Going deeper with convolutions, 2017
Introduction
-
AlexNet보다 12배 적은 파라미터로 더 좋은 성능을 얻어냈다
-
Network in network 논문으로부터 아이디어를 얻은 "Inception" 모듈을 사용하여 network를 더욱 깊게 만들 수 이었다.
1X1 convolution layer
- 현재 CNN pipeline에서 쉽게 사용할 수 있음
- computational bottelneck을 제거하기 위해 dimension reduction module에서 주로 사용됨(network size limit)
Big size model
많은 파라미터를 가지기 때문에 여러 문제점을 갖는다.
- overfitting되는 경향
- 심한 bottleneck
- 많은 computational resource 사용
이에 대한 해결 책으로 논문에서는 convolution안에 sparsley connected architecture를 제시하였다
그 결과로
then the optimal network
topology can be constructed layer by layer by analyzing the correlation statistics of the activations
of the last layer and clustering neurons with highly correlated outputs.(3p)
Inception
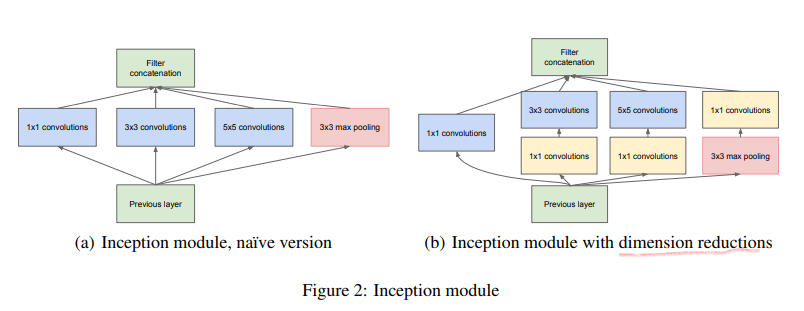
- Inception 구조의 주요 아이디어는 어떻게 최적의 local sparse structure가 추정되고 dense components에 의해 다루어 질 수 있는지 알아내는 것을 기반으로 한다
- 저수준의 layer(input에 가까운)에서 correlated unit은 local region에 집중하는데 이것은 많은 cluster들이 single region에 집중한다는 것을 의미한다. 그런 cluster들이 다음 layer에서 1x1 convolution으로 대체될 수 있다고 보았다.
- 병렬적인 pooling을 사용하여 추가적으로 이로운 효과를 얻었다고 한다.
- naive version의 상위 layer에서는 매우 많은 연산량이 필요하기 때문에 1x1 convolution을 추가하여 차원을 감소시키는 용도로 사용하였다
-학습하는 동안 메모리 효율의 이유로 기존 convolution 층을 먼저 쌓고 그 위에 inception module을 쌓는 것이 좋다고 하였다. - 이 구조의 장점으로 다양한 scale로 처리되어 다음 layer에서 여러 feature들을 추출할 수 있다는 것을 들었다.
- Inception 구조를 사용하지 않은 모델모다 2-3배 빠른 성능을 보였다.
GoogLeNet
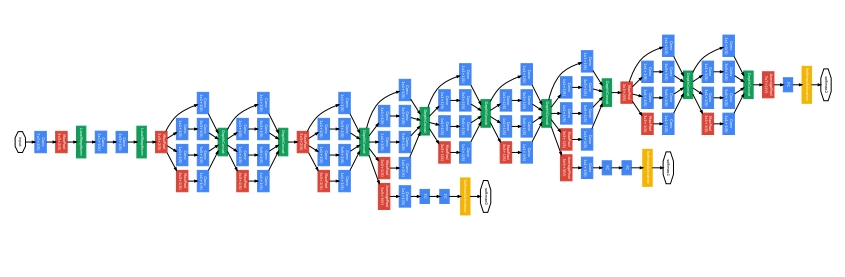
- Yann LeCuns의 LeNet 5 모형에 대한 경의를 표현하는 의미에서 비슷한 이름으로 선정하였다.
- 상대적으로 매우 깊은 망이기 때문에 gradient를 모든 layer에 걸쳐 효과적으로 전달하기 위해 중간 보조 출력층을 만들어 사용하였다.
- 저자들은 network의 중간층도 매우 discriminative한 것을 확인하였고 이에 따라 중간 출력층을 생성하여 최종 loss에 더하여 손실을 계산하였다. 이는 gradient signal을 증가시키고 추가적인 regularization을 부여하였다고 한다.
- 이 부분은 학습에서만 사용되었고, 추론에서는 사용되지 않는다.

인공지능 꿈나무