본 글의 저작권과 원문은 https://blog.naver.com/sweetie_rex 에 있습니다.
현재의 글은 업데이트가 되지 않음을 유의해서 읽어주세요.
최신 업데이트 된 글을 읽으시려면 아래의 링크를 확인해주세요.
Python 응용 프로젝트(1) - 데이터 시각화와 데이터 분석
이번에는 Python 의 가장 대표적인 분야라고 할 수 있는 '데이터 시각화' 와 '데이터 분석' 을 직접해보려고 해.
첫번째 프로젝트인 만큼 쉽고 간단하게 해볼거야.
파이썬에는 데이터분석에 아주 유용한 라이브러리가 많아서 이쪽 분야에서 실제로 매우 많이 사용되고 있어. 그래서 파이썬은 통계학자, Data Scientist 등의 직군으로부터 사랑받는 언어야. 실제로 파이썬을 다룰줄 모르면 관련 업무를 하기 어려운 정도지. 또 다른 데이터분석/시각화 측면에서 유명한 프로그래밍 언어로는 'R' 이라는 언어도 있지만, 파이썬이 R보다 더 다방면으로 유용하게 사용되는 편이야.
데이터 시각화(Data Visualization) 란?
데이터 시각화는 위의 그림만 봐도 와닿을 것 같아.
데이터를 시각적으로 이해할 수 있도록, 데이터의 특징에 어울리는 차트를 그리는 것 을 뜻하는데, 데이터를 시각화하면 데이터가 가지고있는 특징을 쉽고 빠르게 파악할 수 있어.
데이터 시각화의 종류는 엄청 많은데, 대표적으로는
- 막대 그래프 (Bar chart)
- 선 그래프 (Line chart, 시계열차트)
- 원 그래프 (Pie chart)
- 산점도 (Scatter plot)
- 줄기-잎 그래프 (Stem-and-leaf plot)
- 캔들 차트 (주식, 환율 등에서 가격표시에 주로 사용)
- Heat map
- Word cloud (텍스트 시각화)
등등이 있어. 이번에는 아주 간단하게 막대그래프, 선그래프, 원그래프 이렇게 3가지 차트만 그려볼거야.
그럼 파이썬을 통해서 간단하게나마 엑셀(Microsoft 사의 소프트웨어)에서 데이터를 추출해와서 차트를 그리는 프로그램을 만들어보자!
프로젝트: 엑셀 가계부 데이터시각화
먼저 엑셀로 가계부 데이터를 입력하고, 해당 엑셀파일의 데이터를 파이썬으로 불러와서 데이터 시각화를 해볼거야.
그럼 엑셀파일을 만들어야겠지?
근데.. 엑셀이 없다고? 설치 못한다고? 걱정하지마! 여기서 중요한 것은 엑셀파일이 아니라, 파이썬을 이용한 데이터 시각화 이기 때문에 엑셀 프로그램이 전혀 없는 사람들을 위해서 준비해놓은 코드가 있어!
우선, 엑셀이 있는 사람들은 조금 더 유용하게 학습할 수 있도록 엑셀파일을 만들어보고, 엑셀과 관련된 코드를 먼저 작성해볼게. 엑셀이 없다면 이 다음 코드에서 시작하면 돼.
엑셀이 있는 경우: 엑셀(.xlsx)파일 만들기
엑셀파일의 완성된 모습은 아래와 같아. 아주 심플하지? 그대로 따라서 적어보자.
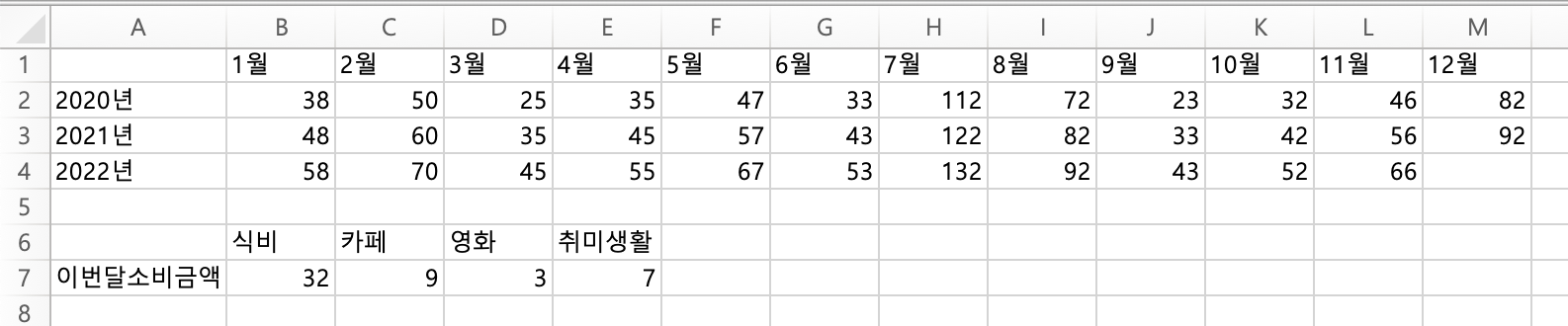
엑셀파일의 1행에는 1월부터 12월
2행은 2020년의 월별 지출금액(만원 단위)
3행은 2021년의 월별 지출금액
4행은 2022년의 월별 지출금액(12월은 아직 정산되지 않았다는 가정)
5행은 비워두고
6행은 소비 카테고리
7행은 이번달 소비금액을 기록해놨어.
우리가 작성할 코드가 정상작동 하기 위해서는 예시의 행과 열을 정확하게 동일하게 입력해줘야 하니까 자리에 맞게 주의해서 입력해줘. 숫자데이터는 똑같이 입력할 필요가 없고, 아무렇게나 입력해도 괜찮아.
우리는 입력된 엑셀파일을 파이썬 코드로 불러올거야.
엑셀파일의 이름을 LP-1-data.xlsx 라고 저장한 뒤, 작업할 공간에 파이썬 파일을 LP-1-data-visualization.py 라는 이름으로 만들고, 아래의 파이썬 코드를 작성해보자!
# 프로그램 구현에 필요한 모듈 가져오기
import pandas as pd # pandas 라는 모듈을 pd 라는 별칭(alias)으로 사용
import numpy as np # numpy 라는 모듈을 np 라는 별명(alias)으로 사용
# 여기서 as(alias) 하는 것은 일반적인 관례이지만, alias 기능을 사용하지 않아도 전혀 상관없음
dataframe = pd.read_excel("./LP-1-data.xlsx", sheet_name="Sheet1", header=None, index_col=None)
x축 = dataframe.iloc[0, 1:13].to_numpy() # 선택한 행렬 데이터를 array 로 변환
y축2020 = dataframe.iloc[1, 1:13].to_numpy()
y축2021 = dataframe.iloc[2, 1:13].to_numpy()
y축2022 = dataframe.iloc[3, 1:13].to_numpy()
소비카테고리 = dataframe.iloc[5, 1:5].to_numpy()
이번달소비금액 = dataframe.iloc[6, 1:5].to_numpy()
이번달소비금액합계 = np.nansum(이번달소비금액, dtype="float16")
평균2020 = np.nanmean(y축2020, dtype="float16")
평균2021 = np.nanmean(y축2021, dtype="float16")
평균2022 = np.nanmean(y축2022, dtype="float16")
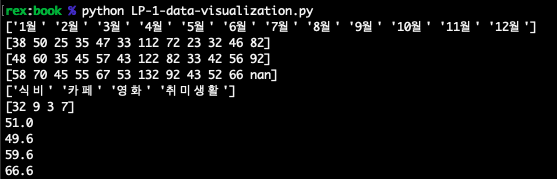
print(x축)
print(y축2020)
print(y축2021)
print(y축2022)
print(소비카테고리)
print(이번달소비금액)
print(이번달소비금액합계)
print(평균2020)
print(평균2021)
print(평균2022)위 코드를 실행시키기 위해 사전에 해야할 일은 파이썬 패키지(라이브러리)를 설치하는 일이야.
파이썬 패키지는 PIP 라는 도구를 활용해서 설치할 수 있는데, PIP 는 Package Installer for Python 이라는 의미야.
터미널에 아래의 명령어를 입력하면 파이썬이 해당 패키지를 설치할 거야.
pip install pandas
pip install numpy
# 그리고 하나 더, 엑셀 파일을 불러오는데 아래의 패키지도 필요할거야!
pip install openpyxlPIP 로 파이썬 패키지를 설치한 후, 위의 코드를 실행시키면 아래의 이미지처럼 결과가 나올거야.
엑셀이 없는 경우: 데이터를 하드코딩 하기
이 프로젝트에서 중요한 것은 엑셀이 아니라, 파이썬 코드이기 때문에 엑셀이 없어도 할 수 있도록 코드를 준비해놨어.
엑셀이 없다면 위의 코드 대신, 아래 코드를 작성하자.
x축 = ["1월", "2월", "3월", "4월", "5월", "6월", "7월", "8월", "9월", "10월", "11월", "12월"]
y축2020 = [38, 50, 25, 35, 47, 33, 112, 72, 23, 32, 46, 82]
y축2021 = [48, 60, 35, 45, 57, 43, 122, 82, 33, 42, 56, 92]
y축2022 = [58, 70, 45, 55, 67, 53, 132, 92, 43, 52, 66, 102]
소비카테고리 = ["식비", "카페", "영화", "취미생활"]
이번달소비금액 = [32, 9, 3, 7]
이번달소비금액합계 = 85
평균2020 = 57
평균2021 = 66
평균2022 = 78
print(x축)
print(y축2020)
print(y축2021)
print(y축2022)
print(소비카테고리)
print(이번달소비금액)
print(이번달소비금액합계)
print(평균2020)
print(평균2021)
print(평균2022)위의 코드를 실행시키면 아래의 이미지처럼 결과가 나올거야.
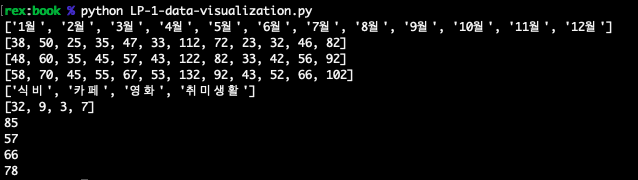
자세히 보면 위에서 엑셀 데이터를 가져온 결과랑은 살짝 다른 형태인 것을 알 수 있어. 그 이유는 엑셀 데이터를 가져올 때에는 'pandas', 'numpy' 라는 라이브러리를 사용해서 만들어진 데이터이고, 이번에는 순수한 파이썬의 데이터타입으로 하드코딩 했기 때문이야.
우리는 가장 먼저 라인차트를 그려볼건데, 라인차트는 보통 시간의 흐름에 따라 데이터를 시각화하는데 매우 유용한 도구야. '시계열차트(time series)' 라고도 해.
그럼 이제 2020년, 2021년, 2022년의 월별 y축 데이터로 라인차트(시계열차트)를 그려보도록 하자.
자세한 내용은 우측에 주석을 달아놓을테니 반드시 주석과 함께 직접 작성해보길 바라!
'백문이불여일타' 알지?!
...
import matplotlib.pyplot as plt # matplotlib 객체의 pyplot 필드를 plt 라는 별칭(alias)으로 사용
...
print(평균2022)
plt.subplot(3, 1, 1) # 가로 3칸, 세로 1칸 사이즈의 차트를 1번째로 그리기 시작하기
plt.title("지난 1년간 월별 카드값 사용 내역 (단위: 만)") # 차트의 제목
plt.plot(x축, y축2020, marker="o", label="2020년")
plt.plot(x축, y축2021, marker="o", label="2021년")
plt.plot(x축, y축2022, marker="o", label="2022년")
plt.legend() # 범례 표시
plt.xlabel("월") # x축 레이블
plt.ylabel("카드사용금액") # y축 레이블
plt.grid(True, axis="y") # 그리드 선 표시
plt.show() # 작성된 모든 plot 들을 표시
코드의 상단에 matplotlib 이라는 모듈을 가져온거 보이지? 위의 pandas, numpy 와 마찬가지로 PIP 를 통해 인스톨해야하는 모듈이야. 터미널에서 설치하자.
pip install matplotlib그리고 위의 코드를 실행하면 라인차트는 정상적으로 나오지만, LP-1-data-visualization.py:40: UserWarning: Glyph 51648 (\N{HANGUL SYLLABLE JI}) missing from current font. 라는 오류메시지가 나오면서 아래 이미지 처럼 모든 한글이 출력되지 않을거야.
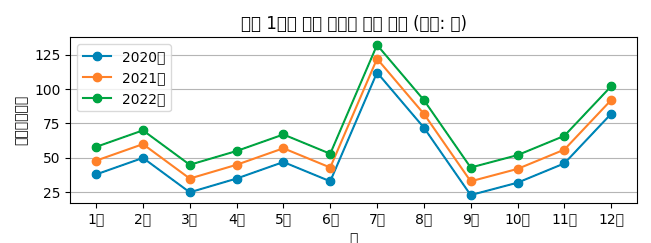
그래서 우리는 한글을 처리할 수 있도록 코드를 작성해야 돼.
...
import platform
...
print(평균2022)
if platform.system() == "Darwin": # Mac OS
plt.rc("font", family="AppleGothic")
else:
plt.rc("font", family="Malgun Gothic")
plt.subplot(3, 1, 1)
...위의 코드는 현재 사용중인 PC 의 OS 에 따라서 matplotlib 의 폰트를 다르게 설정해주는 코드야.
platform 모듈의 경우, 파이썬 기본 내장 모듈이기 때문에 별도의 PIP 설치 없이 즉시 사용 가능해.
Mac OS 의 경우 '애플고딕' 폰트를, Windows 의 경우 '맑은고딕' 폰트를 사용하면 한글이 깨지지 않고 정상적으로 노출 돼.
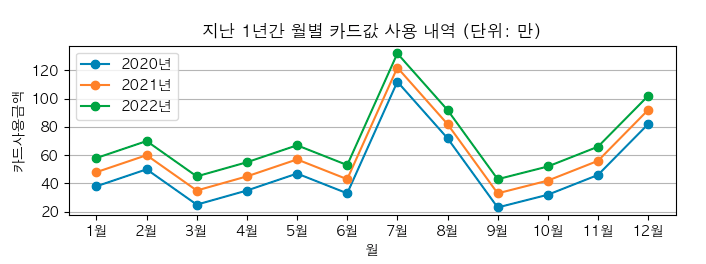
짠! 이제 한글이 정상적으로 보이지?!
이제 막대그래프(Bar chart)를 그려보자.
막대그래프는 2개 이상의 데이터를 비교하는데 자주 사용되는 편인데, 우리는 이번달 소비금액과 연도별 평균 소비금액을 비교하는데 사용할거야.
... 라인차트 작성 로직 ...
x = ["이번달 소비금액", "2020년 평균", "2021년 평균", "2022년 평균"]
plt.subplot(3, 1, 2) # 가로 3칸, 세로 1칸 사이즈의 차트를 2번째로 그리기 시작하기
plt.title("이번달 소비금액과 지난 3년의 평균치 소비금액 비교그래프 (단위: 만)") # 차트의 제목
plt.bar(x[0], 이번달소비금액합계, label="이번달")
plt.bar(x[1], 평균2020, label="2020년")
plt.bar(x[2], 평균2021, label="2021년")
plt.bar(x[3], 평균2022, label="2022년")
plt.legend() # 범례 표시
plt.xlabel("이번달 소비금액 & 연도별 평균 소비금액") # x축 레이블
plt.ylabel("카드사용금액") # y축 레이블
plt.grid(True, axis="y", linestyle=":") # 그리드 선 표시
plt.show() # 작성된 모든 plot 들을 표시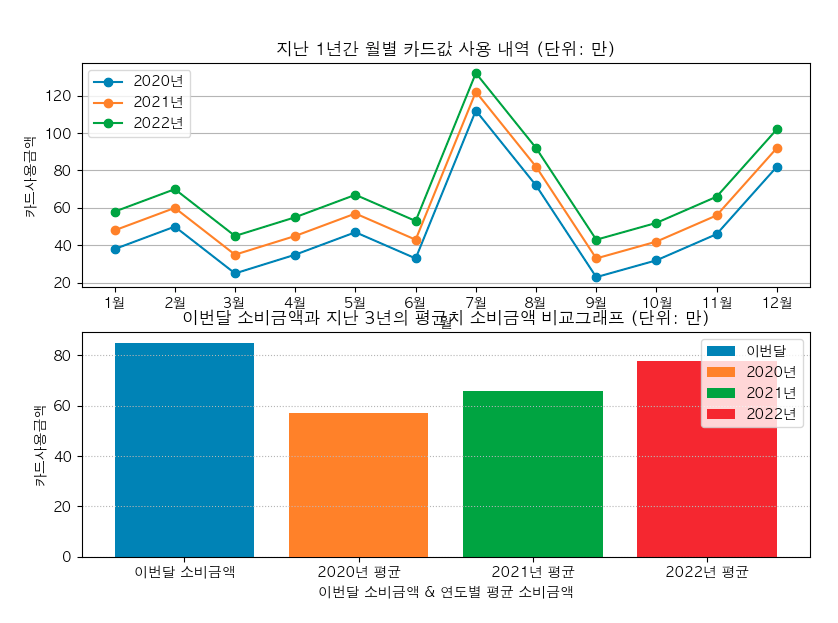
짠! 이렇게 2개의 차트가 나란히 나왔어.
이번 코드에서 조금 헷갈릴 수 있는 건, 한 화면에 여러개의 차트를 그릴때에는 모든 subplot 을 다 그린 후에 최종적으로 plt.show() 함수를 한 번만 호출해야 된다는 거야.
그런데 문제가 한가지 있지. 위의 이미지를 보면 2개의 차트가 조금 겹쳐있는 것을 볼 수 있어. 이것을 보정해주는 코드는 아래와 같아.
plt.tight_layout() # subplot 간의 레이아웃이 겹치지 않도록 함
plt.show()plt.show() 를 호출하기 전에 plt.tight_layout() 함수를 먼저 호출해주는 것으로 문제를 해결할 수 있어.
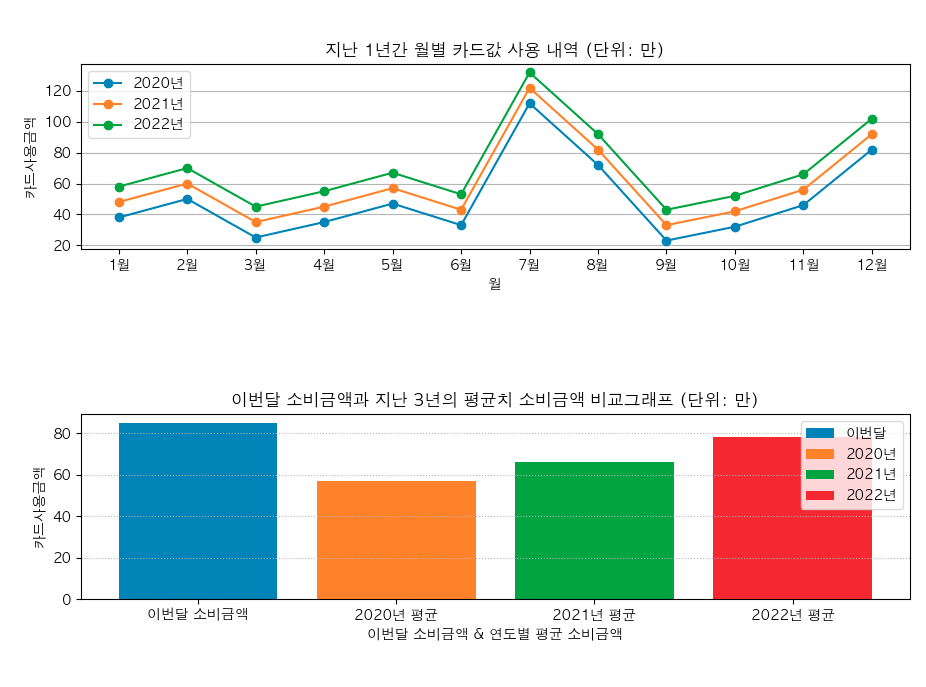
이제 라인차트와 막대그래프를 겹치지 않게 모두 그려보았어. 마지막으로 파이차트(Pie chart)를 그려볼거야.
파이차트는 동그란 파이(pie)처럼 생겨서 파이차트라고 하는데, 100% 의 영역 내에서 영역별로 비율을 분할하여 표시할 때 주로 사용해.
... 라인차트 작성 로직 ...
... 막대그래프 작성 로직 ...
plt.subplot(3, 1, 3) # 가로 3칸, 세로 1칸 사이즈의 차트를 3번째로 그리기 시작하기
plt.title("이번달 소비금액 카테고리별 비율") # 차트의 제목
plt.pie(이번달소비금액, labels=소비카테고리, autopct="%.1f%%") # 각 파이 위에 소수점 1자리까지 표시
plt.legend() # 범례 표시
plt.tight_layout()
...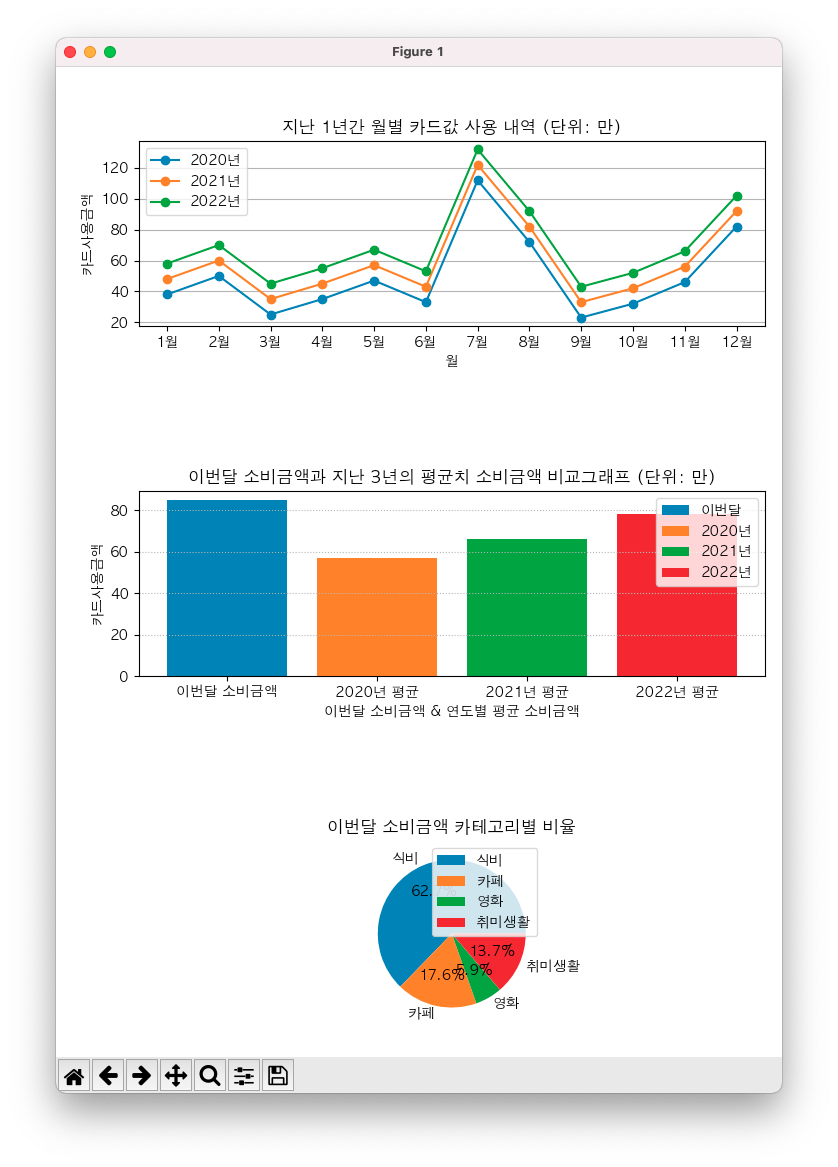
짜잔! 우리가 원하던 라인차트, 막대그래프, 파이차트를 모두 그려봤어!
우리의 첫번째 파이썬 프로젝트가 완성되었어, 축하해! 그리고 여기까지 따라와줘서 고마워! :-)
어때? 파이썬으로 다른 파일의 데이터를 불러오고, 그 데이터를 시각화 할 수 있다는 것, 이제 알겠지?
전혀 어렵지 않았을거야!
초기버전 전체 코드
# 프로그램 구현에 필요한 모듈 가져오기
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import platform
x축 = ["1월", "2월", "3월", "4월", "5월", "6월", "7월", "8월", "9월", "10월", "11월", "12월"]
y축2020 = [38, 50, 25, 35, 47, 33, 112, 72, 23, 32, 46, 82]
y축2021 = [48, 60, 35, 45, 57, 43, 122, 82, 33, 42, 56, 92]
y축2022 = [58, 70, 45, 55, 67, 53, 132, 92, 43, 52, 66, 102]
소비카테고리 = ["식비", "카페", "영화", "취미생활"]
이번달소비금액 = [32, 9, 3, 7]
이번달소비금액합계 = 85
평균2020 = 57
평균2021 = 66
평균2022 = 78
print(x축)
print(y축2020)
print(y축2021)
print(y축2022)
print(소비카테고리)
print(이번달소비금액)
print(이번달소비금액합계)
print(평균2020)
print(평균2021)
print(평균2022)
if platform.system() == "Darwin": # Mac OS
plt.rc("font", family="AppleGothic")
else:
plt.rc("font", family="Malgun Gothic")
plt.subplot(3, 1, 1) # 가로 3칸, 세로 1칸 사이즈의 차트를 1번째로 그리기 시작하기
plt.title("지난 1년간 월별 카드값 사용 내역 (단위: 만)") # 차트의 제목
plt.plot(x축, y축2020, marker="o", label="2020년")
plt.plot(x축, y축2021, marker="o", label="2021년")
plt.plot(x축, y축2022, marker="o", label="2022년")
plt.legend() # 범례 표시
plt.xlabel("월") # x축 레이블
plt.ylabel("카드사용금액") # y축 레이블
plt.grid(True, axis="y") # 그리드 선 표시
x = ["이번달 소비금액", "2020년 평균", "2021년 평균", "2022년 평균"]
plt.subplot(3, 1, 2) # 가로 3칸, 세로 1칸 사이즈의 차트를 2번째로 그리기 시작하기
plt.title("이번달 소비금액과 지난 3년의 평균치 소비금액 비교그래프 (단위: 만)") # 차트의 제목
plt.bar(x[0], 이번달소비금액합계, label="이번달")
plt.bar(x[1], 평균2020, label="2020년")
plt.bar(x[2], 평균2021, label="2021년")
plt.bar(x[3], 평균2022, label="2022년")
plt.legend() # 범례 표시
plt.xlabel("이번달 소비금액 & 연도별 평균 소비금액") # x축 레이블
plt.ylabel("카드사용금액") # y축 레이블
plt.grid(True, axis="y", linestyle=":") # 그리드 선 표시
plt.subplot(3, 1, 3) # 가로 3칸, 세로 1칸 사이즈의 차트를 3번째로 그리기 시작하기
plt.title("이번달 소비금액 카테고리별 비율") # 차트의 제목
plt.pie(이번달소비금액, labels=소비카테고리, autopct="%.1f%%") # 각 파이 위에 소수점 1자리까지 표시
plt.legend() # 범례 표시
plt.tight_layout() # subplot 간의 레이아웃이 겹치지 않도록 함
plt.show() # 작성된 모든 plot 들을 표시자, 그런데 이게 끝이 아니야. 한가지가 더 남았어. 그것은 바로 코드 리팩토링(Code Refactoring)!
사실 위 코드들은 원하는대로 작동하긴 하지만 코드가 체계적이지가 않아. 우리는 훌륭한 개발자가 되기 위해 이 더러운 코드들을 클린하게 정리해야할 의무가 있어.
이러한 과정을 Code Refactoring(코드 리팩토링) 이라고 불러.
Code Refactoring 을 해보자
Refactoring(리팩토링) 이란, 프로그램의 실행 결과를 바꾸지 않으면서, 구조를 개선한다는 의미야. 실제로 프로그램이 작동하는 결과물은 완전 동일하지만, 내부 소스코드를 더 깔끔하게 개선하는 작업이지.
지금까지의 코드는 그냥 흘러가는대로 대충 쓴 상태고, 이런식으로 코딩하면 나중에 유지보수가 불편해서 개발이 힘들어져. 파이썬의 가장 기본적인 구조부터 시작해볼게.
파이썬 프로그램을 단일 파일에 작성할때는 아래와 같은 구조로 코딩하는게 좋아.
# 프로그램 구현에 필요한 모듈 가져오기
import ...
# 전역변수 선언 및 초기화
var1 = ...
var2 = ...
...
# 프로그램을 시작하면 가장 먼저 실행되는 메인함수
def main():
...
# main 함수에서 사용할 역할 기반의 함수1
def func1(url):
...
# main 함수에서 사용할 역할 기반의 함수2
def func2():
...
# 파이썬 파일을 직접 실행시키면 작동하는 로직
if __name__ == "__main__":
main()여기에서 __name__ == "__main__" 이 코드는 무엇이냐면, 파이썬은 내부적으로 __name__ 이라는 변수를 가지고 있고, 터미널에서 python 파일을 직접 실행시키면 해당 파일의 __name__ 변수에 "__main__" 이라는 string 값을 자동으로 넣어줘.
그래서 위 로직이 실행되는거지.
그리고 이 구조에서 main() 이라는 함수를 선언하고, 모든 주요 로직들을 main() 함수 내에 구현한 뒤, if 문 내에서 main() 함수를 실행시키는게 보편적인 구조라고 할 수 있어.
이런 구조로 코딩하면 함수를 선언 순서와 관계없이 언제든지 사용할 수 있어서 편해.
그리고 계속 파이썬 개발자로 지내다보면 추후에 알게되겠지만 모듈 테스트 에 용이한 구조야. 사실 모듈테스트가 핵심 내용이고 이 책을 공부하는 단계에서는 해당 내용까지는 몰라도 아무 상관없지만, 더 깔끔하고 쉬운 유지보수가 가능한 코드를 위해 이런 구조로 작성하는 버릇을 들여보자.
이 구조로 위의 초기버전 소스코드를 리팩토링 해보면 아래와 같이 작성할 수 있어.
완성된 소스코드
# 프로그램 구현에 필요한 모듈 가져오기
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import platform
"""
pip install matplotlib
pip install pandas
pip install numpy
pip install openpyxl
* References
- https://matplotlib.org/stable/api/
- https://numpy.org/doc/stable/reference/
- https://pandas.pydata.org/docs/reference/
"""
# 전역변수 선언 및 초기화
x축 = None
y축2020 = None
y축2021 = None
y축2022 = None
소비카테고리 = None
이번달소비금액 = None
이번달소비금액합계 = None
평균2020 = None
평균2021 = None
평균2022 = None
# 프로그램을 시작하면 가장 먼저 실행되는 메인함수
def main():
set_data_from_excel() # 엑셀이 있는 경우 사용
# set_data_from_hardcoding() # 엑셀이 없는 경우 사용
init_matplotlib()
draw_linechart()
draw_barchart()
draw_piechart()
plt.tight_layout() # subplot 간의 레이아웃이 겹치지 않도록 함
plt.show() # 작성된 모든 plot 들을 표시
return
# 엑셀 데이터 받아오기
def set_data_from_excel():
global x축
global y축2020
global y축2021
global y축2022
global 소비카테고리
global 이번달소비금액
global 이번달소비금액합계
global 평균2020
global 평균2021
global 평균2022
dataframe = pd.read_excel("./LP-1-data.xlsx", sheet_name="Sheet1", header=None, index_col=None)
x축 = dataframe.iloc[0, 1:13].to_numpy() # 선택한 행렬 데이터를 array 로 변환
y축2020 = dataframe.iloc[1, 1:13].to_numpy()
y축2021 = dataframe.iloc[2, 1:13].to_numpy()
y축2022 = dataframe.iloc[3, 1:13].to_numpy()
소비카테고리 = dataframe.iloc[5, 1:5].to_numpy()
이번달소비금액 = dataframe.iloc[6, 1:5].to_numpy()
이번달소비금액합계 = np.nansum(이번달소비금액, dtype="float16")
평균2020 = np.nanmean(y축2020, dtype="float16")
평균2021 = np.nanmean(y축2021, dtype="float16")
평균2022 = np.nanmean(y축2022, dtype="float16")
return
# 엑셀이 없는 경우, 하드코딩으로 데이터 값 지정
def set_data_from_hardcoding():
global x축
global y축2020
global y축2021
global y축2022
global 소비카테고리
global 이번달소비금액
global 평균2020
global 평균2021
global 평균2022
global 이번달소비금액합계
x축 = ["1월", "2월", "3월", "4월", "5월", "6월", "7월", "8월", "9월", "10월", "11월", "12월"]
y축2020 = [38, 50, 25, 35, 47, 33, 112, 72, 23, 32, 46, 82]
y축2021 = [48, 60, 35, 45, 57, 43, 122, 82, 33, 42, 56, 92]
y축2022 = [58, 70, 45, 55, 67, 53, 132, 92, 43, 52, 66, 102]
소비카테고리 = ["식비", "카페", "영화", "취미생활"]
이번달소비금액 = [32, 9, 3, 7]
이번달소비금액합계 = 85
평균2020 = 57
평균2021 = 66
평균2022 = 78
return
# 한글폰트 사용을 위해 matplotlib 폰트 설정
def init_matplotlib():
if platform.system() == "Darwin": # Mac OS
plt.rc("font", family="AppleGothic")
else:
plt.rc("font", family="Malgun Gothic")
return
# 지난 3년간 월별 카드값 사용 내역
def draw_linechart():
# 2개 array의 갯수가 다르다면 오류가 발생함
# plt.figure() # 새로운 차트 그리기 시작
plt.subplot(3, 1, 1) # 가로 2칸, 세로 1칸 사이즈의 차트를 1번째로 그리기 시작하기
plt.title("지난 1년간 월별 카드값 사용 내역 (단위: 만)") # 차트의 제목
plt.plot(x축, y축2020, marker="o", label="2020년")
plt.plot(x축, y축2021, marker="o", label="2021년")
plt.plot(x축, y축2022, marker="o", label="2022년")
plt.legend() # 범례 표시
plt.xlabel("월") # x축 레이블
plt.ylabel("카드사용금액") # y축 레이블
plt.grid(True, axis="y") # 그리드 선 표시
return
# 이번달 소비금액과 지난 12개월의 평균치 소비금액 비교그래프
def draw_barchart():
x = ["이번달 소비금액", "2020년 평균", "2021년 평균", "2022년 평균"]
# plt.figure() # 새로운 차트 그리기 시작
plt.subplot(3, 1, 2) # 가로 2칸, 세로 1칸 사이즈의 차트를 2번째로 그리기 시작하기
plt.title("이번달 소비금액과 지난 3년의 평균치 소비금액 비교그래프 (단위: 만)") # 차트의 제목
plt.bar(x[0], 이번달소비금액합계, label="이번달")
plt.bar(x[1], 평균2020, label="2020년")
plt.bar(x[2], 평균2021, label="2021년")
plt.bar(x[3], 평균2022, label="2022년")
plt.legend() # 범례 표시
plt.xlabel("이번달 소비금액 & 연도별 평균 소비금액") # x축 레이블
plt.ylabel("카드사용금액") # y축 레이블
plt.grid(True, axis="y", linestyle=":") # 그리드 선 표시
return
# 이번달 소비금액 카테고리별 비율
def draw_piechart():
# plt.figure() # 새로운 차트 그리기 시작
plt.subplot(3, 1, 3) # 가로 1칸, 세로 1칸 사이즈의 차트를 3번째로 그리기 시작하기
plt.title("이번달 소비금액 카테고리별 비율") # 차트의 제목
plt.pie(이번달소비금액, labels=소비카테고리, autopct="%.1f%%") # 각 파이 위에 소수점 1자리까지 표시
plt.legend() # 범례 표시
return
# 파이썬 파일을 직접 실행시키면 작동하는 로직
if __name__ == "__main__":
main()자 이제 진짜로 완성됐어! 어때? 전체적인 코드가 훨씬 깔끔해보이고, 각 코드의 역할이 분명하게 보여지지? 이렇게 결과물의 변경 없이 내부 코드만 개선하는 것이 코드 리팩토링이야.
위의 완성된 코드에서 특이한 점은 global x축, global y축2020 ... 이라는 코드인데, 이건 전역변수 x축, y축2020 등 에 대한 변경을 허용하겠다는 의미야. 이 코드가 없으면 전역변수 x축, y축2020 등 의 변수의 값을 변경할 수가 없으니 반드시 알아둬야 해.
다만 이건 상식적으로 알아둬야 하는데, 전역변수를 사용해서 접근하는 건 코드의 결합도(Coupling)를 높이는 안좋은 방법 이야. 따라서 실무에서는 권장되지 않지만, 우리는 초심자이기 때문에 이해의 편리함을 위해 전역변수를 사용했다는 점 이해해줘. :-)
이 프로젝트의 응용
프로그래밍에서 가장 중요한 것은 '응용'이야. 개발서적은 특정 목적지로 가는 가장 쉽고 빠른 방법을 알려준 것 뿐이지, 결코 내가 진정으로 원하는 길은 아닐거야. 내가 진정으로 원하는 길을 가기 위해서는 응용이 필요해.
서울에서 부산으로 가려고 한다면, 책은 가장 흔한 길을 길찾기 검색 마냥 찍어서 알려 줄 뿐이야. 가는 길 하나를 외운다고 정말 그 길을 잘 찾아갈 수 있을까? 결코 아니겠지.
현실에서 직접 차를 타고 이동해보면 어떤 길은 밀리고, 어떤 길은 사고가 나서 못갈 수도 있고, 중간에 편의점이나 주유소를 들려야 할 수도 있고, 아예 목적지가 바뀌는 경우도 많지. 이런 수많은 케이스들을 극복하기 위해서는 반드시 '응용력'이 필요해.
우리는 방금 배웠던 코드를 익힘으로서 비슷한 프로그램들을 응용해서 구현할 수 있어.
- 나만의 가계부를 만들어보기
- 코로나바이러스 통계 데이터로 원하는 차트 파이썬으로 그려보기
- PPT 발표용 차트를 파이썬으로 그려보기
다음 프로젝트도 함께 도전해보자, 다음은 우리의 실생활과 밀접하게 관련된 프로젝트라서 더욱 더 재밌을거야!😃
