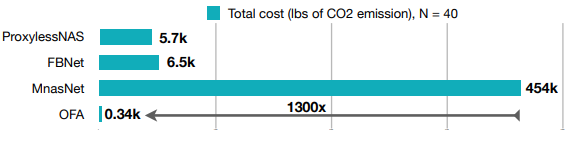Once-For-All : Train one network and specialize it for efficient deployment
Abstract
다양한 device의 제약조건 하에서 효율적으로 inference 하는 것은 쉽지 않은 문제이다. 전통적인 방법으로 네트워크를 디자인하는 것도 엄청난 연산량이 부담된다.
본 연구에서는 a once-for-all (OFA) 네트워크 학습법을 제안하며, OFA는 training과 search를 분리함으로써 다양한 환경을 지원한다. OFA 네트워크에서는 추가적인 학습 없이 특화 sub-network를 빠르게 선택할 수 있다.
효율적으로 OFA 네트워크를 학습하기 위해, Progressive Shrinking (PS) Algorithm 도 제안한다. PS는 보다 일반화된 pruning 방법으로, model size를 일반 pruning 방법보다 다양한 차원에 걸쳐 줄일 수 있다(depth, width, kernel size, resolution). PS를 통해 1020개 이상의 sub-networks를 얻을 수 있으며, 이들 중 다양한 하드웨어 플랫폼에 맞는, latency / accuracy 손실이 거의 없는 네트워크를 별도 학습 없이 찾을 수 있다.
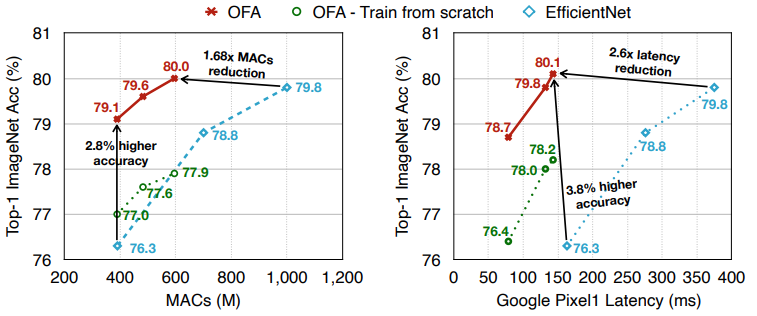
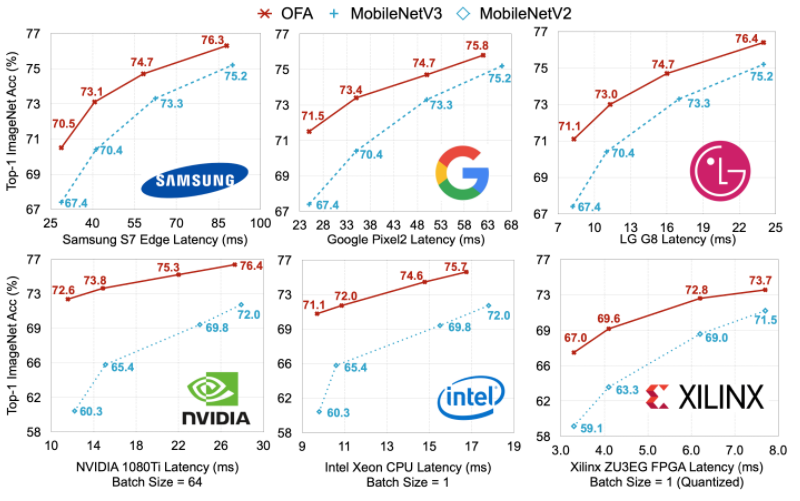
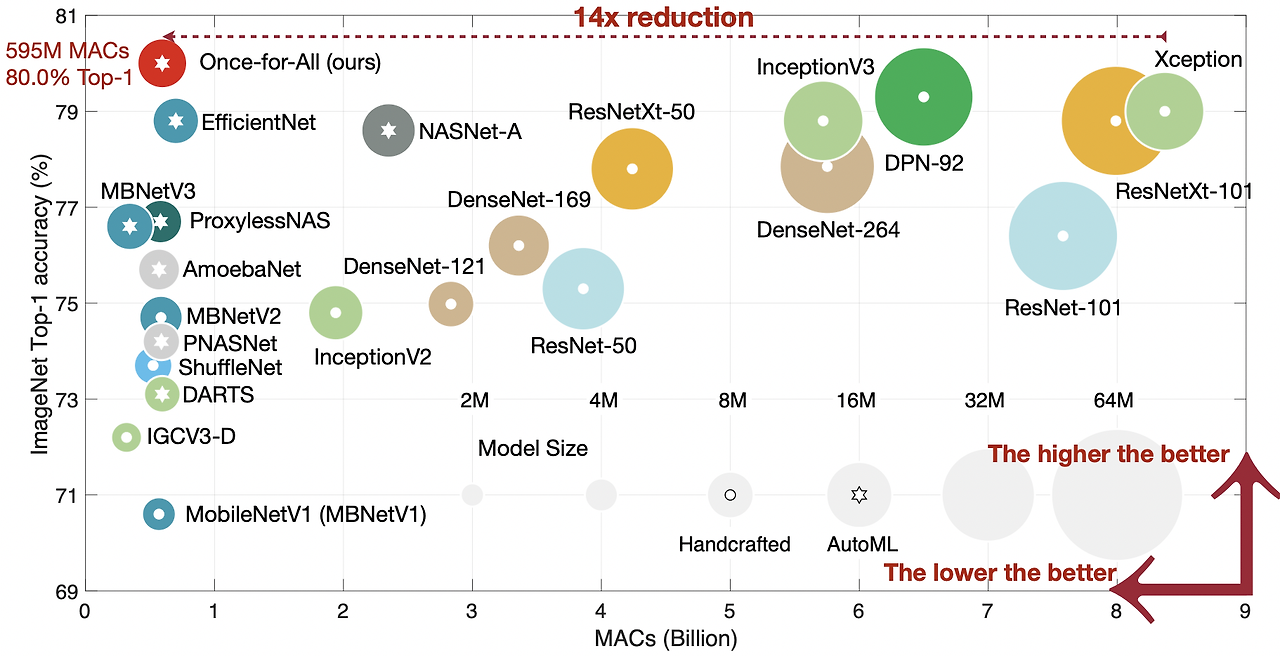
다양한 edge devices에서 OFA는 GPU hours를 크게 줄이면서도 SOTA NAS 방법론을 여러 방면에서 지속적으로 뛰어넘는 모습을 보여준다. 특히 OFA는 ImageNet top-1 accuracy 80.0%를 모바일 세팅에서 달성하였다.
Introduction
DNN은 다양한 ML 분야에서 SOTA accuracy를 달성하였으나 model size는 폭발적으로 증가하여, 효율적으로 모델을 다양한 하드웨어 플랫폼에 이식하는 것이 어렵다. 이는 Hardware 사양에 따라 최적 모형이 달라지기 때문이며, 심지어 device가 같더라도 배터리 상태, workloads 등에 따라 성능 차이가 크게 발생할 수 있다.
이에 대응하기 위해 모바일을 위한 compact models 또는 기존 모델을 압축하는 방법들이 제안되나 모든 발생 가능한 상황에 대해 맞춤형 DNN을 준비하는 것은 다양한 모든 케이스에 대해 모형을 처음부터 설계하고 학습해야 하므로 너무 많은 연산이 필요한 어려움이 있다.
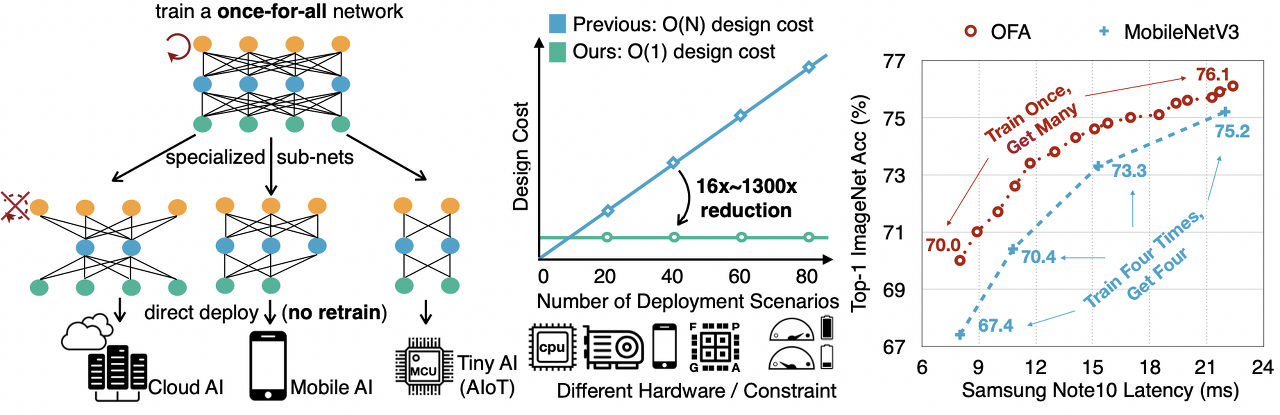
본 논문에서는 이러한 문제에 대한 해결방법을 제시한다
- 한 번만 학습을 하고, 다양한 환경에 맞춰 sub-network를 선택한다.
- 유연하게 모형의 depths, widths, kernel sizes, and resolutions를 재학습 없이 조정할 수 있으며, 이는 학습과 모형 선택 과정을 분리했기에 가능하다
학습 과정에서는 모든 sub-networks들의 성능이 향상되는 것을 목표로 한다. 모델 선택 과정에서는 sub-networks의 subset을 샘플링 한 뒤 accuracy 예측기와 latency 예측기를 학습하며, 주어진 hardware 및 제약조건에 따라 예측기가 architecture search를 수행한다.
그러나 OFA 학습은 모든 sub-networks의 성능까지 고려해야 하므로 쉽지 않다. 모든 sub-networks의 수를 세는 것은 연산 한계로 불가능하며, 소수의 sub-networks만을 샘플링하는 것은 성능 저하를 일으키다.
효율적인 학습을 위해 본 논문에서 PS 방법론을 제안한다. OFA를 처음부터 학습하지 않고, depth, width, kernel size가 최대값인 가장 큰 네트워크를 먼저 학습한 다음 점진적으로 sub-networks를 fine-tune하는 방식이다. 이를 통해 sub-networks에 더 좋은 학습 시작점을 제공하고, 가장 큰 네트워크의 능력을 작은 네트워크들에 녹여낼 수 있다.
Related Works
Efficient Deep Learning
기존에는 하드웨어 효율을 제고하기 위한 제안들이 있었다. SqueezeNet, MobileNets, ShuffleNetes 등이 있었다. 이와는 상반되게, 네트워크 compression에 촛점을 맞춘 제안들도 있었으며, 이는 network pruning 개념을 포함한다.
Neural Architecture Search (NAS)
NAS는 architecture design 과정을 자동화하려는 시도이다. 초기의 NAS는 하드웨어 효율성을 전혀 고려하지 않아, 제안됐던 NASNet, AmoebaNet 등은 inference 효율이 매우 떨어진다. 최근의 하드웨어를 고려한 NAS 방법들은 하드웨어의 feedback을 직접적으로 architecture search 과정에 포함시킨다. 그러한 결과 inference efficiency를 향상시킬 수 있었으나, 새로운 플랫폼에 대해서는 architecture search 과정을 다시 반복해야 한다. 이는 수 많은 시나리오가 존재하는 search space에서 전혀 scalable한 방법이 아니다.
Dynamic Neural Networks
네트워크의 효율성 향상을 위해, 이미지 처리 일부 part를 동적으로 제거하는 방법들이 제안되기도 한다
- controller 또는 gating modules을 만들어 layers를 동적으로 제거
- early-exit branches
- adaptively prune channels based on the input feature map
- stochastic downsampling adaptively
- Slimmable Nets은 기존 네트워크에 다수의 width multipliers 적용이 가능하도록 학습
이러한 방법들은 runtime 상황에서 다양한 효율성 제약을 만족시킬 수 있지만, 여전히 이전에 디자인된 네트워크가 필요하다. 이전에 디자인된 네트워크가 모든 시나리오에서 최적이라고 볼 수 없다는 문제가 있다.
Methods
Problem Formalization
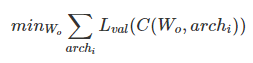

Architecture Space
OFA 네트워크는 한 개의 모델이지만, CNN의 중요한 기준들(depth, width, kernel size, and resolution)을 다양하게 변경 가능한 sub-networks를 함께 제공한다. 일반적인 CNN 이론에 따라 본 연구에서도 점점 feature map size는 작아지며, channel numbers는 증가하는 구조를 채택한다.
- input image size: 128 ~ 224 w. stride 4 (25 different input resolutions)
- depth: {2,3,4}
- width: {3,4,6}
- kernel size: {3,5,7}
- 5 units
모든 sub-networks들이 weights를 공유하므로, OFA 네트워크는 7.7M parameters만 저장한다.
Training the Once-For-All Network
Naive Approach
OFA network 학습은 multi-objective problem. 각각의 sub-network를 학습하는 것이 하나의 problem. 이런 관점에서 가장 기초적인 학습 방법은 모든 목표에 대한 gradient를 구해서 처음부터 학습하는 것. 이를 위해서는 모든 sub-networks의 경우를 미리 계산해야 함. 그러나 이 방법은 sub-networks의 수에 따라 선형적으로 연산량이 증가하게 됨. 따라서 제한된 시나리오의 경우에만 이렇게 학습할 수 있음.
또 다른 기본적인 접근법은 몇 개의 sub-networks를 매 step 마다 샘플링하는 것. 그러나 수 많은 sub-networks가 weights를 공유하므로, 이러한 방법으로는 모든 sub-networks의 accuracy를 유지할 수 없었음
Progressive Shrinking
큰 sub-networks부터 작은 sub-networks 순서대로 점진적으로 학습하는 방법을 제안. 아래의 Figure 3, Figure 4가 Progressive Shrinking (PS) 학습 예시를 나타낸 것

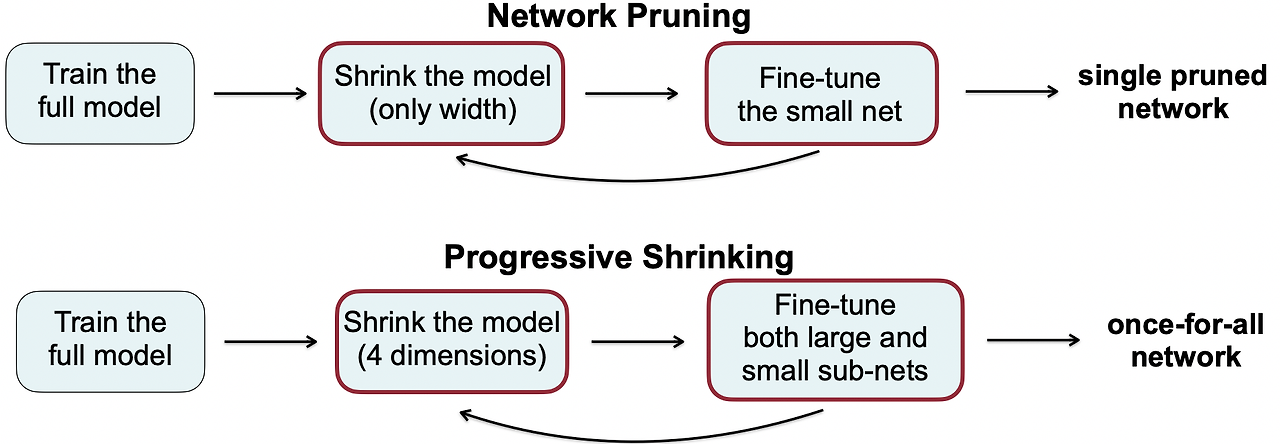
일단 가장 큰 신경망 네트워크를 최대 kernel size, depth, width로 학습한다. 그 다음, 점진적으로 sub-networks를 학습시키기 위해 sampling space를 점점 넓혀간다. 최대 네트워크를 학습한 뒤, kernel size를 각 layer에서 {3, 5, 7} 중 선택할 수 있도록 하지만 depth, width는 최대값으로 고정하고 그 다음 차례로 depth, width를 elastic하게 변경한다. resolution은 다양한 이미지 크기를 배치마다 샘플링 함으로써 전체 학습 내내 다양하게 학습한다(elastic). Knowledge distillation 기법도 가장 큰 네트워크의 결과를 활용해서 적용한다. soft label과 real label 두 개에 대한 loss terms 활용한다.

-
Elastic Kernel Size: {3,5,7}이 가능하며, {3,5}의 weights는 공유된다. 공유되는 weights는 다른 분포 또는 크기를 가져야 할 수 있다. 그래서 "kernel transformation matrices"를 고안하였다. kernel transformation matrices는 layer마다 다르다. 하지만 각각의 layer 안에서는 서로 공유한다. 따라서 layer마다는 25x25 + 9x9 = 706개의 parameters만 추가된다.
-
Elastic Depth: 최대 N layers가 있을 때, D layers만 사용하는 경우, 처음의 D layers의 결과만 사용한다.
-
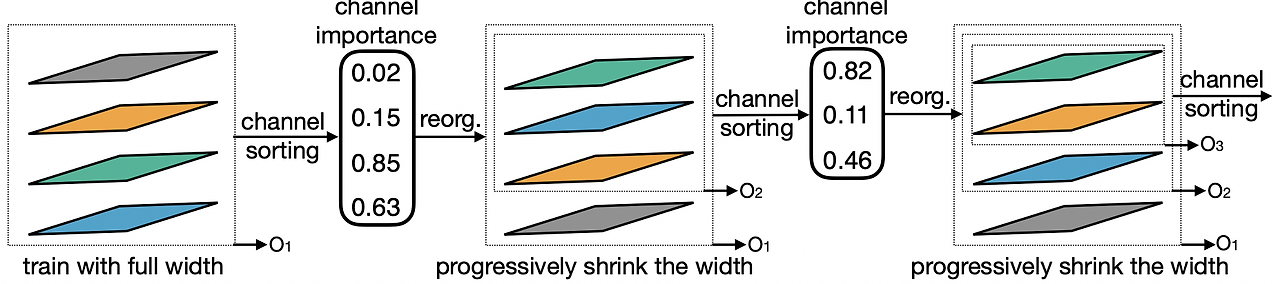
Elastic Width: Width는 채널의 수를 의미하며, 유연하게 channel expansion ratios를 적용한다. 먼저 full model을 학습하고, channel sorting 후 channel을 선택한다. channel importance는 L1 norm을 활용하며, L1 norm이 클 수록 더 중요하다 판단한다.
Specializaed Model Deployment with Once-For-All Network
OFA 네트워크를 학습한 뒤, 적절한 sub-network를 찾는 단계가 남아있다. 타겟 하드웨어의 efficiency constraints (latency, energy)를 만족시키면서도 accuracy가 가장 뛰어난 네트워크를 찾아야 한다. 이를 위해 "neural-network-twins"를 구성하여 주어진 신경망 구조에 따라 latency와 accuracy를 예측할 수 있게 하였다. 임의로 16K의 sub-networks를 샘플링하고, 10K validation images에 대한 accuracy를 측정. 이러한 [architecture, accuracy] 쌍은 accuracy predictor를 학습하는 데 사용한다. 또한 각각의 target hardware pltform에 대한 latency lookup table도 구성한다. 주어진 target hardware and latency 제약조건에 맞춰 evolutionary search를 통해 sub-network를 찾는다.
Experiments
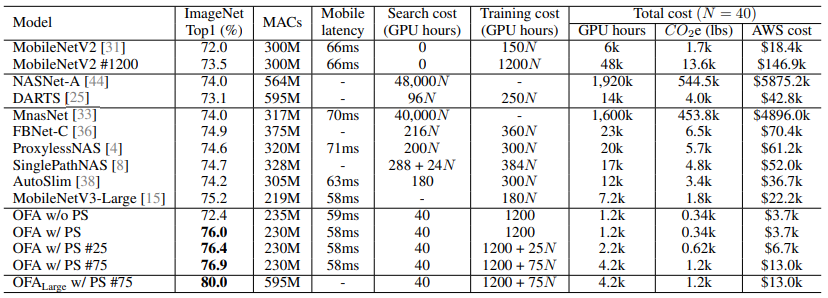
ImageNet으로 테스트 했으며, 다양한 hardware platforms를 사용하였다.
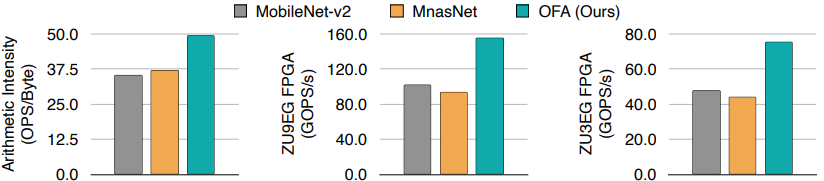
Samsung S7 Edge, Note8, Note10, Google Pixel1, Pixel2, LG G8, NVIDIA 1080Ti, V100 GPUs, Jetson TX2, Intel Xeon CPU, Xilinx ZU9EG, and ZU3EG FPGAs.
Training the Once-For-All Network on ImageNet
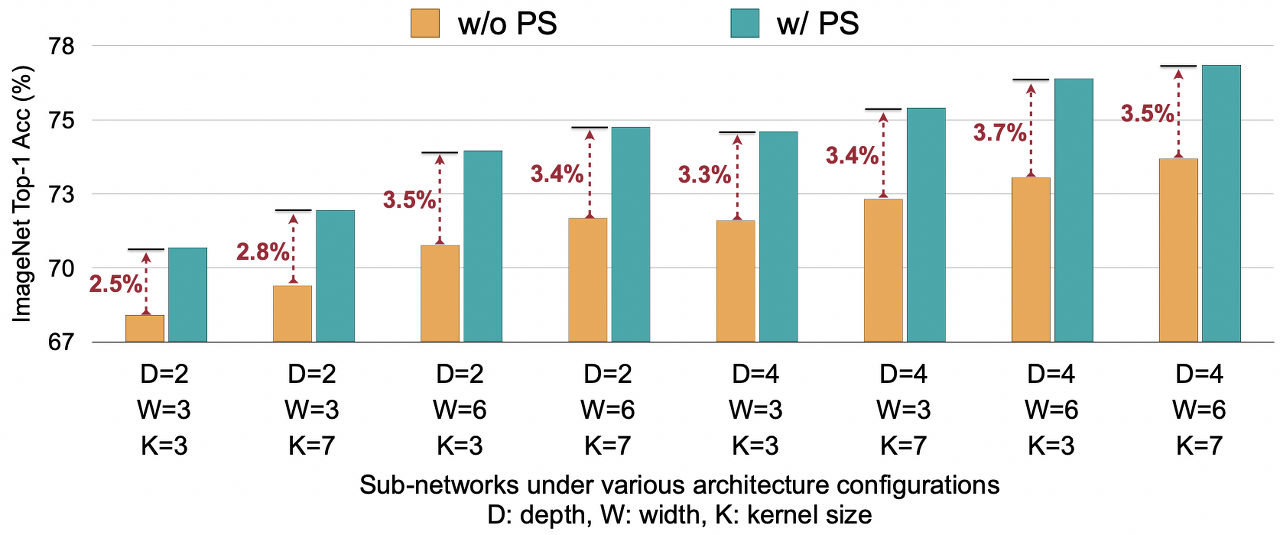
SPECIALIZED SUB-NETWORKS FOR DIFFERENT HARDWARE AND CONSTRAINTS