Section 3: Scheduling
1주차 Day 5에 이어지는 내용입니다.
🎶 Taints and Tolerations vs Node Affinity
앞선 강의에서 Taint & Toleration과 Node Affinity를 배웠으니 두 개념을 연결해보자!
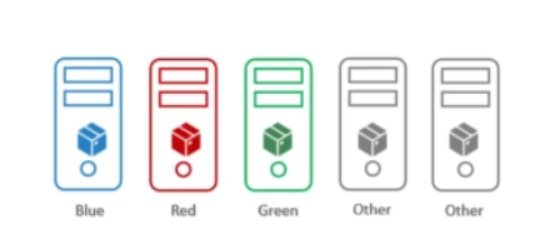
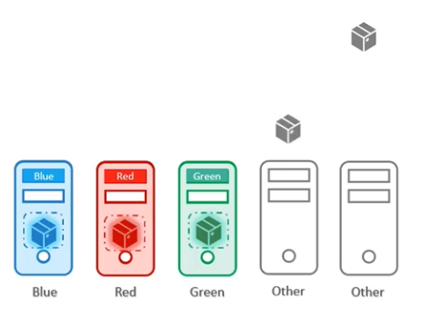
세 가지 색상의 노드와 파드가 있다.
우리가 연습할 것은 노드와 파드의 색을 일치시키는 것이다.
즉, 클러스터 내 3개의 노드에 다른 색의 파드가 배치되지 않게 하고, 파드가 다른 색 노드에 배치되지 않게 하는 것이 목표이다.
1) Taints and Tolerations
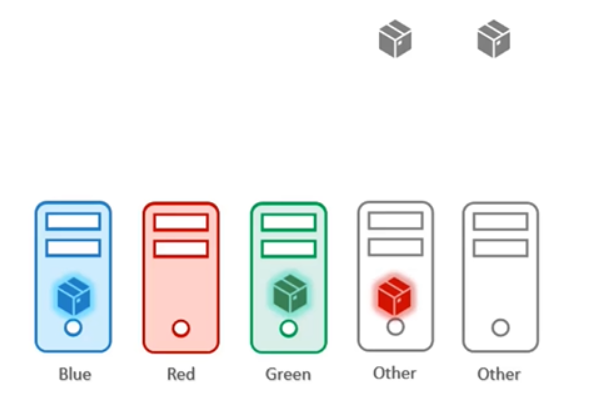
먼저 Taint와 Toleration을 사용해 목표를 달성해보자!
파란색, 빨간색, 녹색으로 노드에 taint를 적용한 다음, 색상에 맞는 파드가 허용되도록 파드에 toleration을 설정한다.
이제 파드가 생성되면 노드는 해당 노드에 대한 toleration을 가진 파드만 수용할 것이다.
그러나 taint와 toleration은 파드가 같은 색 노드만 선호할 것이라는 보장은 할 수 없다.
따라서 빨간색 파드는 taint가 설정되지 않은 노드에 배치될 수 있으므로 목표를 달성할 수 없다.
2) Node Affinity
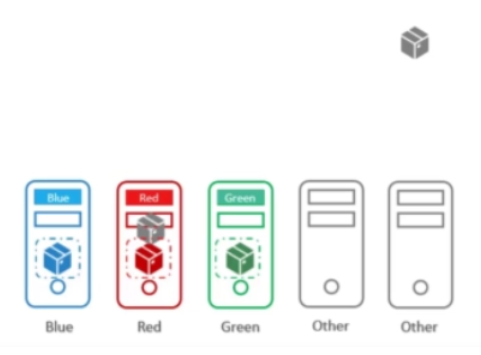
Node affinity를 사용해 문제를 해결해보자!
Node Affinity를 사용해 해당 색상(color=색상)으로 노드에 레이블을 지정한다.
그리고 파드에 Node Selector를 설정하여 파드를 같은 색상의 노드와 연결한다.
이렇게 하면 색이 있는 파드들은 알맞은 노드에 배치될 것이다. 그러나 색이 없는 파드가 색이 있는 노드에 배치되지 않는다는 보장은 없다.
Node Affinity를 사용하는 것도 목표를 달성할 수 없다.
파드 배치 규칙 설정!
따라서 taint, toleration 및 Node Affinity 조합을 함께 사용하여 특정 파드에 대해 전용 노드를 설정할 수 있다.
1) non-color 파드가 color 노드에 배치되지 못하게 하자!
먼저 taint와 toleration을 사용하여 다른 파드가 노드에 배치되지 않도록 한다.
2) color 파드가 non-color 노드에 배치되지 못하게 하자!
Node Affinity를 사용해 파드가 다른 노드에 배치되지 않도록 한다.
💥 Resource Requirements & Limits
쿠버네티스 클러스터에 3개의 노드가 존재한다. 각 노드에는 사용 가능한 CPU, 메모리, 디스크 리소스 모음이 있다.
모든 파드는 실행을 위해 요구되는 리소스 집합이 존재한다. 파드는 노드에 배치될 때마다 해당 노드에서 사용할 수 있는 리소스를 소비한다.
파드는 쿠버네티스 스케줄러에 의해 알맞은 노드에 배치되는데, 이때 스케줄러는 파드에 필요한 리소스와 노드에서 사용 가능한 리소스 양을 고려한다.
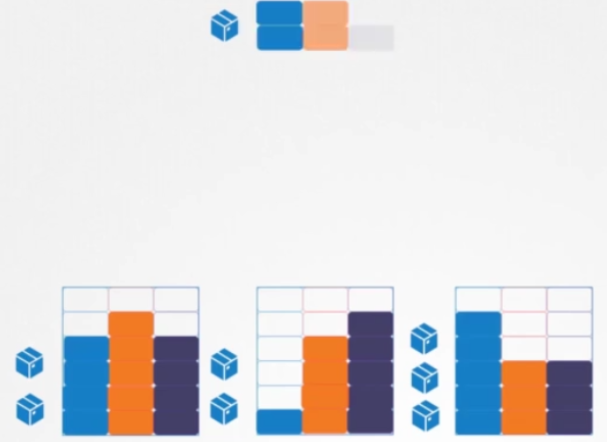
위의 상황에서 스케줄러는 2번 노드에 새 파드를 배치해야 한다. 노드에 충분한 리소스가 없으면 스케줄러는 해당 노드에 파드를 배치하지 않는다.
만약 노드의 리소스가 충분하지 않은 경우 쿠버네티스는 파드 예약을 보류하여 파드가 Pending 상태가 된다.
Resource Requests
기본적으로 쿠버네티스는 파드 또는 파드 내 컨테이너가 실행되기 위해 0.5 CPU와 메모리 256Mi가 필요하다고 가정한다.
아닌 것 같다..!
이는 컨테이너에 요청되는 최소 CPU, 메모리 양을 의미하며, 컨테이너에 대한 리소스 요청이라고 한다.
스케줄러는 파드를 노드에 배치하기 위해 리소스 요청량을 확인하여 리소스 가용량이 충분한 노드를 식별한다.
파드의 리소스 요청량을 변경하기 위해 구성 파일을 수정할 수 있다.
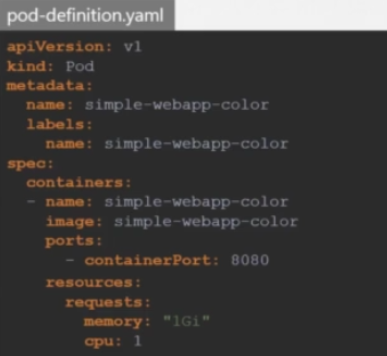
0.5 CPU를 1 CPU로, 256Mi 메모리를 1Gi로 증가시켰다.
Resource - CPU
꼭 CPU를 0.5 단위로 증가, 감소시킬 필요는 없다!
0.1처럼 작은 값도 지정할 수 있고, 0.1 CPU는 100m로 표시할 수 있다.

노드에 충분한 리소스가 있는 경우 컨테이너의 CPU 리소스 요청을 더 증가시킬 수 있다.
Resource - Memory
메모리 리소스의 단위는 1KiB, MiB, GiB로, 바이트 단위로 나타낼 수 있다.
MB와 MiB, GB와 GiB는 다른 단위이다.
- (1000 * 1000) KB = 1000MB = 1GB
- (1024 * 1024) KiB = 1024MiB = 1GiB
Resource Limits
도커의 컨테이너는 노드에서 사용 가능한 리소스에 제한이 없다.
컨테이너가 1 CPU로 실행되어도 그 이후에 노드나 다른 컨테이너가 실행될 수 없을만큼 많은 리소스를 소비할 수 있다는 의미이다.
그러나 쿠버네티스 파드는 리소스 사용량에 대한 제한을 설정할 수 있다.
기본적으로 쿠버네티스는 컨테이너의 CPU 제한을 1 vCPU로 설정해두었다. 따라서 명시적으로 지정하지 않으면 컨테이너는 노드에서 1 vCPU까지만 사용하도록 제한된다.
마찬가지로 쿠버네티스는 컨테이너의 메모리 제한도 512 MiB로 설정해두었다.
기본 제한을 변경하려면 파드 구성 파일의 resources 섹션 아래에 limits 섹션을 추가하여 변경할 수 있다.
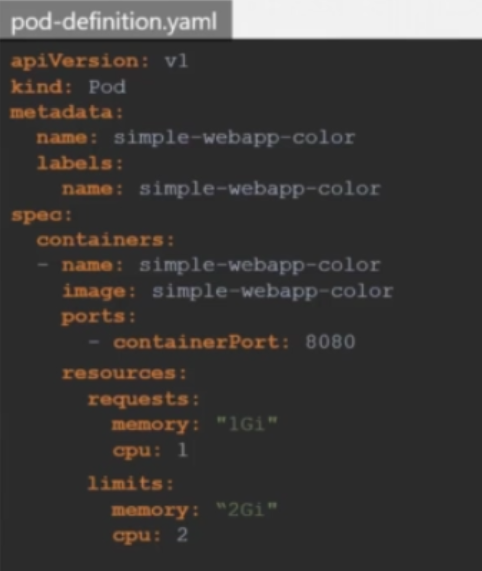
위 구성 파일과 같이 파드 내 각 컨테이너마다 CPU와 메모리의 request와 limit을 지정할 수 있다.
Exceed Limits
그렇다면 파드가 제한된 리소스를 초과하여 사용하려 하면 어떻게 될까?
CPU의 경우 쿠버네티스가 제한된 CPU 리소스를 초과하지 않도록 조절해주기 때문에 컨테이너는 제한보다 더 많은 CPU 리소스를 사용할 수 없다.
그러나 메모리의 경우 컨테이너가 제한된 양보다 더 많은 메모리 리소스를 사용할 수 있다. 따라서 파드가 지속적으로 메모리 리소스를 초과하여 사용하려고 하면 파드가 종료된다.
🔄 Edit a POD
이미 생성된 파드의 내용은 몇 가지 항목 외에는 수정할 수 없다.
- spec.containers[*].image
- spec.initContainers[*].image
- spec.activeDeadlineSeconds
- spec.tolerations
만약 파드 내용을 수정하고자 한다면 두 가지 방법이 존재한다.
파드 수정 방법
1) kubectl edit pod <pod name>
edit 명령을 실행하면 vi 편집기에서 pod의 구성 파일이 열리며 수정할 수 있다.
그러나 파일을 저장하려고 하면 편집할 수 없는 파드의 필드를 편집하려 하기 때문에 요청이 거부된다. 그 대신 /tmp/ 경로에 저장하려 했던 파드 구성 파일이 임시저장 된다.
이제 파드를 삭제하고 임시저장된 파일로 새 파드를 생성한다.
kubectl delete pod <pod name>
kubectl create -f /tmp/<pod definition file name>2) Kubectl get pod <pod name> -o yaml > <new pod definition file name>
yaml 형식의 파드 구성 파일을 추출하여 vi 편집기로 구성 파일을 수정한다.
이제 기존 파드를 삭제하고, 편집된 구성 파일로 새 파드를 생성한다.
🗄 DaemonSets
DaemonSet은 ReplicaSet, Deployment와 같이 pod의 여러 인스턴스를 배포하는데 도움을 주는 오브젝트이다.
DaemonSet을 통해 배포되는 파드들은 노드마다 하나씩 배포된다. 또한 클러스터에 노드가 새로 추가될 때마다 해당 노드에 새 파드를 자동으로 배포한다.
DaemonSet의 역할은 파드 인스턴스를 클러스터의 모든 노드에 항상 존재하게 하는 것이다.
사용 사례
Monitoring Solution, Log Viewer 배포
데몬셋은 모니터링, 로깅 등을 위해 클러스터 내의 상태 변화(노드 생성)에 따라 모니터링 도구와 로그 수집기를 배포해준다.
kube-proxy
쿠버네티스 클러스터 내의 모든 파드들의 통신을 위해 노드마다 kube-proxy를 파드 형태로 배포해주는 것도 데몬셋이 해준다.
Networking
Vivenet과 같은 네트워킹 솔루션은 클러스터 내 각 노드에 배포되어야 하는데 이 또한 데몬셋이 해준다.
DaemonSets - Definition
데몬셋을 만드는 방법은 레플리카셋과 유사하다.
kind 항목에 ReplicaSet이 아닌 DaemonSet을 적어주면 된다.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: monitoring-daemon
labels:
app: nginx
spec:
selector:
matchLabels:
app: monitoring-agent
template:
metadata:
labels:
app: monitoring-agent
spec:
containers:
- name: monitoring-agent
image: monitoring-agent- 생성
kubectl create -f daemon-set-definition.yamlView DaemonSets
- DaemonSet 조회
kubectl get daemonsets
- 더 자세한 데몬셋 조회
kubectl describe daemonsets 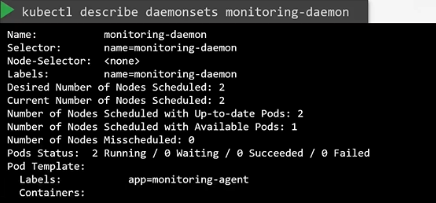
데몬셋 작동 원리
- 데몬셋은 어떻게 각 노드에 파드를 스케줄링 할까?
- 데몬셋은 어떻게 모든 노드에 파드가 배포되어 있는지 확인할까?
쿠버네티스 버전 1.12 까지는 파드가 생성되기 전 각 노드 이름을 속성으로 가지고 있었다. 그래서 파드가 생성되면 속성에 지정된 노드에 배포되었다.
현재 쿠버네티스 버전에서는 앞에서 배웠던 NodeAffinity와 default scheduler를 사용하여 파드를 스케줄링한다.
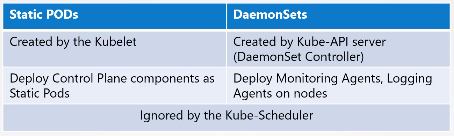
🔲 Static Pods
kubelet은 kube-apiserver에 의존해 노드에 어떤 오브젝트를 할당할지 지시를 내린다.
이 지시는 etcd 데이터 저장소에 저장된 kube scheduler의 결정에 의한 것이다.
- 그렇다면 kube-apiserver와 kube scheduler가 없다면 어떻게 될까?
- 컨트롤러나 etcd 클러스터가 없다면?
- 마스터 노드가 존재하지 않는다면?
- 다른 워커 노드가 없다면?
kubelet은 노드를 각각 관리할 수 있고, 노드에는 kubelet과 docker가 설치되어 있기 때문에 컨테이너를 실행시킬 수 있다.
kubelet은 스스로 파드를 생성할 수 있지만 파드의 상세 정보를 제공하는 apiserver가 없다.
kube-apiserver 없이 파드 정의 파일을 kubelet에 어떻게 제공할까?
파드에 대한 정보를 저장하도록 지정된 서버의 디렉터리에서 파드 구성 파일을 읽도록 kubelet을 구성할 수 있다!
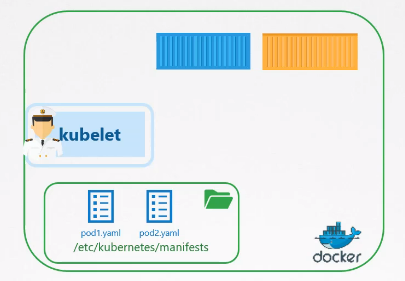
이 디렉터리에 파드 구성 파일을 저장하고, kubelet이 주기적으로 디렉터리를 확인하여 파드를 생성하게 하면 된다.
디렉터리 내의 구성 파일이 변경되면 kubelet은 업데이트를 인식하여 파드를 다시 만들고, 디렉터리에서 구성 파일이 삭제되면 해당 파일로 생성된 파드는 자동으로 삭제된다.
이처럼 apiserver나 쿠버네티스 클러스터 구성요소의 개입 없이 kubelet이 스스로 만든 파드를 Static Pod라고 한다.
그러나 이 방법으로는 오직 Pod만 생성할 수 있다.
레플리카셋이나 디플로이먼트, 서비스 등은 디렉터리 내에 구성 파일이 있어도 생성되지 않는다. 파드를 제외한 나머지 오브젝트들은 컨트롤러 같은 클러스터 구성요소가 있어야 생성할 수 있다.
kubelet은 파드 수준에서 동작하기 때문에 Static pod를 생성할 수 있는 것이다.
그렇다면 지정된 폴더는 무엇이며 어떻게 구성할 수 있을까?
kubelet.service 파일을 수정하여 디렉터리의 경로를 지정할 수 있다.
1) --pod-manifest-path 옵션
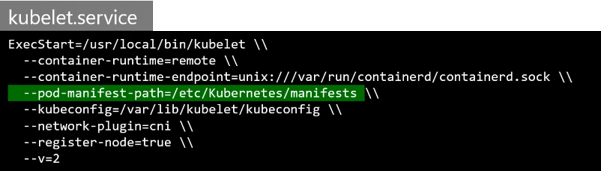
호스트(워크 노드)에 있는 어떤 디렉터리든지 지정할 수 있으며, --pod-manifest-path라는 옵션으로 경로를 지정할 수 있다.
2) --config 옵션에 다른 구성 파일을 지정하고, 그 구성 파일에 경로 설정

kube admin 도구로 만들어진 클러스터는 이 방법을 사용한다.
kubelet.service 파일에서 직접 옵션을 지정하는 대신, config 옵션을 사용하여 다른 config 파일에 대한 경로를 제공하고 파일에서 디렉터리 경로를 staticPodPath 속성으로 정의할 수 있다.
따라서 Static Pod를 생성할 때에는 클러스터 오브젝트를 만들 때 사용했던 방법과 관계없이
kubelet.service의 옵션을 확인해야 한다는 것을 기억하자!
Static Pod 매니페스트 확인
- 먼저 kubelet.service 파일의 옵션에서 파드의 매니페스트 경로를 확인한다.
- 경로를 확인할 수 없다면
--config옵션을 찾아 구성 파일로 사용되는 파일을 확인한다. - 해당 구성 파일 내에서 Static pod의 경로를 찾을 수 있다.
Static pod 확인
docker ps
왜 kubectl 인터페이스를 사용할 수 없는걸까?
kubectl 유틸리티는 kube-apiserver를 통해 작동하기 때문에 docker 명령어를 사용해야 한다.
apiserver가 존재할 때 kubelet은 동시에 두 가지 파드를 만들 수 있다.
- apiserver의 파드 (apiserver를 통해 전달된 파드 요청)
- static pod (kubelet이 설정한 경로에 존재하는 파드 매니페스트 파일)
apiserver는 kubelet이 생성한 static pod를 인식한다.
마스터 노드에서 kubectl 명령으로 파드를 출력하면 static pod도 다른 파드와 똑같이 출력된다.
다만 kube-apiserver가 인식한 파드는 다른 파드처럼 편집하거나 삭제할 수 없고, kubelet에 설정된 경로에 존재하는 매니페스트 내용을 수정, 삭제해야 한다.
static pod를 사용하는 이유
static pod는 쿠버네티스 컨트롤러에 의존하지 않기 때문에 노드의 컨트롤러 파드를 static pod로 생성해 컨트롤러를 각 노드에 배포할 수 있다.
과정
1) 쿠버네티스 클러스터 내의 모든 컨트롤 플레인에 kubelet을 설치한다.
2) 다양한 컨트롤 플레인 구성요소를 파드 정의 파일로 만든다.
3) 지정된 매니페스트 디렉터리에 정의 파일을 넣어 kubelet이 구성요소들을 생성하게 한다.
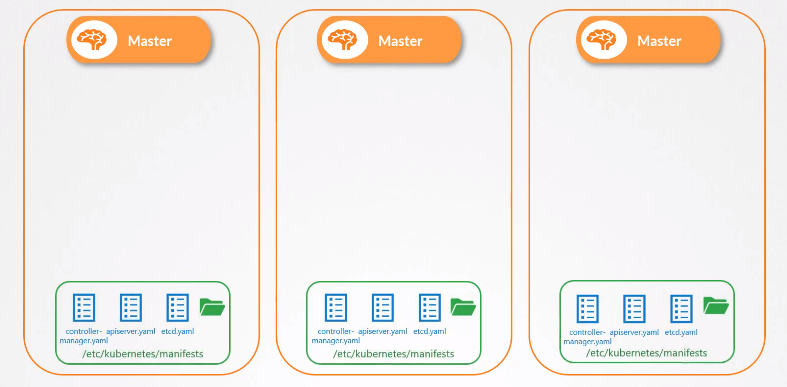
만약 구성요소에 문제가 발생하면 kubelet이 자동으로 재시작 해준다.
kube admin tool은 이러한 방법으로 쿠버네티스 클러스터를 구성한다.
그래서 kube-system 네임스페이스에 존재하는 파드를 출력하면 컨트롤 플레인 구성요소를 볼 수 있는 것이다.
Static Pods vs DaemonSets