
해당 글은 GLUE 논문 을 바탕으로 작성한 글입니다.
paperswithcode dataset description을 참고하였습니다
0. Intro
GLUE는 자연어 이해 모델에서 범용적으로 사용되는 성능지표이다.
당신이 자연어 처리와 인공지능에 관심이 있고, 관련 논문을 읽어 보았다면,
이 모델이 GLUE SOTA(State-Of-The-Art)를 달성하였습니다!!라고 자신의 모델을 자랑하는 글 또한 읽어 보았을 것이다.
이 글은 "SOTA는 아는데, GLUE는 무슨 뜻이지...?" 하는 사람들을 위한 글이다.
1. What is GLUE?
인간지능은 생각보다 대단하다! 여러분은 글을 읽고 요약도 할 수 있고, 누군가 글에 대해 질문을 했을 때 대답을 해줄 수도 있고, 이 글이 어떤 주제인지도 남들에게 자연스럽게 자신이 사용하는 언어로 이야기해 줄 수 있다. (현재까지의 인공지능은 인간의 광범위한 언어 이해 능력의 발끝도 따라오지 못한다!)
인간이 언어를 이해하는 능력은 general, flexible, robust하다고 논문에서는 말한다. 그리고 이런 대단한 인간의 언어 이해 능력을 따라오는 것이 NLU Model의 핵심 과제라고 할 수 있다.
인간의 언어 능력을 인공지능이 얼마나 따라왔는지 정량적 성능지표를 만든 것이 GLUE (General Language Understanding Evaluation) Benchmark라고 할 수 있다.
논문의 저자들은 인간이 언어를 이해하는 방식과 유사한 여러 가지 태스크를 만들어 NLU Model의 성능을 측정하고자 하였다.
- Question Answering
- Sentiment Analysis
- Textual Entailment
등의 과제들이 GLUE에 포함되어 있고, 또한 논문의 저자들은 GLUE에 대한 리더보드를 온라인에 공개하여 SOTA 모델들을 한 눈에 볼 수 있도록 하였다.
여기에서 GLUE 리더보드를 볼 수 있다.
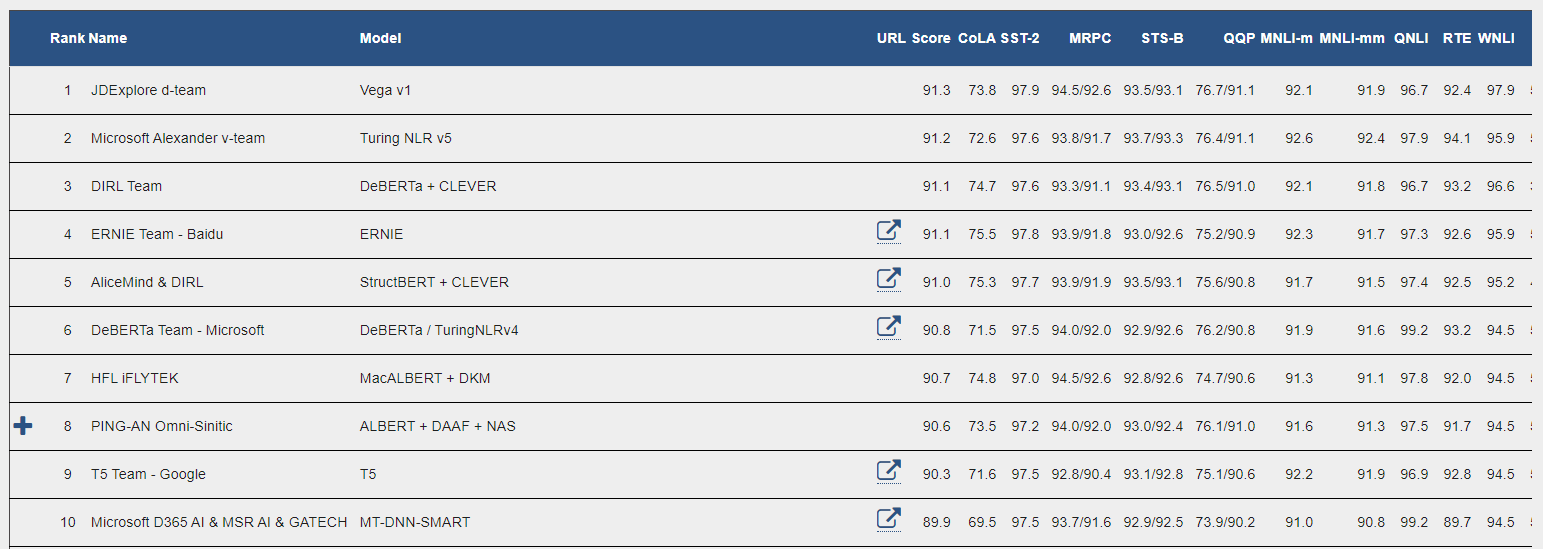
Task의 점수의 합이 높을수록 리더보드 상위권에 올라가게 된다.
2. GLUE Tasks
GLUE는 (논문에서) 9개의 영어 문장 이해 태스크를 제공한다.
GLUE 벤치마크로 NLU Task에서 저자들이 달성하고자 하는 목표는 일반화 가능한 자연어 이해 시스템을 발전시키는 것이라고 한다.
Single-Sentence Tasks
CoLA
The Corpus of Linguistic Acceptability의 줄임말로써, '언어학적으로 수용 가능한 문장인지' 판별하는 태스크이다. 데이터는 언어 이론 관련 책이나 기사에서 가져왔다고 한다.

출처: Neural Network Acceptability Judgements (Warstadt et al., 2018)
해당 태스크는 기본적으로 이진분류(Binary Classification) 문제이며, 평가 지표는 Matthews correlation coefficient를 사용한다고 한다. 아래는 매튜스 상관계수의 수식이다.
이 평가지표는 기본적으로 상관계수라서 값은 -1~1 사이로 나오고, 값이 0이면 uninformed guessing이라고 한다.
SST-2
The Stanford Sentiment Treebank의 줄임말로, 영화 리뷰와 그에 따른 긍정/부정 라벨링이 붙어 있는 데이터이다. 태스크는 문장이 주어지면 감성 분석을 통하여 문장의 긍정/부정 여부를 class로 구분하여 이진분류하는 태스크이다. 아래는 감성 분석의 예시이다.

Similarity and Paraphrase Tasks
MRPC
The Microsoft Research Paraphrase Corpus의 줄임말로써, 문장 쌍과 그에 대한 라벨로 구성되어 있다. 태스크는 문장 쌍이 의미론적으로 동일한지 판별하여 이진분류하는 것이며, 라벨의 불균형 때문에 F1-Score,Accuracy 두 가지의 평가지표를 사용한다고 한다.

출처: Automatically Constructing a Corpus of Sentential Paraphrases (Dolan & Brockett, 2005)
QQP
The Quora Question Pairs dataset의 약자이며, 말 그대로 질문 페어로 구성된 데이터셋이다. 두 개의 질문이 의미론적으로 같은지 여부를 판별하며, 여기에서도 라벨 불균형 문제 때문에 F1-Score,Accuracy 두 가지의 평가지표를 사용한다.
STS-B
The Semantic Textual Similarity Benchmark의 줄임말이다. 뉴스 헤드라인, 이미지 및 비디오 캡셔, 그리고 자연어 추론 데이터에서 문장 쌍을 가져온 데이터라고 한다. 이 데이터는 인간이 문장 쌍에 대한 유사도를 1~5로 라벨링 해 놓은 데이터이고, 자연어 모델로 이것을 예측하는 태스크이다. 성능지표로는 Pearson correlation coefficient와 Spearman correlation coefficient를 사용한다.
Inference Tasks
MNLI
The Multi-Genre Natural Language Corpus의 줄임말이며, 문장 쌍에 대해 언어적 함의(textual entailment)에 대한 라벨링이 되어 있다. 기본적으로 전제(premise)와 가설(hypothesis) 쌍으로 문장이 구성되어 있으며, 이 문장 간의 관계를 세 가지로 예측하는 태스크이다.
- entailment (가설이 전제의 함의를 담고 있음)
- contradiction (가설과 전제가 모순)
- neutral (둘다 아닐 때)
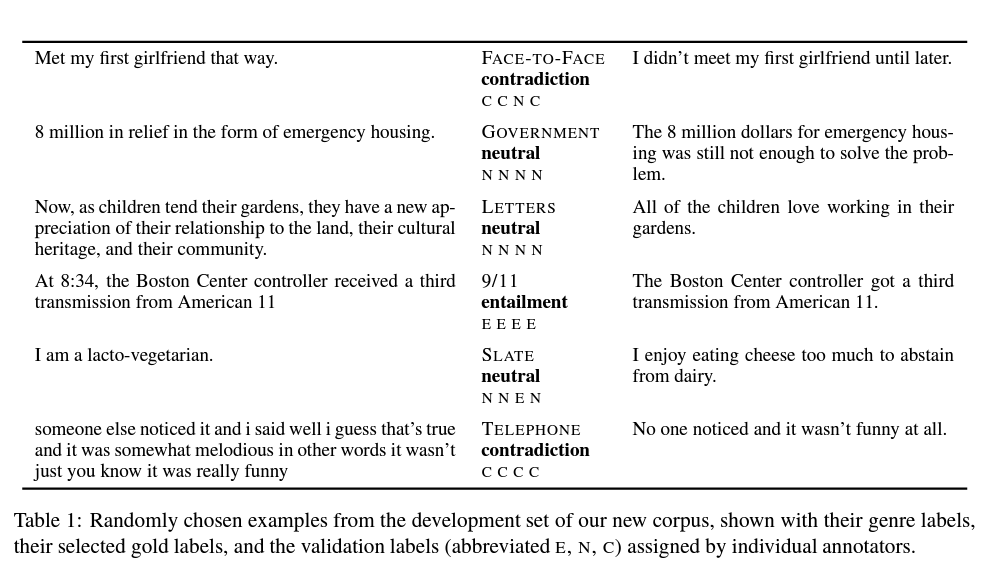
출처: A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference (Williams et al., 2018)
QNLI
The Stanford Question Answering Dataset의 줄임말이다. 질문-응답 태스크이며, 문단-질문 쌍으로 구성되어 있다. 문단 중 한 문장이 질문(사람이 만든)에 대한 답을 담고 있다.
저자는 태스크를 살짝 비틀었는데 - 문단에서 질문의 내용을 담고 있는 문장과 질문 문장에 대한 문장 쌍 분류 를 수행하고, 중복되는 어휘가 적은 문장 쌍을 걸러내었다(filtering out)고 한다.
결론적으로 우리가(모델이) 수행해야 할 태스크는 - context sentence(문단의 원래 문장)이 질문에 대한 답을 담고 있냐 아니냐에 대한 분류이다.
저자는 이렇게 태스크를 비틂으로써 "단순히 겹치는 어휘쌍이 많은 문장 쌍"을 정답으로 추론하는 "간단한 추론"을 모델이 하지 못하게 함으로써 보다 general하게 모델 성능을 측정할 수 있다고 한다.
RTE
The Recognizaing Textual Entailment의 약자로 annual textual entailment challenge 에서 데이터를 가져왔다고 한다. 위의 MNLI task와 유사하지만 neutral과 contradiction을 모두 not-entailment 라벨로 만듦으로써 이진 분류 task로 만들었다고 한다.
WNLI
Winograd NLI 의 줄임이고, The Winograd Schema Challenge에서 데이터를 가져왔다고 한다. 해당 challenge는 system이 대명사가 포함된 문장을 읽고, 대명사가 가리키는 대상을 리스트에서 고르는 챌린지이다.
저자는 이 챌린지를 태스크로 만들기 위해, 가능한 모든 참조(대상)에 대해 모호한 대명사를 조합하여 문장 쌍을 만들었다고 한다.
태스크는 대명사가 포함된 문장이 원래 문장의 함의를 담고 있나 예측하는 것이다. 말로 하면 어려우니 예시를 하나 보자.
Sentence with the pronoun substituted :
I put the cake away in the refrigerator. It has a lot of leftovers in it.
Original Sentence :
The refrigerator has a lot of leftovers in it.
해당 예시는 위의 문장에서의 대명사 It이 원래 문장의 the refrigerator를 정확히 가리키고 있으니 1로 예측해야 맞다.
3. Conclusion
저자들은 베이스라인을 만들어본 결과 하나의 GLUE task에 대해 학습시킨 것보다 모든 task에 대해 동시에 학습시킨 모델의 종합 성능이 더 좋았다고 한다. 처음에 얘기했던 모델의 general함을 어느 정도 달성했다고 볼 수 있겠다.
저자들은 GLUE 벤치마크가 general-purpose NLU 모델을 더 발전시킬 수 있는 양분이 될 수 있을 것이라 말하며 논문을 마친다.
여러분도 각자의 NLU 모델들을 개발하여 GLUE top performance에 도전해 보는 것이 어떨까?
