본 글의 저작권과 원문은 https://blog.naver.com/sweetie_rex 에 있습니다.
현재의 글은 업데이트가 되지 않음을 유의해서 읽어주세요.
최신 업데이트 된 글을 읽으시려면 아래의 링크를 확인해주세요.
Python 응용 프로젝트(2) - 중고나라 크롤링
자 이제 진짜 시작이야. 드디어 우리가 공부한 것들을 이용해서 무언가 가치있는 것을 만들어 볼 차례라구!
소프트웨어 개발이란, 대부분의 경우 아래 3가지 절차를 따르게 되어 있어.
- 문제 정의 (Problem)
- 해결 방안 (Solution)
- 구현 (Implements)
첫번째 프로젝트는 내가 가장 좋아하는 기능을 만들어보려고 해.
다들 이런 경험 있을거야.
Problem (문제 정의)
중고나라에서 삼성/LG 노트북(또는 어떤 물건이든)을 저렴하게 구매하고 싶은데, 원하는 물건이 언제 나올지 몰라서 계속 확인해야 하는 경우가 있지.
계속 확인하지 않으면 좋은 물건 다 뺏기고.. 계속 보고있자니 너무 피곤하고.. 해야할 일은 많은데 언제 하나하나 보고있나.. 내가 원하는 물건이 뙇! 나오면 나한테 알림이 뙇! 와주면 좋을텐데 말이야.
바로 우리가 원하는 그런 기능을 만들어보려고 해.
우리는 중고나라의 내부 코드들을 분석해서, 우리가 원하는 정보를 추출하고 재가공한 다음, 우리가 원하는 동작을 자동으로 해주는 프로그램을 만들거야. 이렇게 웹페이지의 데이터를 추출해 내는 행위를 크롤링(Crawling) 이라고 해.
크롤링을 하는 소프트웨어를 크롤러(Crawler) 라고 하는데, 이런 크롤링 기법은 아주 많은 영역에서 자주 사용되는 방식이야.
그래서 우리의 첫 프로젝트는 중고나라 크롤링!
이제 모든 꿀거래는 너의 것!
Solution (해결 방안)
- 중고나라 웹사이트에 접속한다.
- 특정 게시판(노트북)을 클릭한다.
- 목록을 쭉 본다.
- 내가 원하는 상품이 있는 경우, 게시물을 열어본다.
- 원하는 물건이 없으면 게시판을 새로고침 한다.
- 한번 본 상품은 다시 확인하지 않는다.
- 이것을 30초마다 계속 반복한다.
Implements (구현)
파이썬 코드를 작성할 crawling-joongonara.py 파일을 생성하자.
이제 위의 솔루션을 차례대로 코드로 구현해볼게.
- 중고나라 웹사이트에 접속한다.
- 특정 게시판(노트북)을 클릭한다.
먼저 중고나라 웹사이트의 특정 게시판에 접속하기 위해서는 URL 이 필요해. 아주 간단하게 아래의 방법으로 가져올 수 있어.
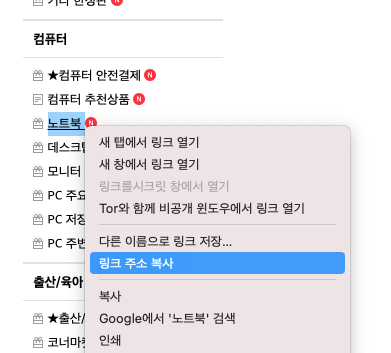
중고나라 카페에 접속한 다음 게시판 목록중에 "노트북" 을 찾아서 오른쪽 클릭을 한 다음, "링크 주소 복사" 를 한 다음, crawling-joongonara.py 파일에 아래처럼 작성해보자.
# 전역변수 선언 및 초기화
URL = "https://cafe.naver.com/ArticleList.nhn?search.clubid=10050146&search.menuid=334&search.boardtype=L"
my_arr = [] # 정제된 데이터를 저장할 array
is_first = True # 프로그램을 처음 실행시켰는지 여부
target = ["삼성", "갤럭시북", "LG", "gram", "엘지", "그램"] # 1개라도 포함되어야함
excepts = ["삽니다", "매입", "구매", "구입"] # 1개라도 포함되면 안됨URL 변수를 만들고 그 값으로 복사한 링크를 넣어줬어.
그럼 이제 URL 변수를 이용해서 네이버카페 서버에 요청(request)을 보내야해.
당연히 브라우저가 내부적으로 어떻게 돌아가고 있는지 잘 모를테니 간단하게 설명해볼게.
- 우리가 Chrome, Internet Explorer 등 웹브라우저의 주소창에 URL 을 입력하면,
- 해당 URL 을 담당하고 있는 서버에 요청이 전송되고,
- 서버는 그 요청에 적절한 응답(response)을 만들어서 보내주고,
- 우리가 사용하는 웹브라우저는 그 응답을 받아서,
- 화면에 결과를 출력하면 우리가 웹페이지를 볼 수 있는거지.
웹페이지 내에 있는 어떠한 링크를 클릭했을 때에도 위와 똑같은 절차가 반복 돼.
이처럼 우리가 웹 브라우저로 웹페이지에 접속하는 모습을 그대로 프로그래밍으로 구현할 수 있어.
프로그래밍은 현실에서 이루어지는 절차를 소스코드로 옮긴 것이기 때문에, 현실의 절차를 잘 정리하면 어떤 것이든 만들기 쉬울거야!
작성했던 코드에 추가로 다음 코드를 작성해보자.
import requests
import time
# 요청을 보내는 행위를 추상화한 function
def request(url):
try:
response = requests.request('GET', url)
except Exception as e:
print("오류 발생")
print(e)
print("5초 후 재시도")
time.sleep(5)
request(url)
# 재귀함수 호출
if response.status_code != 200:
print(response.status_code)
raise f'${response.status_code}'
return response.text # HTML 데이터맨 첫번째 줄 import requests 라는 코드는 requests 라는 http 요청을 담당해주는 오픈소스 라이브러리 를 불러오는 코드야. 이전 오픈소스 설명에서 "오픈소스를 제대로 이해하고 잘 활용하는 것이야말로 현재 이 시대에 스마트한 개발자로 살아가는 가장 빠르고 현명한 방법" 이라고 설명했었지? 그래서 우리는 프로젝트를 진행하며 적극적으로 오픈소스 라이브러리를 사용할거야. 이것을 '모듈(module)' 이라고 표현해.
그리고 time 이라는 모듈은 시간과 관련된 로직을 구현할 때 자주 사용되는 모듈이야. 여기에서는 request 에 실패시 5초 단위로 재시도(재귀함수 호출)를 하기 위해 사용했어.
그리고 def request(url): 부분은 바로 위에서 설명한 5가지 절차를 그대로 구현한 request 함수야. 요청(request)이라는 행위를 추상화 한 함수지.
여기에는 우리가 그동안 배웠던 예외처리, 재귀함수 등 다양한 문법들이 포함되어 있어.
URL 을 http 프로토콜로 요청(request)을 보내면, cafe.naver.com(네이버카페) 의 서버가 응답(response)을 주는데, 그 응답은 HTML 이라는 형식으로 만들어져있어.
HTML은 Hyper-Text Markup Language 의 약자인데, 웹사이트에서 눈에 보이는 모든 영역은 전부 다 HTML 로 구성되어 있어. 네이버든 구글이든 중고나라든 네이버카페든 블로그든 PC버전이든 모바일이든 전세계 어느 웹사이트든 말이야. 그래서 웹사이트를 만들고싶다면 HTML 을 반드시 잘 알고 있어야해. 크롤링을 할때에도 마찬가지야. 크롤링은 웹사이트를 역으로 분석해서 필요한 정보를 추출하는 작업이니까 말이야.
그럼 이제 서버에 요청을 보내고, HTML 을 분석해서 현재 게시판에 어떤 내용들이 있는지 확인해볼까?
- 목록을 쭉 본다.
목록을 보는 행위는 기본적으로 HTML 과 CSS Selector 라는 것을 이해해야 잘 할 수 있는데, HTML 은 여러 태그들이 구조적으로 계층을 이루면서 설계가 되어있어. 웹페이지의 각각의 요소(버튼, 링크, 제목, 글, 이미지 등등)는 tag(태그) 라는 것으로 이루어져 있는데, 이 태그들을 분석하면 결국 우리가 원하는 데이터를 추출해 낼 수 있어.
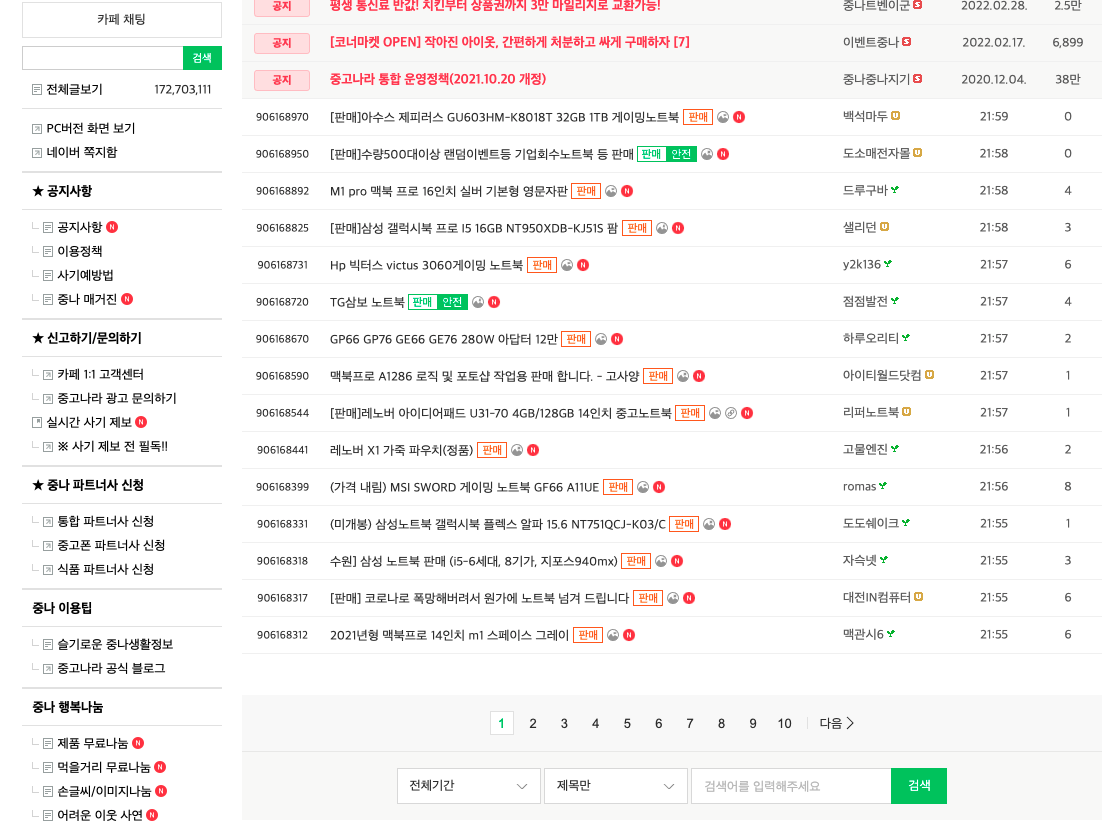
우리는 중고나라 웹페이지에 보이는 수많은 HTML 구성요소 중에서 목록(그 중에서도 게시물의 제목)에 대한 태그들을 추출할거야.
아래 코드를 작성하면서 동작원리를 살펴보자.
정확한 이해를 돕기위해 꼭 주석까지 함께 작성해줘!
from bs4 import BeautifulSoup
html = request(URL)
# 서버에 요청을 보내고 응답으로 HTML string 데이터를 받음
soup = BeautifulSoup(html, 'html.parser')
# 파이썬 라이브러리 BeautifulSoup 를 이용해서 html 데이터를 파싱
tr_arr = soup.select('#main-area > div.article-board:not([id="upperArticleList"]) > table > tbody > tr')
# 파싱된 html 데이터의 내부 tag 에 CSS Selector 로 순차적으로 접근해서,
# 'tbody' 태그 하위의 모든 'tr' 태그들을 가져옴 (array 형태로)
# 이 tr 태그가 바로 게시판 목록의 한줄, 한줄을 표현하는 태그! ('tr' 은 table row 의 줄임)
# 목록의 한줄(row)에는 게시물 번호, 제목, 판매/구매 여부, 판매자닉네임, 시간, 조회수 등이 들어있음
# tr 태그들을 for loop 을 이용해서 하나씩 분석
for tr in tr_arr:
is_new_item = True
# 새로운 상품인지 여부를 표현하는 변수 생성
# 기본적으로 '새로운 상품이 있을 것이다' 라는 접근으로 True 값을 넣음
a_tag = tr.select_one('td.td_article a')
# tr 태그 내부에 CSS Selector 로 접근해서 'a' 태그를 가져옴 ('a' 는 anchor 의 줄임)
# a 태그에는 우리가 원하는 '제목' 이 들어있음
map = {
"title": a_tag.text.strip(),
"url": a_tag["href"],
"is_checked": False,
}
# 우리에게 딱 필요한 데이터만 정제하여 map 으로 만듦
# 나의 데이터목록을 for loop 으로 확인
for element in my_arr:
# 기존에 확인했던 element 와 방금 새로 확인한 map 데이터가 같은지 비교
if element["url"] == map["url"]:
is_new_item = False
# url 값이 같다면 새로운 데이터가 아님!
break
# 만약 새로운 데이터라면
if is_new_item:
my_arr.insert(0, map)
# 나의 데이터목록에 추가
print(my_arr)Python 에서 HTML 을 분석(parsing)하는데 가장 유명한 오픈소스 라이브러리는 beautifulsoup4(아름다운 수프 4)야.
from bs4 import BeautifulSoup 이라는 코드는 라이브러리의 이름이 bs4 이고, 해당 라이브러리 내에 존재하는 BeautifulSoup 를 가져오라는 의미야. 아마 눈치 빠른 사람들은 알았을 텐데, PascalCase 로 되어있어서 딱 봐도 class 라는 것을 알 수 있지. 즉, BeautifulSoup 는 Class 를 instance 화 할 수 있는 '생성자(Constructor)'야. (잘 기억이 안난다면 이전의 Class & instance & Constructor 영역을 다시 읽어보기)
요청(request)을 보내서 응답(response)으로 받은 html 을 BeautifulSoup 생성자에 파라메터로 넣고, soup 이라는 instance 를 생성한 다음, soup 의 select() 메소드를 이용해서 <tr> 태그를 찾았어.
그 다음에 <tr> 태그가 여러개 담겨있는 tr_arr 배열을 for loop 으로 반복해서 우리에게 필요한 map 데이터를 만들고, my_arr 에 저장하는 과정을 구현했어.
필요한 데이터를 구했으니, 그 데이터들 중에 내가 원하는 상품이 있는지 확인해봐야겠지?
- 내가 원하는 상품이 있는 경우, 게시물을 열어본다.
위의 동작을 check_my_arr 라는 function 으로 추상화 해볼게. 계속해서 기존 코드에 덧붙여서 작성해보자.
import webbrowser
# 나의 데이터목록을 확인하는 로직을 추상화한 function
def check_my_arr():
# 나의 데이터목록을 for loop 으로 확인
for element in my_arr:
# 만약 확인하지 않은 게시물이 있다면
if not element["is_checked"]:
element["is_checked"] = True
# 이제 확인할 예정이니, 미리 확인한 것으로 변경
print(f'element["title"] ==> ', element["title"])
# 콘솔에 제목 출력
# 만약 제목중에 1개라도 포함되어야할 단어가 있고, 제목중에 포함되어서는 안되는 단어가 1개도 없다면,
if any(x in element["title"] for x in target) and not any(x in element["title"] for x in excepts):
print(f'새로운 아이템 등장 ==> ', element["title"])
webbrowser.open(f"https://cafe.naver.com{element['url']}")
# 바로 확인할 수 있도록 웹 브라우저 열기
check_my_arr()
# 나의 데이터목록 확인첫번째 줄에 임포트한 webbrowser 모듈은 우리 컴퓨터의 웹브라우저를 조작할 수 있어. 원하는 상품을 발견했는데 직접 URL 을 타이핑해서 접속하면 너무 귀찮으니까, 발견하는 즉시 브라우저를 열어주면 훨씬 편하겠지? 그러려고 사용한 모듈이야!
나머지 코드는 주석에 상세히 적혀있는대로 내가 저장한 데이터에서 확인하지 않은 게시물이 있는지 체크한 다음, 원하는 데이터라면 웹브라우저에서 바로 열어주는 로직이야.
근데 if any(x in element["title"] for x in target) and not any(x in element["title"] for x in excepts): 이 부분이 상당히 난해하게 느껴질 수도 있어.
이건 파이썬의 내장함수 중 any() 라는 함수를 이용해서 제목을 검사하는 부분인데, any() 함수의 파라메터로 들어가는 x in element["title"] for x in target 코드는 영어의 어순처럼 뒤에서부터 읽으면 돼.
target배열의 요소들을 변수x로 설정하고,element["title"]의 내용 안에 변수x의 값이 들어있는지 검사
직역하면 위와 같아. 바로 뒤에 not 연산자와 따라오는 것은 그 반대지.
첫번째는 제목에 반드시 포함되어야하는 단어가 있는지 확인하는 것이고,
두번째는 제목에 반드시 포함되면 안되는 단어가 있는지 확인하는 거야.
내가 삼성 또는 LG노트북을 구매할거라면, 레노버나 HP 같은건 볼 필요 없잖아?
그리고 내가 구매자인데 "고가에 매입합니다" 같은 글도 볼 필요가 없잖아?
프로그래밍은 인생과 닮아있고, 우리가 생각하는 모든 절차를 그대로 구현해주면 돼.
여기까지 입력하고 실행하면 원하는 상품이 있을경우 바로 브라우저가 열리게 될거야.
한번에 여러가지 개념이 동시에 들어가고 코드가 길어지니까 조금 어렵게 느껴질거야. 하지만 늘 생각하자. 어려운 것이 아니라, 익숙하지 않은 뿐이라는 것을!
이제 거의 다왔어.
- 원하는 물건이 없으면 게시판을 새로고침 한다.
- 한번 본 상품은 다시 확인하지 않는다.
- 이것을 30초마다 계속 반복한다.
위 3가지를 한번에 처리할건데, 이 내용들을 읽어보면 뭔가 공통된 느낌이 있어. 바로 '반복' 이야.
우리는 프로그래밍의 꽃 인 반복문을 이용해서 이 모든 시스템을 자동화해서 나 대신 컴퓨터가 중고나라를 항상 쳐다보고 있게 만들거야. 내가 해야할 노동을 컴퓨터에게 맡겨버리는거지!
여태까지 작성한 모든 코드들 중, 맨 위의 '전역변수' 부분을 제외한 나머지 모든 코드들을 반복문으로 감싸주자.
# 전역변수 선언 및 초기화
URL = "https://cafe.naver.com/ArticleList.nhn?search.clubid=10050146&search.menuid=334&search.boardtype=L"
my_arr = [] # 정제된 데이터를 저장할 array
is_first = True # 프로그램을 처음 실행시켰는지 여부
target = [...] # 1개라도 포함되어야함
excepts = [...] # 1개라도 포함되면 안됨
# 무한 반복
while True:
import requests
import time
# 요청을 보내는 행위를 추상화한 function
def request(url):
... 나머지 모든 코드들 ...
check_my_arr()
# 나의 데이터목록 확인
print('reload')
time.sleep(30)이렇게 작성한 후에 코드를 실행해보면, 30초마다 중고나라 노트북 상품들을 반복해서 확인하는 모습을 볼 수 있을거야.
짜잔! 나만의 중고나라 크롤러가 완성되었어!
초기버전 코드
# 전역변수 선언 및 초기화
URL = "https://cafe.naver.com/ArticleList.nhn?search.clubid=10050146&search.menuid=334&search.boardtype=L"
my_arr = [] # 정제된 데이터를 저장할 array
is_first = True # 프로그램을 처음 실행시켰는지 여부
target = ["삼성", "갤럭시북", "LG", "gram", "엘지", "그램"] # 1개라도 포함되어야함
excepts = ["삽니다", "매입", "구매", "구입"] # 1개라도 포함되면 안됨
# 무한 반복
while True:
import requests
import time
# 요청을 보내는 행위를 추상화한 function
def request(url):
try:
response = requests.request('GET', url)
except Exception as e:
print("오류 발생")
print(e)
print("5초 후 재시도")
time.sleep(5)
request(url)
# 재귀함수 호출
if response.status_code != 200:
print(response.status_code)
raise f'${response.status_code}'
return response.text # HTML 데이터
from bs4 import BeautifulSoup
html = request(URL)
# 서버에 요청을 보내고 응답으로 HTML string 데이터를 받음
soup = BeautifulSoup(html, 'html.parser')
# 파이썬 라이브러리 BeautifulSoup 를 이용해서 html 데이터를 파싱
tr_arr = soup.select('#main-area > div.article-board:not([id="upperArticleList"]) > table > tbody > tr')
# 파싱된 html 데이터의 내부 tag 에 CSS Selector 로 순차적으로 접근해서,
# 'tbody' 태그 하위의 모든 'tr' 태그들을 가져옴 (array 형태로)
# 이 tr 태그가 바로 게시판 목록의 한줄, 한줄을 표현하는 태그! ('tr' 은 table row 의 줄임)
# 목록의 한줄(row)에는 게시물 번호, 제목, 판매/구매 여부, 판매자닉네임, 시간, 조회수 등이 들어있음
# tr 태그들을 for loop 을 이용해서 하나씩 분석
for tr in tr_arr:
is_new_item = True
# 새로운 상품인지 여부를 표현하는 변수 생성
# 기본적으로 '새로운 상품이 있을 것이다' 라는 접근으로 True 값을 넣음
a_tag = tr.select_one('td.td_article a')
# tr 태그 내부에 CSS Selector 로 접근해서 'a' 태그를 가져옴 ('a' 는 anchor 의 줄임)
# a 태그에는 우리가 원하는 '제목' 이 들어있음
map = {
"title": a_tag.text.strip(),
"url": a_tag["href"],
"is_checked": False,
}
# 우리에게 딱 필요한 데이터만 정제하여 map 으로 만듦
# 나의 데이터목록을 for loop 으로 확인
for element in my_arr:
# 기존에 확인했던 element 와 방금 새로 확인한 map 데이터가 같은지 비교
if element["url"] == map["url"]:
is_new_item = False
# url 값이 같다면 새로운 데이터가 아님!
break
# 만약 새로운 데이터라면
if is_new_item:
my_arr.insert(0, map)
# 나의 데이터목록에 추가
import webbrowser
# 나의 데이터목록을 확인하는 로직을 추상화한 function
def check_my_arr():
# 나의 데이터목록을 for loop 으로 확인
for element in my_arr:
# 만약 확인하지 않은 게시물이 있다면
if not element["is_checked"]:
element["is_checked"] = True
# 이제 확인할 예정이니, 미리 확인한 것으로 변경
print(f'element["title"] ==> ', element["title"])
# 콘솔에 제목 출력
# 만약 제목중에 1개라도 포함되어야할 단어가 있고, 제목중에 포함되어서는 안되는 단어가 1개도 없다면,
if any(x in element["title"] for x in target) and not any(x in element["title"] for x in excepts):
print(f'새로운 아이템 등장 ==> ', element["title"])
webbrowser.open(f"https://cafe.naver.com{element['url']}")
# 바로 확인할 수 있도록 웹 브라우저 열기
check_my_arr()
# 나의 데이터목록 확인
print(f'reload')
time.sleep(10)
하지만 사실 위 코드들은 원하는대로 작동하긴 하지만 코드가 매우 더럽고 개판이야... 이런걸 스파게티 코드(spaghetti code) 라고 부르지... 소스 코드가 복잡하게 얽힌 모습을 스파게티의 면발에 비유한 표현이야. 우리는 개발자로서 이 더러운 코드들을 클린하게 정리해야할 의무가 있어.
이러한 과정을 Refactoring(리팩토링) 이라고 불러.
코드 리팩토링을 해보자
Refactoring(리팩토링) 이란, 프로그램의 동작을 바꾸지 않으면서 구조를 개선한다는 의미야. 실제로 프로그램이 작동하는 결과물은 완전 동일하지만, 내부 소스코드를 더 깔끔하게 개선하는 작업이지.
지금까지의 코드는 너무너무 대충 쓴 상태고, 이런식으로 코딩하면 나중에 유지보수가 불편해서 개발이 힘들어져. 파이썬의 가장 기본적인 구조부터 시작해볼게.
파이썬 프로그램을 단일 파일에 작성할때는 아래와 같은 구조로 코딩하는게 보편적이야.
# 프로그램 구현에 필요한 모듈 가져오기
import ...
# 전역변수 선언 및 초기화
URL = ...
...
# 프로그램을 시작하면 가장 먼저 실행되는 메인함수
def main():
...
# 요청을 보내는 행위를 추상화한 function
def request(url):
...
# 나의 데이터목록을 확인하는 로직을 추상화한 function
def check_my_arr():
...
# 파이썬 파일을 직접 실행시키면 작동하는 로직
if __name__ == "__main__":
main()여기에서 __name__ == "__main__" 이 코드가 핵심인데, 파이썬은 내부적으로 __name__ 이라는 변수를 가지고 있고, 터미널에서 python 파일을 직접 실행시키면 해당 파일의 __name__ 변수에 "__main__" 이라는 string 값을 자동으로 넣어줘.
그래서 위 로직이 실행되는거지.
그리고 이 구조에서 main() 이라는 함수를 선언하고, 모든 주요 로직들을 main() 함수 내에 구현한 뒤, if 문 내에서 main() 함수를 실행시키는게 보편적인 구조라고 할 수 있어.
이런 구조로 코딩하면 함수를 선언 순서와 관계없이 언제든지 사용할 수 있어서 편해.
그리고 계속 파이썬 개발자로 지내다보면 추후에 알게되겠지만 모듈 테스트 에 용이한 구조야. 사실 모듈테스트가 핵심 내용이지. 그렇기 때문에 이런 구조로 작성하는 버릇을 들여보자.
이 구조로 위의 소스코드를 리팩토링 해보면 아래와 같이 작성할 수 있어.
완성된 소스코드
# 프로그램 구현에 필요한 모듈 가져오기
import requests
from bs4 import BeautifulSoup
import webbrowser
import time
# 전역변수 선언 및 초기화
URL = "https://cafe.naver.com/ArticleList.nhn?search.clubid=10050146&search.menuid=334&search.boardtype=L"
my_arr = [] # 정제된 데이터를 저장할 array
is_first = True # 프로그램을 처음 실행시켰는지 여부
target = ["삼성", "갤럭시북", "LG", "gram", "엘지", "그램"] # 1개라도 포함되어야함
excepts = ["삽니다", "매입", "구매", "구입"] # 1개라도 포함되면 안됨
# 프로그램을 시작하면 가장 먼저 실행되는 메인함수
def main():
# 무한 반복
while True:
html = request(URL)
# 서버에 요청을 보내고 응답으로 HTML string 데이터를 받음
soup = BeautifulSoup(html, 'html.parser')
# 파이썬 라이브러리 BeautifulSoup 를 이용해서 html 데이터를 파싱
tr_arr = soup.select('#main-area > div.article-board:not([id="upperArticleList"]) > table > tbody > tr')
# 파싱된 html 데이터의 내부 tag 에 CSS Selector 로 순차적으로 접근해서,
# 'tbody' 태그 하위의 모든 'tr' 태그들을 가져옴 (array 형태로)
# 이 tr 태그가 바로 게시판 목록의 한줄, 한줄을 표현하는 태그! ('tr' 은 table row 의 줄임)
# 목록의 한줄(row)에는 게시물 번호, 제목, 판매/구매 여부, 판매자닉네임, 시간, 조회수 등이 들어있음
# tr 태그들을 for loop 을 이용해서 하나씩 분석
for tr in tr_arr:
is_new_item = True
# 새로운 상품인지 여부를 표현하는 변수 생성
# 기본적으로 '새로운 상품이 있을 것이다' 라는 접근으로 True 값을 넣음
a_tag = tr.select_one('td.td_article a')
# tr 태그 내부에 CSS Selector 로 접근해서 'a' 태그를 가져옴 ('a' 는 anchor 의 줄임)
# a 태그에는 우리가 원하는 '제목' 이 들어있음
map = {
"title": a_tag.text.strip(),
"url": a_tag["href"],
"is_checked": False,
}
# 우리에게 딱 필요한 데이터만 정제하여 map 으로 만듦
# 나의 데이터목록을 for loop 으로 확인
for element in my_arr:
# 기존에 확인했던 element 와 방금 새로 확인한 map 데이터가 같은지 비교
if element["url"] == map["url"]:
is_new_item = False
# url 값이 같다면 새로운 데이터가 아님!
break
# 만약 새로운 데이터라면
if is_new_item:
my_arr.insert(0, map)
# 나의 데이터목록에 추가
# 만약 프로그램 첫 실행이라면
global is_first
if is_first:
is_first = False
# 더이상 처음이 아님으로 바꿔주기
for element in my_arr:
element["is_checked"] = True
# 모든 초기 데이터의 "is_checked" 값을 True 로 설정
continue
# 아래 로직을 수행하지 않고 다음 loop 를 진행
check_my_arr()
# 나의 데이터목록 확인
# 아래에 선언된 함수의 구현체 참조
print(f'reload')
time.sleep(10)
# 10초 간격
return
# 요청을 보내는 행위를 추상화한 function
def request(url):
try:
response = requests.request('GET', url)
except Exception as e:
print("오류 발생")
print(e)
print("5초 후 재시도")
time.sleep(5)
request(url)
# 재귀함수 호출
if response.status_code != 200:
print(response.status_code)
raise f'${response.status_code}'
return response.text # HTML 데이터
# 나의 데이터목록을 확인하는 로직을 추상화한 function
def check_my_arr():
# 나의 데이터목록을 for loop 으로 확인
for element in my_arr:
# 만약 확인하지 않은 게시물이 있다면
if not element["is_checked"]:
element["is_checked"] = True
# 이제 확인할 예정이니, 미리 확인한 것으로 변경
print(f'element["title"] ==> ', element["title"])
# 콘솔에 제목 출력
# 만약 제목중에 1개라도 포함되어야할 단어가 있고, 제목중에 포함되어서는 안되는 단어가 1개도 없다면,
if any(x in element["title"] for x in target) and not any(x in element["title"] for x in excepts):
print(f'새로운 아이템 등장 ==> ', element["title"])
webbrowser.open(f"https://cafe.naver.com{element['url']}")
# 바로 확인할 수 있도록 웹 브라우저 열기
# 파이썬 파일을 직접 실행시키면 작동하는 로직
if __name__ == "__main__":
main()자 이제 진짜로 완성됐어.
위의 코드 중간에 보면 아래와 같은 코드들이 추가되었는데, 이것은 프로그램이 첫 실행일 때는 기본적인 초기작업만 해주고 2번째 실행부터 원하는 동작을 하도록 추가해준 로직이야.
# 만약 프로그램 첫 실행이라면
global is_first
if is_first:
is_first = False
# 더이상 처음이 아님으로 바꿔주기
for element in my_arr:
element["is_checked"] = True
# 모든 초기 데이터의 "is_checked" 값을 True 로 설정
continue
# 아래 로직을 수행하지 않고 다음 loop 를 진행특이한 점은 global is_first 라는 코드인데, 이건 전역변수 is_first 에 대한 변경을 허용하겠다는 의미야. 이 코드가 없으면 is_first 변수의 값을 변경할 수가 없으니 반드시 알아둬야 해.
다만 이건 상식적으로 알아둬야 하는데, 전역변수를 사용해서 접근하는 건 코드의 결합도(Coupling)를 높이는 안좋은 방법 이야. 따라서 실무에서는 권장되지 않지만, 우리는 초심자이기 때문에 이해의 편리함을 위해 사용했다는 점 이해해줘. :-)
이 프로젝트의 응용
우리는 이러한 코드를 구현함에 따라서 비슷한 프로그램들을 응용해서 구현할 수 있어.
- 중고나라 상품 자체의 url 까지 접속하여 가격확인까지 하고, 원하는 가격 범위 안에 들어오면 브라우저 띄우기
- 기차표, 비행기표, 공연의 빈자리 티켓팅
- 뉴스의 특정 키워드 알림
어때? 너무 재미있지? 프로그래밍이 우리의 인생에 직접적인 도움이 된다니 말이야!
이 처럼 프로그래밍은 우리의 실생활에서 벌어지는 각종 절차들을 추상화하고 자동화해서 우리의 인생을 편리하게 만들어줄 수 있어.
다음 프로젝트도 함께 도전해보자!😃

안녕하세요~ 소스코드 보고 문의 드려요~
중고나라에서 이게 되면 번개장터도 될까요?