문제 인식
Spring Boot 애플리케이션에서 DB에 직접 데이터를 전송하는 대신 Kafka Connect를 통해 데이터베이스로 데이터를 전송하려고 합니다. 그러나 Kafka Connect에 데이터를 입력했음에도 불구하고, 데이터베이스가 정상적으로 업데이트되지 않는 문제가 발생했습니다.
전송하는 스키마는 아래와 같습니다.
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int64",
"optional": false,
"field": "test_id"
},
{
"type": "string",
"optional": true,
"field": "content"
},
{
"type": "string",
"optional": true,
"field": "title"
}
],
"optional": false,
"name": "testing"
},
"payload": {
"content": "kafka test",
"title": "test"
}
}Kafka Connect의 연결 문제나 구성 설정 등을 면밀히 검토해보았지만, 문제를 찾을 수 없었습니다. 그렇다면 스키마 형식의 문제가 있을 가능성이 크다고 판단했습니다.
그래서 비효율적이긴 하지만, DB에 저장되는 데이터를 Kafka 소스-커넥트를 통해 역으로 추산하기로 결정했습니다. 그 결과 추산한 스키마는 아래와 같습니다.
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int64",
"optional": false,
"field": "message_id"
},
{
"type": "int64",
"optional": false,
"name": "org.apache.kafka.connect.data.Timestamp",
"version": 1,
"field": "created_at"
},
{
"type": "int64",
"optional": false,
"name": "org.apache.kafka.connect.data.Timestamp",
"version": 1,
"field": "updated_at"
},
{
"type": "string",
"optional": true,
"field": "message"
},
{
"type": "int8",
"optional": false,
"field": "message_check_status"
},
{
"type": "string",
"optional": true,
"field": "sender"
},
{
"type": "int64",
"optional": true,
"field": "room_id"
}
],
"optional": false,
"name": "chat_message"
},
"payload": {
"message_id": 242,
"created_at": 1677750286087,
"updated_at": 1677750286087,
"message": "상돈님 안녕하세요",
"message_check_status": 0,
"sender": "lsd123",
"room_id": 18
}
}내가 처음에 보낸 값과 다른 것은 message_id, timestamp, 그리고 Java에서의 boolean 값인 message_check_status입니다. 이 3가지 값을 면밀히 검증하여 문제를 해결하려고 합니다.
문제 해결
message_id
message_id는 primary key 값으로 절대 누락되어서는 안 되는 값입니다. 하지만 스프링 어플리케이션에서도 그렇지만, 이 값은 넣어주지 않아도 처음에 데이터베이스의 테이블 column 세팅을 auto_increment로 했다면 이 값을 넣지 않아도 자동으로 생성됩니다.
이는 다른 카프카 테스트를 통해 직접 확인한 부분입니다. 그러므로 이 부분은 문제가 되지 않는다고 판단하였습니다.
결과적으로 이 값은 optional: false이지만, 없어도 문제가 전혀 없었습니다.
Boolean data
카프카 사이트의 reference를 참조하였는데 (https://kafka.apache.org/11/javadoc/org/apache/kafka/connect/data/Schema.Type.html) 이 데이터 표를 보고 boolean 값을 넣었습니다.
하지만, 실제 스키마에서는 int8의 형태로 boolean 데이터를 처리하고 있었습니다.
 이 값도 최대한 스키마 원본과 동일하게 하기 위해, boolean 값을 int8의 값을 갖는 형태인 byte로 변경해주었습니다.
이 값도 최대한 스키마 원본과 동일하게 하기 위해, boolean 값을 int8의 값을 갖는 형태인 byte로 변경해주었습니다.
Time_stamp
카프카 커넥트에서 지원하는 timestamp 타입 관리가 있습니다. 그렇다면 분명 간단하게 이런 column 데이터를 삽입, 변경, 삭제하는 방법이 있을 것이라 생각했지만, 실제 해결 방법을 찾지 못했습니다.
결국, 역추산한 스키마의 데이터 형식에 맞춰 보내기로 타협하는 형태로 해결하려고 합니다.
{
"type": "int64",
"optional": false,
"name": "org.apache.kafka.connect.data.Timestamp",
"version": 1,
"field": "created_at"
}다른 스키마와 다른 점은 name과 version 값이 있다는 것입니다.
우선적으로 저 두 값은 생략하고 topic에 보내보았지만 sink-connector가 처리하지 못하였습니다. 그래서, 결국 저 field에 한해서만 두 가지 데이터를 더 보내주는 형태로 문제를 해결하려고 합니다. 우선 Field 클래스의 형태입니다. 다른 데이터는 type, optional, field 세 가지의 값만 사용합니다.
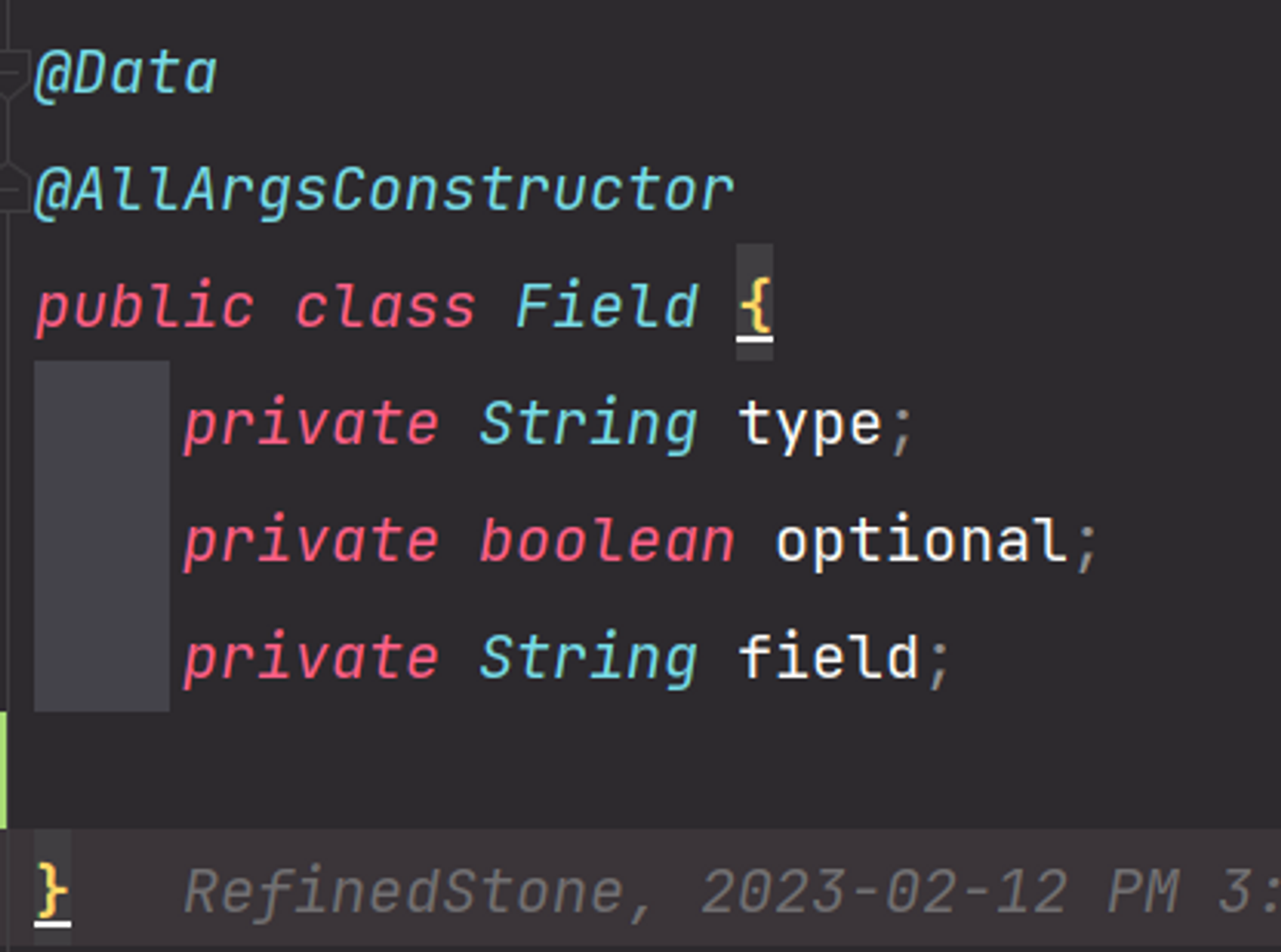 Field 클래스의 멤버 변수 3가지 입니다.
Field 클래스의 멤버 변수 3가지 입니다.
다음은 Field가 모여있는 List<Field>의 형태입니다.
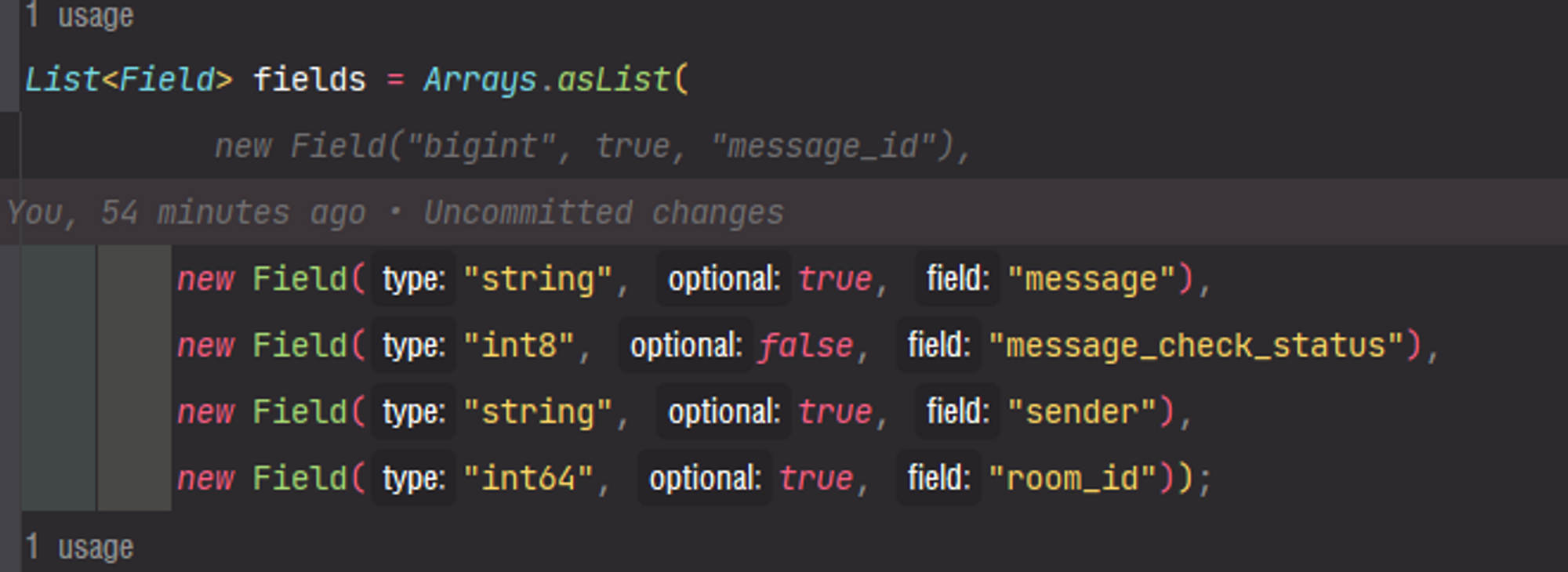 Arrays.asList를 통해,
Arrays.asList를 통해, List<Field>를 구성 하였습니다.
단발성이며 특정 상태에서만 사용하고 소멸되는 형태의 로직이 필요하다고 판단하였습니다. 물론 @builder 패턴을 사용할 수도 있지만, 가독성을 포함하여, 초기화 되지 않은 클래스 멤버의 null 값으로 저장된다는 단점도 확실히 있다고 판단하였습니다.
그래서 고안해낸 방법은 바로 익명 클래스입니다.
한때 넘쳐나는 DTO 클래스를 줄이기 위한 방법으로 고민했던 경험이 있었습니다. 이를 익명 클래스로 부분적으로 해소한 적이 있습니다.
테스트 케이스를 작성하자면 아래와 같습니다.
 익명 클래스를 통해 클래스 멤버 변수의 추가가 가능합니다.
익명 클래스를 통해 클래스 멤버 변수의 추가가 가능합니다.
여기서 중요한 것은, 접근 제한자를 public으로 작성해야한다는 것입니다. 그림과 같이 private이라면, return 값에 포함되지 않습니다.
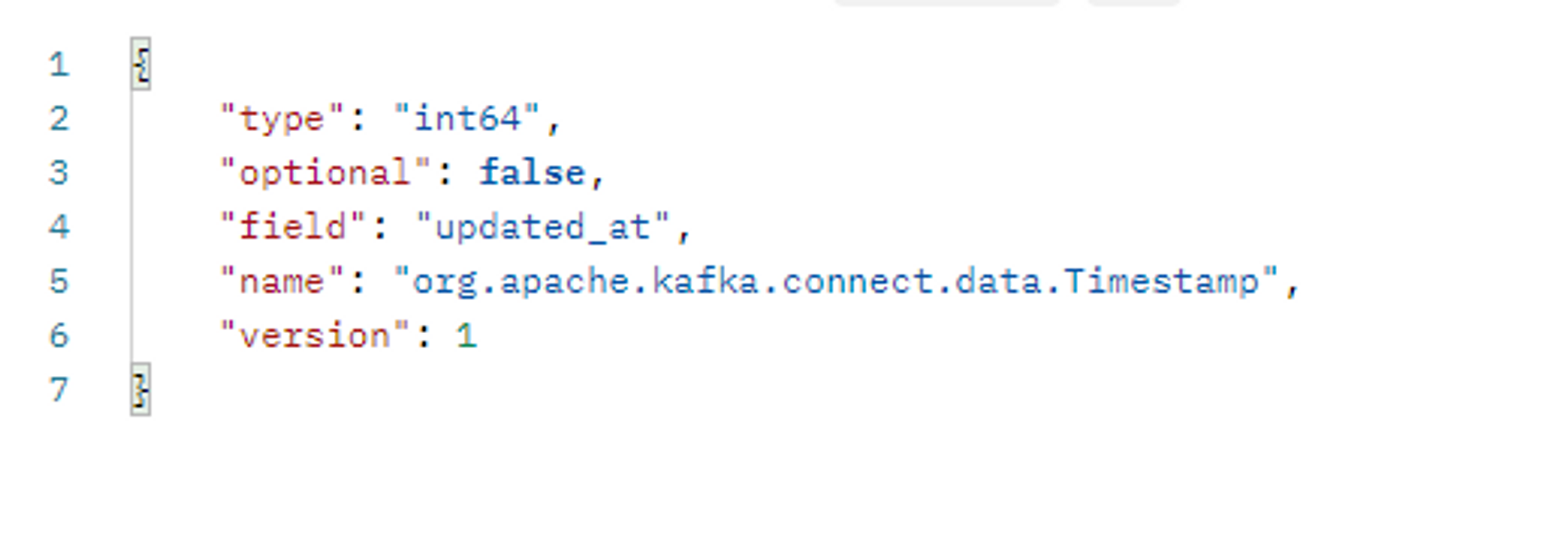 접근 제한자를 public으로 선언해주어야 이렇게 정상적인 return 값을 받을 수 있습니다.
접근 제한자를 public으로 선언해주어야 이렇게 정상적인 return 값을 받을 수 있습니다.
이 방법을 적용한 List<Field> 부분은 다음과 같습니다.
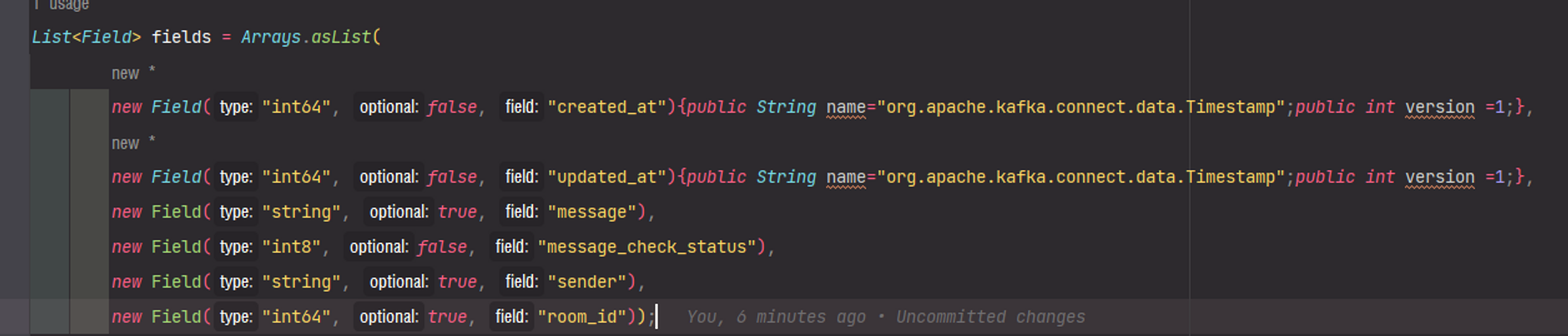 기존의 코드를 최대한 적게 변경하면서 요구 사항을 준수하였습니다.
기존의 코드를 최대한 적게 변경하면서 요구 사항을 준수하였습니다.
Payload도 알맞게 변경해 주었습니다.
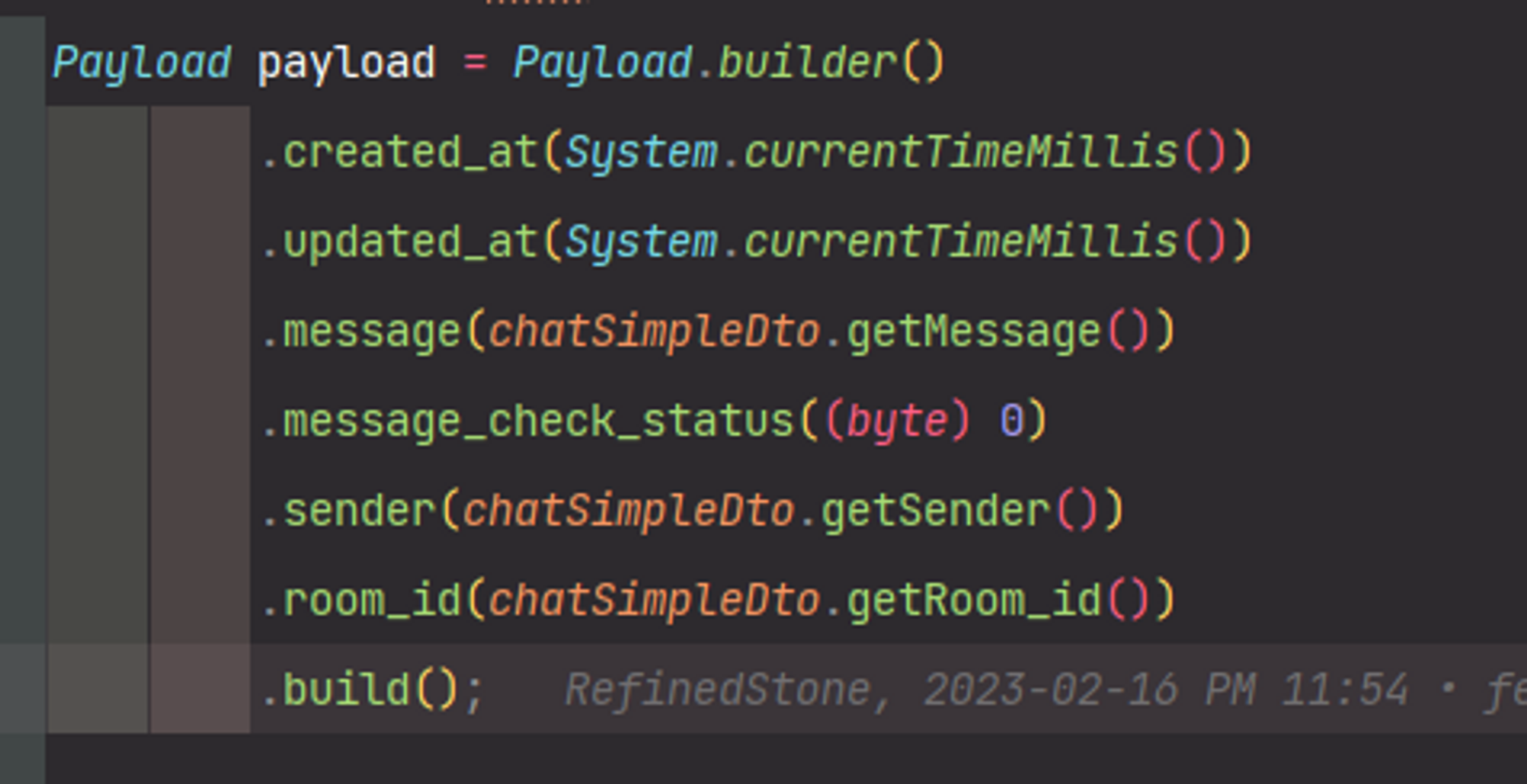 created_at의 값에 System.currentTimeMillis를 넣어 주었습니다.
created_at의 값에 System.currentTimeMillis를 넣어 주었습니다.
결과 확인
우선 Kafka의 topic에 정상적으로 값이 들어오는지 확인 하였습니다
 정상적으로 스키마의 형식이 맞춰진것을 확인 할 수 있습니다
정상적으로 스키마의 형식이 맞춰진것을 확인 할 수 있습니다
카프카 sink-connect가 정상적으로 가동되는지를 체크 하였습니다
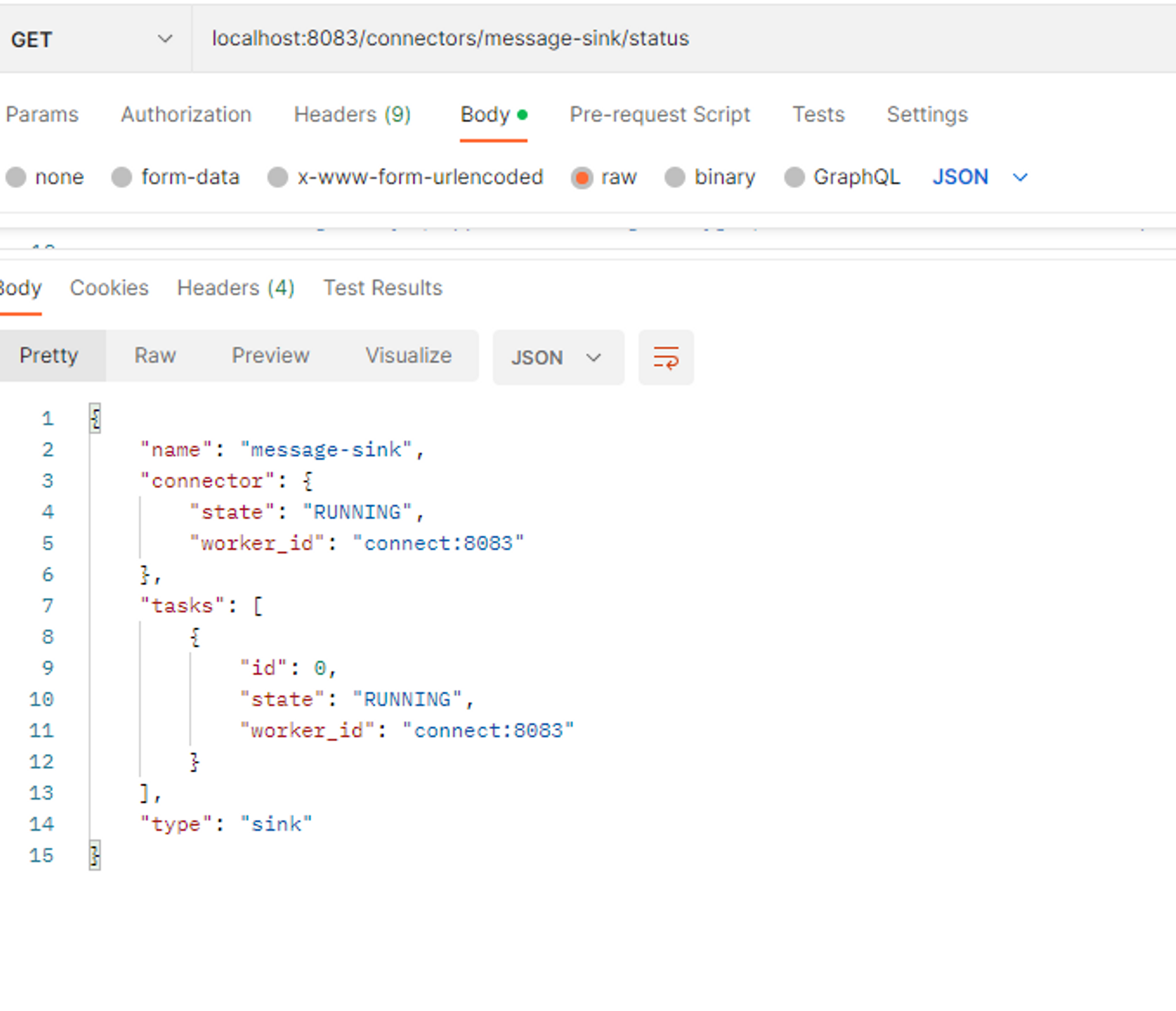 ※ topic을 db데이터와 연결하지 못했다면 tasks가 error를 띔
※ topic을 db데이터와 연결하지 못했다면 tasks가 error를 띔
마지막으로 DB에 정상적으로 값이 insert되었는지 확인하였습니다
 값이 정상적으로 들어온것은 물론, timestamped의 값도 알맞게 입력되었습니다.
값이 정상적으로 들어온것은 물론, timestamped의 값도 알맞게 입력되었습니다.
