
Section 6: Cluster Maintenance
이번 섹션에서는 클러스터 유지 관리와 관련된 주제에 대해 학습할 것이다.
- Cluster Upgrade Process
- Operating System Upgrades
- Backup and Restore Methodologies
운영체제 업그레이드
OS 패치나 업그레이드를 적용하기 위해 의도적으로 클러스터에서 노드를 제거하는 예시를 통해 클러스터에서 노드를 제거하면 어떤 결과가 발생하는지 알아볼 것이다.
클러스터 업그레이드 과정
클러스터 업그레이드를 직접 수행해볼 것이다.
백업과 복원 방법
오류 복구 시나리오를 통해 클러스터 백업, 클러스터 복구에 대해 배울 것이다.
Operating System Upgrade
소프트웨어 기반 업그레이드나 보안 패치 등의 유지 보수를 위해 클러스터의 노드를 삭제하는 시나리오로 학습할 것이다.
여러 노드와 파드를 통해 응용 프로그램을 실행하는 클러스터이다.

노드 중 하나가 다운되면 어떻게 될까?
더이상 노드에 있던 파드에는 접근할 수 없다. 그리고 파드가 어떻게 배치되어 있느냐에 따라 사용자가 영향을 받을 수 있다.
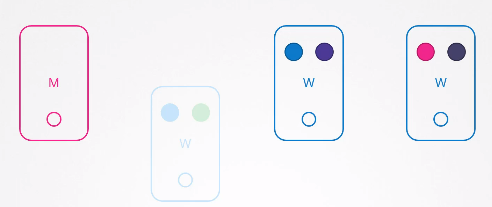
파란색 파드는 복제본이 있기 때문에 파란색 파드에 액세스하는 사용자에게는 영향을 미치지 않는다.
하지만 녹색 파드에 접속하는 사용자는 영향을 받을 수 밖에 없다.
쿠버네티스에서는 이런 경우 노드가 복구되었을 때 kubelet을 통해 파드를 복구한다.
그러나 노드가 5분 이상 다운되었다면 노드에 존재했던 파드들은 모두 종료된다.
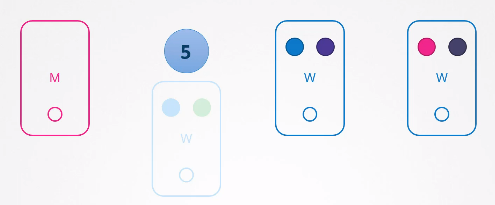
파드가 레플리카셋으로 생성된 경우 다른 노드에 재생성 될 것이다.
파드가 복구될 때까지 기다리는 시간을 pod-eviction-timeout=5m0s라고 하며, 컨트롤러 매니저에 기본적으로 5분으로 설정되어 있다.

워커 노드가 다운되면 마스터 노드는 최대 5분간 노드가 복구되길 기다리고, 노드가 그 이후에 복구된다면 해당 노드 안에 있던 모든 파드는 삭제된다.
유지보수 조건!
- 노드에서 수행할 유지 관리 작업이 있는 경우
- 노드에서 실행 중인 워크로드에 다른 replicas가 있음을 알고있는 경우
- 노드가 다시 복구될 것이 확실한 경우
5분 이내로 노드를 빠르게 업그레이드하여 재부팅할 수 있다.
그러나 노드가 5분 안에 다시 온라인 상태가 될 수 있는지는 보장할 수 없다. 따라서 더 안전한 방법을 찾아야 한다.
안전하게 유지보수 하는 방법
워커 노드 내의 모든 내용이 클러스터의 다른 노드로 이동되도록 의도적으로 워커노드를 비울 수 있다.
kubectl drain node1
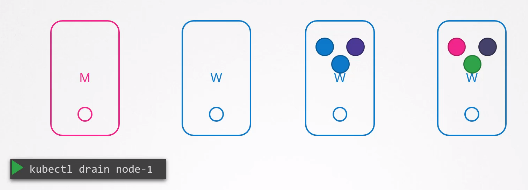
노드를 drain 하면 기술적으로는 파드가 움직이는 것이 아니라 파드가 해당 노드에서 정상적으로 종료되고 다른 노드에서 재생성된다.
그리고 노드의 상태는 cordoned 또는 unschedulabled로 표시된다.
즉, drain을 해제할 때까지 해당 노드에 파드를 배치할 수 없다.
kubectl uncordon node1
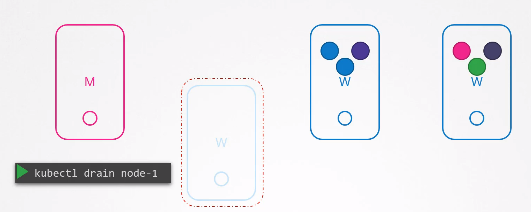
이제 drain된 노드를 업그레이드 한 후, 재부팅 할 수 있다.
재부팅된 노드는 온라인 상태가 되었지만 여전히 unschedulabled 상태로 유지되고 있다.
따라서 노드에 파드를 스케줄링 할 수 있도록 uncordon 해주어야 한다.
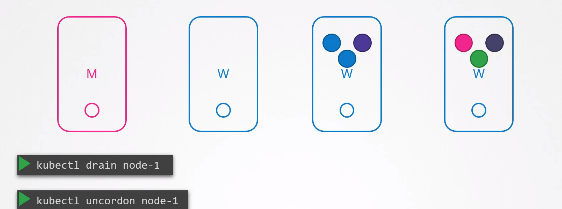
다른 노드로 이동된 파드는 자동으로 돌아오지 않기 때문에 이동된 파드가 삭제되거나 클러스터에 새 파드가 생성되는 경우 uncordon된 노드에 스케줄링 될 것이다.
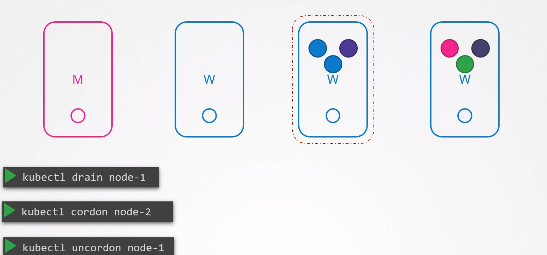
kubectl cordon node2
cordon이라는 명령도 존재하는데, 이 명령어는 drain처럼 노드의 상태를 unschedulable로 만든다.
하지만 drain처럼 노드에 존재하는 오브젝트를 다른 노드로 이동시키지는 않고, 단순히 새로운 파드가 해당 노드에 스케줄링 되지 않도록 하는 명령이다.
Kubernetes Release
쿠버네티스의 버전에 대해 알아볼 것이다.
쿠버네티스가 소프트웨어 Release를 관리하는 방법
쿠버네티스 릴리즈 버전
- 쿠버네티스 버전 확인
kubectl get nodes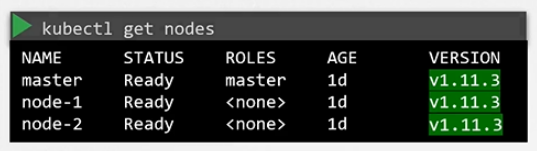
현재 버전은 1.11.3으로 확인된다.
쿠버네티스 릴리즈 버전은 3개의 부분으로 나뉘어진다.

첫 번째는 major 버전, 두 번째는 minor 버전, 세 번째는 패치 버전이다.
- minor : 새로운 기능을 갖춘 버전으로 몇 달에 한번씩 릴리즈 된다.
- patch : 중요한 버그 수정으로 자주 릴리즈 된다.
쿠버네티스도 다른 애플리케이션과 같이 standard software release versioning procedure를 따른다.
몇 달에 한 번씩 소규모 릴리즈를 통해 새로운 특징과 기능을 선보인다
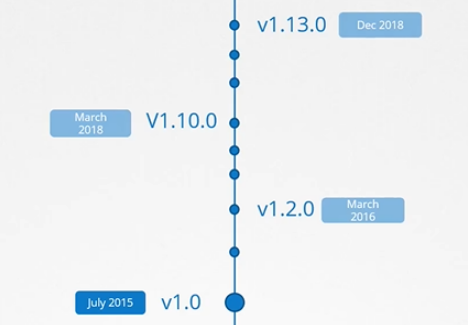
쿠버네티스의 첫 번째 major 버전은 2015년 7월에 출시되었다.
가장 최신의 안정된 버전은 v1.13.0로, 쿠버네티스의 안정된 릴리즈 버전이다.
이 외에도 알파와 베타 릴리즈가 있다.
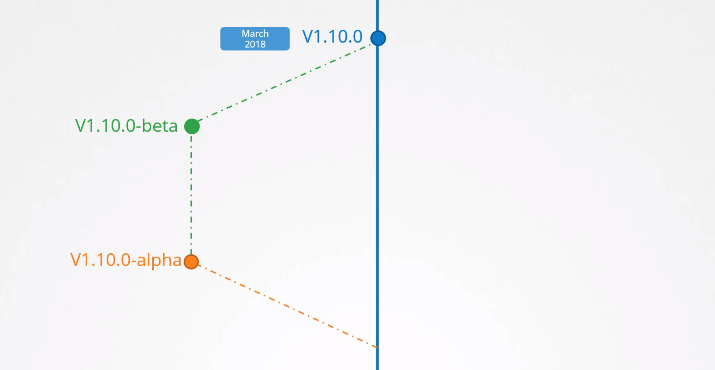
모든 버그를 수정하고 개선하면 알파 태그를 부착한 알파 릴리즈를 먼저 출시한다.
알파 버전은 기능이 default로 비활성화 되어 있으며, 버그가 발생할 가능성이 있다.
이제 베타 버전에서 코드 테스트를 통해 기능이 잘 작동되면 새로운 기능이 default로 활성화 된다.
그리고 안정된 버전으로 릴리즈된다.
쿠버네티스의 github Release repository에서 모든 릴리즈 버전을 확인할 수 있다.
쿠버네티스를 설치하기 위해 tar.gz 파일을 다운로드하고 압축을 풀면 모든 kubernetes 구성요소에 대한 실행 파일이 들어있다.

실행 파일에는 컨트롤 플레인 구성요소가 포함되어 있으며, 모두 동일한 버전이다.
etcd 클러스터와 CoreDNS 서버는 별도의 프로젝트이므로, 자체 버전이 존재하기 때문에 컨트롤 플레인에는 동일하지 않은 버전의 구성요소도 존재한다는 것을 기억하자!
Cluster Upgrade Process
컨트롤 플레인 구성요소들은 모두 같은 버전을 사용해야 하는건지 의문을 가질 수 있다.
아니다. 다른 버전의 구성요소를 사용할 수 있다.
Control plane 구성요소 버전
kube-apiserver는 다른 모든 구성요소와 통신하는 컨트롤 플레인의 주요 구성요소이다.
따라서 kube-apiserver보다 더 높은 버전의 구성요소는 사용하면 안된다.
Controller-manager, kube-scheduler
kube-apiserver 버전보다 1만큼 낮은 버전까지 사용할 수 있다.
kubelet, kube-proxy
kube-apiserver 버전보다 2만큼 낮은 버전까지 사용할 수 있다.
kubectl
kube-apiserver 버전 ± 1 범위의 버전을 사용할 수 있다.
skew 명령을 통해 구성요소의 업그레이드를 수행할 수 있다.
언제 업그레이드가 필요할까?
쿠버네티스는 3개의 최신 minor 버전만 지원한다.
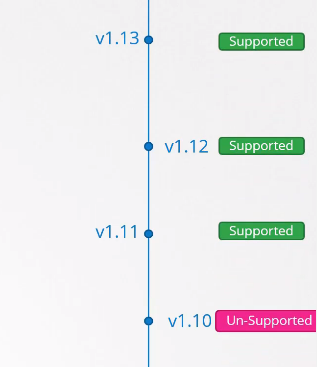
만약 1.13 버전이 새로 릴리즈 되면 1.10 버전은 지원되지 않는다. 따라서 최신 버전이 나오기 전에 업그레이드를 하면 좋을 것이다.
업그레이드 방법
권장되는 접근 방법은 한 번에 하나의 minor 버전씩 업그레이드 하는 것이다.
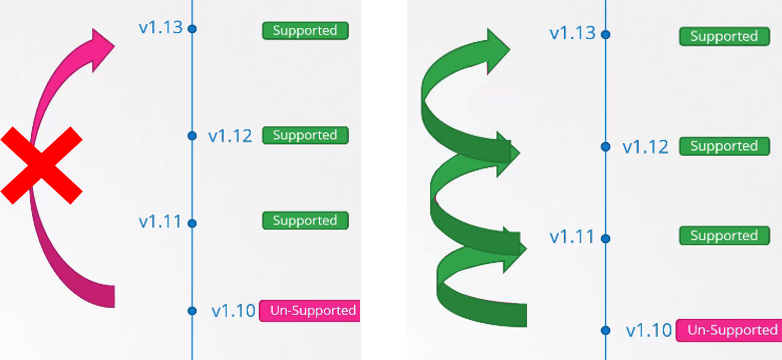
1.10에서 1.11로, 1.11에서 1.12로, 1.12에서 1.13으로 순차적으로 올려주면 된다.
업그레이드 프로세스는 클러스터 설정을 어떻게 했느냐에 따라 달라진다.
클러스터가 클라우드 서비스 공급자(CSP)에 의해 배포된 관리형 쿠버네티스 클러스터라면 몇 번의 클릭으로 클러스터를 업그레이드 할 수 있다.
만약 kubeadm으로 클러스터를 배포했다면 kubeadm을 사용하여 클러스터를 업그레이드 할 수 있다. 업그레이드 시 모든 구성요소를 수동으로 업그레이드 해야 한다.
kubeadm으로 클러스터 업그레이드
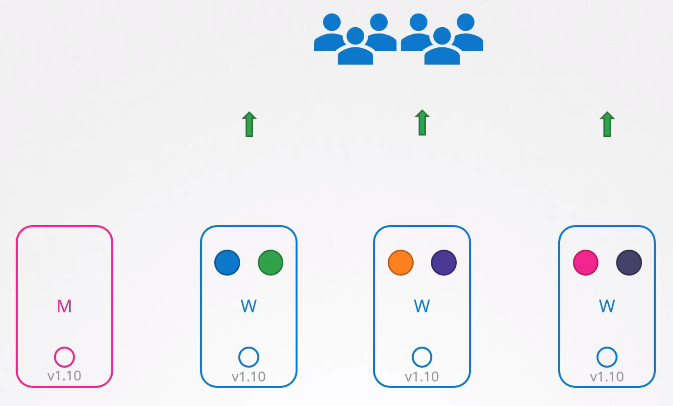
마스터 노드와 워커 노드가 있는 클러스터를 생각해보자.
클러스터 업그레이드는 두 가지 단계로 진행된다.
1) 마스터 노드 업그레이드
2) 워커 노드 업그레이드
1) 마스터 노드
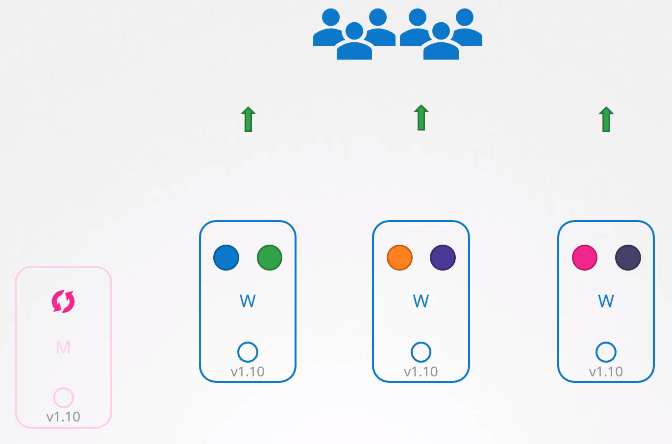
마스터 노드가 업그레이드 되는 동안 apiserver, scheduler, controller-manager와 같은 컨트롤 플레인 구성요소는 잠시 다운된다.
마스터 노드가 다운되어도 워커 노드와 클러스터 내의 응용 프로그램이 영향을 받는 것은 아니다.
워커 노드에 호스팅된 모든 워크로드들은 마스터와 함께 중단된 관리 기능에 영향을 받지 않고, 정상적으로 사용자에게 서비스를 제공한다.
그러나 kubectl 또는 apiserver를 통해 클러스터에 액세스 할 수 없다. 또한 새 애플리케이션을 배포하거나 기존 애플리케이션을 수정 또는 삭제할 수 없다.
controller-manager도 작동하지 않고, 파드에 문제가 발생해도 새 파드가 자동으로 생성되지 않는다.
업그레이드가 완료되고 클러스터 백업이 복구되면 모든 구성요소가 정상적으로 작동해야 한다.
이제 마스터 노드와 컨트롤 플레인 컴포넌트의 버전은 1.11, 워커 노드의 버전은 1.10이 되었다.
2) 워커 노드
워커노드 업그레이드에는 다양한 전략이 있다.
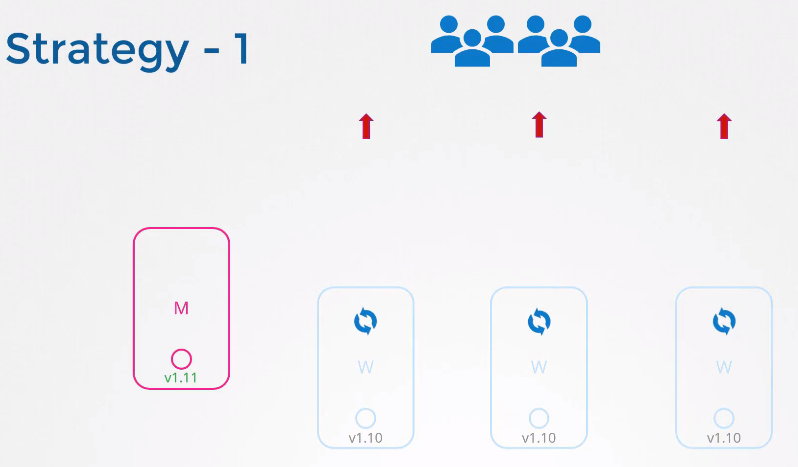
하지만 이 전략은 파드가 다운되면 사용자가 애플리케이션에 접근할 수 없다는 단점이 있다.
업그레이드가 완료되어야 노드가 백업되고, 새 파드가 스케줄링되어 사용자가 다시 애플리케이션에 액세스 할 수 있다.
마스터가 업그레이드 된 후, 노드들은 업그레이드를 기다리는 상태가 된다.
첫 번째 노드를 업그레이드 하면 노드 내의 작업들이 다른 워커 노드로 이동하고 서비스된다.
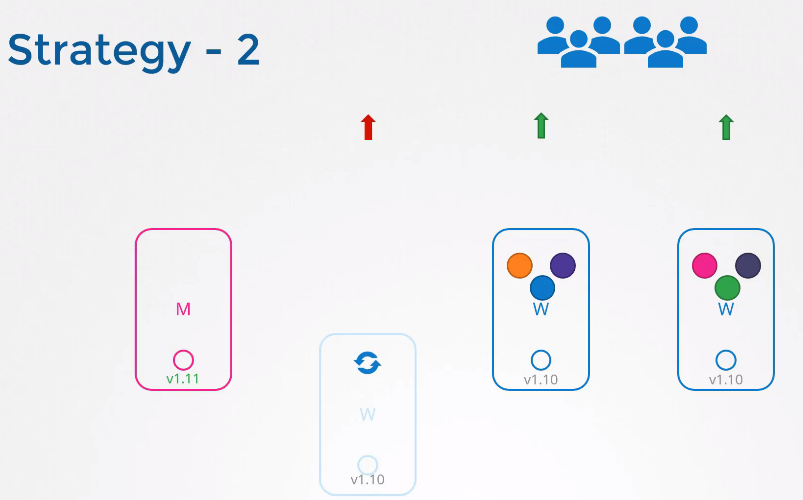
첫 번째 노드의 업그레이드 이후 이전 상태가 복구되면 다음 노드가 업그레이드 된다.
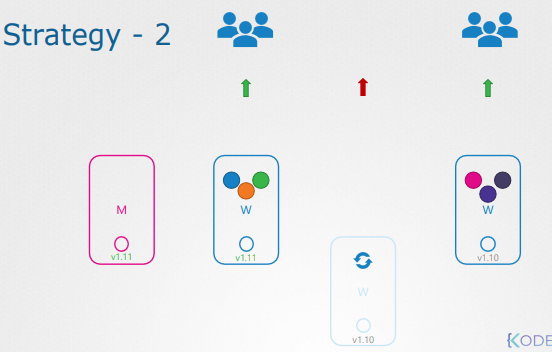
두 번째 노드를 업데이트 하기 위해 노드 내 작업들이 다른 노드로 이동한다.
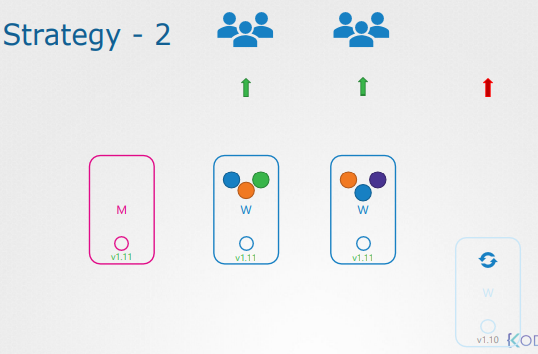
두 번째 노드의 백업 복구 이후 세 번째 노드의 업그레이드가 진행된다.
모든 노드의 업그레이드가 종료되면 마스터 노드와 워커 노드가 모두 동일하게 1.11 버전으로 업그레이드 된 것을 확인할 수 있다.
편하게 새 노드를 프로비저닝하고, 오래된 노드를 제거할 수 있는 클라우드 환경에서 특히 편리한 방법이다.
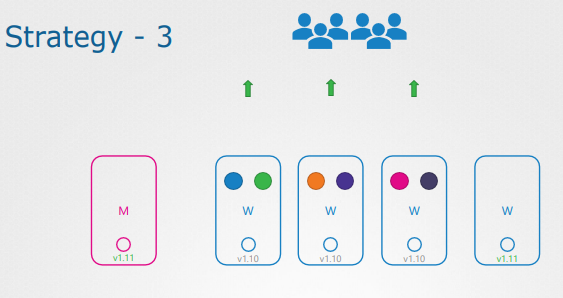
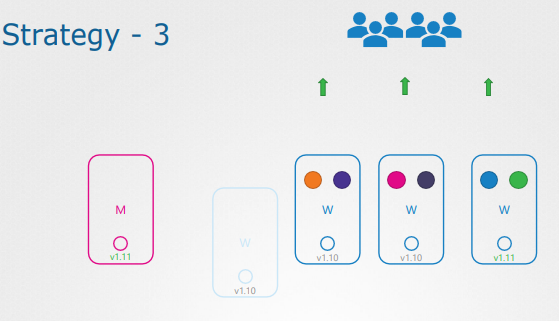
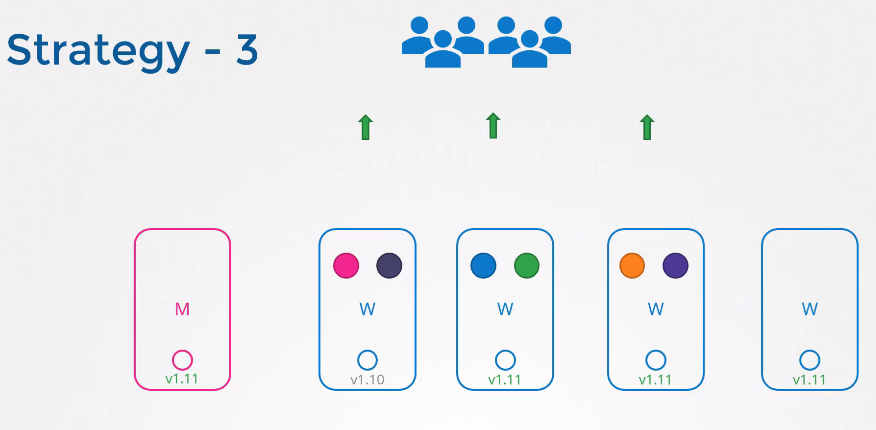
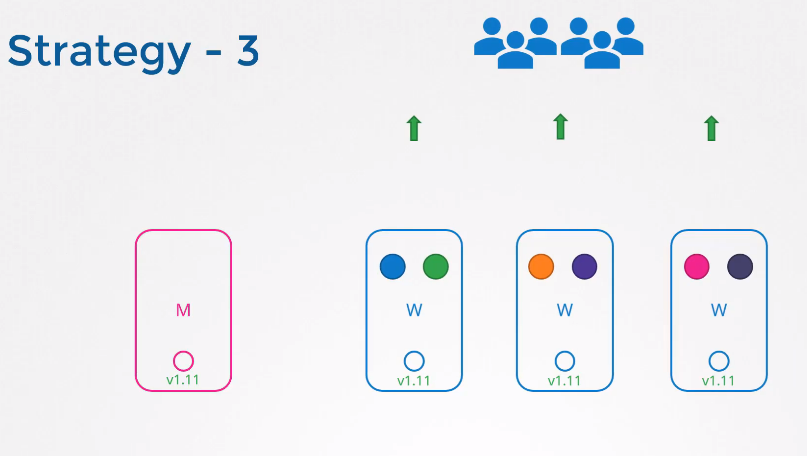
새 소프트웨어 버전의 노드를 클러스터에 추가하여 오래된 노드의 워크로드를 옮긴 후 노드를 제거하면 최종적으로 업그레이드 된 노드만이 남게 된다.
