
- CVPR 2021에서 발표된 논문
- github
1. Introduction
- 기존의
semantic segmentation모델들은contextual information in high-level feature에 집중했다.
:high-level layer만을 사용하는 것은 edge 등의중요한 detail을 놓칠 수 있어skip-connection등의 기법이 활용된다.- 해당 논문에서는
low-level texture feature가local structure뿐 아니라global statistical knowledge도 가지고 있다고 주장한다.low-level information의distribution을 분석하기 위해STLNet(Statistical Texture Learning Network)을 고안했다고 한다.image texture는 단순boundary,smoothness,coarseness등의local structural property일 뿐 아니라global statistical property라고 주장한다.low-level information을 통해histogram of intensity를 추출하는 일종의spectral domain analysis라고 주장한다.

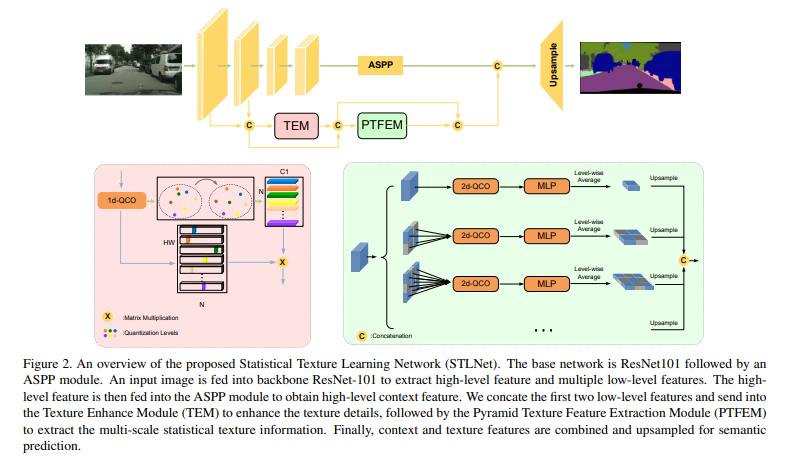
2.Model
- 모델의 크게 3가지 구조를 가진다.
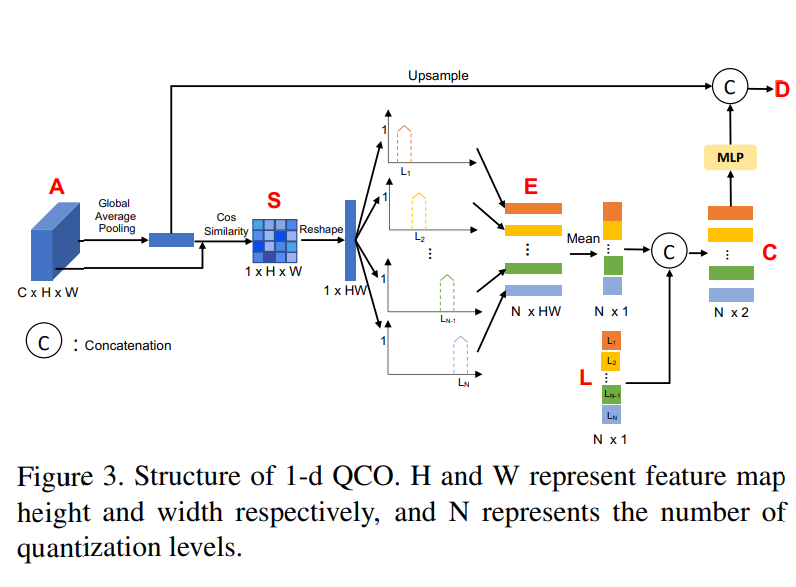
2.1 QCO(Quantization and Counting Operator)
- 크게
quntize와count두가지 연산을 수행하고1-d QCO와2-d QCO로 구분된다.
1) quantize inpute feature into multiple layer
2) count the number of features2.1.1 1-d QCO
Quanitzation
1)
input map에Global Average Pooling을 한 결과를 다시input map과Cosine similarity를 구해준다
2) 임의의
N개의 level로 나누어 준후quantization encoding vector를 얻는다.
- 이때 얻어지는 는 의
quantization level을 나타낸다argmax나one-hot encoding방법보다smoother way를 사용함으로써gradient vanishing문제를 피할 수 있다고 한다.
Counting
- 벡터 과 의
channel-wise mean을Concat한다.Average Feature Encoding
- 위의 과정을 통해 얻은 와 앞서
global average pooling을 통해 얻었던 를concat하여output을 얻는다2.1.2 2-d QCO
2-d QCO에서는1-d와 유사하지만 인접pixel간 관계를 통해 공간정보에 주목한다.
2.2 TEM
enhance texture details1-d QCO를 통해 얻은 값을q,k,v로 나누어 학습한다.
2.3 PTFEM
exploit texutre-related informationmulti-scale feature사용을 위해 다양한 크기의2-d QCO를 사용하고 논문에서는[1, 2, 3, 6]크기의 scale을 사용하여 이미지를 축소하였다.
2.4 Loss
- 원활한 학습을 위해
auxilary layer를 사용하였다.auxiliary output에는cross entropy를,main ouput에는 OHEM(online hard examples mining)을 사용하였다고 한다(focal loss와 유사한 목적인듯?)
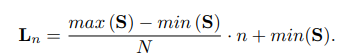
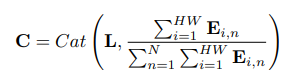
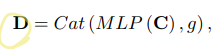
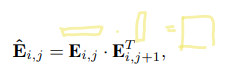


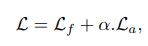
3. Result
TEM모듈 적용 전, 후를 비교했을 때 더 뚜렷한texture detail에 대해 얻을 수 있었다고 한다.
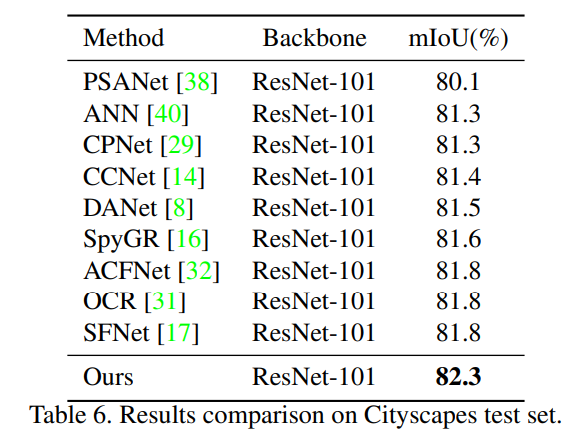
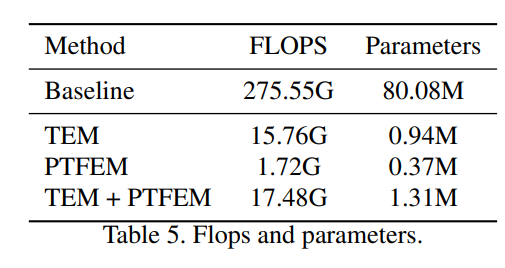
PASCAL,ADE20K,Cityscapes등의 데이터셋에서 기존SOTA모델 보다 좋은 성능을 보였다고한다.(ResNet-101기준)FLOPS
github에 올라와있는 코드를backbone없이 사용했을 때에도 다른 모델 보다 상당히 무거워졌다.--> 확인해볼 필요가 있는듯
DeepLapV3와의 비교시 조금더detail한 부분을 잡는 것을 확인할 수 있다.



인공지능 꿈나무