[Review] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (ViT)
0
PaperReview
목록 보기
8/9


1. Introduction
ViT이전에computer vision에서attention구조는 실용적으로 좋은 성능을 내지 못했음Transformer구조에 영감을받아
1)image를patch로 쪼개고
2)patch들의sequence를 모델의 input으로 사용하는 구조
를 고안했다고함.- 여기서
image patch들은NLP에서token과 같은 역할을 함.ImageNet과 같은mid-sized데이터셋은ResNet계열에 비해 약간 낮은 성능을 보였다고함.- 하지만
ImageNet-21k나JFT-300M같은large-scale의 데이터셋에서는 SOTA모델을 뛰어넘는 성능을 보여주었다고함.
Inductive Bias
ViT에서 데이터셋 일정 크기 이상이어야 기존CNN계열의 모델보다 성능이 좋았는데 이는CNN과Transformer계열의 모델이 가진inductive bias의 차이 때문이라고 한다.CNN모델들은 이미translation equivariance와locality라는inductive bias를 갖는sliding window구조로 되어있다.
translation equivariance: 사물의 위치가 바뀌어도 인지할 수 있음 (참고블로그)sliding window구조가 갖는inductive bias덕분에CNN계열의 모델은 데이터가 적을 때에도 좋은 성능을 보여준다.- 하지만 이미
bias를 갖는 구조이기 때문에 많은 데이터가 주어졌을 때에는 오히려inductive bias가 작은Transformer보다 낮은 성능을 보여준다.1) CNN
localitytwo-dimensional neighborhood structuretranslation equivariance2) ViT
MLP layer에서만locality와translation equivariance를 갖는다고 한다.Position embedding도2D가 아닌1D를 사용하기 때문에ViT는 공간정보에 대한inductive bias가 낮다고 볼 수 있다.
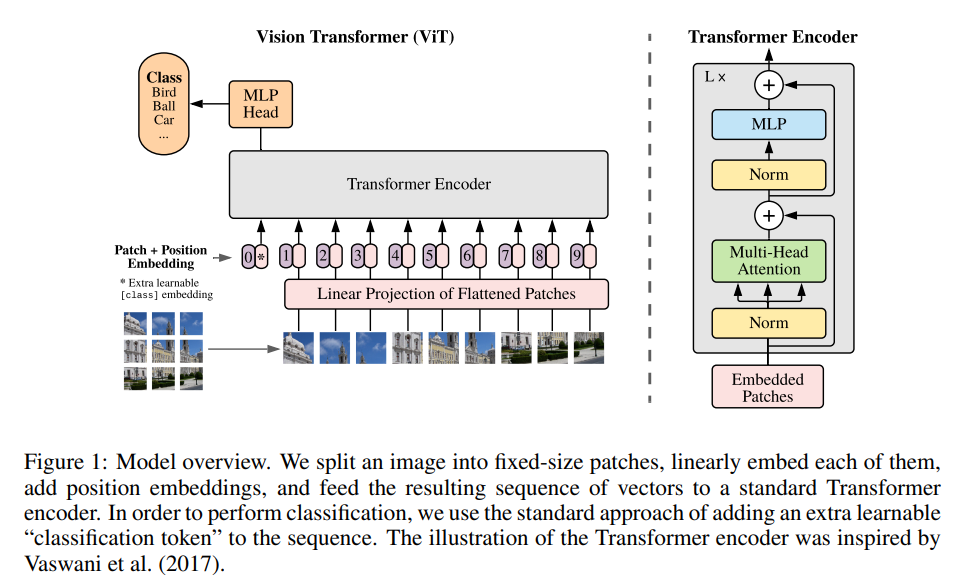
2. Model
ViT의 구조는Transformer의 구조와 거의 유사하다.- Transformer구조 참고
1) Patch
- 크기의 이미지를 크기를 가진 개의
patch embedding으로 바꾸어 사용한다. ()- 여기서 는 패치의 크기를 의미한다.
2) Classification
classification을 위해patch embedding맨 앞에class토큰을 추가로 사용한다.classification head는pre-train시에는하나의 hidden layer를 가진MLP에서 계산되고fine-tuning시에는하나의 linear layer에서 계산된다.3) Position embedding
Transformer와 마찬가지로 위치정보를 나타내기 위해class토큰과patch embedding에1D position embedding을 더해준다.2D position embedding과 비교했을 때 성능향상이 없어1D Position embedding을 사용하였다고 한다.4) Equation
ViT의 구조를 수식으로 나타내면 다음과 같다
- :
- :
- :
- :
- [ concatenated with ]
- 위의 식에서 는 차원의
Linear Projection을 위한 용도로 사용된다Patch의Linear Projection을 통해 를 구한 이후부터는 기존의Transformer와 동일하다5) Hybrid Architecture
- 원본 이미지에서
patch를 만들지 않고 기존의CNN모델의feature map을patch로 나누어 모델을 학습시키는 방법도 제시하였다.6) Fine-tuning and High Resolution
fine-tuning시resolution이 더 큰 image가 들어왔을 경우Patch의 크기는 고정되어 있기 때문에 sequence의 길이()만 길어지게 된다. 이 때, 의 길이가pre-trained position embedding의 길이와 맞지 않게 되는데, 이 경우에는2D interpolation을 통해 해결한다고 한다.
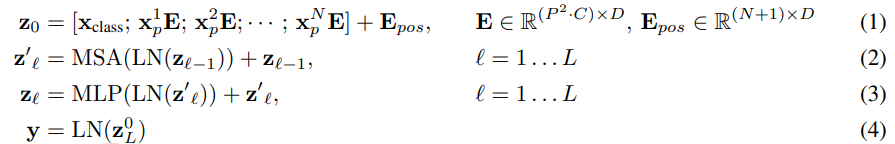
3. Experiments
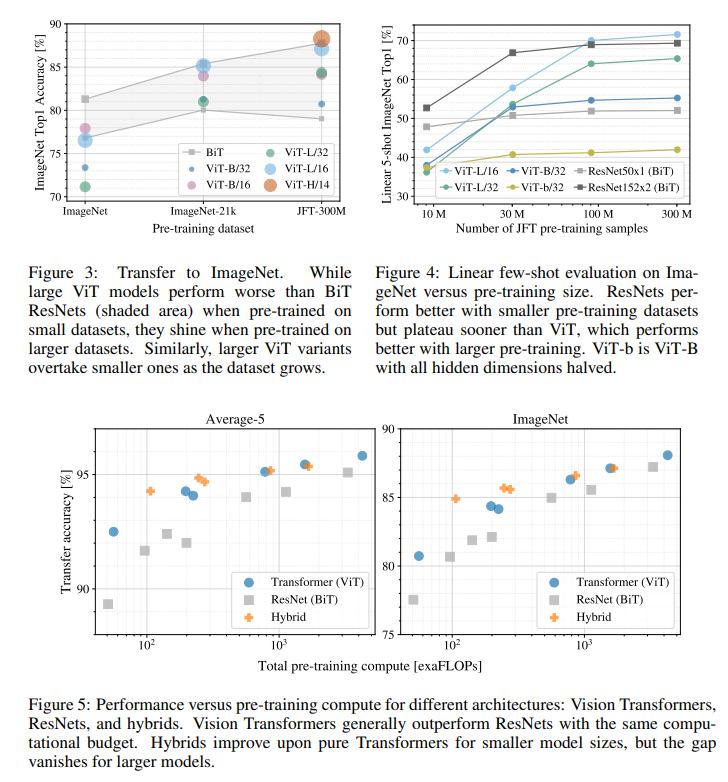
figure 3, 4-ViT는 다른 모델과 비교했을 때, 학습 데이터가 크고, 많아야 좋은 성능을 얻을 수 있다.fugure 5동일FLOP(연산량)에서ViT모델이BiT모델보다 좋은 성능을 보였다.
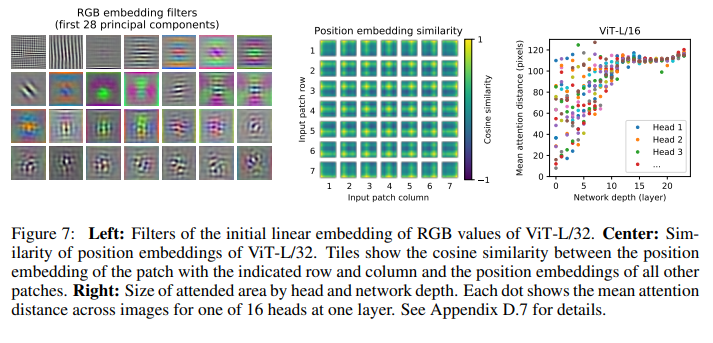
1) Position embedding
- 가운데 이미지는
position embedding간의cosine similarity를 보여준다.- 위치정보를 주지 않았음에도 불구하고, 데이터를 학습하며 가까운 위치에 있는
embedding일 수록similarity가 높아지는 경향을 보이는 것을 확인할 수 있다.2) Receptive field?
- 오른쪽의 이미지는
layer깊이에 따른attention weight의 평균거리를 나타낸다.- 네트워크의 깊이가 얕은
head에서는 작은attention distance를 가지고, 원본 이미지의 좁은 영역만을 보는 경향이 있고,- 네트워크의 깊이가 깊은
head에서는 대부분 큰attention distance를 가지고 원본 이미지의 넓은 영역에 주의(attention)를 기울이는 경향이 있다고 한다.- 이는
CNN의Recetptive field와 유사한 경향을 보인다.
3) Attention
ViT의attention을 시각화한 결과classification을 위한semantic영역에 주의를 기울인다는 것을 확인할 수 있었다고 한다.


인공지능 꿈나무