
Stack의 정의
Stack은 쌓다, 쌓이다, 포개지다 와 같은 뜻을 가지고 있습니다. 마치 접시를 쌓아 놓은 형태와 비슷한 이 자료구조는 직역 그대로, 데이터(data)를 순서대로 쌓는 자료구조입니다. 일상생활에서 Stack과 비슷한 예를 찾아볼 수 있습니다:
다섯 대의 자동차가 순서대로 좁은 골목을 지나고 있습니다. 좁은 골목에 진입한 차량은 곧 맞이할 미래를 모르고 있지만, 이 골목의 끝은 막혀 있습니다. 첫 번째 자동차는 이 골목을 통과하기 위해 직진했고, 나머지 자동차도 앞 자동차의 꽁무니를 따라 직진했습니다. 그러나 첫 번째 차량이 막다른 길을 맞이했습니다. 마지막으로 들어온 다섯 번째 자동차가 먼저 후진하여 나와야 하는 상황이 되어버린 겁니다.
Stack의 구조
골목을 자료구조 Stack, 자동차는 데이터(data)로 비유할 수
이 그림에서 볼 수 있듯이, 가장 먼저 들어간 자동차는 가장 나중에 나올 수 있습니다. 다시 말해, 가장 나중에 들어간 자동차가 가장 먼저 나올 수 있습니다.
- 자료구조 Stack의 특징은 입력과 출력이 하나의 방향으로 이루어지는 제한적 접근에 있습니다.
- 이런 Stack 자료구조의 정책을 LIFO(Last In First Out) 혹은 FILO(First In Last Out)이라고 부르기도 합니다.
- Stack에 데이터를 넣는 것을 'PUSH', 데이터를 꺼내는 것을 'POP'이라고 합니다.
Stack의 특징
1. LIFO(Last In First Out)
먼저 들어간 데이터는 제일 나중에 나오는 후입선출의 구조를 가지고 있습니다.
예1) 1, 2, 3, 4를 스택에 차례대로 넣습니다.
stack.push(데이터)
1 <- 2 <- 3 <- 4
들어간 순서대로, 1번이 제일 먼저 들어가고 4번이 마지막으로 들어가게 됩니다.
예2) 스택이 빌 때까지 데이터를 전부 빼냅니다.
stack.pop()
4, 3, 2, 1
제일 마지막에 있는 데이터부터 차례대로 나오게 됩니다.
이러한 특성으로 인해 스택 구조는 조회가 필요하지 않으므로, 해당 자료구조를 사용해 데이터를 저장하고 검색하는 프로세스가 매우 빠르며, 최상위 블록에서 데이터를 저장하고 검색하면 된다는 장점이 있습니다.
-
데이터는 하나씩 넣고 뺄 수 있습니다.
Stack 자료구조는 데이터가 아무리 많이 있어도 하나씩 데이터를 넣고, 뺍니다. 한꺼번에 여러 개를 넣거나 뺄 수 없습니다. -
하나의 입출력 방향을 가지고 있습니다.
Stack 자료구조는 데이터의 입출력 방향이 같습니다. 만약, 입출력 방향이 여러 개라면 Stack 자료구조라고 볼 수 없습니다. -
저장되는 데이터는 유한하고 정적이어야 합니다.
스택이라는 자료 구조를 사용한 콜 스택(Call Stack)을 예시로 들어 설명하도록 하겠습니다. 콜 스택 내부에 함수의 실행 데이터는 스택의 프레임으로 저장됩니다. 각 프레임은 해당 기능에 필요한 데이터가 저장되는 공간 블록이라 이해하면 됩니다. 예를 들어, 함수가 새로이 변수를 선언할 때마다 스택의 최상위 블록으로 Push 됩니다. 그 다음 함수가 종료될 때마다 최상위 블록이 지워지므로(후입선출 구조이기 때문에), 해당 함수에 의해 스택에 들어간 모든 변수가 지워지게 됩니다. 여기에 저장된 데이터가 정적 특성을 가져야지만이 컴파일 시간이 결정됩니다. 스택에 저장되는 일반적인 데이터는 로컬 변수(value type 또는 프리미티브, 프리미티브 상수), 포인터 및 함수 프레임입니다. -
스택의 크기는 제한되어 있습니다.
힙(heap)에 비해 스택의 크기가 제한되어 있으므로, 스택 오버플로(Stack Overflow) 같은 에러가 자주 발생합니다. 대부분의 언어는 스택에 저장할 수 있는 값의 크기가 제한되어 있습니다.
이러한 특성으로 인해 스택 구조는 조회가 필요하지 않으므로, 해당 자료구조를 사용해 데이터를 저장하고 검색하는 프로세스가 매우 빠르며, 최상위 블록에서 데이터를 저장하고 검색하면 된다는 장점이 있습니다.
-
데이터는 하나씩 넣고 뺄 수 있습니다.
Stack 자료구조는 데이터가 아무리 많이 있어도 하나씩 데이터를 넣고, 뺍니다. 한꺼번에 여러 개를 넣거나 뺄 수 없습니다. -
하나의 입출력 방향을 가지고 있습니다.
Stack 자료구조는 데이터의 입출력 방향이 같습니다. 만약, 입출력 방향이 여러 개라면 Stack 자료구조라고 볼 수 없습니다. -
저장되는 데이터는 유한하고 정적이어야 합니다.
스택이라는 자료 구조를 사용한 콜 스택(Call Stack)을 예시로 들어 설명하도록 하겠습니다. 콜 스택 내부에 함수의 실행 데이터는 스택의 프레임으로 저장됩니다. 각 프레임은 해당 기능에 필요한 데이터가 저장되는 공간 블록이라 이해하면 됩니다. 예를 들어, 함수가 새로이 변수를 선언할 때마다 스택의 최상위 블록으로 Push 됩니다. 그 다음 함수가 종료될 때마다 최상위 블록이 지워지므로(후입선출 구조이기 때문에), 해당 함수에 의해 스택에 들어간 모든 변수가 지워지게 됩니다. 여기에 저장된 데이터가 정적 특성을 가져야지만이 컴파일 시간이 결정됩니다. 스택에 저장되는 일반적인 데이터는 로컬 변수(value type 또는 프리미티브, 프리미티브 상수), 포인터 및 함수 프레임입니다. -
스택의 크기는 제한되어 있습니다.
힙(heap)에 비해 스택의 크기가 제한되어 있으므로, 스택 오버플로(Stack Overflow) 같은 에러가 자주 발생합니다. 대부분의 언어는 스택에 저장할 수 있는 값의 크기가 제한되어 있습니다.
[그림] 브라우저의 뒤로 가기와 앞으로 가기 기능에 사용된 Stack
브라우저에서 자료구조 Stack이 사용될 때에는 다음과 같은 순서를 거칩니다.
1. 새로운 페이지로 접속할 때, 현재 페이지를 Prev Stack에 보관합니다.
2. 뒤로 가기 버튼을 눌러 이전 페이지로 돌아갈 때에는, 현재 페이지를 Next Stack에 보관하고 Prev Stack에 가장 나중에 보관된 페이지를 현재 페이지로 가져옵니다.
3. 앞으로 가기 버튼을 눌러 앞서 방문한 페이지로 이동을 원할 때에는, Next Stack의 가장 마지막으로 보관된 페이지를 가져옵니다.
4. 마지막으로 현재 페이지를 Prev Stack에 보관합니다.
이렇게 자료구조 Stack을 이용하면, 뒤로 가기와 앞으로 가기 버튼을 구현할 수 있습니다.
Queue의 정의
큐(Queue)는 줄을 서서 기다리다, 대기행렬 이라는 뜻을 가지고 있습니다. 어떤 구조로 되어 있는지 짐작할 수 있나요?
명절에는 고향으로 가기 위해 많은 자동차가 고속도로를 지납니다. 고속도로에는 톨게이트가 있고, 자동차는 톨게이트에 진입한 순서대로 통행료를 내고 톨게이트를 통과합니다.
톨게이트를 Queue 자료구조, 자동차는 데이터(data)로 비유할 수 있습니다.
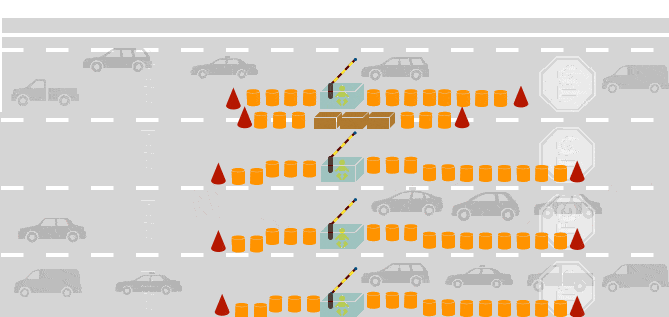
[그림] 자료구조 Queue는 순서대로 지나가는 자동차가 지나가는 톨게이트와 유사합니다.
이 그림에서 볼 수 있듯이 가장 먼저 진입한 자동차가 가장 먼저 톨게이트를 통과합니다. 다시 말해, 가장 나중에 진입한 자동차는 먼저 도착한 자동차가 모두 빠져나가기 전까지는 톨게이트를 빠져나갈 수 없다는 말입니다.
자료구조 Queue는 Stack과 반대되는 개념으로, 먼저 들어간 데이터(data)가 먼저 나오는 FIFO(First In First Out) 혹은 LILO(Last In Last Out) 을 특징으로 가지고 있습니다. 티켓을 사려고 줄을 서서 기다리는 모습과 흡사한 이 자료구조는 입력과 출력의 방향이 고정되어 있으며, 두 곳으로 접근이 가능합니다. Queue에 데이터를 넣는 것을 'enqueue', 데이터를 꺼내는 것을 'dequeue'라고 합니다.
자료구조 Queue는 데이터(data)가 입력된 순서대로 처리할 때 주로 사용합니다.
1. FIFO (First In First Out)
먼저 들어간 데이터가 제일 처음에 나오는 선입선출의 구조를 가지고 있습니다.
예1) 1, 2, 3, 4를 큐에 차례대로 넣습니다.
queue.enqueue(데이터)출력 방향 <---------------------------< 입력 방향
1 <- 2 <- 3 <- 4
<---------------------------<
들어간 순서대로, 1번이 제일 먼저 들어가고 4번이 마지막으로 들어가게 됩니다.
예2) 큐가 빌 때까지 데이터를 전부 빼냅니다.
queue.dequeue(데이터)출력 방향 <---------------------------< 입력 방향
<---------------------------<1, 2, 3, 4
제일 첫 번째 있는 데이터부터 차례대로 나오게 됩니다.
2. 데이터는 하나씩 넣고 뺄 수 있습니다.
Queue 자료구조는 데이터가 아무리 많이 있어도 하나씩 데이터를 넣고, 뺍니다. 한꺼번에 여러 개를 넣거나 뺄 수 없습니다.
- 두 개의 입출력 방향을 가지고 있습니다.
Queue 자료구조는 데이터의 입력, 출력 방향이 다릅니다. 만약 입출력 방향이 같다면 Queue 자료구조라고 볼 수 없습니다.
-
데이터는 하나씩 넣고 뺄 수 있습니다.
Queue 자료구조는 데이터가 아무리 많이 있어도 하나씩 데이터를 넣고, 뺍니다. 한꺼번에 여러 개를 넣거나 뺄 수 없습니다. -
두 개의 입출력 방향을 가지고 있습니다.
Queue 자료구조는 데이터의 입력, 출력 방향이 다릅니다. 만약 입출력 방향이 같다면 Queue 자료구조라고 볼 수 없습니다.
Queue의 실사용 예제
자료구조 Queue는 컴퓨터에서도 광범위하게 활용됩니다. 컴퓨터와 연결된 프린터에서 여러 문서를 순서대로 인쇄하려면 어떻게 해야 할까요?
우리가 문서를 작성하고 출력 버튼을 누르면 해당 문서는 인쇄 작업 (임시 기억 장치의) Queue에 들어갑니다.
프린터는 인쇄 작업 Queue에 들어온 문서를 순서대로 인쇄합니다.
컴퓨터(출력 버튼) - (임시 기억 장치의) Queue에 하나씩 들어옴 - Queue에 들어온 문서를 순서대로 인쇄
만약 Queue에 들어온 순서대로 출력하지 않는다면, 인쇄 결과물이 뒤죽박죽일 겁니다.
[그림] 인쇄 작업 Queue는 Queue에 들어온 문서를 순서대로 출력합니다.
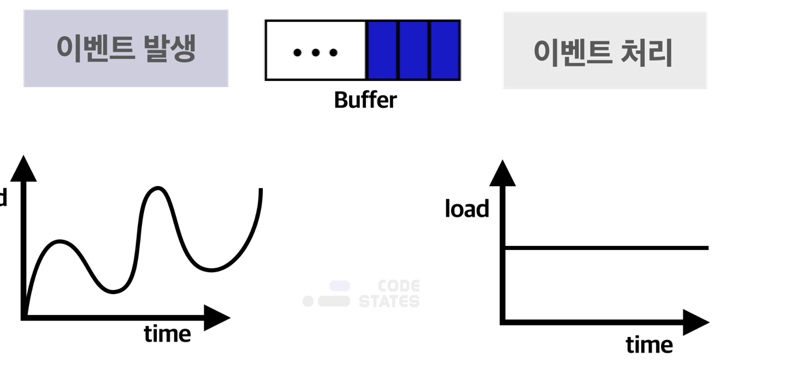
위 예시처럼 컴퓨터 장치들 사이에서 데이터(data)를 주고받을 때, 각 장치 사이에 존재하는 속도의 차이나 시간 차이를 극복하기 위해 임시 기억 장치의 자료구조로 Queue를 사용합니다. 이것을 통틀어 버퍼(buffer)라고 합니다. 아래 이미지는 버퍼링(buffering)의 개념을 보여주고 있습니다.
대부분의 컴퓨터 장치에서 발생하는 이벤트는 파동 그래프와 같이 불규칙적으로 발생합니다. 이에 비해 CPU와 같이 발생한 이벤트를 처리하는 장치는 일정한 처리 속도를 갖습니다. 불규칙적으로 발생한 이벤트를 규칙적으로 처리하기 위해 버퍼(buffer)를 사용합니다.
컴퓨터와 프린터 사이의 데이터(data) 통신을 정리하면 다음과 같습니다.
- 일반적으로 프린터는 속도가 느립니다.
- CPU는 프린터와 비교하여, 데이터를 처리하는 속도가 빠릅니다.
따라서, CPU는 빠른 속도로 인쇄에 필요한 데이터(data)를 만든 다음, 인쇄 작업 Queue에 저장하고 다른 작업을 수행합니다. - 프린터는 인쇄 작업 Queue에서 데이터(data)를 받아 일정한 속도로 인쇄합니다.
유튜브와 같은 동영상 스트리밍 앱을 통해 동영상을 시청할 때, 다운로드 된 데이터(data)가 영상을 재생하기에 충분하지 않은 경우가 있습니다. 이때 동영상을 정상적으로 재생하기 위해 Queue에 모아 두었다가 동영상을 재생하기에 충분한 양의 데이터가 모였을 때 동영상을 재생합니다.
