Introduction
ICCV 2023 (Oral). Paper github
Shoufa Chen, Peize Sun, Yibing Song, Ping Luo
The University of Hong Kong | Tencent AI Lab | Fudan University | Shanghai AI Laboratory
17 Nov 2022
Object detection은 하나의 이미지에서 대상 객체에 대한 일련의 bounding box와 카테고리 레이블을 예측하는 것을 목표로 한다. 현재 object detection 감지 접근 방식은 객체 후보의 개발과 함께 진화해 왔다. 즉, 경험적 object prior에서 학습 가능한 object query로 발전해 왔다. 특히 대부분의 detector는 sliding window, region proposal, anchor box, reference point와 같이 경험적으로 설계된 객체 후보에 대한 회귀 및 분류를 정의하여 detection task를 해결한다.
최근 DETR에서는 수작업으로 설계한 구성요소를 제거하고 end-to-end detection 파이프라인을 설정하는 학습 가능한 object query를 제안하여 query 기반 detection 패러다임이 큰 주목을 받고 있다. DETR은 간단하고 효과적인 디자인이지만 여전히 고정된 학습 가능한 query 집합에 의존한다. 다음과 같은 자연스러운 질문이 생긴다.
학습 가능한 query들의 대체가 필요하지 않은 더 간단한 접근 방식이 있는가?
저자들은 일련의 랜덤 박스에서 객체를 직접 감지하는 새로운 프레임워크를 설계하여 이 질문에 대답하였다. 학습 단계에서 최적화해야 하는 학습 가능한 파라미터가 포함되지 않은 순전히 랜덤 박스부터 시작하여 대상 객체를 완벽하게 덮을 때까지 이러한 상자의 위치와 크기를 점차적으로 개선한다. 이 noise-to-box 접근 방식은 경험적 object prior나 학습 가능한 query가 필요하지 않으므로 객체 후보를 더욱 단순화하고 detection 파이프라인 개발을 촉진한다.
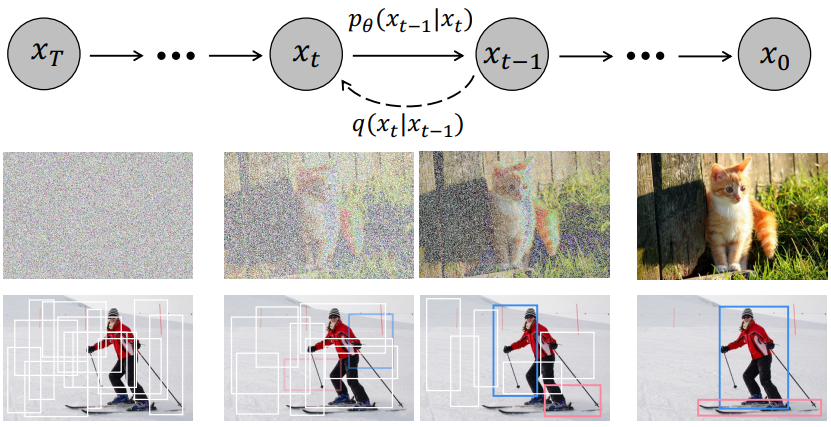
Noise-to-box 패러다임의 철학은 점진적으로 이미지를 생성하는 likelihood 기반 모델인 DDPM의 noise-to-image 프로세스와 유사하다. Diffusion model은 많은 생성 task에서 큰 성공을 거두었으며 image segmentation과 같은 인식 작업에서 연구되기 시작했다. 그러나 diffusion model을 object detection에 성공적으로 적용한 기술은 없다.
본 연구에서는 이미지 내 bounding box의 위치(중심 좌표)와 크기(너비, 높이) 공간에 대한 생성 task로 detection을 캐스팅하여 diffusion model을 사용하여 object detection을 처리하는 DiffusionDet을 제안하였다. 학습 시에서는 분산 schedule에 따라 제어되는 Gaussian noise를 ground-truth box에 추가하여 noisy box를 얻는다. 그런 다음 이러한 noisy box는 backbone 인코더(ex. ResNet, Swin Transformer)의 출력 feature map에서 관심 영역(RoI)의 feature를 자르는 데 사용된다. 마지막으로 이러한 RoI feature들은 noise 없이 ground-truth box를 예측하도록 학습된 detection decoder로 전송된다. 이를 통해 DiffusionDet은 랜덤 박스에서 ground-truth box를 예측할 수 있다. Inference 시에서 DiffusionDet은 학습된 diffusion process를 역전시켜 bounding box를 생성한다. 이는 bounding box에 대한 학습된 분포에 noisy한 사전 분포를 조정한다.
Approach
1. Architecture
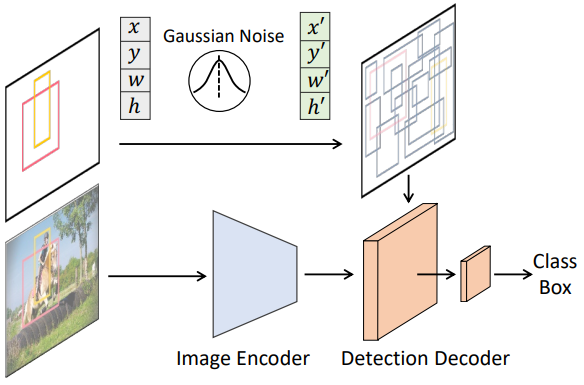
Diffusion model은 반복적으로 데이터 샘플을 생성하므로 inference 단계에서 모델 fθ를 여러 번 실행해야 한다. 그러나 모든 반복 step에서 이미지에 fθ를 직접 적용하는 것은 계산상 다루기 어렵다. 따라서 저자들은 전체 모델을 image encoder와 detection decoder의 두 부분으로 분리할 것을 제안하였다. 여기서 전자는 입력 이미지 x에서 feature 표현을 추출하기 위해 한 번만 실행되고 후자는 원본 이미지 대신 이 feature를 조건으로 사용하여 noisy box zt로부터 박스 예측을 점진적으로 개선한다.
Image encoderPermalink
Image encoder는 이미지를 입력으로 사용하고 detection decoder를 위한 상위 레벨 feature를 추출한다. 저자들은 ResNet과 같은 CNN 기반 모델과 Swin과 같은 Transformer 기반 모델을 모두 사용하여 DiffusionDet을 구현하였다. Feature Pyramid Network는 ResNet과 Swin backbone 모두에 대한 멀티스케일 feature map을 생성하는 데 사용된다.
Detection decoderPermalink
Sparse R-CNN를 따라 detection decoder는 proposal box 집합을 입력으로 사용하여 image encoder에서 생성된 feature map에서 RoI feature들을 자르고 이러한 RoI feature들을 detection head로 보내 박스 회귀 및 분류 결과를 얻는다. DiffusionDet의 경우 proposal box는 학습 시에는 ground-truth box에서 교란되고 평가 시에서는 가우시안 분포에서 직접 샘플링된다.
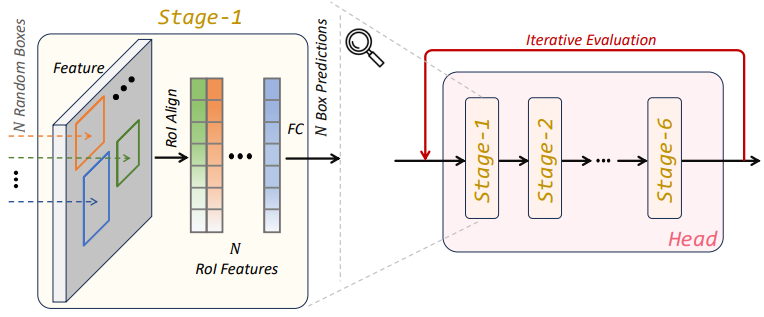
Detection decoder는 6개의 계단식 단계로 구성돤다. 본 논문의 디코더와 Sparse R-CNN의 디코더 사이에는 3가지 차이점이 있다.
Inference 시, DiffusionDet은 랜덤 박스에서 시작하는 반면 Sparse R-CNN은 고정된 학습 세트를 사용한다.
Sparse RCNN은 proposal box와 해당 proposal feature의 입력 쌍을 취하는 반면 DiffusionDet은 proposal box만 필요하다.
DiffusionDet은 평가를 위해 반복적인 방식으로 detector head를 재사용할 수 있으며 파라미터는 여러 step에서 공유된다. 각 step은 반복 평가라고 하는 timestep 임베딩에 의해 diffusion process에 지정되는 반면 Sparse R-CNN은 detection decoder를 한 번만 사용한다.
2. Training
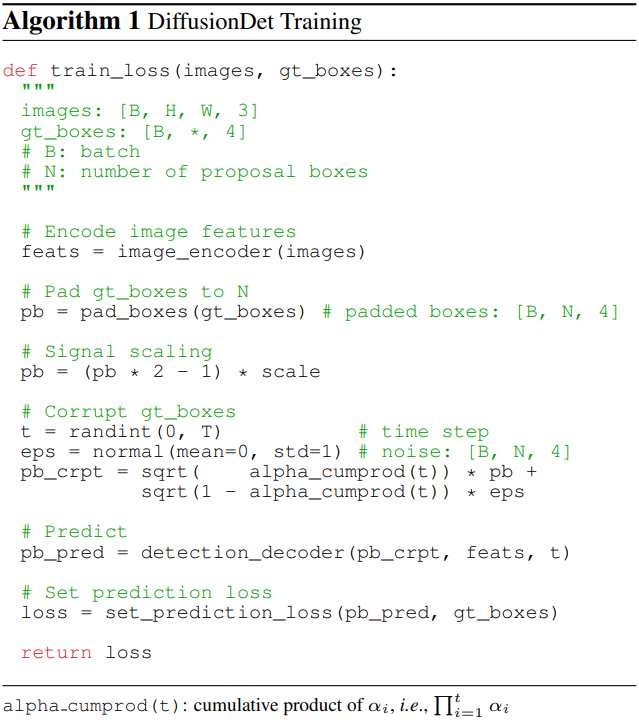
학습 중에 먼저 ground-truth box에서 noisy box로의 diffusion process를 구성한 다음 이 과정을 역전시키도록 모델을 학습시킨다. Algorithm 1은 DiffusionDet 학습 절차의 pseudo-code이다.
Ground truth boxes padding
최신 object detection 벤치마크의 경우 관심 있는 인스턴스 수는 일반적으로 이미지에 따라 다르다. 따라서 먼저 원래의 ground-truth box에 일부 추가 박스들을 채워서 모든 박스가 고정된 수의 Ntrain으로 합산되도록 한다. 저자들은 기존 ground-truth box 반복, 랜덤 박스 concatenate, 또는 이미지 크기 박스와 같은 여러 패딩 전략을 살펴보았다. 그 중 랜덤 박스를 concatenate하는 것이 가장 효과적이었다.
Box corruption
패딩된 ground-truth box에 Gaussian noise를 추가한다. Noise 스케일은 αt에 의해 제어되며, 서로 다른 timestep t에서 αt에 대해 단조롭게 감소하는 cosine schedule을 채택하였다. 특히, 신호 대 잡음 비율(SNR)이 diffusion model 성능에 중요한 영향을 미치기 때문에 ground-truth box 좌표도 스케일링되어야 한다. 저자들은 object detection이 이미지 생성 작업보다 상대적으로 높은 신호 스케일링 값을 선호한다는 것을 관찰했다.
Training losses
Detector는 Ntrain개의 손상된 박스를 입력으로 사용하고 카테고리 분류와 박스 좌표에 대한 Ntrain개의 예측을 예측한다. Ntrain개의 예측 집합에 set prediction loss를 적용한다. 최적의 전송 할당 방법을 통해 가장 적은 비용으로 상위 k개의 예측을 선택하여 각 ground-truth 값에 여러 예측을 할당한다.
3. Inference
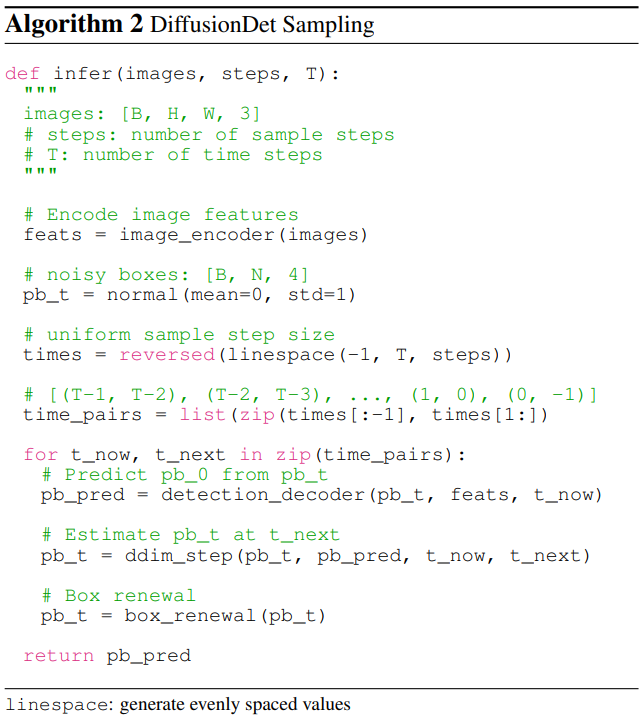
DiffusionDet의 inference 절차는 noise에서 object box까지의 denoising process이다. 가우시안 분포에서 샘플링된 박스에서 시작하여 모델은 Algorithm 2에 표시된 대로 예측을 점진적으로 개선한다.
Sampling step
각 샘플링 step에서는 마지막 샘플링 step의 랜덤 박스 또는 추정된 박스가 detection decoder로 전송되며 카테고리 분류 및 박스 좌표가 예측된다. 현재 step의 박스를 얻은 후 DDIM을 사용하여 다음 step의 박스를 추정한다. DDIM 없이 예측된 박스를 다음 step으로 보내는 것도 선택적인 점진적 개선 전략이지만 상당한 성능 악화를 가져온다.
Box renewal
각 샘플링 step 후에 예측된 박스는 원하는 예측과 원하지 않는 예측이라는 두 가지 유형으로 대략적으로 분류될 수 있다. 원하는 예측에는 해당 객체에 올바르게 위치한 박스가 포함되어 있는 반면, 원하지 않는 예측은 랜덤으로 분포된다. 이러한 원하지 않는 박스를 다음 샘플링 iteration으로 직접 보내는 것은 원하지 않는 박스의 분포가 학습 중에 구성되지 않기 때문에 이점을 가져오지 않는다. Inference를 학습과 더 잘 일치시키기 위해 저자들은 원하지 않는 박스를 랜덤 박스로 대체하여 부활시키는 박스 갱신 (box renewal) 전략을 제안하였다. 먼저 특정 임계값보다 점수가 낮은 원하지 않는 박스를 필터링한다. 그런 다음 나머지 박스와 가우시안 분포에서 샘플링된 새로운 랜덤 박스를 concatenate한다.
Flexible usage
랜덤 박스 디자인 덕분에 학습 단계와 동일할 필요가 없는 임의의 랜덤 박스 수와 반복 횟수로 DiffusionDet을 평가할 수 있다. 이에 비해 이전 접근 방식들은 학습과 평가 중에 동일한 수의 박스에 의존하며 detection decoder는 forward pass에서 한 번만 사용된다.
Experiment
-
데이터셋: COCO, LVIS v1.0, CrowdHuman
-
구현 디테일
ResNet과 Swin backbone은 각각 ImageNet-1K와 ImageNet-21K에서 사전 학습된 가중치로 초기화
Detection decoder는 Xavier init으로 초기화
optimizer: AdamW
learning rate: 2.5×10−5
weight decay: 10−4
batch size: 16
iteration: 45만
data augmentation: random horizontal flip, scale jitter
각 샘플링 step의 예측은 NMS과 함께 앙상블되어 최종 예측이 됨
1. Main Properties
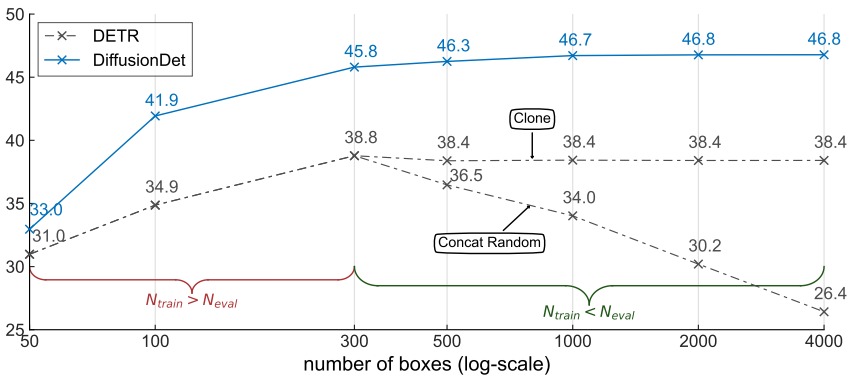
다음은 300개의 object query 또는 proposal box로 학습된 DETR과 DiffusionDet의 성능을 평가 시 사용하는 박스 수에 따라 비교한 그래프이다.
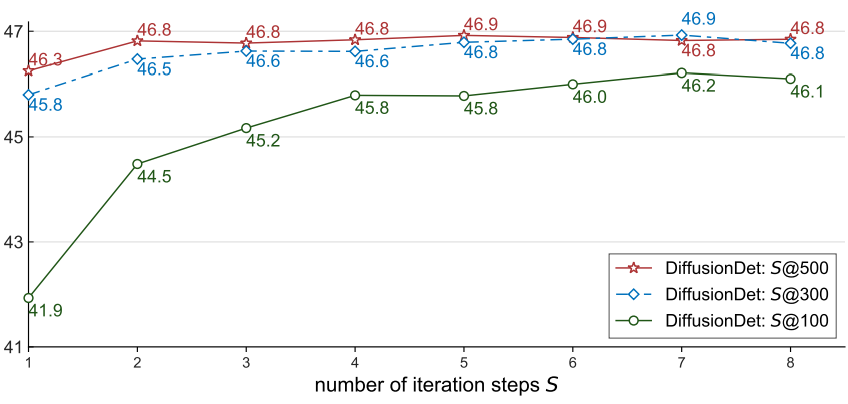
다음은 학습 시 사용한 박스 수에 따른 성능을 iteration step 수에 따라 비교한 그래프이다.
2. Benchmarking on Detection Datasets
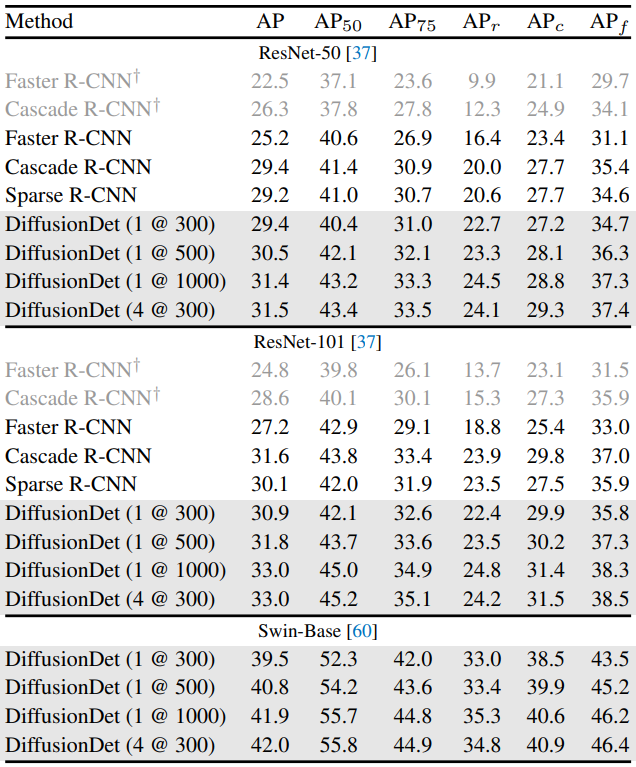
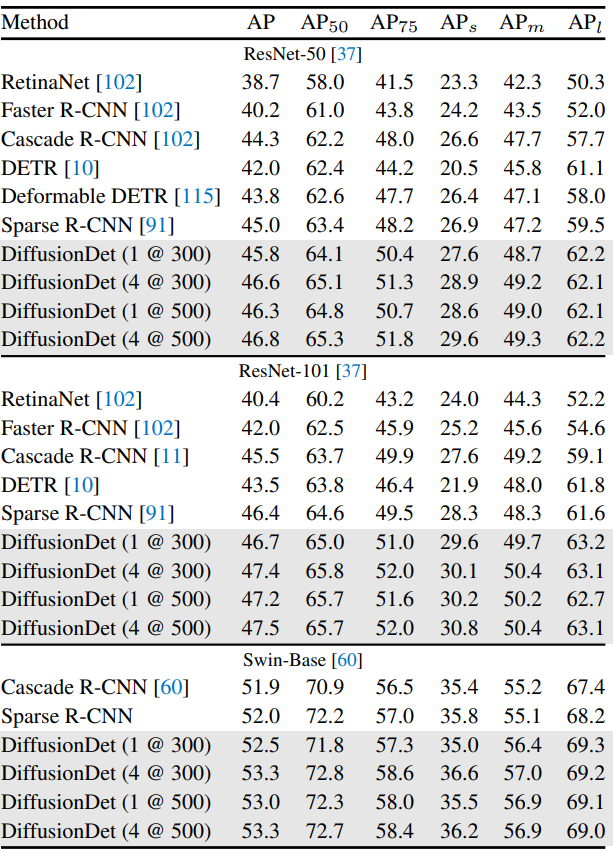
다음은 COCO 2017 val set에서 다양한 object detector와 성능을 비교한 표이다.
다음은 LVIS v1.0 val set에서 다양한 object detector와 성능을 비교한 표이다.