0. 개요
한방 쿼리란?
One-Shot Query로 불리는 한방쿼리는 한 번에 모든 데이터를 가져오기 때문에 데이터베이스와의 통신 횟수를 줄여 성능상 이점이 있을 수 있다.
하지만, 대량의 데이터를 처리하는 경우, 한방 쿼리는 데이터베이스에 부하를 줄 수 있으며, 시스템의 메모리를 많이 사용할 수 있다. 또한, 한방 쿼리가 복잡한 경우 데이터베이스 서버의 부하가 증가하여 다른 쿼리의 처리 속도에도 영향을 미칠 수 있다.
따라서, 한방 쿼리를 사용할 때는 데이터베이스의 상황과 데이터 양, 시스템의 메모리 상황을 고려하여 적절한 분량으로 가져오는 것이 좋다.
1. 문제 상황
게시글의 단건 조회 성능 문제
게시물의 detail(단 건 조회)시 네트워크 통신 response time 이 1400ms 가까이 치솟는 문제가 발생하였다. 이는 백엔드 서버의 성능에 크게 문제가 있다고 판단하였다.
2. 문제 원인 분석
1-1. 서버 성능 문제
프로젝트의 고려 조건중 비용 문제 또한 고려 해야 한다. MSA 구성이기에 일반적인 monolithic 아키텍쳐에 비해 많은 리소스를 차지한다. 처음에는 AWS EC2 freetier 를 기준으로 개발 하였으나, 리소스의 부족으로 원할한 서비스를 제공 할 수 없었다.
그래서, 지인을 통해 서버를 제공받았다. cpu의 코어와 주메모리는 충분하였으나, 네트워크 통신 속도가 상당히 느렸다. AWS EC2 freetier 인스턴스보다도 많이 느린 상태 였다.
하지만, 서비스를 목적에 맞게 배포 하기 위해서는 차선책이라고 생각하여 유지하기로 결정하였다.
1-2. 설계 문제
서버 성능 문제가 발생하여 문제 해결을 위해 어플리케이션의 비효율적인 구조를 개선하고자 하였다.
1-2-1. 비효율적 DB 설계
해당 프로젝트에서는 JPA를 사용한 테이블 설계를 하였다. 그러나 @Entity의 구조에 따라 Database의 table이 종속되며, 이 과정에서 데이터 테이블의 연관관계에 맞는 정규화가 이루어졌다. 그 결과, Post(게시글)와 Applyment(지원)라는 Entity가 분리되었다. 하지만, 해당 서비스에서는 게시글의 단건 조회 시 Applyment의 column의 Count Query를 날려 계산하여 보여줘야 하는 과정때문에 비효율성이 발생하게 되었다.
1-2-2. Query 최적화 문제
JPA를 사용하면 entity관점으로 data를 가져오게 된다. 이 과정에서 통신하는 query의 갯수가 증대 하게 된다. 비효율적인 DB 설계와 합쳐서 게시글의 단건 조회시 7-8개의 쿼리가 나가는것을 확인 하였다.
2. 제한 조건
이 문제를 해결하기 위한 제한 조건은 다음과 같다.
- 게시물의 detail 조회는 One-Shot Query로 해결해야 한다.
- AWS EC2 freetier 인스턴스보다도 느린 서버 환경에서 작업해야 한다.
3. 개선 방법
3-1. DB 설계 개선
위에서 언급했듯이, 게시물 detail 조회 시에는 해당 게시물과 연관된 applyment의 column의 Count Query가 필요하다. 그러나 이러한 설계는 쿼리의 성능을 저하시키는 원인 중 하나였다.
그래서 applyment의 count 정보를 denormalization하여 post 테이블에 추가하였다. 이를 통해 조회 시 별도의 count 쿼리를 발생시키지 않고, 빠르게 조회할 수 있도록 개선했다.
3-2. Query 최적화
Data JPA의 Method Query 기반으로 작성된 query를 QueryDsl을 사용하여 select Query를 한방 쿼리(One-Shot Query)로 작성 하였다.
4. 개선 과정
4-1. DB 설계 개선
<Post.java>
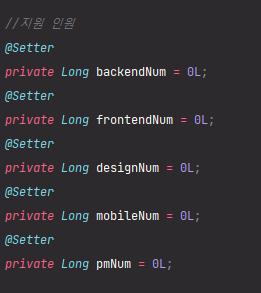
지원 인원을 post entity에 편입 하였다.
<Applyment.java>
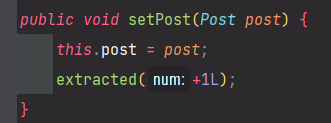
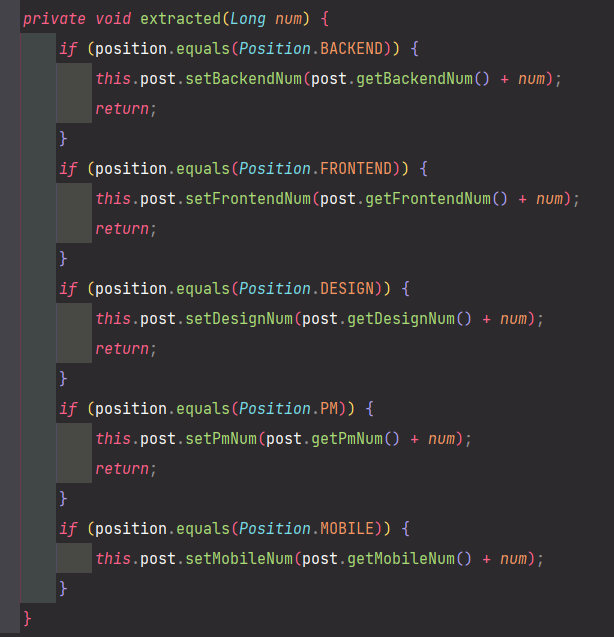
지원시 post의 분야별 지원자의 수를 늘리도록 종속적인 관계를 만들었다.
4-2. Query 최적화
4-2-1. 개선전
<PostService.java>
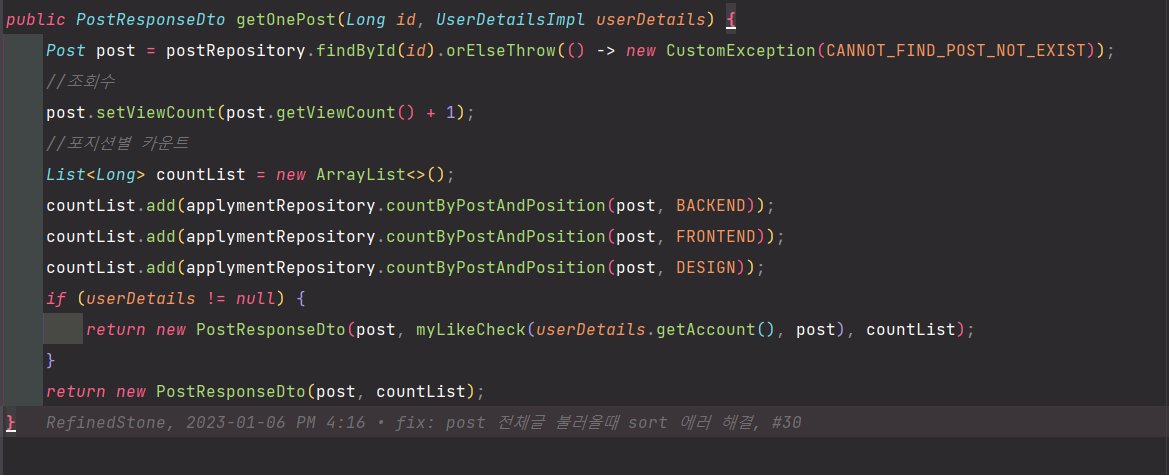
Applyment Repository에서 많은 count Query를 보내 결과 값을 만들어서 response를 보내고 있다.
4-2-2. 개선후
<PostService.java>

<PostRepositoryImpl.java>
- 한방 쿼리 작성
/*게시물 단건 조회*/
@Override
public PostDetailResponseDto findOnePostWithOneQuery(Long id, UserDetailsImpl userDetails) {
/*main-query*/
return queryFactory
.select(Projections.fields(PostOneQuerylResponseDto.class,
Expressions.asNumber(id).as("postId"),
post.duration,
post.createdAt,
techs,
post.title,
post.viewCount,
post.category,
post.postState,
post.place,
post.likesLength,
post.frontReqNum,
post.frontendNum,
post.backReqNum,
post.backendNum,
post.pmReqNum,
post.pmNum,
post.mobileReqNum,
post.mobileNum,
post.designReqNum,
post.designNum,
post.contentUrl,
account.id.as("accountId"),
account.email,
account.nickname,
account.imgUrl.as("profileImg"),
likes.likeCheck
))
.from(techs)
.leftJoin(techs.post, post)
.where(post.id.eq(id))
.leftJoin(post.account, account)
.leftJoin(post.likes, likes).on(usernameEq(userDetails))
.fetch()
/*application region*/
.stream()
.collect(Collectors.groupingBy(
v1 -> {
if (postDetailResponseDto.getAccountId() == null)
BeanUtils.copyProperties(v1, postDetailResponseDto);
return postDetailResponseDto;
},
Collectors.mapping(v2 -> new Techs.TechsResponseDto(v2.getTechs()), Collectors.toList())))
.entrySet().stream()
.map(v3 -> {
v3.getKey().setTechs(v3.getValue());
return v3.getKey();
})
.findAny().orElseThrow(()->new CustomException(FAILED_TO_ACCESS_POST));
}굉장히 복잡하고 길다고 볼 수 있지만, 의외로 굉장히 짧은 코드이다. select를 통해 받아온 데이터를, DTO에 맞게 객체로 변형하는 구조이다. 이 과정에서 Stream과 BeanUils.copyProperties를 사용하지 않았다면, 현재 대략 80라인의 코드가 800줄 이상 되었을 것이다.
※ 참고
BeanUils.copyProperties는 Apache Commons BeanUtils 라이브러리에서 제공하는 유틸리티 메서드 중 하나로, JavaBeans의 프로퍼티 값을 복사하는 기능을 제공한다.
즉, 두 개의 JavaBeans 객체를 인자로 받아서 소스 객체의 프로퍼티 값을 대상 객체의 프로퍼티에 복사하는 것입니다. 이 메서드를 이용하면 코드의 양을 줄일 수 있고, 객체 간에 프로퍼티 값을 복사하는 작업을 편리하게 할 수 있다.
5. 결과
- Response time이 평균 1400ms에서 300ms 까지 개선 되었다.
- 실제 DB에 날리는 Query 갯수가 1개로 제한 조건을 만족 하였다.
Response time 기준: 약 267% 성능 개선 달성
6. 결론
나의 개발 스타일은 항상 무엇이든 TRADE-OFF를 지키는 것이다. 그래서 QUERY 또한, 성능 최적화와 개발편의성 및 수정을 고려해서 작성한다.
하지만, 이번 사례에서는 서버 환경이나 제한 조건 등의 이유로 최적화가 필요했기 때문에, 한방 쿼리를 사용하여 성능 개선을 시도하였다. 하지만 한방 쿼리는 작성 과정에서 공수가 많이 들고, 추후 수정이 필요할 경우 불편한 상황이 발생할 수 있기 때문에, 이러한 방법을 적용할 때는 반드시 장단점을 고려해야 한다.
더 나은 성능과 개발 효율성을 위해서는, 처음부터 설계 과정에서 적절한 정규화를 진행하고, 적절한 인덱스를 설정하고, Query 최적화를 고려하는 등의 방법을 사용하여 성능을 최적화하는 것이 필요하다고 본다.
그래서, 이번과 같이 크게 성능에 문제가 있는것이 아니라면, 한방쿼리는 작성하지 않으려고 한다.

AWS free tier는 참 리소스 부족이 잘 일어나네요..ㅠㅠ
한 방 쿼리의 효율이 대단한 거 같네요 response time을 267% 개선해주다니..
저도 성능 문제가 생길 때 한 방 쿼리를 사용해보겠습니다..!