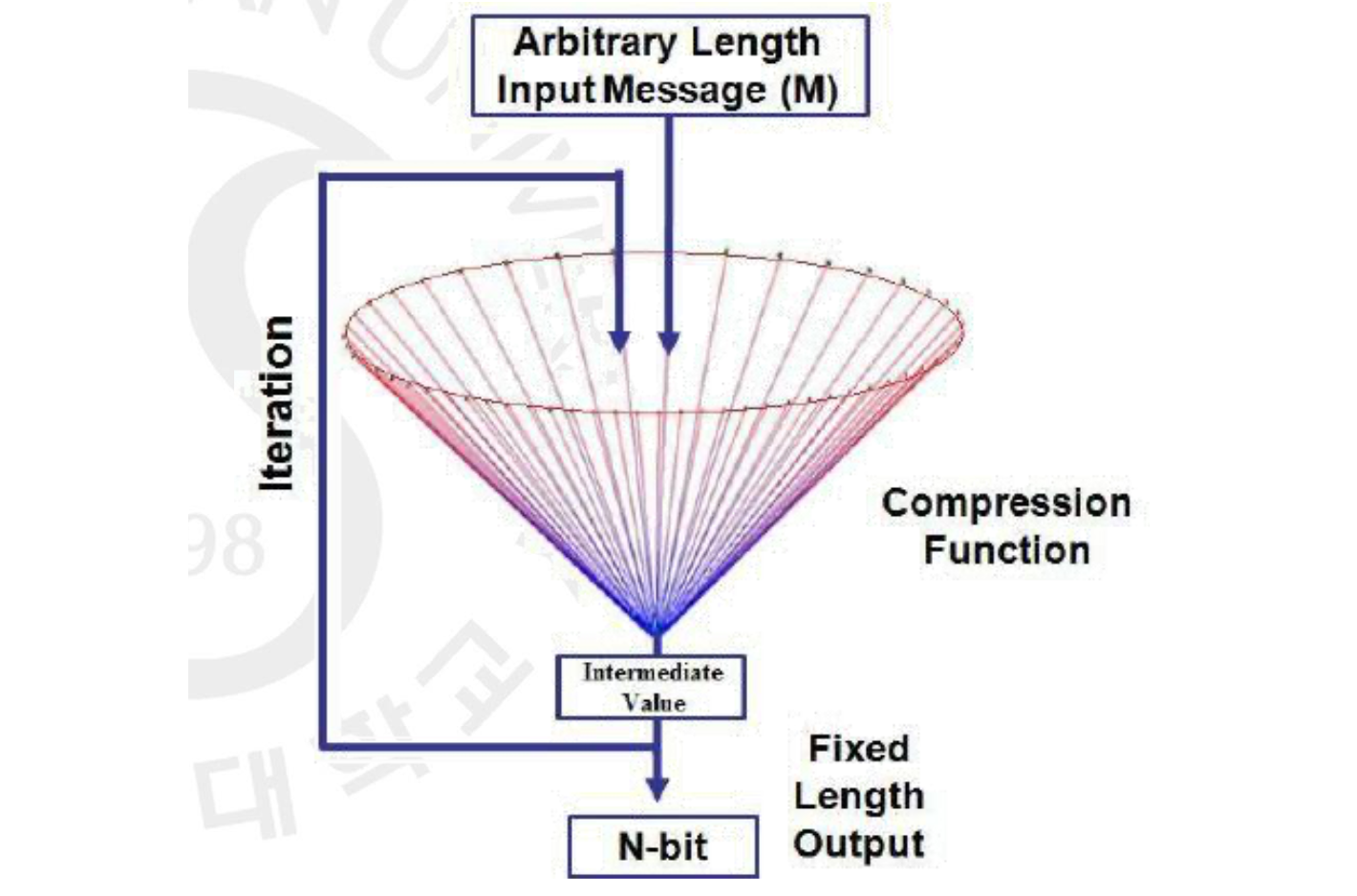
결과적으로 Hash Function 이란 variable-length(다양한 길이) 의 데이터 블록(메시지) 을 받아 fixed-size(고정된 길이)의 해시 값 을 생성합니다. 여기서 은 의 이전 형태라는 뜻으로 Preimage 라고 부릅니다. 좋은 해시 함수라 하믄 굉장히 많은 input들을 골고루 그리고 랜덤 의 형태처럼 분배하며 output을 만들어 내는 함수인 겁니다. 아래는 Hash Function 이 되기 위한 조건입니다.
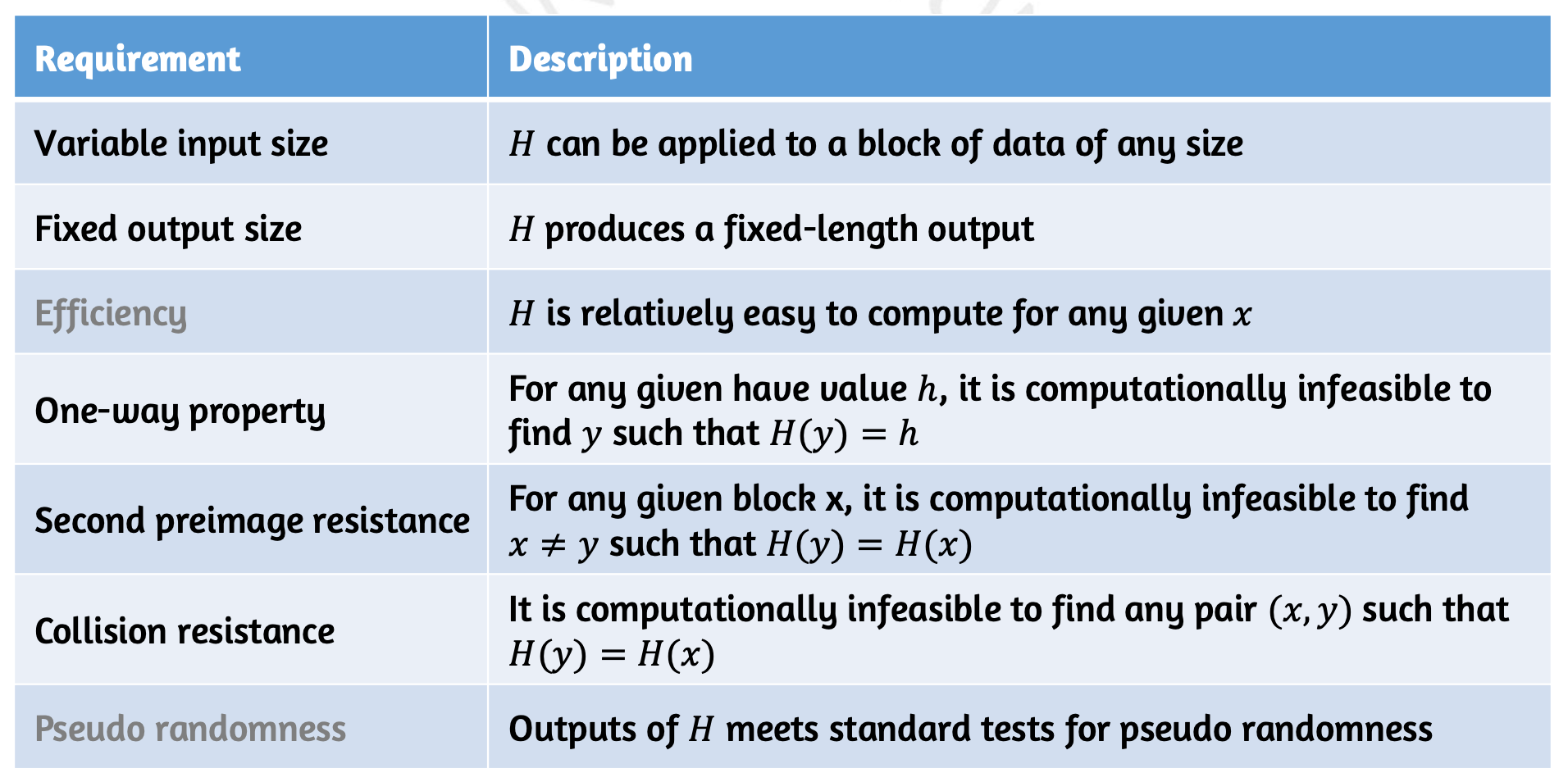
첫 번째, 두 번째는 언급하였으니 세 번째부터 가봅시다. 해시 함수는 계산이 상대적으로 쉽고 빨라야 합니다. 그래서 연산을 돌리는 데에 시간 복잡도가 을 달성하는 것이 우리가 해시를 사용하는 이유 중 하나니까요.
그리고 해시는 One-Way 여야 합니다. 이미 익숙하지요? 를 알 때 해시를 구하는 계산은 쉽고 빠르게 이루어지지만 반대로 해시 값 를 알 때의 를 구하는 것은 컴퓨터 상으로 거의 불가능해야 합니다. irreversible 하다, 한국어로는 비가역성이라고 부르기도 하죠. preimage resistant 라고 표현하기도 하는데, 즉 preimage 를 예측할 수 없어야 합니다. 언급하였듯이 해시는 많고 큰 데이터를 훨씬 작고 제한된 영역으로 위치시키는 함수 입니다. 예를 들어 100 비트의 메시지에 10 비트의 해시를 적용한다고 생각해봅시다. 총 가지의 메시지를 가지의 해시 값으로 만드니 각각의 해시 값은 총 가지의 메시지를 담게 되는 것이지요. 여기서 정확히 어떤 메시지일지 찾아내는 것은 쉽지 않겠죠?
그 다음은 Second Preimage Resistant 로 해시는 두 번째 preimage 를 구할 수 없어야 합니다. 두 번째 라는게 무슨 말이냐면 어떤 가 있을 때 자신과 해시 값이 같은() 다른 값 를 찾는 것이 컴퓨터 상으로 거의 불가능해야 합니다. 그게 가능하다면 메시지를 변경하여도 해시 값이 같아 받은 입장에서는 메시지 변경이 이루어지지 않았다고 생각할 수 있으니까요!😢 이 다섯 번째 조건까지 만족하는 해시 함수를 WEAK 한 해시 함수라고 합니다. 그렇다면 STRONG 한 해시 함수가 되려면 어떠해야 할까요? 다음 나머지 두 조건을 만족해야 합니다.
하나는 Collision Resistant 로 어떤 가 주어진 것은 아니지만 해시 값이 같은 두 쌍 을 찾을 수 있어서도 안됩니다. 예를 들어 Bob 이 Alice 에게 $1000를 빚졌다는 메시지와 $10 빚졌다는 메시지의 해시 값이 같은 걸 안다면 $1000에 Alice 가 사인을 했지만 자기가 사인 받은 건 $10 라고 우길 수 있게 되는 겁니다. 그리고 나머지는 처음에 언급한 Pseudo-Randomness 로 마치 랜덤으로 값이 매겨지는 형태를 지녀야 합니다.
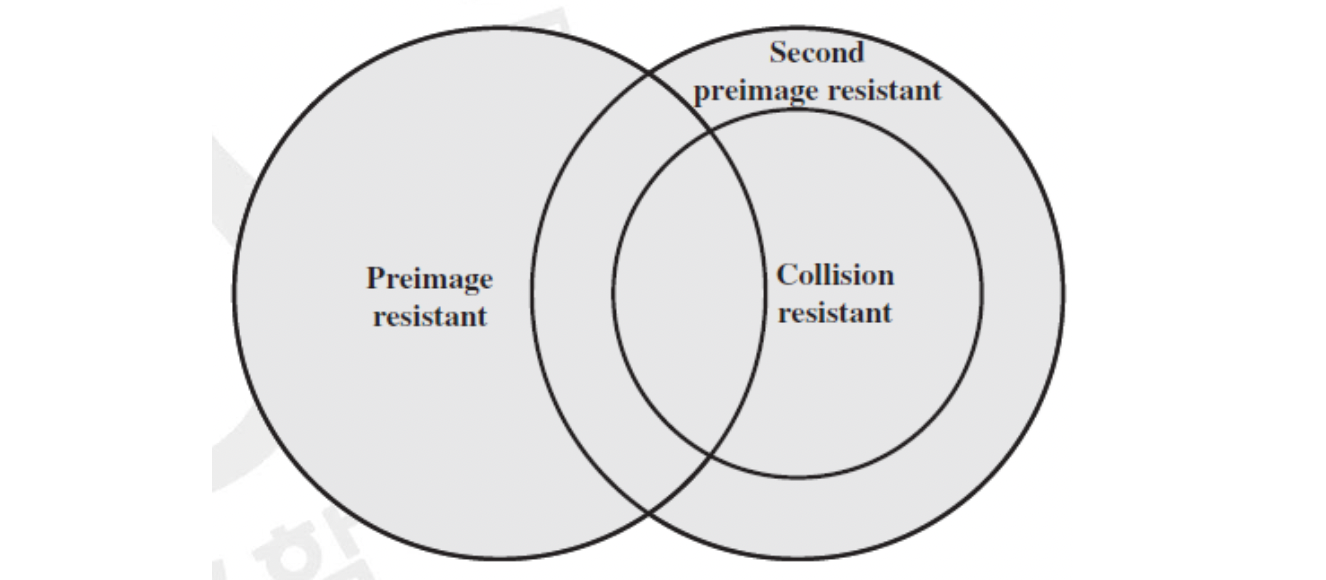
이 조건들의 관계를 집합으로 표현하면 위와 같습니다. 해시 함수를 풀기 위한 방법에는 함수 분석과 더불어 역시나 Brute-Force 방법이 있습니다. 만약 해시 값이 총 비트의 길이를 지닌다면 Brute-Force 를 수행할 경우 가지 경우가 존재하기 때문에 preimage 와 second preimage 를 찾기 위해서는 평균적으로 번 수행해야 합니다.
그런데 우리가 가지 경우의 수에서 랜덤으로 두 수를 골랐을 때 이 두 값이 같을 확률은 수학적으로 이면 반이 넘습니다. 이를 Birthday Paradox 라고 합니다. 생일의 경우의 수는 365로 이기 때문에 9 비트로 표현할 수 있습니다. 따라서 이므로 랜덤으로 모인 23명 중에서 생일이 같은 둘이 존재할 확률이 반이 넘는 것입니다. 이 때문에 Collision Resistant 를 깨기 위해서는 평균적으로 번의 전수 조사가 필요하게 됩니다. 이것이 해시의 Strength 의 핵심이지요.
Secure Hash Algorithm(SHA)
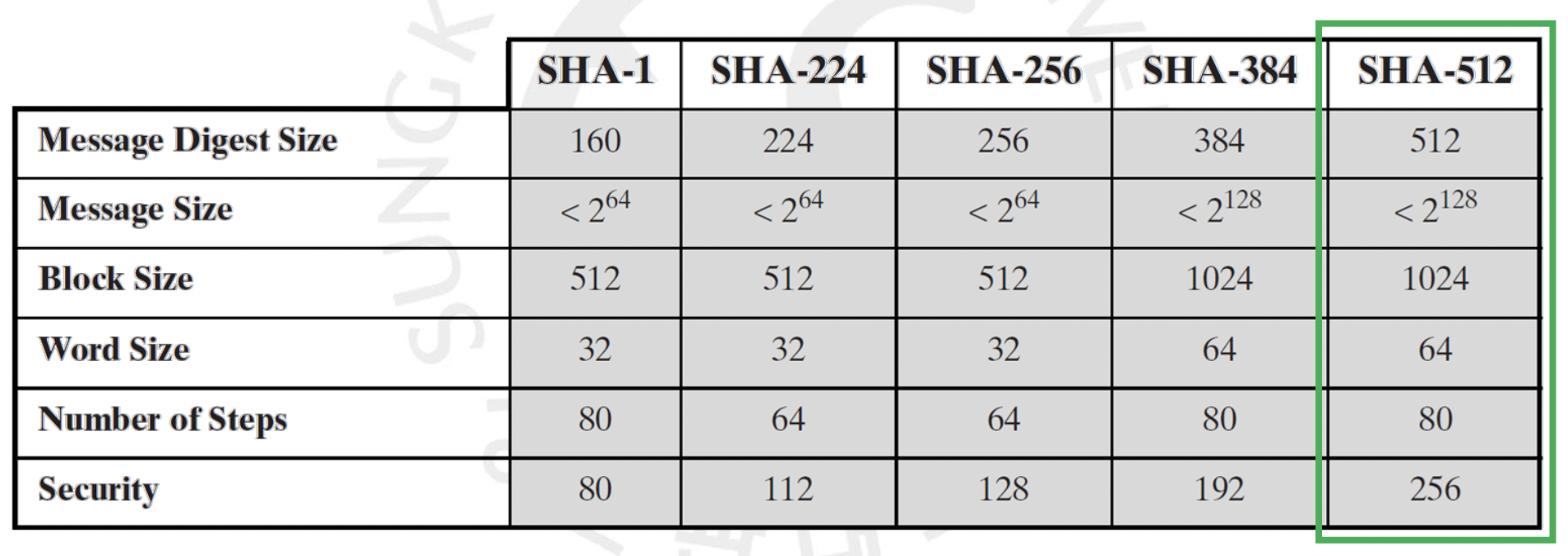
그렇게 미국 NSA가 제작하고 미국 국립표준기술연구소(NIST)에서 표준으로 채택한 암호학적 해시 함수 Secure Hash Algorithm, 줄여서 SHA가 1993년 개발되어 1995년 160 비트를 사용하는 SHA-1 이라는 이름으로 세상에 등장하게 되었습니다. 그러나 2005년에 심지어 보다 빠르게 번의 전수조사만에 Collision 이 깨져버리게 되었지요. 그래서 각각 256, 384, 512 비트를 사용하는 SHA-256, SHA-384, SHA-512 버전을 갖는 SHA-2 가 등장하게 되었습니다. SHA-512 의 구조는 아래와 같습니다.
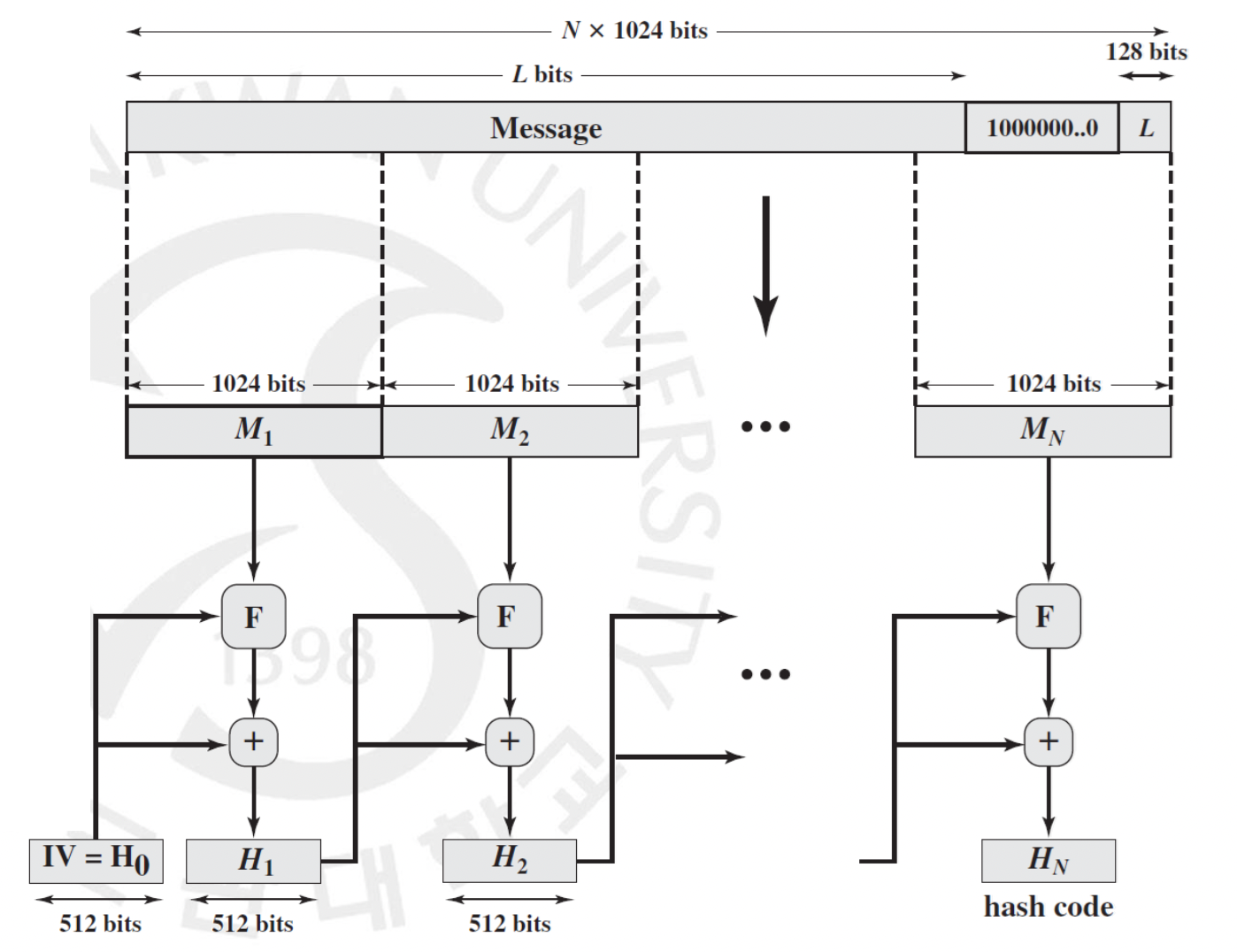
먼저 메시지를 1024 비트 단위로 쪼개기 위해 '맨 앞자리가 1이고 뒤가 모두 0' 인 padding 이 들어가게 됩니다. 그 뒤에 마지막 128비트는 원래의 메시지 길이를 저장하게 되고요. 그렇기 때문에 사실 메시지의 길이는 절대 비트를 넘지 못하게 됩니다. 그렇게 잘린 첫 1024 비트는 해시 함수 적용에 IV 를 넣어 총 512 비트의 값을 생성하게 됩니다. 그리고 이것이 다음 1024 비트의 연산에 적용되는 Chaning 구조를 확인할 수 있습니다. 이것을 반복하여 나온 최종 512 비트의 값이 진정한 메시지의 해시 값이 되는 것입니다.
여기서 특이한 점은 padding 은 무조건 들어가야 한다는 점입니다. 따라서 1024비트로 딱 떨어질 경우에는 패딩이 필요가 없지만 무조건 들어가야 하기 때문에 1024 비트의 패딩을 붙인다는 점입니다. 그렇다면 어떻게 1024 비트 단위를 512비트의 값으로 압축하는 것일까요? 구조는 아래와 같습니다.
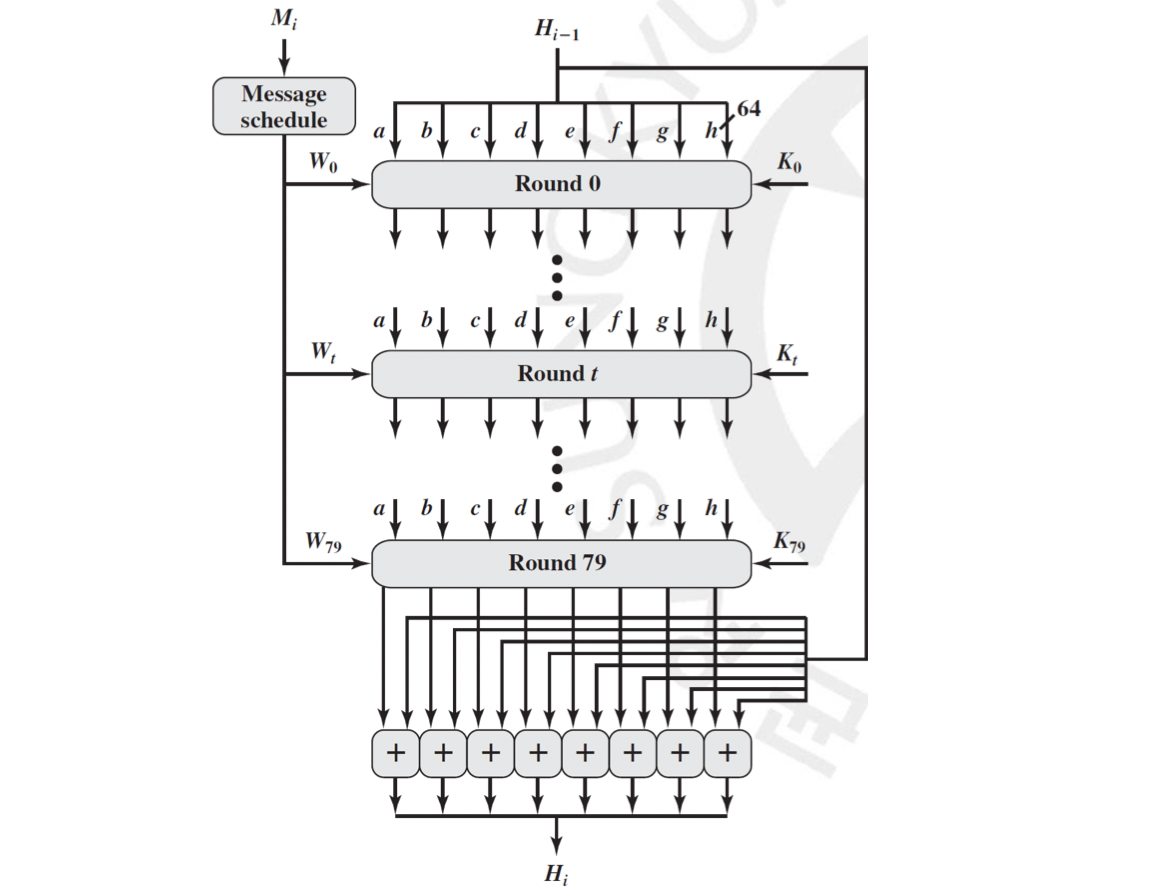
먼저 이전에서 넘어온 값 (처음에는 IV 겠지요?) 의 512비트를 64비트씩 8개로 나눕니다. 그리고 1024비트의 메시지를 파생시켜 총 80개의 64비트 값인 를 만들어줍니다. 그리고 여기서 는 번째 소수의 세제곱근서 앞의 64비트를 따옵니다. 이게 무슨 말이냐면 는 순서대로 해서 총 80 번째까지의 소수에서 앞의 64비트를 의미하는 겁니다. 그렇기 때문에 는 언제나 고정된 값이지요. 이 값들로 Round 함수를 돌려서 최종적으로 512 비트의 를 만들게 되는 것입니다.
지금까지 알게 된 계보를 정리하면 위와 같습니다. 이렇게 개발된 SHA-2 이지만 결국 이전 버전인 SHA-1 과 같은 구조와 수학적 연산을 지닌다는 점에서 한계점이 드러나게 됩니다. 그래서 미국 국립표준기술연구소(NIST) 가 2007 년에 새로운 세대인 SHA-3 에 대한 공모전을 진행하였고 그렇게 SHA-3 가 탄생하게 되었습니다.
SHA-512 는 1024 비트의 블럭과 512 비트의 해시 값이 정해져 있었습니다. SHA-3 도 마찬가지로 이 값들이 정해져 있지만 내부에서 처리하는 과정에서만큼은 모두 고정되지 않은 변수 값으로 줄 수 있습니다. 컴퓨팅 파워가 갈수록 세지는 데 이에 대응하도록 소프트웨어를 업데이트 하는 것은 번거롭기 그지 없으니 가변적으로 해서 비트 수를 늘리는데 효율적이도록 하는 것이지요.
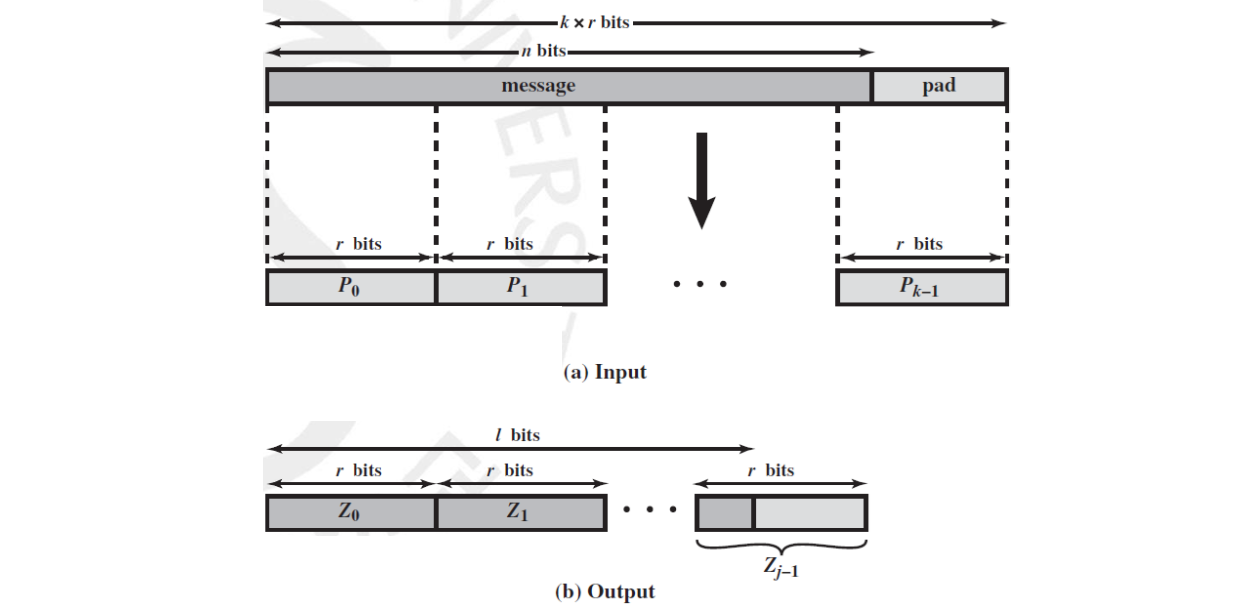
마찬가지로 Padding 이 들어가는 데 양식은 10*1 입니다. 1과 연속된 0 후에 1로 마무리 되는 것이지요. 일관성을 위해서 Padding 은 무조건 적으로 사용됩니다. 만약 비트가 비트로 딱 나눠지더라도 Padding 이 비트만큼 붙게 되는 것입니다.
Message Authentication Code(MAC)

글 초반의 내용을 복습하자만 MAC 은 해시 값을 안전히 보내기 위해 메시지에 공유된 비밀 키를 이용해서 해싱한 것을 같이 붙여 전송하는 것을 의미했습니다. 받는 쪽에서는 자신이 직접 계산한 값과 이 값을 비교해서 변조가 되었는지를 확인할 수 있었구요. 공격자는 비밀 키 값을 모르기 때문에 변조를 해도 이에 맞는 MAC 을 생성할 수 없어서 안정성을 보장하였습니다.
이 MAC 값을 TAG 라고 표현하기도 합니다. 따라서 다음과 같이 나타낼 수 있습니다.
T = MAC(K,M)
실제로 MAC 알고리즘은 일반적인 Encryption 방식과 비슷하게 동작합니다. 하지만 한 가지 확실한 차이는 MAC 은 복호화처럼 역으로 동작할 필요가 없다는 것이지요. 만들고 비교하는 것이 전부니까요. MAC 에는 크게 Symmetric Block Cipher 를 사용하는 CMAC 과 Cryptographic Hash Function 을 사용하는 HMAC 이 존재합니다. 전통적으로 CMAC 이 많이 사용되었지만 요즘은 더 빠른 HMAC 에 관심이 쏠리고 있는 추세입니다.
HMAC
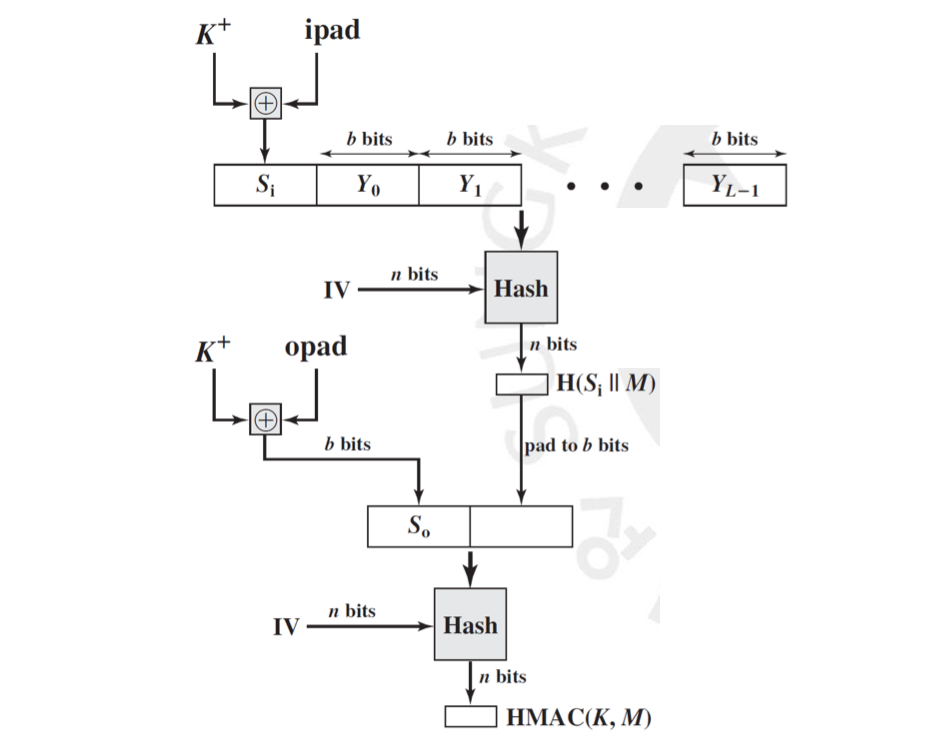
먼저 HMAC 을 알아보도록 하겠습니다. 먼저 비밀 키 앞에 0을 붙여 비트로 만든 와 ipad 값을 XOR 연산하여 를 생성합니다. 여기서 ipad 는 00110110 이 번 반복되는 비트 값입니다. 그리고 그 뒤에 메시지를 이어 붙입니다. 그 다음 블럭 크기를 비트로 하고 OUTPUT 을 비트로 하는 해시를 돌려서 해시 값을 만듭니다. 이 되겠군요. 는 Concatenate 로 연달아 이어 붙였다는 뜻입니다. 이 값을 다시 비트로 늘려(패딩하여) 와 opad 값을 XOR 연산한 값 뒤에 붙인 뒤 같은 해시를 또 돌려서 최종적으로 을 구하게 됩니다. 여기서 opad 는 01011100 이 번 반복되는 비트 값입니다.
HMAC 의 특이한 점은 사용하는 해시로 이미 깨진 해시인 MD5 SHA-1 과 같은 해시를 써도 무방하다는 것입니다. 이를 각각 HMAC-MD5, HMAC-SHA1 이라고 명명합니다. 공격자가 해시를 뚫기 위해 Brute-Force 로 사용할 쌍을 만들어야 하는데 를 모르기 때문에 애초에 해시에 들어갈 INPUT 값을 만들어볼 수조차 없는 것입니다. 하나의 같은 Key 만 하더라도 만큼이 필요하기 때문이지요.
CMAC
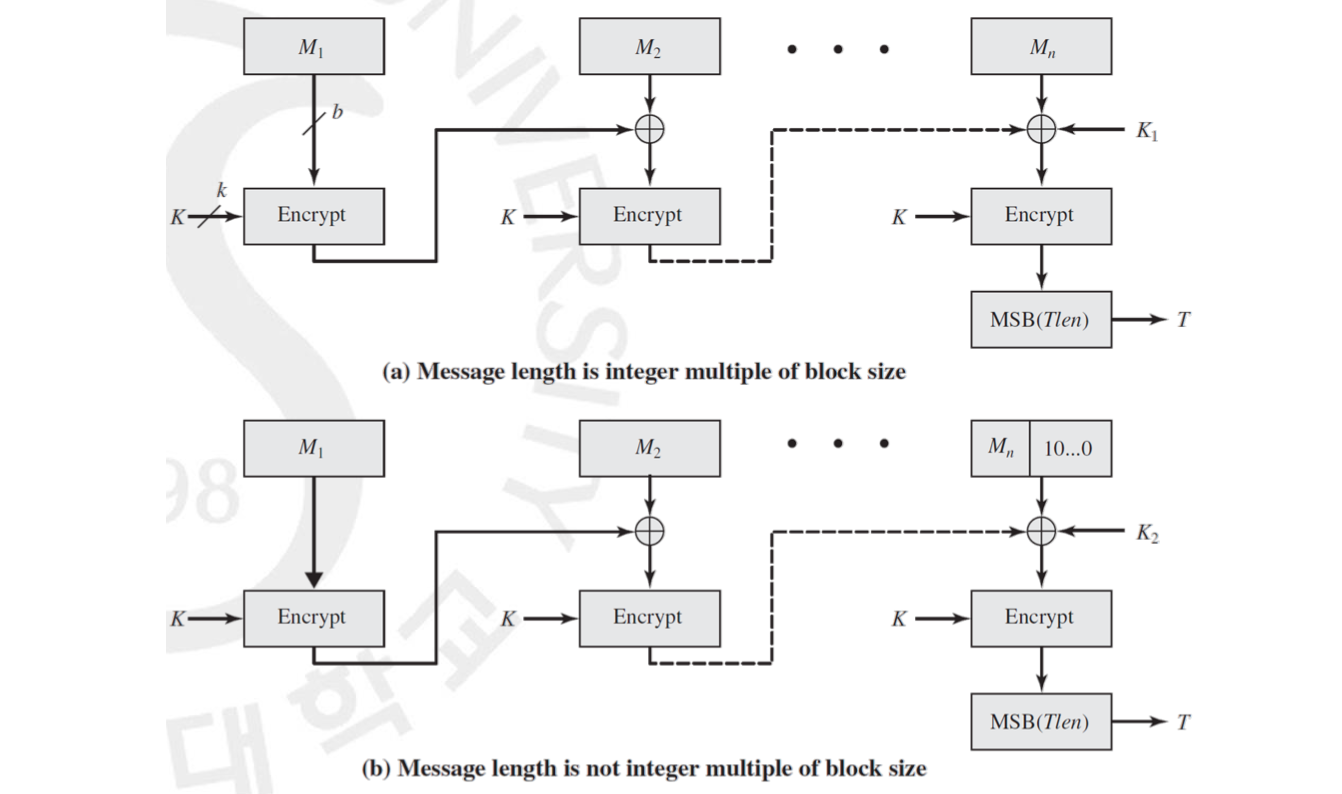
그 다음 CMAC 은 AES 나 Triple-DES 를 사용합니다. 먼저 메시지 을 비트 크기의 개의 블럭을 생성합니다. 그 다음 을 생헝하고 이 값을 다음 와 XOR 한 뒤 이를 또 Encrypt 하며 이와 같은 과정을 Chaning 으로 반복합니다. Mode of Operations 로 CBC 를 사용하는 것이죠. 최종적으로 나온 값에서 앞에서 TAG 의 길이만큼을 떼어 최종적으로 TAG 를 만드는 것입니다.
자 그렇다면 우리는 해시를 생성하는 Authenticity 와 메시지를 암호화하는 Confidentiality 를 만족해야 합니다. 그렇다면 그 순서에는 다음과 같은 접근법들이 있을 겁니다.
- Hash-then-Encrypt:
메세지에 해시를 해서 메세지 뒤에 이 해시값을 붙인 것을 암호화하는 방식입니다. 받으면 복호화를 한 뒤 메시지를 해싱한 값과 받은 해시값을 비교하면 되는 것입니다. - MAC-then-Encrypt:
MAC 을 만들어 메세지에 붙인 다음에 암호화하는 방식입니다. 마찬가지로 MAC 을 알기 위해 복호화를 선행해야 합니다. - Encrypt-then-MAC:
메시지를 암호화하고 암호화된 메시지로 MAC, 즉 TAG를 각각 만드는 방식입니다. 이렇게 되면 복호화도 하기 전에 미리 MAC 을 비교해서 메시지가 변조됬는지, 즉 복호화를 해야 할지 말지를 미리 알 수 있습니다. 그리고 TAG 가 Plaintext 가 아닌 채널로 날아가는 Ciphertext 자체를 보호하기 때문에 가장 이상적인 방식입니다.
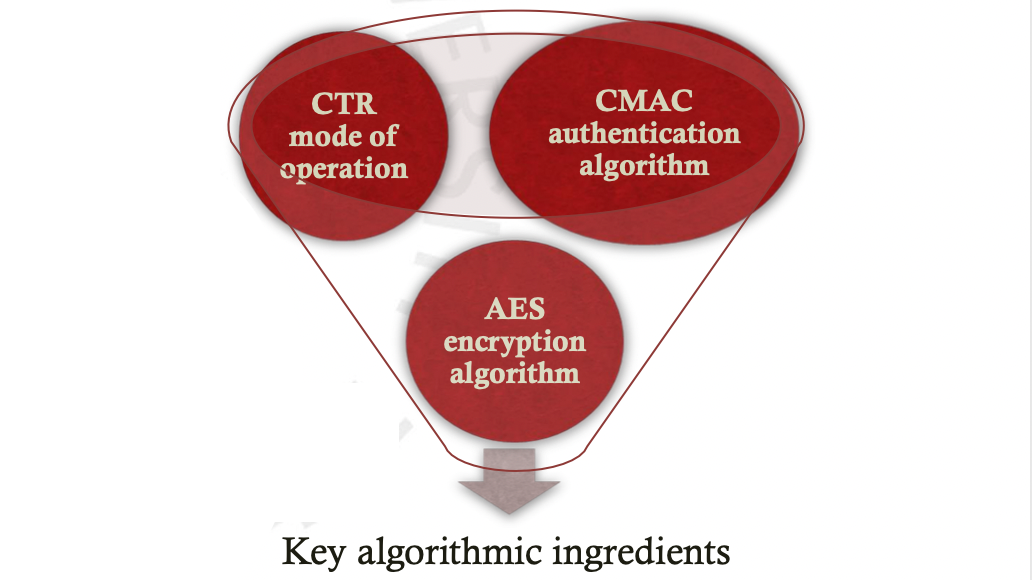
CCM 은 Counter with Cipher Block Chaining-Message Authentication Code 의 약자로 CBC MAC 이라고도 불립니다. 어려울 것 없이 위의 그림과 같이 선택한 디자인을 의미하는데요. Encryption 으로 Block Cipher 인 AES 를 사용합니다. Block Cipher 를 쓰려면 Mode of Operations 를 정해야 하겠지요? 그걸로 CTR 을 사용하고 MAC 으로는 CMAC 을 사용하는 것입니다. 이렇게 통합하면 Encryption 과 MAC 을 동시에 할 수 있어 기존 Encrypt-then-MAC 이 아닌 Encrypt-and-MAC 이라고 합니다.
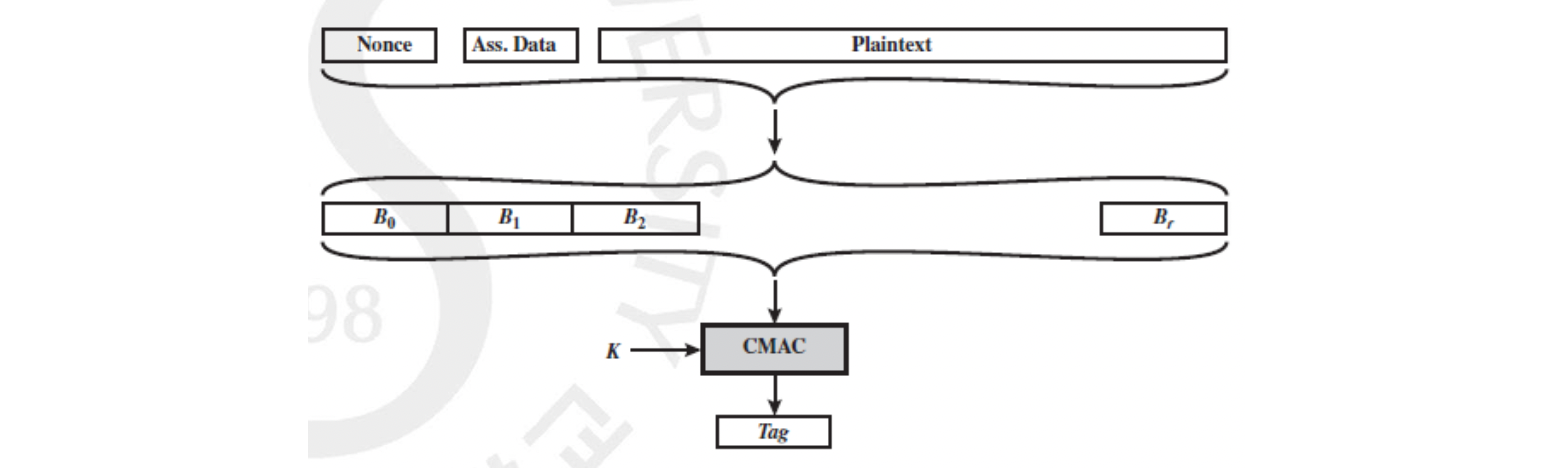
Authentication, 즉 CMAC 을 만드는 과정은 위와 같습니다. Plaintext 앞에 연관된 데이터와 replay 를 막기 위한 랜덤한 값인 Nonce 를 붙입니다. 이를 개의 블럭으로 만들어 비밀값 로 CMAC 을 돌려 TAG 값을 만듭니다.
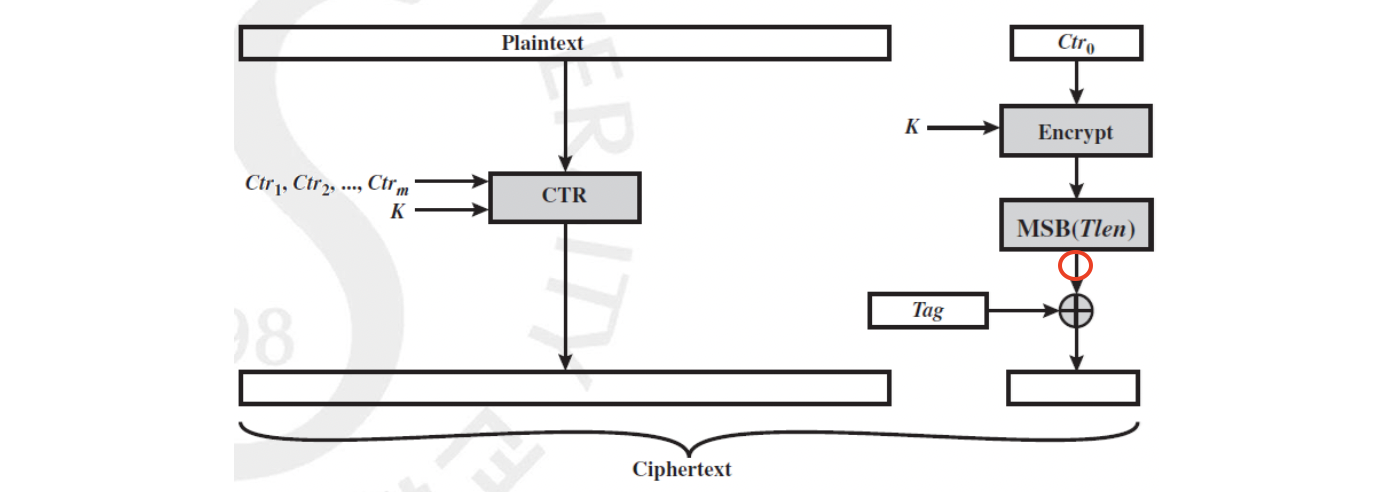
Encryption 은 위와 같이 CTR 을 Mode of Operations 로 하는 Block Cipher 를 사용합니다. 다시 말씀드리자면 CTR 은 Counter 값 자체를 암호화해서 Plaintext 와 XOR 하는 것으로 이 Counter 값은 비밀일 필요는 없지만 각 블럭마다 다른 값이어야 하기 때문에 보통 1씩 더해서 사용한다고 했습니다. 여기서 특이한 점은 가장 첫 번째 를 Encrypt 한 값은 TAG 만큼 길이를 따서 TAG 와 XOR 하여 암호화된 메시지 뒤에 붙임으로써 최종적인 Ciphertext 를 만듭니다.
문제는 받는 상대방은 복호화를 해서 Plaintext 를 만들어야 TAG 를 만들어 비교를 할 수 있다는 점입니다. 뒤에 붙어 있는 값과 만든 TAG 를 XOR 하면 빨강으로 표시된 부분의 값이 나올 테고, 이를 똑같이 를 와 Encryption 한 값에 MSB 로 자른 값이 맞는 지 비교합니다. 결국 TAG 가 Plaintext 를 감싸고 있기에 비도(보안성) 에서 Encrypt-then-MAC 보다 떨어지지만 Computation 관점에서는 병렬적인 처리로 빠르다는 이점 덕분에 많이 사용되고 있습니다.
Digital Signature
해시 값을 안전하게 보내기 위한 방법으로 두 번째는 바로 이전에도 설명드렸었던 Digital Signature 입니다. MAC 은 보내는 사람과 받는 사람, 즉 Two Parties 를 중간에 침입한 임의의 공격자, 즉 Third Party 로부터 보호하는 방법입니다. 그렇기 때문에 양 서로간에는 보호하지 못한다는 점이 있습니다.
상대 자체가 적이 될 수도 있잖아요? 예를 들어 Alice 가 Bob 에게 MAC 을 써서 메세지를 보냈습니다. 그런데 Bob 은 다른 메시지를 갖고 Alice 한테서 왔다고 주장할 수도 있는 것이죠. 왜냐하면 같은 비밀 키가 있는 Bob 은 쉽게 새로운 TAG 를 형성할 수 있기 때문입니다. 이를 보안해주는 것이 바로 Digital Signature 이 되겠습니다.
- 서명자를 증명할 수 있습니다.
이것을 증명하는 제 3자는 서명자의 공개키를 가지고 있습니다. 서명자의 공개키로 풀린다는 것은 즉, 이것이 서명자의 개인키로부터 만들어졌다는 것을 의미하기 때문에 서명자를 증명할 수 있겠습니다.
Digital Signature 로 사용하는 Asymmetric Cipher 인 RSA 를 기억하시나요? RSA 의 치명적인 약점으로는 암복호화가 각각 으로 모듈러 을 취하기 때문에 메시지의 길이가 보다 클 수 없었습니다. 그러면 이번 글에서 공부했던 내용으로 이를 어떻게 해결할 수 있을까요? 바로 HASH 이겠죠! 메시지가 아닌 메시지의 해시 값을 암복호화 하는 것입니다. 서명도 마찬가지이고요. 다만, 해시 충돌이 나지 않도록 만전을 가해야 할 것입니다. 다른 서명인데 같은 해시 값을 공격자가 찾아버린다면 정말 큰일 나니까요.😤
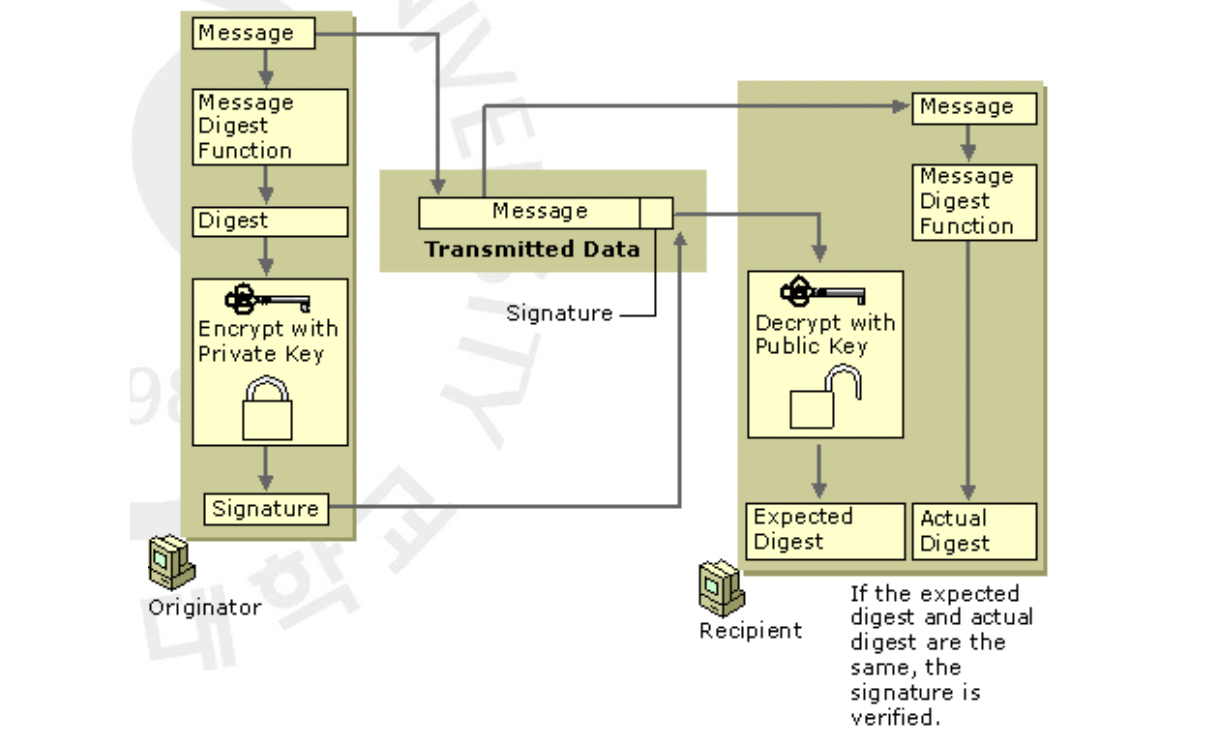
위 그림이 Digital Signature 의 과정을 그림으로 표현한 것입니다. 위의 Digest 가 바로 Hash 를 의미하는 것입니다. 복화한 사람 또한 마찬가지로 받은 메세지를 Digest, 즉 해시를 돌려 이 값과 서명을 Public Key 로 푼 값을 비교함으로써 Authentication 이 이루어집니다. MAC 과는 다르게 받는 사람까지가 아닌 보낸 사람만이 이 값을 만들 수 있기 때문에 비도가 높은 것입니다. CIA(Confidentiality, Integrity, Availability 외에 추가적으로 요구했던 Non-Repudiation(부인 방지) 까지 제공하기 때문에 많이 사용되지만 Asymmetric 특성 상 무겁다는 점은 피할 수 없습니다.
