
Section 3: Scheduling
Section 2에서는 스케줄러 설치 방법과 구성에 대해 간단히 살펴보았다면, Section 3에서는 스케줄링과 관련된 다양한 개념을 살펴볼 것이다.
커스터마이징에 사용할 수 있는 다양한 옵션들과 스케줄러의 동작을 구성하는 방법을 자세히 살펴보자!
📓 Manual Scheduling
내장된 스케줄러에 의존하는 대신 파드를 직접 스케줄링 하고자 한다.
간단한 파드 구성 파일부터 확인해보자.
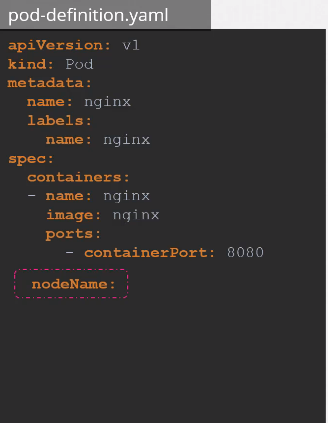
파드를 생성할 때 nodeName 필드값을 지정할 수 있다.
우리는 파드 구성 파일을 작성할 때 nodeName 항목 값을 지정하지 않아도 된다. 쿠버네티스가 자동으로 추가해주기 때문이다.
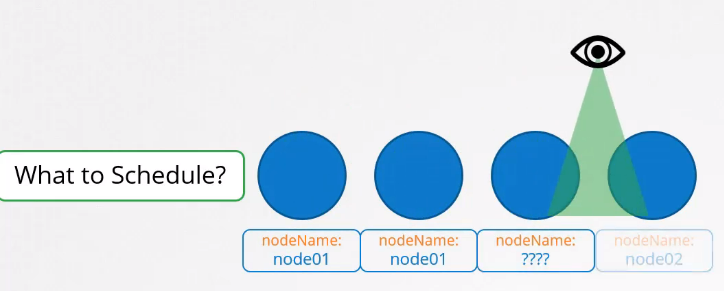
스케줄러는 모든 파드를 확인해 nodeName 속성이 지정되지 않은 파드를 찾아 스케줄링 대상 목록에 추가한다.
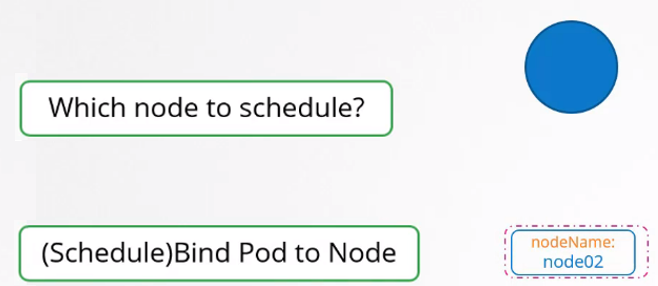
그리고 스케줄링 알고리즘을 실행해 적절한 노드를 찾아 해당 노드에 파드를 스케줄링한다. 스케줄링 할 때 Binding 오브젝트를 생성해 파드의 nodeName 속성을 설정한다.
클러스터 내에 노드를 모니터링, 스케줄링 하는 스케줄러가 없다면 어떻게 해야할까?
파드는 스케줄링되지 못해 Pending 상태로 스케줄링을 기다릴 것이다. 이 경우 직접 노드를 선택해 파드를 할당할 수 있다.
1) nodeName 항목값 설정
스케줄러 없이 파드를 스케줄링하는 가장 쉬운 방법은 파드의 구성 파일에 nodeName을 지정하는 것이다.
파드는 지정된 노드에 할당되며, nodeName은 생성 시에만 지정할 수 있다. 쿠버네티스는 파드가 생성된 후에는 nodeName을 변경하지 못하게 한다.
2) Binding 오브젝트

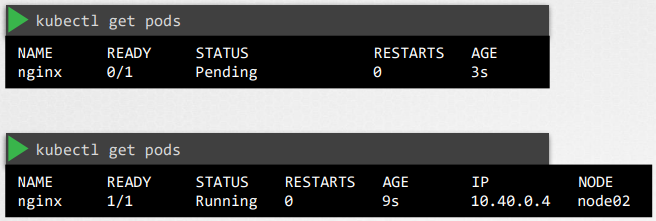
이미 생성된 파드가 스케줄링 될 노드를 선택하기 위해서는 바인딩 오브젝트를 사용하면 된다.
바인딩 오브젝트를 생성하여 바인딩 API에 POST 요청을 보내면 된다.

POST 요청을 보낼 때 yaml 파일의 내용을 JSON 형식으로 바꿔줘야 한다.
이 방식은 실제로 스케줄러가 수행하는 작업을 따라한 것이다.
🔖 Labels & Selectors
라벨과 셀렉터는 오브젝트를 그룹으로 묶어주는 대표적인 방법이다.
다양한 종의 동물들을 다양한 기준(클래스, 종류, 색 등)에 따라 그룹화, 필터링하고자 한다면 정확히 그 기준에 따라 선별해낼 수 있는 기능이 필요하다.
이를 수행하는 가장 좋은 방법은 Label을 사용하는 것이다.
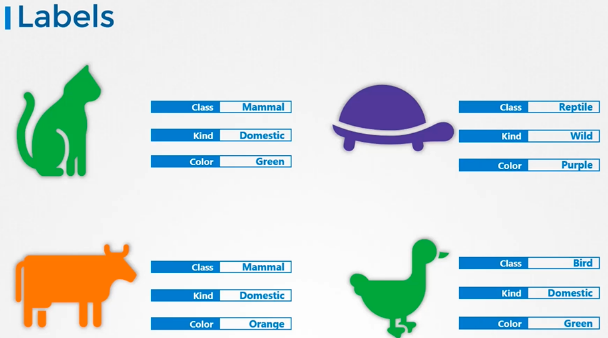
- Labels
라벨은 각 항목에 부착된 속성이며, 클래스, 종류, 색상에 대한 속성을 각 항목에 추가한다.
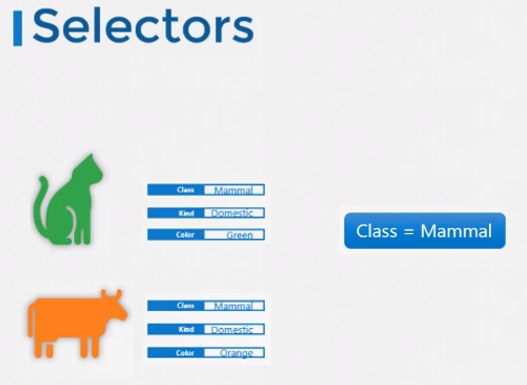
- Selectors
셀렉터는 항목들을 필터링하는 것을 도와준다.
예를 들어, 클래스가 포유류인 동물을 필터링하면 포유류인 동물의 목록이 추출된다.
또한 색상은 녹색이라고 하면 녹색 포유류가 필터링된다.
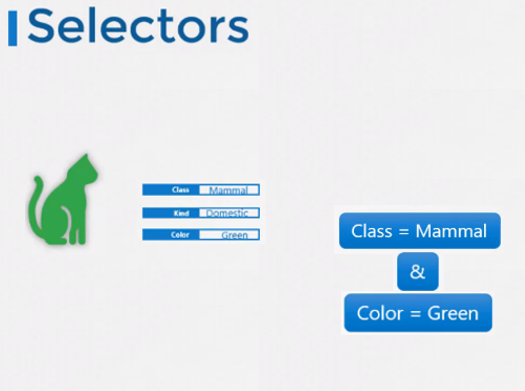
라벨과 셀렉터는 유튜브 비디오, 블로그의 태그 키워드 또는 온라인 스토어의 아이템 필터링 등에서 볼 수 있다.
🙄 쿠버네티스에서는 라벨과 셀렉터를 어떻게 사용할까?
쿠버네티스의 파드, 서비스, 레플리카셋, 디플로이먼트 등 다양한 오브젝트를 생성해봤다.
시간이 흐르면 이런 오브젝트가 수백, 수천 개가 될 수 있다. 그러면 많은 오브젝트들을 타입, 애플리케이션, 기능 등 다양한 범주별로 그룹화하고 필터링할 수 있는 방법이 필요하다.
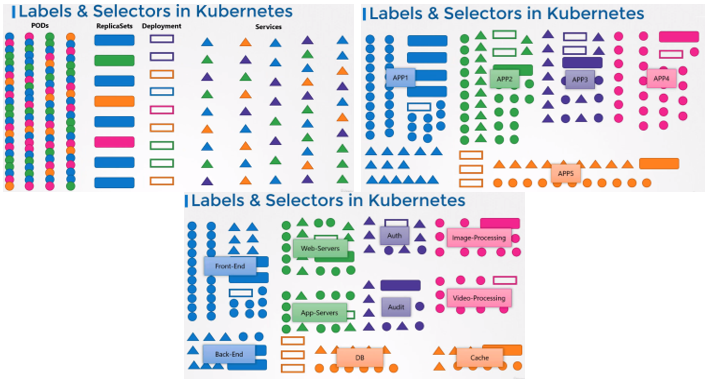
그 방법이 바로 label과 selector를 사용하는 것이다!
label과 selector를 사용하여 각 오브젝트에 대해 라벨을 붙여 그룹화하고, 선택할 수 있다. 그리고 선택 시 특정 오브젝트를 필터링할 조건을 지정할 수 있다.
Labels
라벨 설정 방법
라벨을 지정하는 방법은 파드의 구성 파일 내 metadata 의 하위 항목에 labels 항목을 생성하여 지정하면 된다.
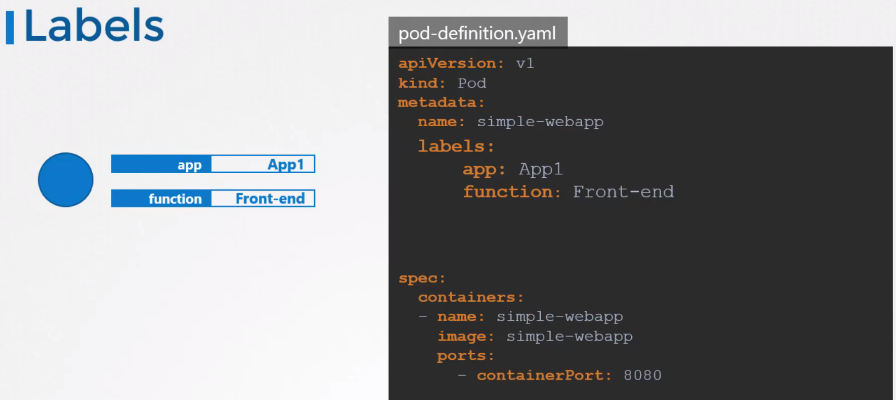
지정한 레이블로 파드를 선택하기 위해 --selector 옵션을 사용한다.
kubectl get pods --selector app=App1
라벨 사용
1) 레플리카셋이 관리할 파드를 찾을 때

레플리카셋은 라벨에 관한 정보를 두 가지 가지고 있다.
metadata->labels
하나는 레플리카셋 오브젝트 자체의 라벨인 metadata의 labels인데, 지금은 이 항목에 대해 관심을 갖지 않아도 된다.
spec->selector->matchLabels
다음은 레플리카셋이 관리할 파드를 찾는 용도로 사용하는 라벨인 matchLabels이다.
레플리카셋은 이 라벨들이 붙어있는 파드를 인식하고 상태와 개수를 관리하기 위해 라벨을 사용한다.
만약 레플리카셋이 관리하는 여러 개의 파드가 다른 범주로 분류될 경우 여러 개의 라벨을 지정하여 레플리카셋이 발견할 수 있게 할 수 있다.
2) 서비스가 부착될 오브젝트를 찾을 때
서비스가 생성되면 서비스의 구성 파일에 정의된 selector를 사용하여 레플리카셋의 matchLAbels에 해당하는 라벨을 선택한다.
그러면 레플리카셋이 관리하는 파드에 서비스가 제공된다.
Annotations
라벨과 셀렉터는 오브젝트를 그룹화하고 선택하는데 사용되는 반면, 주석은 정보 제공 목적으로 기타 세부 정보를 기록하는데 사용된다.

예를 들어 이름, 버전, 빌드 정보 등의 세부 정보 기록이나 연락처, 전화번호, 이메일 등 통합을 위한 목적으로 사용한다.
Taints and Tolerations
사람과 벌레로 비유하여 taint와 tolertaion이 무엇인지 이해해보자.
벌레가 사람에게 붙는 것을 막기 위해 벌레 스프레이를 뿌린다. 여기서 벌레 스프레이는 taint를 의미한다.
벌레는 벌레 스프레이를 견딜 수 없기 때문에 사람에게 다가올 수 없다.
그러나 스프레이에 내성이 있는 다른 벌레가 있을 수 있다. 그 벌레에게는 taint의 효과가 없다는 것이다.
결국 내성이 있는 벌레는 사람에게 붙을 수 있다.
쿠버네티스에서 벌레는 파드이고, 사람은 노드이다.
taint와 toleration은 어떤 파드가 노드에 스케줄링 될 수 있는지에 대한 제한을 설정하는데 사용한다.
- Taint : 노드에 스케줄링 하지 않음
- Toleration : 파드가 노드에 스케줄링 될 수 있게 해줌
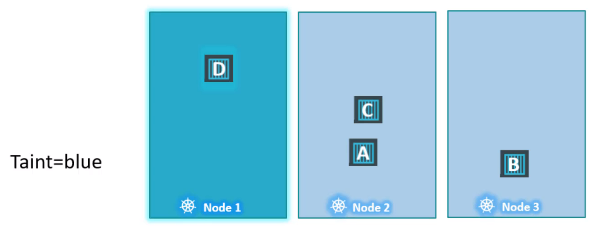
클러스터 내에 3개의 워커 노드와 노드에 배포할 파드 A, B, C, D가 있다.
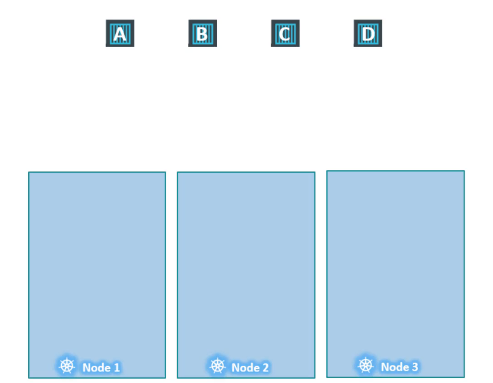
파드가 생성되면 쿠버네티스 클러스터는 생성된 파드를 워커 노드에 배포를 시도한다. 아무런 제한 설정이 없기 때문에 스케줄러는 모든 노드에 균형을 맞추어 파드를 할당한다.
이때 노드 1에 특정 애플리케이션을 위한 전용 리소스가 있다고 가정해보자.
노드 1에는 특정 애플리케이션에 속하는 파드만 배치하고자 한다.
노드 1에 taint를 배치하여 모든 파드가 그 노드에 배치되지 못하게 한다. 이 taint를 blue라고 할 것이다.
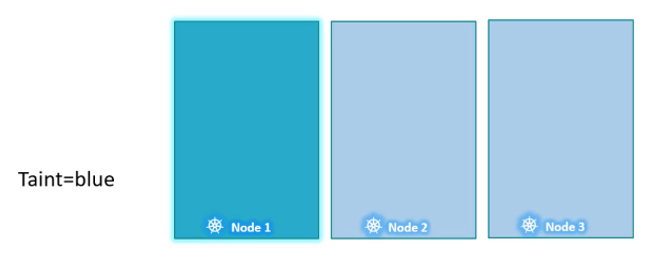
파드는 기본적으로 toleration을 가지고 있지 않기 때문에 따로 명시하지 않으면 어떠한 파드도 노드 1에 할당되지 못할 것이다.
이제 어떤 파드가 노드 1에 할당될 수 있을지 지정해야 한다. 우리는 파드 D만 노드 1에 배치될 수 있게 설정하고 싶다.
이를 위해서는 파드 D에 toleration을 추가하면 된다.
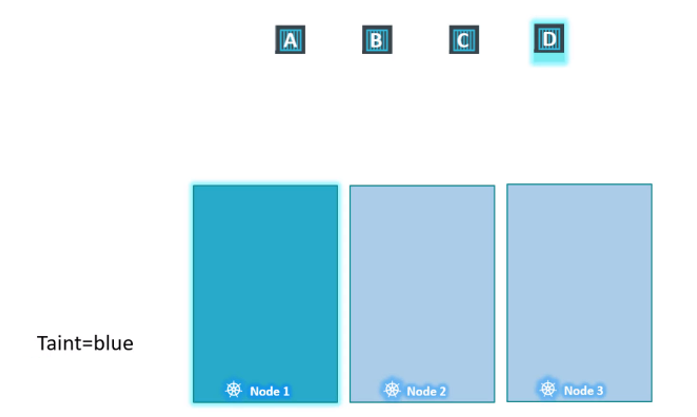
이제 모든 파드를 스케줄링 해보자.
스케줄러는 파드 A를 1번 노드에 스케줄링 하려하지만 taint로 인해 2번 노드에 파드 A를 할당한다.
다음 파드 B를 1번 노드에 스케줄링 하려다 실패하고 3번 노드에 파드 B를 할당한다.
마찬가지로 파드 C 또한 1번 노드에 스케줄링 되지 못해 2번 노드에 할당된다.
마지막으로 파드 D를 1번 노드에 스케줄링 하려할 것이고, 파드 D는 toleration을 가지고 있어 1번 노드에 할당될 수 있다.
그렇다면 Taint와 Toleration을 설정하는 방법은 무엇일까?
Taints
kubectl taint nodes node name key=value:taint-effectnode name: taint를 설정할 노드 이름key=value: app=blue와 같이 taint 조건을 설정taint-effect: 파드가 toleration을 갖고있지 않을 경우 발생하는 효과NoSchedule: toleration을 갖고 있지 않은 파드는 노드에 스케줄링 하지 않겠다!PreferNoSchedule: 노드에 스케줄링 하지 않는 것을 선호하지만, 결과는 보장할 수 없다.NoExecute: toleration이 없는 파드는 스케줄링 하지 않고, 이미 노드에 존재하는 파드가 toleration을 갖고있지 않으면 방출된다.
앞에서 설명했던 예시대로 taint를 설정하려면
kubectl taint nodes node1 app=blue:NoSchedule명령을 입력해야 한다.
Tolerations
파드에 toleration을 추가하기 위해서는 파드의 구성 파일 내용을 변경해야 한다.
구성 파일 spec의 하위 항목에 tolerations 속성을 추가한다.
taint를 생성했을 때 사용한 값과 동일하게 입력한다.
앞에서는 app=blue 라는 조건으로 taint를 설정했으므로, 구성 파일에도 동일한 조건으로 toleration을 입력해주면 된다.

tolerations: taint 조건에 적합하면 스케줄링 가능하도록 설정key: taint 조건의 key 값operator: taint 조건의 연산자value: taint 조건의 value 값effect: taint 조건의 효과
Taint - NoExcute
taint의 effect 종류 중 NoExcute에 대해 더 알아보자.
이번에는 taint 없는 3개의 노드에 파드 A, B, C, D가 실행되고 있다.
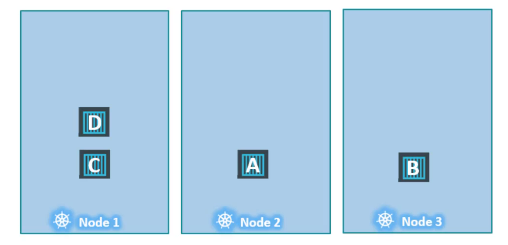
이때 1번 노드를 특정 애플리케이션 전용으로 사용하기로 결정되었다.
1번 노드에 애플리케이션에 대한 taint를 설정하고, NoExcute 효과를 지정했다. 그리고 파드 D에 taint에 대한 toleration을 추가해주었다.
taint가 작동하게 되면 파드 C는 노드에서 제외되어 죽게 된다.
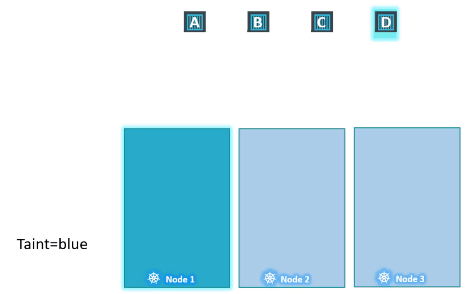
다시 파드를 스케줄링 하는 시점으로 되돌아 가보자.
taint와 toleration이 설정된 상황에서 1번 노드는 파드 D만 실행될 수 있는 노드이다.
그러나 파드 D가 무조건 1번 노드에 할당될 것이라는 보장은 할 수 없다. 다른 노드들에 taint가 설정되지 않았기 때문에 다른 노드에 할당될 수도 있다.
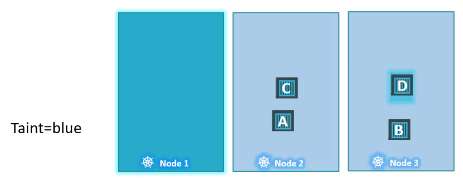
즉, taint는 파드를 특정 노드에 할당하기 위한 것이 아니고 노드가 특정 파드만 수용하게 하기 위한 것이다.
파드를 특정 노드에 할당하는 것이 요구될 경우에는 Node affinity를 사용해야 한다.
지금까지 이야기한 내용에서는 워커 노드만 언급되었다.
클러스터에는 마스터 노드도 존재하지만, 스케줄러는 마스터 노드에 오브젝트를 스케줄링하지 않는다.
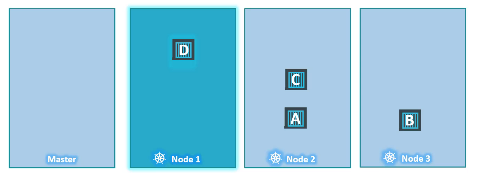
쿠버네티스는 클러스터가 구성되면 마스터 노드에 taint를 설정하여 스케줄링 대상 노드에서 제외시킨다.
마스터 노드는 파드를 호스팅하고, 모든 관리 소프트웨어를 실행하는 역할을 하기 때문이다.
- 마스터 노드에 설정된 taint 확인하기
kubectl describe node kubemaster | grep taint✅👈 Node Selectors
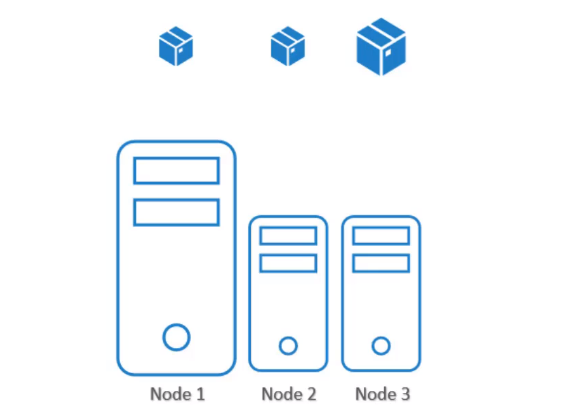
3개의 노드가 존재한다.
1번 노드는 다른 2개의 노드보다 큰 하드웨어 리소스를 가지고 있다.
데이터 처리 등 리소스 요구량이 큰 작업은 1번 노드에서 실행해야 한다. 다른 노드들보다 리소스 여유가 더 크므로 안정적인 실행이 가능할 것이다.
특정 노드에 파드 스케줄링 하기
현재는 모든 파드가 제한 없이 모든 노드에 스케줄링 될 수 있다.
이 경우 파드 C가 2, 3번 노드에 스케줄링 될 수 있는데, 문제를 해결하려면 특정 노드에 파드 C가 스케줄링 되도록 파드에 제한을 설정해야 한다.
1) Node Selectors

첫 번째 방법은 간단하고 쉬운 Node Selectors이다.
먼저 1번 노드에 스케줄링 할 파드의 구성 파일의 spec 하위 항목으로 nodeSelector를 추가해준다.
구성 파일의 size: Large는 무엇일까?
1번 노드의 size가 Large로 설정되어 있는 것이라 생각할 수 있겠지만 이것은 단지 라벨일 뿐이다.
데이터 처리 작업을 실행하는 파드를 생성하기 전, 먼저 노드에 size=Large 라는 라벨을 붙여주어야 한다.
노드 라벨링 방법 (Label Nodes)
kubectl label nodes <node-name> <label-key>=<label-value>위 명령으로 노드에 라벨을 붙여줄 수 있다.
우리는 kubectl label nodes node-1 size=Large 라고 입력하면 된다!
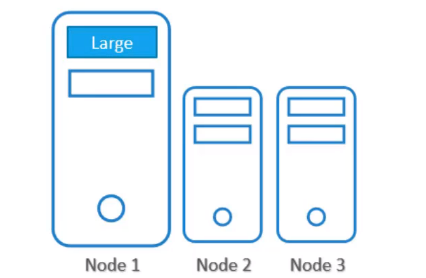
이제 노드에 라벨을 붙였으니 파드를 생성하면 된다.
kubectl create -f pod-definition.yml이제 파드 C가 1번 노드에 할당된 것을 확인할 수 있다.
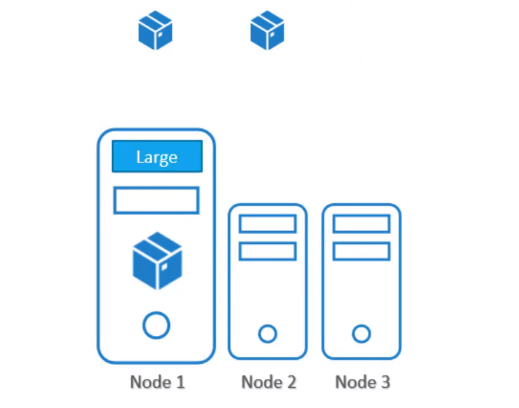
하지만 Node Selector의 경우 한계가 있다.
앞서 설명한 예시에서 라벨 1개와 selector를 사용했지만 만약 요구 사항이 훨씬 복잡하다면 어떨까?
"파드 C를 Large 또는 Medium 노드에 배치"하거나 "파드 B를 Small이 아닌 노드에 배치"하는 요구 사항이 발생하면 Node Selector로는 이를 만족할 수 없다.
Node Affinity
앞에서 Node Selector의 한계에 대해 알아봤다.
다음으로 더욱 복잡한 요구사항이 발생할 경우 사용할 수 있는 Node Affinity에 대해 알아볼 것이다.
Node Affinity 기능
Node Affinity는 advance expression을 제공한다.
사용 방법

파드 구성파일을 보면 node selector 보다 훨씬 복잡한 구성임을 확인할 수 있다.
affinitynodeAffinityrequiredDuringSchedulingIgnoreDuringExcutionnodeSelectorTermsmatchExpressions:key: label의 keyoperator:values에 지정된 값과 라벨의 관계 (???)values: 노드를 선택할 조건의 값 리스트 (여러 개 지정 가능)
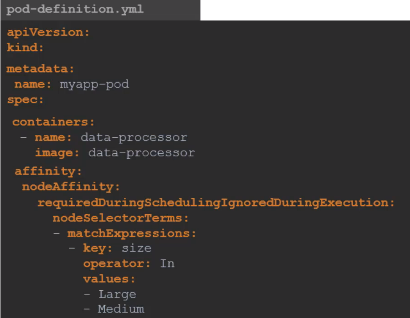
- size 라벨의 값으로 Large 또는 Medium을 가지고 있는 노드를 선택한다.
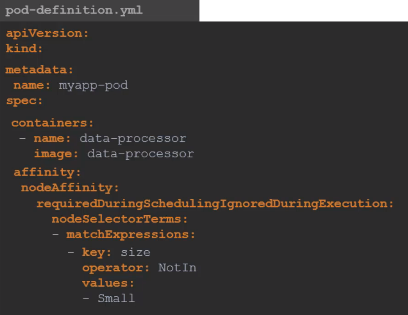
- size 라벨의 값으로 small을 가지지 않은 노드를 선택한다.
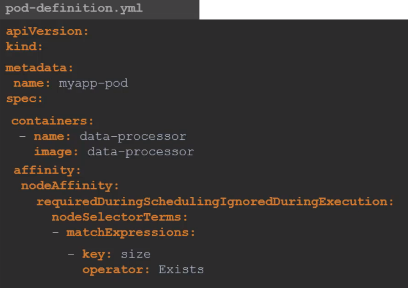
- size 라벨을 가진 노드를 선택한다.
만약 NodeAffinity의 조건과 일치하는 노드가 존재하지 않으면 어떻게 할까?
예를 들어, Large 노드에 파드를 배치하려 했는데 Large라는 라벨이 붙은 노드가 없는 경우 또는 파드가 이미 스케줄링 상태에서 노드의 레이블을 변경하는 경우에는 어떻게 되는 것일까?
이 대답은 NodeAffinity Type이 해줄 것이다.
NodeAffinity Type
현재 사용 가능한 NodeAffinity Type은 두 가지 이다.
Available Node Affinity Type
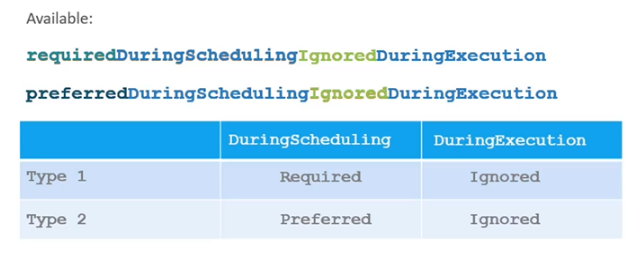
requiredDuringSchedulingIgnoreDuringExcutionpreferredDuringSchedulingIgnoreDuringExecution
추가적으로 계획중인 NodeAffinity Type도 존재한다.
Planned Node Affinity Type
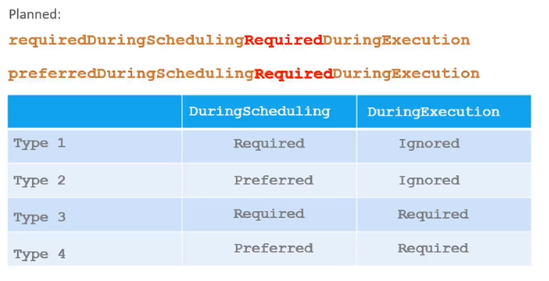
requiredDuringSchedulingRequiredDuringExecution
먼저 사용 가능한 타입에 대해 알아볼 것이다.
Pod Lifecycle
파드의 라이프사이클에는 두 가지 상태가 있다.
1) DuringScheduling
파드가 존재하지 않다가 처음 생성된 상태를 의미한다.
파드가 처음 생성되면 설정된 규칙에 따라 올바른 노드에 스케줄링 된다.
만약 설정된 규칙에 해당하는 노드가 없다면 어떻게 될까?
여기서 NodeAffinity Type이 적용된다.
requiredDuringSchedulingIgnoreDuringExcution
첫 번째 타입인 required를 선택하면 스케줄러는 지정된 Node Affinity를 사용하여 파드를 노드에 스케줄링하도록 지시한다.
노드를 찾을 수 없으면 파드가 스케줄링 되지 않는다. 이 타입은 파드의 배치가 중요한 경우 사용한다.
일치하는 노드가 없으면 파드가 생성되지 않는다.
preferredDuringSchedulingIgnoreDuringExecution
그러나 파드 배치가 작업을 수행하는 것보다 중요하지 않을 수 있다.
이 경우에는 Preferred를 선택하여 일치하지 않는 노드를 찾지 못했을 때 스케줄러가 Node Affinity를 무시하고 사용 가능한 노드에 파드를 스케줄링 한다.
일치하는 노드가 없으면 사용 가능한 노드에 파드를 스케줄링 한다.
2) DuringExecution
파드가 실행 중일 때 노드 라벨 변경과 같이 Node Affinity에 영향을 주는 변경이 발생한 상태이다.
예를 들어 관리자가 size=Large라는 라벨을 삭제했다고 가정해보자.
이 경우에는 어떻게 될까?
두 가지 NodeAffinity Type을 살펴보면 DuringExecution 값이 모두 Ignored로 설정되어 있다. 즉, 파드는 계속 실행되고 Node Affinity의 변경 사항은 파드가 실행되고 있는 상태에서는 영향을 주지 않는다.
이미 실행되는 파드에는 영향을 주지 않는다.
Planned Node Affinity Type은 DuringExecution 부분에서 차이가 있다.
RequiredDuringExecution 이라는 새 옵션은 Node Affinity의 변경에 따른 영향을 실시간으로 반영하여, Node Affinity를 충족하지 않는 노드에서 실행 중인 파드를 제거하는 옵션이다.
