
배운걸 코딩해보죠
실습시간입니당! 가설 함수Hypothesis Function의 비용 함수Cost Function을 TensorFlow로 직접 구현해볼겁니다.
우선 비용 함수를 짜보죠!
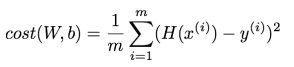
가설 함수Hypothesis Function와 데이터y를 빼고 이를 제곱한 값의 평균MSE이라고 했었습니당!
import tensorflow as tf
x_data = [1, 2, 3, 4, 5]
y_data = [1, 2, 3, 4, 5]
# 이거슨 임의(Random) 변수
W = tf.Variable(2.9)
b = tf.Variable(0.5)
# 가설 함수 W * x + b
hypothesis = W * x_data + b
# cost = MSE
cost = tf.reduce_mean(tf.square(hypothesis - y_data))문법 먼저 간단히 살펴보자면, TensorFlow에 활용할 변수를 선언하기 위해 tf.Variable함수를 사용했습니당. 여기서 W랑 b는 변화를 통해 머신러닝의 목표를 달성하기 때문에 TensorFlow가 관리할 수 있게 변수로 선언을 했습니당
그리고 평균제곱오차MSE 수식화를 위해 tf.reduce_mean과 tf.square를 사용했습니당. 각각 수치들의 평균 값, 수치의 제곱을 의미합니당.
v = [1., 2., 3., 4.]
print(tf.reduce_mean(v)) # 2.5
print(tf.square(v)) # [1. 4. 9. 16.]W랑 b를 점점 좁혀갑니다
저는 수학을 열심히 해서 x_data와 y_data만 봐도 최적의 W와 b는 1과 0임을 알 수 있었어용. 이제 이걸 컴퓨터가 찾을 수 있게 만들겁니당.
그 수단 중 하나가 경사하강법Gradient Descent Method이라고 합니당. TensorFlow엔 이 메서드가 따로 준비되어 있습니당.
learning_rate = 0.01
print(W, b) # 2.9, 0.5
with tf.GradientTape() as tape:
hypothesis = W * x_data + b
cost = tf.reduce_mean(tf.square(hypothesis - y_data))
W_grad, b_grad = tape.gradient(cost, [W, b])
W.assign_sub(learning_rate * W_grad)
b.assign_sub(learning_rate * b_grad)
print(W, b) # 2.4520001, 0.376로직을 보시면 가설 함수Hypothesis Function와 비용 함수Cost Function를 선언하고, gradient라는 메서드가 비용 함수와 W랑 b를 매개변수로 받아와 _grad 관련 변수 2개를 반환하고 있습니당.
이것이 바로 경사하강법Gradient Descent Method을 통해 W와 b의 변화량을 구한 것입니당. 그래서 마지막에 assign_sub 메서드를 통해 변화량 만큼 빼서 적절한 W와 b를 구한다고 보면 됩니당
경사하강법Gradient Descent Method 을 통한 수치 적용 전후를 비교해보면 W는 1에, b는 0에 가까워지는 것을 볼 수 있습니당.
여기서 learning_rate는 정답에 접근하기 위한 보폭이라고 보시면 됩니당. 적당한 값을 넣어줘야 소프트웨어가 잘 돌아갑니당.
아직이에요. 될 때까지 해야죠
자, 이걸 한번만 하면 안되고 여러번 해야 우리가 원하는 결과에 근접할 수 있습니당.
learning_rate = 0.01
print("{:6}|{:10}|{:10}|{:10}".format( "Epochs", "W", "b", "cost"))
for i in range(100 + 1):
with tf.GradientTape() as tape:
hypothesis = W * x_data + b
cost = tf.reduce_mean(tf.square(hypothesis - y_data))
W_grad, b_grad = tape.gradient(cost, [W, b])
W.assign_sub(learning_rate * W_grad)
b.assign_sub(learning_rate * b_grad)
if i % 10 == 0:
print("{:5}|{:10.4f}|{:10.4f}|{:10.6f}".format( i, W.numpy(), b.numpy(), cost.numpy()))돌려보면, 아래와 같은 결과를 얻을 수 있어용.
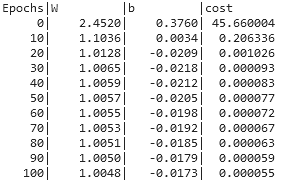
횟수Epoch를 거듭할 수록 W는 1에, b는 0에 가까워지는 것을 알 수 있습니당.
그리구 비용Cost도 눈에 띄게 줍니당!

그림으로 보자면, 처음엔 저언혀~ 점데이터에 적합한 직선이 아니었다가, 회차Epoch를 거듭할 수록 적합해지는 것을 확인할 수 있습니당.
선형 회귀Linear Regression는 이렇게 반복적으로 학습을 수행해서 적합한 가설 함수Hypothesis Function의 W와 b를 구하는 것입니당!
후기
블로그를 정리하면서 공부하는 거라 확실히, 유튜브 보고 바로 실습하는거보다 속도가 더디네요 ㅠ 유튜브 보고 실습해서 GitHub에 커밋하는건 빨랐는뎁...
그래도 확실히 블로그로 정리해 가면서 쓰다보니까 머릿속에 더 기억에 남는 것 같습니당 ㅎㅎ 예전엔 뭔지는 알지만 정리해서 설명할 수 없었지만, 지금은 물어보면 어느정도 정리해서 이야기할 수 있을 것 같아용!
블로그로 정리하는 걸 병행하는 걸 시작해서 아직 속도는 더디지만 꾸준히 하다보면 속도, 학습력 둘 다 잡을 수 있을 거라는 희망이 생깁니다! 헤헤 더 열심히 글 써야겠어용!
