딥레이크란 무엇인가요?
Deep Lake는 원시 데이터에 이미지, 비디오, 오디오 및 기타 비정형 데이터가 포함된 딥러닝 사용 사례에 특화된 데이터 레이크(데이터베이스) 입니다. 원시 데이터는 딥 러닝 기본 저장 형식으로 구체화되고 네트워크를 통해 모델 학습으로 스트리밍됩니다.

딥레이크의 중요성
-
LLM 애플리케이션을 위한 데이터 및 벡터 저장:
LLM을 사용하여 애플리케이션을 구축할 때 많은 데이터와 벡터를 처리해야 합니다. 딥레이크는 이런 정보를 정말 잘 처리하는 특별한 저장공간 입니다. -
훈련 모델을 위한 데이터 세트 관리:
AI 모델, 특히 딥 러닝과 관련된 모델을 훈련할 때 데이터 세트를 효과적으로 관리해야 하는 데 Deep lake는 그렇게 할 수 있도록 도와줄 수 있습니다. -
엔터프라이즈급 LLM 제품 만들기:
LLM을 사용하여 대규모 프로젝트를 작업하는 경우 Deep Lake는 임베딩, 오디오, 텍스트, 비디오, 이미지, PDF, 주석 등 모든 종류의 데이터에 대한 저장소를 제공합니다. 또한 데이터에서 벡터 검색, 모델을 훈련하는 동안 데이터 스트리밍(AI 학습과 유사), 데이터의 다양한 버전 추적과 같은 작업도 수행합니다. -
모든 크기의 데이터, 서버리스 및 클라우드 친화적으로 작동:
데이터가 아무리 크더라도 Deep Lake는 이를 처리할 수 있습니다. 또한 serverless이므로 서버 관리에 대해 걱정할 필요가 없고 모든 데이터를 자체 클라우드에 저장할 수 있습니다.
딥레이크의 특징
1. 다중 모드 센서 입력:
DeepLake는 다중 모드로 설명됩니다. 이는 다양한 형식의 정보를 처리할 수 있는 기능이 있음을 의미하며 일반적으로 텍스트, 이미지 및 오디오와 같은 다른 형식, 다양한 유형의 데이터를 나타냅니다.
예를 들어 DeepLake는 텍스트 및 시각적 입력을 기반으로 콘텐츠를 분석하고 생성할 수 있습니다. 이러한 다양성을 통해 다양한 소스에서 얻은 통찰력을 결합하여 보다 전체적인 방식으로 정보를 이해하고 대응할 수 있습니다.

2. Serverless:
다중 클라우드 지원(S3, GCP, Azure): Deep Lake는 S3, GCP, Azure와 같은 다양한 클라우드에서 작업할 수 있습니다. 이는 마치 여러 클라우드 언어에 능통하므로 데이터가 어디에 저장되어 있든 Deep Lake가 이를 처리할 수 있습니다.
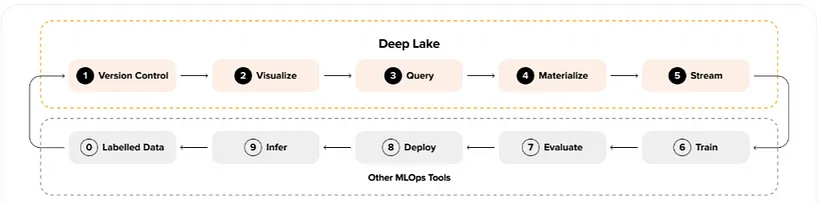
여기서 MLOP는 이러한 클라우드 환경에서 수행될 수 있습니다.
3. All-in-One:
a. Query: Tensor 쿼리 언어를 사용한 query
1,000개의 이미지와 레이블로 구성된 데이터 세트를 만들고, 날씨 조건과 이미지 상의 개체를 기준으로 필터링한 다음, 예측결과의 오류를 기준으로 정렬하는 작업을 한다고 가정하면 이는 복잡한 작업이며 일반적으로 데이터 사이언티스트가 이를 수행하는 데 많은 시간과 엄청난 양의 코드가 필요합니다.
그러나 Deep Lake의 Tensor Query Language는 단 하나의 SQL 명령으로 다차원 배열 및 텐서와 관련된 고급 쿼리를 수행할 수 있습니다.

SELECT 100 500 100 500 100 100 0 0
WHERE contains (categories,'bicycle') and weather == 'raining'
ORDER BY desc
LIMIT 1000위는 이미지 데이터 세트에서 수행할 수 있는 TQL(Tensor Query Language)의 예시입니다.
b. Lazy NumPy와 유사한 인덱싱을 사용한 기본 압축
Deep Lake는 데이터를 압축하여 공간을 덜 차지하면서도 필요할 때 쉽게 액세스할 수 있습니다. 이것은 Lazy NumPy와 유사한 인덱싱을 사용한 기본 압축입니다. 데이터를 찾기 어렵게 만들지 않으면서 공간을 절약하는 매우 조직화된 파일링 시스템을 갖는 것과 같습니다.
c. 데이터 세트 구체화
데이터셋을 구축하면 모델 학습에 착수할 준비가 모두 완료된 것입니다. 그러나 실제 학습을 하기 위해 많은 파일을 처리하고 데이터 세트를 컴퓨터에 복사하는 것은 많은 시간이 소요될 수 있어, 때로는 GPU가 데이터를 복사될 때까지 기다리는 경우가 발생합니다.
'materialization of the dataset'는 딥러닝 모델에서 사용할 수 있는 형태로 데이터 셋을 변환하는 것입니다 를 딥러닝 모델에서 사용할 수 있는 것으로 바꾸는 것과 같습니다.(turning your virtual view of the dataset into something that’s ready to be used by your deep learning model - 원문)
Deep Lake가 이 프로세스를 매우 효율적으로 만듭니다. 데이터가 스토리지에서 로컬 시스템으로 복사되는 동안 기다리는 대신 Deep Lake를 사용하면 데이터를 GPU로 직접 스트리밍할 수 있습니다 . 이는 데이터를 위한 빠르고 직접적인 고속도로와 같아서, 시간을 낭비하지 않고 강력한 GPU가 항상 의미 있는 작업을 수행하도록 보장합니다.
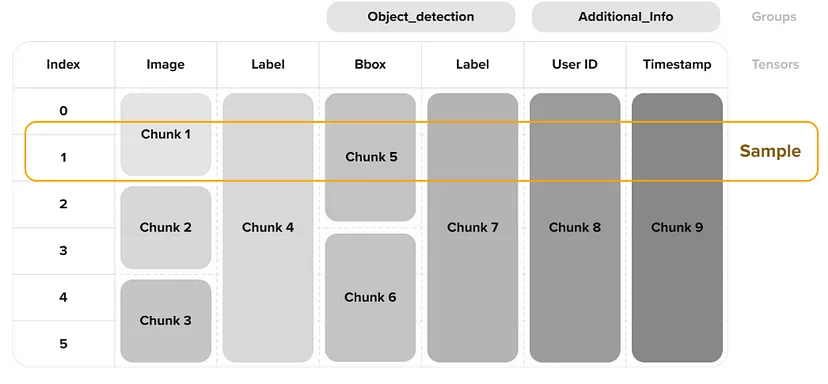
d. Dataset Version Control
Deep Lake는 데이터 셋의 버전관리를 통해 데이터를 효율적으로 관리할 수 있습니다. 원하는 경우 이전 버전으로 돌아갈 수 있습니다.
Git 버전 관리와 마찬가지로 아래 예에서 볼 수 있듯이 분기가 있습니다.

e. Dataloaders for Popular Deep Learning Frameworks
Nvidia GPU와 같은 딥 러닝 하드웨어는 속도에 최적화되어 있어 모델이 매우 빠른 속도로 학습하고 예측할 수 있으나 문제는 연산이 아닌 모델에 데이터를 전달하는 과정에서 속도가 느려지는 문제가 있습니다.
Python은 많은 데이터를 처리하고 문제 없이 모델에 전달되도록 하는 데에는 몇 가지 한계가 있습니다. Python의 다중 처리 및 다중 스레딩과 관련된 문제가 있습니다.
Deep lake는 PyTorch, Tensorflow와 같은 프레임워크와 원활하게 작동하도록 설계되었다는 것입니다. Deep Lake에는 데이터 로더가 있어 데이터를 효율적인 전달할 수 있습니다. 모델이 해당 GPU에서 학습하고 훈련하는 동안 데이터 로더는 필요한 정보가 스토리지에서 GPU로 원활하게 흐르도록 합니다.

f. Integrations with Powerful Tools
Deep Lake는 다른 도구와 원활하게 작동할 수 있습니다.
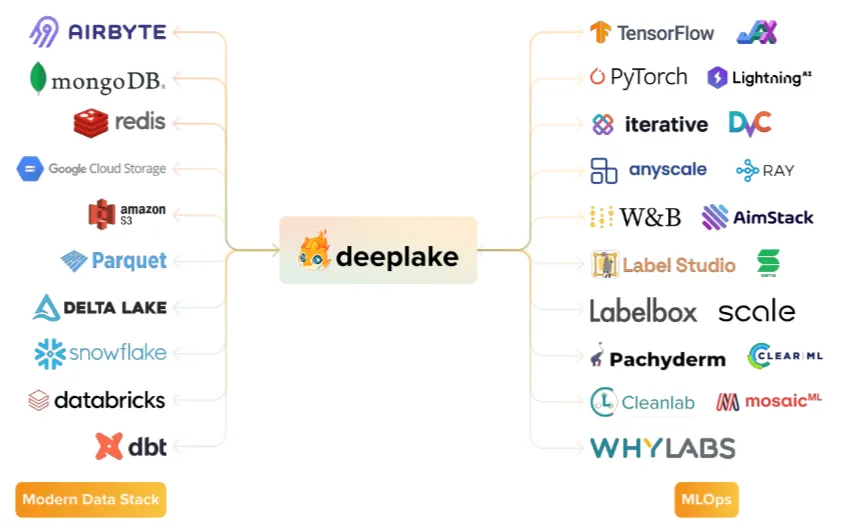
g. 빠른 엑세스
Deep Lake를 사용하면 프로젝트에 필요한 데이터를 매우 빠르고 쉽게 얻을 수 있습니다.
h. Deep Lake 앱의 즉각적인 시각화 지원
Deep Lake는 단지 뒤에서 데이터를 처리하는 것만이 아닙니다. 또한 데이터를 즉시 보고 이해할 수 있는 앱도 있습니다. 이는 데이터 세트의 세계를 들여다보는 창을 갖는 것과 같습니다.
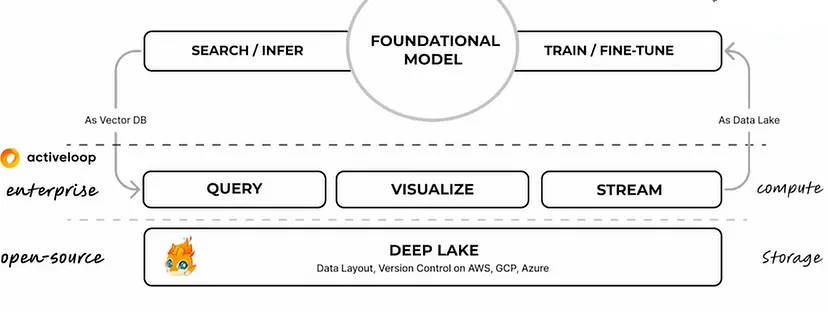
Example of building chatbot with and without Data lake
Without deep lake:

With Deep Lake:
출처 - https://medium.com/@aneesha161994/what-is-deep-lake-e5798d9122a8
