YOLO v4 논문 리뷰
이번 포스트는 yolo v4에 대한 리뷰를 하고자 한다. 사실 v3까지만 하더라고 이미 시간이 지났기도 하고 많은 분들이 리뷰도 해주셔서 어떻게든 따라갈 수 있었는데 v4는 갑자기 처음 보는 알고리즘 들과 기술들이 너무 많이 나와서 솔직히 힘들다 ㅠㅠ
그래도 몇몇 분들의 선구자적인 정신으로 리뷰 해 놓으신걸 참고하여 해보고자 한다(아래에 출처 남겨드립니다 진심으로 감사드립니다 [꾸벅])
논문제목
YOLOv4: Optimal Speed and Accuracy of Object Detection
목차
Abstract
기존의 CNN들은 batch-normalization, residual-connections과 같은 새로운 기법을 활용하여 성능을 향상시킴
여기서 batch-normalization은 간단하게 배치간의 편차를 표준화(normalization)하는 것으로 사실 이론적으로 더 파고들면 더 복잡하다(인공지능에서 수학이 필수인 이유, 특히 통계....).
딥러닝 핵심 요소 기술 중에 하나로 layer 수가 많아질수록 vanishing/exploding gradient 문제가 심각해지는데 활성함수로 sigmod나 hyper-tangent와 같은 비선형 포화함수를 사용하게 됨으로써 발생한다. 입력의 절대값이 작은 일부 구간을 제외하면 미분값이 0 근처로 가기 때문에 역전파를 통한 학습이 어려워지거나 느려지게 된다. 이 부분은 ReLU 함수로 문제가 완화하긴 했지만 근본적인 해결책은 아니다. 그러다가 2015년에 batch normalization에 대한 방법이 논문을 통해 나오고 최근에는 거의 모든 딥러닝에 적용되는 추세이다.
YOLO v4에서는 최신의 딥러닝 기법을 적용하여 성능 향상을 했다. 사용한 기법들은 아래와 같다.
1) WRC (Weighted-Residual-Connections)
2) CSP (Cross-Stage-Partial-Connections)
3) CmBN (Cross mini-Batch Normalizations)
4) SAT (Self-Adversarial-Training)
5) Mish Activation
6) Mosaic Data Agumentation
7) Drop Block Regularization
8) CIOU Loss
-
Introduction
최신 Neural Networks들은 높은 정확도를 가지지만, 낮은 FPS(실시간 X)와 너무나 큰 mini-batch-size로 인해 학습하는데 많은 수의 GPU들이 필요하다는 단점이 있다. 이러한 문제를 해결하기 위해, YOLO v4는 다음과 같은 기여를 제공한다.
1) 일반적인 학습 환경에서도 높은 정확도와 빠른 object detector를 학습시킬 수 있다. 1개의 GPU(ex : GTX 1080 Ti, 2080 Ti)만 있으면 충분하다.
2) detector를 학습하는 동안, 최신 BOF, BOS 기법이 성능에 미치는 영향을 증명한다. (BOF와 BOS가 무엇인지는 2장에서 설명)
3) CBN, PAN, SAM을 포함한 기법을 활용하여 single GPU training에 효과적이다.
object detection 기술은 2013년 fast rcnn 이후 많은 논문이 발표되었지만, 처리 속도가 많이 걸리기 때문에 실생활에서 사용되는 사례가 얼마되지 않는다.
-
실시간 기술이 필수가 아닌 주차장의 빈자리를 찾거나 공항 검색대에서 x-ray 위험 물질을 찾는 등의 추천 시스템에만 사용되고 있다.
-
속도를 올리려면 그만큼 정확도가 낮아지기 때문에 모델이 단독으로 사용되는 사례는 거의 없다.
요약하자면 1개의 GPU를 사용하는 일반적인 학습환경에서 BOF, BOS 기법을 적용하여 효율적이고 강력한 Object Detection을 제작했다는 이야기다.
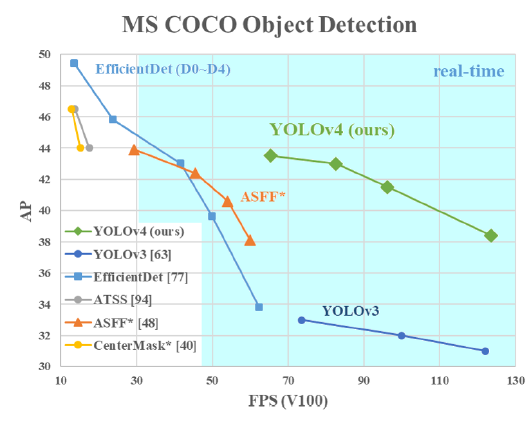
Figure 1. 본 논문에서 제안하는 YOLO v4와 최신 object detectors과의 비교. YOLO v4는 EfficientDet과 비슷한 AP 성능을 내면서도 2배 더 빠른 FPS를 보유한다. YOLO v3에 비해서 AP는 10%, FPS는 12% 향상됐다.
- Related Work
2.1. Object Detection Models
이 절에서는 Object Detection의 일반적인 구조(백본, Neck, Head)와 종류(1-stage, 2-stage)에 대해 소개한다.
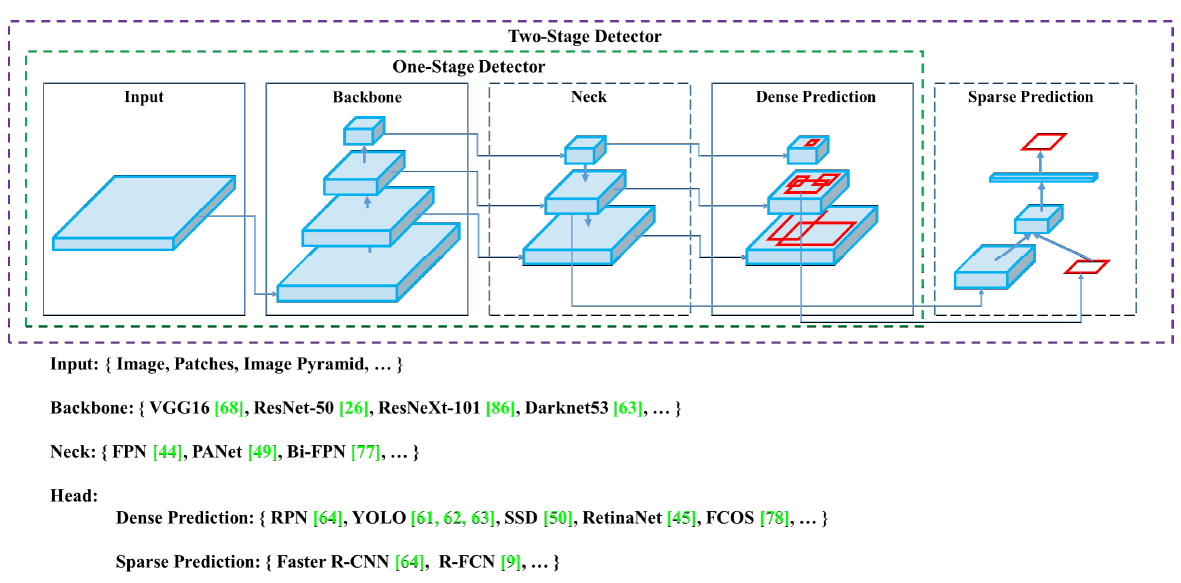
최신 detector는 주로 백본(Backbone)과 헤드(Head)라는 두 부분으로 구성된다. 백본은 입력 이미지를 feature map으로 변형시켜주는 부분이다. ImageNet 데이터셋으로 pre-trained 시킨 VGG16, ResNet-50 등이 대표적인 Backbone이다. 헤드는 Backbone에서 추출한 feature map의 location 작업을 수행하는 부분이다. 헤드에서 predict classes와 bounding boxes 작업이 수행된다.
헤드는 크게 Dense Prediction, Sparse Prediction으로 나뉘는데, 이는 Object Detection의 종류인 1-stage인지 2-stage인지와 직결된다. Sparse Prediction 헤드를 사용하는 Two-Stage Detector는 대표적으로 Faster R-CNN, R-FCN 등이 있다. Predict Classes와 Bounding Box Regression 부분이 분리되어 있는 것이 특징이다. Dense Prediction 헤드를 사용하는 One-Stage Detector는 대표적으로 YOLO, SSD 등이 있다. Two-Stage Detector과 다르게, One-Stage Detector는 Predict Classes와 Bounding Box Regression이 통합되어 있는 것이 특징이다. 자세한 설명은 아래 블로그에서 친절히 설명되어 있다.
넥(Neck)은 Backbone과 Head를 연결하는 부분으로, feature map을 refinement(정제), reconfiguration(재구성)한다. 대표적으로 FPN(Feature Pyramid Network), PAN(Path Aggregation Network), BiFPN, NAS-FPN 등이 있다. FPN과 PAN도 추후 기회가 되면 블로그에 정리를 해보겠다.
2.2. Bag of Freebies (BOF)
BOF는 inference cost의 변화 없이 (공짜로) 성능 향상(better accuracy)을 꾀할 수 있는 딥러닝 기법들이다. 대표적으로 데이터 증강(CutMix, Mosaic 등)과 BBox(Bounding Box) Regression의 loss 함수(IOU loss, CIOU loss 등)이 있다. 이 기법들의 상세한 내용은 3.4 YOLO v4에서 소개하겠다.
2.3. Bag of Specials (BOS)
BOS는 BOF의 반대로, inference cost가 조금 상승하지만, 성능 향상이 되는 딥러닝 기법들이다. 대표적으로 enhance receptive filed(SPP, ASPP, RFB), feature integration(skip-connection, hyper-column, Bi-FPN) 그리고 최적의 activation function(P-ReLU, ReLU6, Mish)이 있다. 이 기법들의 상세한 내용도 3.4절에서 소개하겠다.
- Methodology
3.1. Selection of Architecture
3.2. Selection of BOF and BOS
3.3. Addition Improvements의 내용은 3.4절에서 통합해서 설명
3.4. YOLO v4
YOLO v4의 아키텍쳐는 다음과 같다.
1) Backbone : CSP-Darkent53
2) Neck : SPP(Spatial Pyramid Pooling), PAN(Path Aggregation Network)
3) Head : YOLO-v3
YOLO v4에서는 다음과 같은 최신 딥러닝 기법들을 사용했다.
[Bag of Freebies (BoF) for backbone]
4-1) CutMix : 데이터 증강법의 일종. 한 이미지에 2개의 class를 넣은 것이 특징.
4-2) Mosaic Data Augmentation : CutMix와 마찬가지로 데이터 증강법의 일종. 한 이미지에 4개의 class를 넣은 것이 특징.
* 3.3절의 Figure 3 참고
4-3) DropBlock Regularization : 드롭아웃(DropOut)과 같은 Regularization 기법의 일종. 랜덤하게 out시키는 DropOut과는 달리, 일정한 범위를 out 시킴.
4-4) Class label Smoothing : 라벨 방법에 관한 새로운 기법. 기존의 라벨법은 0과 1과 같은 정수로 표시했지만, label smoothing 기법을 적용하면 label을 0.1, 0.9와 같은 확률로 표시하게 됨. 이러한 기법을 사용하는 이유는 misslabeling 때문. 이미지 라벨링을 사람이 하기 때문에 misslabeling 문제가 발생하는데(ex : 고양이 사진을 dog라고 라벨링하는 경우), 데이터 수가 많다면 라벨 수정에 어려움을 겪게 됨. 이 문제를 해결하기 위해 label을 0 또는 1이 아니라 smooth하게 부여함으로써, calibration 및 regularization 효과를 얻게 되어 overfitting 문제를 방지.
[Bag of Specials (BoS) for backbone]
5-1) Mish Activation : 활성화 함수에 관한 최신 기법. 수식은 다음과 같이 정의되고, 그래프는 아래에 첨부한다.
Mish를 사용하면 다음과 같은 이점을 얻게 된다.f(x) = x * tanh(softpuls(x))
softplus(x) = ln(1 + e^x)
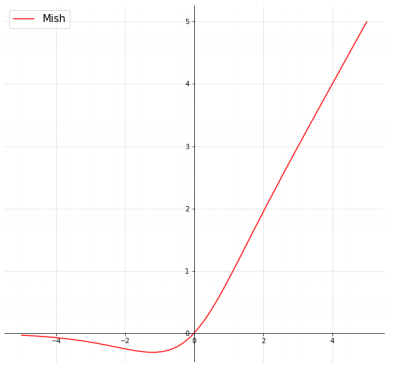
5-1-1) 일반적으로 0에 가까운 기울기로 인해, 훈련 속도가 급격히 느려지는 포화(Saturation) 문제 방지
-> ReLu보다 Mish의 gradient가 좀 더 smooth함
5-1-2) 강한 규제(Regularation) 효과로 overfitting 문제 방지
5-2) CSP(Cross-Stage Partial connections) : 기존의 CNN 네트워크의 연산량을 줄이는 기법. 원문에서 제안하는 CSP Net은 연산량을 20% 줄이면서도 MS COCO에서 높은 AP를 가진다고 한다. 요약하자면 학습할 때 중복으로 사용되는 기울기 정보를 없앰으로써 연산량을 줄이면서도 성능을 높인다. CPS를 소개하기 위해서, 원문 3장에서와 같이 DenseNet과 CSP-DenseNet을 비교하면서 설명하겠다.
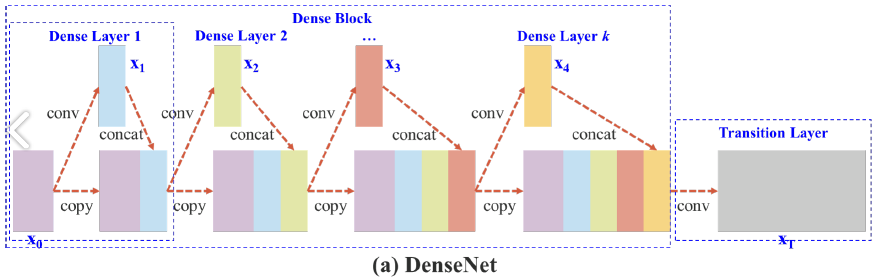
위의 그림은 DenseNet의 네트워크 구조이다. DenseNet은 크게 dense block과 tranistion layer이 포함된다. 그리고 각 dense block은 k개의 dense layers을 포함하고 있다. i번째의 dense layer에서 x_0(연보라색 블록)과 x_1(연하늘색 블록)이 결합되고(concatenated), 이 결합된 output은 (i + 1)번 째의 dense layer의 input이 된다. 이에 관한 메커니즘 방정식은 다음과 같이 식 1로 표현될 수 있다.
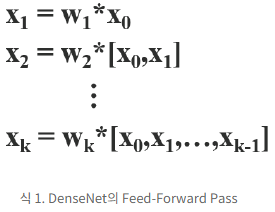
식 1에서 *는 convolution 연산자를 나타낸다. [x_0, x_1, ,,, x_k]는 x0, x1, ,,, x_k를 결합했다는 의미이다. (ex : Dense Layer 1에서 연보라와 연하늘 블록이 결합) w_i, x_i는 i번째 dense layer의 가중치(weight)와 output이다. 이 식을 보면 이전 레이어에서 계산했던 x_0, x_1 등의 결합 연산을 다음 레이어에서 한번 더 반복한다. (쓸데 없는 연산 낭비)

여기서 함수 f는 가중치 업데이트에 관한 함수이며 g_i는 i번째 dense layer로 전파되는 기울기(gradient)를 나타낸다. 우리는 많은 양의 기울기 정보가 서로 다른 dense layers의 가중치를 업데이트하기 위해 재사용된다는 것을 발견할 수 있다. 이렇게 되면 서로 다른 dense layers가 복사된 gradient 정보를 반복적으로 학습하게 된다.
가중치를 업데이트 하기 위해서 오차 역전파(back propagation) 알고리즘을 사용할 때, 가중치 업데이트 방정식은 다음과 같이 작성할 수 있다.
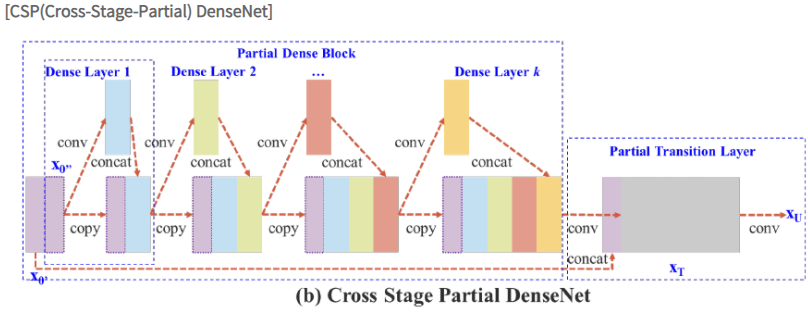
본문에서 제안하는 CSP DenseNet의 아키텍쳐는 위의 추가 Figure 2-(b)에서 볼 수 있다. CSP DenseNet은 partial dense block과 partial transition layer로 구성된다. (DenseNet의 구성품 앞에 수식어 'partial'를 붙임)
partial dense block에서는 dense layer 1의 피쳐맵(연보라색 블록을 의미, 원문에서는 base layer라고 표기됨)은 채널을 통해 다음과 같이 두 부분으로 분리된다.
현재까지 파악한 논문의 내용은 여기까지이다 아직 한참 남았......
앞으로도 계속 수정할 예정이다
다시한번 아래의 두 링크의 블로거님 들에게 감사드립니다.
