SSD : Single Shot Multibox Detector
Intro
오늘 리뷰할 논문은 yolo의 뒤를 잇는 1 Step object detection 알고리즘, SSD입니다.

Yolo는 속도 측면에서 당시 Faster R-CNN이 7FPS이었던 것을 45FPS까지 끌어올리는 비약적인 발전을 이루었습니다. 하지만 정확도 측면에선 다소 한계점이 있었습니다. 또한 작은 물체들은 잘 잡아내지 못한다는 문제가 있었습니다. SSD는 바로 이러한 한계점을 극복하고자 하는 시도에서 출발하게 됩니다.
- 영향력: 인용 횟수가 약 6700회에 달하며, 2저자인 드라고는 현재 구글 웨이모의 헤드 리서쳐입니다.
- 주요 기여: 1 Step Object Detection의 정확도와 속도를 향상 시켰습니다.
Yolo의 문제점은 입력 이미지를 7x7 크기의 그리드로 나누고, 각 그리드 별로 Bounding Box Prediction을 진행하기 때문에 그리드 크기보다 작은 물체를 잡아내지 못하는 문제가 있었습니다. 그리고 신경망을 모두 통과하면서 컨볼루션과 풀링을 거쳐 coarse한 정보만 남은 마지막 단 피쳐맵만 사용하기 때문에 정확도가 하락하는 한계가 있었습니다. 이에 SSD는 이전 리서치들에서 장점을 모아서 yolo의 한계점을 극복하려 합니다.
Multi Scale Feature Maps for Detection
SSD는 Yolo와 달리 컨볼루션 과정을 거치는 중간 중간 피쳐맵들에서 모두 Object Detection을 수행합니다. 논문 상에서는 다음과 같은 그림으로 이러한 구조를 표현합니다.
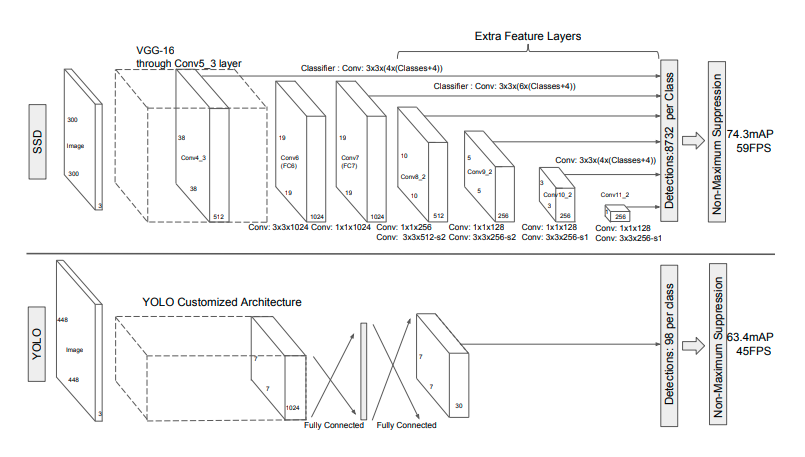
SSD는 먼저 300*300 크기의 이미지를 입력받아서 이미지 넷으로 pretrained된 VGG의 Conv5_3층까지 통과하며 피쳐를 추출합니다. 그 다음 이렇게 추출된 피쳐맵을 컨볼루션을 거쳐 그 다음 층에 넘겨주는 동시에 Object detection을 수행합니다. 이전 Fully Convolution Network에서 컨볼루션을 거치면서 디테일한 정보들이 사라지는 문제점을 앞단의 피쳐맵들을 끌어오는 방식으로 해결하였습니다.
SSD는 여기서 착안하여 각 단계별 피쳐맵에서 모두 Object Detection을 수행하는 방식을 적용한 것입니다. 이를 더 자세한 그림으로 표현하면 아래와 같습니다.

VGG를 통과하며 얻은 피쳐맵을 대상으로 쭉쭉 컨볼루션을 진행하여 최종적으로 1 x 1 크기의 피쳐맵까지 뽑습니다. 그리고 각 단계별로 추출된 피쳐맵은 Detector & Classifier를 통과시켜 object detection을 수행합니다. 그러면 Detector & Classifier는 어떤 구조로 되어 있는지 살펴보겠습니다.
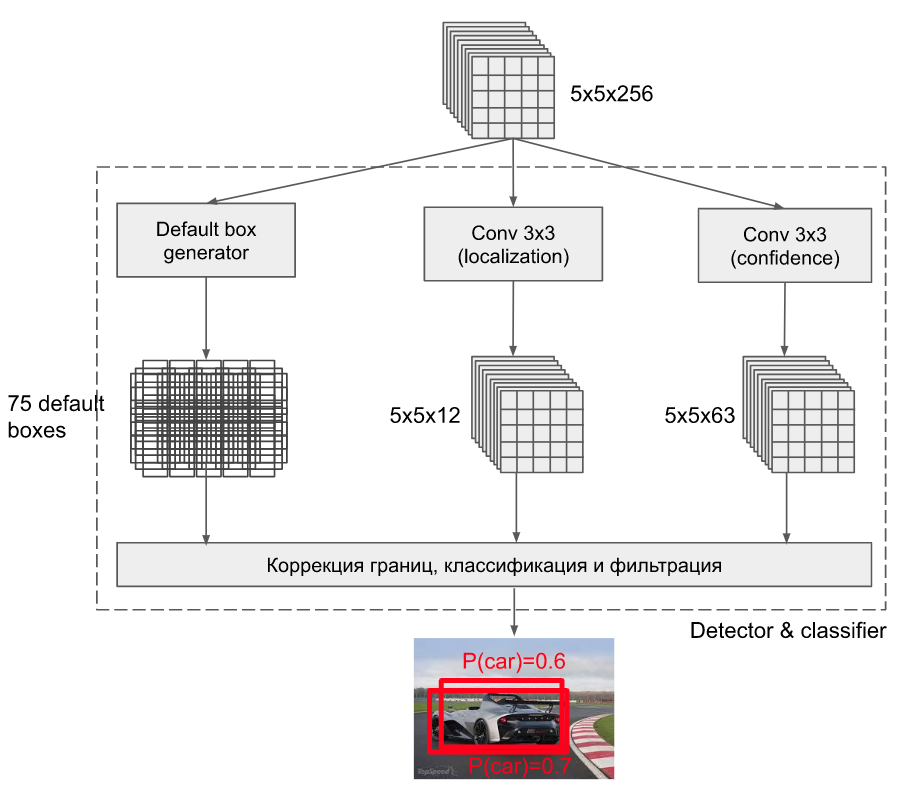
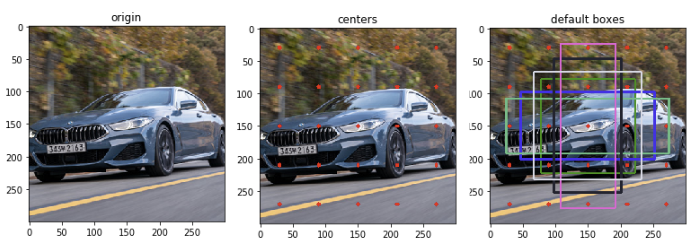
컨볼루션 중간에 5 x 5 x 256 크기의 피쳐맵을 대상으로 object detection을 수행한다고 가정합니다. 여기서 5 x 5는 YOLO에서 그리드 크기에 해당한다고 생각하시면 됩니다. 이제 하나의 그리드마다 크기가 각기 다른 default box들을 먼저 계산합니다. default box란 faster r-cnn에서 anchor의 기념으로 비율과 크기가 각기 다른 기본 박스를 먼저 설정해놓아서 bounding box를 추론하는데 도움을 주는 장치이며 그림으로 나타내면 아래와 같습니다.

위 그림을 보면 고양이는 작은 물체이고 강아지는 상대적으로 더 큽니다. 높은 해상도의 피쳐맵에서는 작은 물체를 잘 잡아낼 수 있고, 낮은 해상도에서는 큰 물체를 잘 잡아낼 것이라 추측할 수 있습니다. SSD는 각각의 피쳐맵을 가져와 비율과 크기가 각기 다른 default box를 투영합니다. 그리고 이렇게 찾아낸 박스들에 bounding box regression을 적용하고 confidence level을 계산합니다. 이는 YOLO가 아무런 기본 값 없이 2개의 box를 예측하도록 한 것과 대조적입니다.
다음으로 피쳐맵에 3 x 3 컨볼루션을 적용(패딩을 1로 설정하여 크기 보존)하여 bounding box regression 값을 계산합니다. 이는 각각의 default box들의 x, y, w, h의 조절 값을 나타내므로 4차원 벡터에 해당하며 위 그림에서는 인덱스 하나에 3개의 default box를 적용 했으므로 겨로가 피쳐맵의 크기는 5 x 5 x 12가 됩니다.
마지막으로 각각의 Default Box마다 모든 클래스에 대하여 클래시피케이션을 진행하는데, 총 20개의 클래스 + 1 (배경 클래스) x Default Box 수이므로 최종 피쳐맵 결과의 크기는 5x5x63이 됩니다.
이렇게 각 층별 피쳐 맵들을 가져와 Object Detection을 수행한 결과들을 모두 합하여 로스를 구한 다음, 전체 네트워크를 학습시키는 방식으로 1 Step end-to-end Object Detection 모델을 구성합니다.
Default Boxes Generating
먼저 Object Detection을 수행할 Feature Map의 개수를 m으로 놓고, 피쳐맵의 인덱스를 k로 놓습니다. 예시를 위해서 m은 6이라 놓겠습니다. 각 피쳐맵 별로 Scale Level은 아래 수식으로 구합니다.
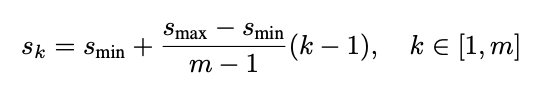
s_min은 0.2, s_max는 0.9이며 위의 수식은 큰 의미 없고 min과 max를 잡은 다음 그 사이를 m값에 따라서 적당히 구간을 나누어주는 값입니다. m=6으로 설정했을 때의 결과는 [0.2, 0.34, 0.48, 0.62, 0.76, 0.9]가 됩니다.
이 값이 무슨 의미냐하면 각각의 피쳐맵에서 default box의 크기를 계산할 때 입력 이미지의 너비, 높이에 대해서 얼만큼 큰 지를 나타내는 값입니다. 즉, 첫 번째 피쳐맵에선 입력 이미지 크기의 0.2 비율을 가진 작은 박스를 default box로 놓겠다는 의미이며 마지막 피쳐맵에서는 0.9와 같이 큰 default box를 잡겠다는 의미입니다.
이제 각각의 default 박스의 너비와 높이를 계산해야합니다. 이 때 우리는 정사각형 뿐만이 아닌, 다양한 비율을 가진 default box를 구하고자합니다. 이를 (1, 2, 3, 1/2, 1/3) 비율 값을 가지고 다음 수식을 통해서 계산합니다.
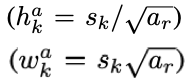
예를 들어 k=3, 즉 3번째 피쳐 맵의 default box들의 width와 height를 구해보겠습니다. 앞서 우리는 scale 값을 구했으며, k=3 일때의 값은 0.48입니다. 주어진 공식에 맞게 쭉쭉 계산을 해보면 아래와 같은 값을 구할 수 있습니다.

5개의 비율에 대하여 각각 계산을 진행하였으며, 논문에서는 여기에 추가적으로 현재 스케일 값 보다 좀 더 큰 정사각형 박스를 하나 추가하여 총 6개의 default box의 높이 너비 값을 구합니다. 이 값들은 모두 입력 이미지의 높이, 너비에 곱해서 사용할 비율 값입니다. 이제 입력 이미지에서 default box가 위치할 중심점을 구해보겠습니다. 이에 대한 수식은 아래와 같습니다.

fk는 피쳐맵의 가로 세로 크기입니다. 즉, mxn 크기의 피쳐맵의 중심점을 구하는 것으로 1x1 크기의 피쳐맵의 중심점은 0.5, 0.5 겠죠? 이를 한 칸씩 인덱스를 옮겨가면서 계산을 해주는 작업으로, Fk가 25라 가정했을 때 아래와 같은 결과를 얻을 수 있습니다.

이제 모든 작업이 끝났습니다. 구해준 중심점 좌표들에 원래의 입력이미지 크기를 곱해서 중심점을 구하고, 각각의 중심점마다 default box를 그려주면 됩니다. 이 작업을 시각화 하면 다음과 같습니다.
Loss function
지금까지 SSD가 prediction 값을 도출하는 과정들을 알아봤습니다. 다소 복잡하긴 해도 그동안 봤던 논문들의 개념이 적용되는 것이라 이해하기가 그렇게 어렵진 않네요. 이렇게 구한 예측 결과 값을 가지고 로스를 구해보도록 하겠습니다. 수식은 아래와 같습니다.
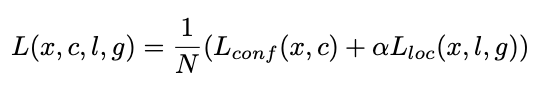
전체적으로 로스는 Yolo의 로스 펑션과 매우 유사합니다. 전체 로스는 각 클래스 별로 예측한 값과 실제 값 사이의 차인 Lconf와 바운딩 박스 리그레션 예측 값과 실제 값 사이의 차인 Lloc를 더한 값입니다. Lconf 먼저 더 자세히 들여다 보겠습니다.

기본적으로 Cross Entrophy Loss라고 생각하시면 되는데, 여기서 xpij라는 값이 등장합니다. 이는 즉 특정 그리드의 i번째 디폴트 박스가 p클래스의 j번째 ground truth box와 match가 된다 (IoU가 0.5 이상)라는 의미입니다. 즉, 모델이 물체가 있다고 판별한 디폴트 박스들 가운데서 해당 박스의 ground truth 박스하고만 cross entrophy loss를 구하겠다는 의미입니다. 뒷 부분은 물체가 없다고 판별한 디폴트 박스들 중에 물체가 있을 경우의 loss를 계산해줍니다. 다음으로 Lloc을 보겠습니다.
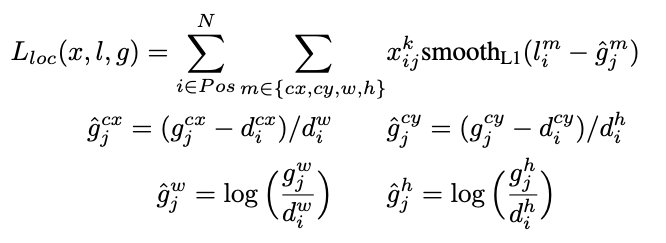
수식을 보자마자 현기증이 나지만 역시나 쫄 필요 없습니다. smoothL1은 앞서 Fast RCNN에서 제시된 Robust bounding box regression loss입니다. 그 아래는 bounding box regression 시에 사용하는 예측 값들을 말합니다. x, y 좌표 값은 절대 값이기 때문에 예측값과 실제 값 사이의 차를 default 박스의 너비 혹은 높이로 나누었습니다. 이렇게 해주면 값이 0에서 1 사이로 정규화되는 효과가 있습니다. 너비와 높이의 경우엔 로그를 씌워서 정규화 시킨 것입니다.
