웹(Web)
이런 브라우저 상에서 제공되는 웹(Web)은 월드 와이드 웹(World Wide Web)이 풀 네임이며, 인터넷 상에서 텍스트나 그림, 소리, 영상 등과 같은 멀티미디어 정보를 하이퍼텍스트(hypertext) 방식으로 연결해 제공합니다. HTML 언어를 사용하여 작성된 문서 형태로 제공이 되며, 이러한 문서들을 웹 페이지(Web Page)라고 부릅니다. 그리고 이런 웹 페이지 중 서로 관련된 내용으로 작성된 웹 페이지들의 집합을 웹 사이트(Web Site)라고 부릅니다.
브라우저에 대해서

웹 브라우저라고도 하고, 웹 탐색기라고도 하는 브라우저는 웹 서버에서 양방향으로 통신을 하며 HTML 문서 및 그림, 멀티미디어(ex. 동영상) 등의 컨텐츠를 열람할 수 있게 해주는 GUI 기반의 소프트웨어 프로그램입니다. 브라우저는 페이지를 다운로드 하기 위해 응용 계층의 대표적인 프로토콜인 HTTP를 통해 송수신을 합니다.
웹(Web)
이런 브라우저 상에서 제공되는 웹(Web)은 월드 와이드 웹(World Wide Web)이 풀 네임이며, 인터넷 상에서 텍스트나 그림, 소리, 영상 등과 같은 멀티미디어 정보를 하이퍼텍스트(hypertext) 방식으로 연결해 제공합니다. HTML 언어를 사용하여 작성된 문서 형태로 제공이 되며, 이러한 문서들을 웹 페이지(Web Page)라고 부릅니다. 그리고 이런 웹 페이지 중 서로 관련된 내용으로 작성된 웹 페이지들의 집합을 웹 사이트(Web Site)라고 부릅니다.
웹 브라우저(Web Browser) 종류
왼쪽부터 순서대로 모자익(Mosaic), 넷스케이프(Netscape), 크롬(Chrome) 브라우저입니다. 최초의 웹 브라우저는 1993년 미국 일리노이 대학을 다니던 마크 안드레센과 에릭 비나가 개발한 모자익(Mosaic)이며, 시간이 지나 1994년에 상업용 브라우저인 넷스케이프 내비게이터가 등장했습니다.
이를 기점으로 하여 웹 브라우저의 편리한 사용성을 인식한 인터넷 사용자가 폭발적으로 증가했고 웹의 대중화가 시작했습니다. 현재에 이르러 웹 브라우저는 다양하게 존재하며, 가장 많은 지분을 차지하는 것은 구글에서 개발한 크롬 브라우저입니다.
브라우저의 특징과 웹의 동작 원리
브라우저는 현존하는 브라우저끼리 조금씩 그 특징이 다르지만 공통점이 하나 있습니다. 그것은 바로 동작 방식입니다. 브라우저는 사용자가 선택한 자원(Resource)를 서버에 요청(Request)하고, 서버의 응답(Response)을 브라우저에 띄우는(Rendering) 방식으로 동작합니다. 여기서 자원은 대개 HTML 문서이나 가끔 PDF, 멀티미디어 등 다른 형태일 수 있으며, 자원의 주소는 URI(Uniform Resource Identifier)로 되어 있습니다.
밑에는 웹 브라우저가 웹 사이트에 접속하여 웹 페이지를 가져오는 과정을 도식화한 그림입니다.
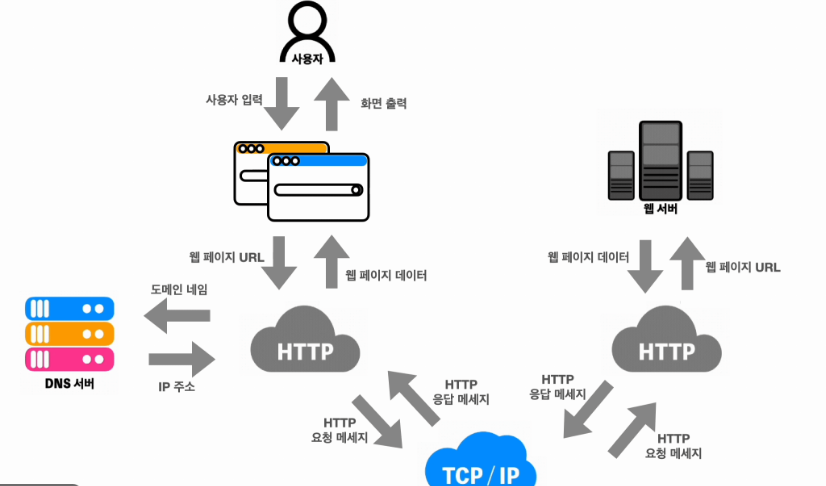
먼저, 사용자가 웹 브라우저를 통해 찾고 싶은 웹 페이지의 URL 주소를 입력합니다. 그러면 DNS 서버에서 사용자가 입력한 URL 주소 중 도메인 네임을 검색을 합니다. 그리고 해당 도메인 네임에 해당하는 IP 주소를 찾아 사용자가 입력한 URL 정보와 함께 전달합니다.
이렇게 웹 페이지 URL 정보와 전달받은 IP 주소는 HTTP 프로토콜을 사용해 HTTP 요청 메세지를 생성해 TCP 프로토콜을 사용해 인터넷을 거쳐 해당 IP 컴퓨터로 전송되고, 이 요청 메세지는 다시 HTTP 프로토콜을 통해 웹 페이지 URL 정보로 변환이 됩니다.
웹 서버는 이 변환이 된 정보에 해당하는 데이터를 검색하여 찾아낸 뒤 HTTP 프로토콜을 통해 HTTP 응답 메세지를 생성하고, 이 메세지는 다시 TCP 프로토콜을 이용해 인터넷을 거쳐 사용자의 컴퓨터로 전송이 됩니다.
사용자의 컴퓨터에 도착한 HTTP 응답 메세지는 HTTP 프로토콜을 사용해 웹 페이지 데이터로 변환이 되고, 변환된 데이터는 웹 브라우저 상에 출력되어 사용자가 볼 수 있게 됩니다.
브라우저의 구조
브라우저는 각기 그 모양이 조금씩 다르지만 모두 기본적인 구조를 가지고 있습니다. 아래는 브라우저의 구조를 간단하게 도식화한 그림입니다.
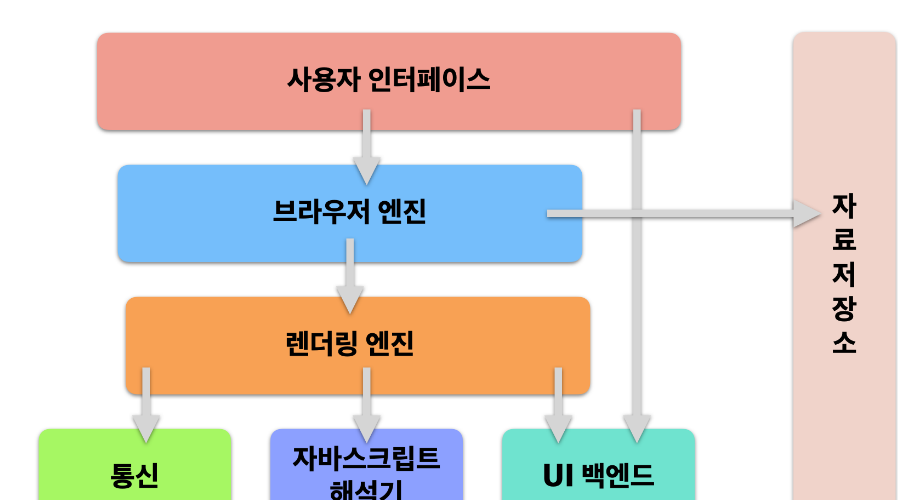
사용자 인터페이스(User Interface)
UI이라고도 부르며, 가장 유저와 밀접하게 맞닿아있는 부분입니다. 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등에 관련된 GUI 부분을 통칭하고 있습니다.
브라우저 엔진(Browser Engine)
사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어합니다. 브라우저 엔진의 주된 역할은 HTML 문서와 기타 자원의 웹페이지를 사용자의 장치에 시각 표현으로 변환시키며, 문서 객체 모델(DOM) 자료 구조를 구현합니다.
레이아웃 엔진(Layout Engine)라고도 부르며, 렌더링 엔진(Rendering Engine)과 밀접한 연관이 있어 보통은 브라우저 엔진과 렌더링 엔진을 묶어 브라우저 엔진으로 부르나 여기서는 구분해서 표현합니다.
이러한 브라우저 엔진은 웹 브라우저 마다 전용 엔진을 사용하고 있습니다. 밑의 표에서 설명한 브라우저 엔진 외에도 다양한 엔진이 있습니다.

렌더링 엔진(Rendering Engine)
요청한 콘텐츠를 화면에 출력하는 역할을 합니다. HTML, CSS 등을 파싱해 최종적으로 화면에 그려주며, 렌더링 엔진은 HTML 및 XML 문서와 이미지를 표시할 수 있습니다. (물론 플러그인이나 브라우저 확장 기능을 이용해 PDF와 같은 다른 유형도 표시할 수 있습니다.)
위에서 기술한 브라우저 엔진과 밀접하게 결합되어 있으므로 보통은 하나의 엔진으로 보는 시각이 많습니다. 렌더링 엔진 또한 웹 브라우저 마다 전용 엔진을 사용하고 있으나 엔진의 동작 원리는 공통된 부분이 많습니다. 렌더링 엔진의 동작 원리는 이후 브라우저 렌더링 챕터에서 상세히 다룰 것입니다.
통신(Networking)
HTTP 요청과 같은 네트워크 호출에 사용됩니다. 보통 플랫폼의 독립적인 인터페이스이고 각 플랫폼의 하부에서 실행됩니다.
네트워크 호출과 같은 부분은 이전 섹션에서 다루고 있으므로, 해당 개념에 대해 미진하다면 다시 이전 섹션의 네트워크 유닛에서 복습하시길 바랍니다.
자바스크립트 해석기(JavaScript Interpreter)
현대의 웹 페이지는 이제 JavaScript와 떼려고 해도 뗄 수 없게 되었습니다. 그 이유는 대부분의 웹 인터랙션(Interaction)에 JavaScript가 사용 되기 때문입니다.
JavaScript는 코드를 위에서 아래로 한 줄씩 읽어내려가는 방식으로 파싱(parsing)하는 언어(Interpreted Language)입니다. 따라서 JavaScript 코드를 해석하고 실행하는 자바스크립트 해석기(JavaScript Interpreter)가 필요에 의해 등장하게 되었습니다.
자바스크립트 엔진(JavaScript Engine)이라고도 부르는 자바스크립트 해석기는 여러 목적으로 사용이 되지만 대체적으로 웹 브라우저에서 이용이 되며, 브라우저마다 전용 엔진이 탑재되어 있습니다. 밑의 표에서 설명한 엔진 외에도 다양한 엔진이 있습니다.


힙 메모리(Heap Memory)
힙 메모리 내부에는 다양한 공간이 있습니다만, 복잡하기 때문에 여기서는 커다랗게 하나의 공간으로 되어있다고 보겠습니다. 힙(heap)은 동적 메모리 할당에 사용되는 자료구조입니다. 이 힙을 이용하여 V8은 객체 또는 동적 데이터를 저장합니다. 여기에 저장되는 메모리는 V8 엔진 내부에서 가장 큰 공간을 차지하고 있으며, 가비지 컬렉션 또한 발생하는 곳입니다.
콜 스택(Call Stack)
JavaScript는 기본적으로 싱글 스레드 기반의 언어입니다. 콜 스택이 하나라는 의미이며, 한 번에 한 작업만 사용할 수 있습니다. 콜 스택은 프로그램 상에서 우리가 어디에 있는지 기록하는 자료구조입니다. 만약 함수를 실행한다면, 해당 함수는 콜 스택의 가장 상단에 위치합니다. 이는 스택이 후입선출(LIFO)이라는 구조를 가지고 있기 때문에 일어나는 일입니다. 만약 함수의 실행이 끝난다면, 해당하는 함수는 콜 스택의 가장 상단에 위치하고 있기 때문에 바로 제거할 수 있습니다.
콜 스택의 동작 방식
콜 스택이 동작하는 방식을 가장 잘 볼 수 있는 예를 보면서 콜 스택을 이해해보도록 하겠습니다.


자료 저장소
말 그대로 자료를 저장하는 계층입니다. 쿠키를 저장하는 것과 같이 모든 자원을 하드 디스크에 저장할 필요가 있기 때문에 존재하고 있습니다. HTML5 명세에는 브라우저가 지원하는 웹 저장소(Web Storage, 이하 웹 스토리지라고 지칭합니다.) 스펙이 정의되어 있습니다. 영구적인 저장소인 로컬스토리지(localStorage)와 임시적인 저장소인 세션스토리지(sesseionStorage)를 따로 두어 데이터의 지속성을 구분할 수 있어 응용 환경에 맞는 선택이 가능해집니다.
웹 스토리지(Web Storage) 특징
HTML5 이전에는 응용 프로그램이 데이터에 서버를 요청할 때마다 매번 쿠키(Cookie)라는 곳에 그 정보를 저장해왔습니다. 그러나 쿠키 자체의 보안상 취약과 더불어 저장소의 절대적인 허용 용량의 적음으로 다른 대안을 찾게 되었고, 이윽고 웹 스토리지(Web Storage)가 나오게 되었습니다.
웹 스토리지는 웹 브라우저가 직접 데이터를 저장할 수 있게 해줍니다. 또한 웹 스토리지는 사용자 측에서 좀 더 많은 양의 정보를 안전하게 저장할 수 있게 해줍니다. 이런 모든 정보는 절대 서버로 전송되지 않으므로 저장된 데이터가 클라이언트에만 존재하기 때문에 네트워크 트래픽 비용 또한 줄여준다는 특징 또한 가지고 있습니다.
이러한 웹 스토리지는 오리진(origin)마다 단 하나씩만 존재합니다. 오리진(origin)은 도메인(domain)과 프로토콜(protocol) 한 쌍으로 이루어진 식별자로, 하나의 오리진에 속하는 모든 웹 페이지는 같은 데이터를 저장하기 때문에 같은 데이터에 접근할 수 있게 됩니다.
이런 웹 스토리지는 사용하기 전에 사용자의 웹 브라우저 버전이 이를 지원하는지 먼저 확인을 해봐야 합니다.
웹 스토리지 종류
웹 스토리지는 데이터의 지속성과 관련해 두 가지 용도의 저장소 객체를 제공합니다.
로컬스토리지(localStorage)
로컬스토리지 객체는 보관 기한이 없는 데이터를 저장합니다. 따라서 브라우저 탭이 닫히거나, 컴퓨터를 재부팅해도 이 저장소에 저장된 데이터는 사라지지 않습니다. Windows 전역 객체의 localStorage라는 컬렉션을 통해 저장과 조회가 가능하며, 도메인 마다 별도의 localStorage가 생성됩니다. 따라서 도메인만 같으면 전역으로 데이터의 공유가 가능해집니다.
세션스토리지(sessionStorage)
세션스토리지 객체는 하나의 세션만을 위한 데이터를 저장합니다. 데이터를 지속적으로 보관하지 않고 브라우징되고 있는 브라우저 컨텍스트 내에서만 데이터가 유지되기 때문에, 사용자가 브라우저 탭이나 창을 닫으면 이 객체에 저장된 데이터는 사라집니다. 브라우징이란 브라우저 프로그램을 실행해서 인터넷에 들어가 필요한 정보를 찾는 행위를 말하며, 브라우저 컨텍스트란 브라우저가 문서를 표시하는 환경을 말합니다. 각 브라우징 컨텍스트는 특정 출처 및 활성화되고 있는 문서의 출처, 표시했던 모든 문서의 방문기록을 가지고 있습니다.
저장과 조회는 Windows 전역 객체의 sessionStorage라는 컬렉션을 통해 이루어지며, 도메인 별로 별도로 생성됩니다. 여기서 알아둬야 할 점은 브라우저 컨텍스트가 다르면 서로 다른 영역이 된다는 특징이 있습니다. 즉, 브라우저 두 개를 실행해 같은 페이지를 열었을 때, 브라우저의 컨텍스트가 서로 다르므로 이 두 페이지의 sessionStorage는 각 별개의 영역으로 인지되어 서로 데이터의 공유가 불가능해집니다.
웹 스토리지를 지원하는 웹 브라우저 버전
버전이 다르면 웹 스토리지를 사용할 수 없기 때문에 반드시 꼭 확인을 해야 합니다.

이번에는 웹 스토리지를 사용하기 위한 문법을 알아봅시다. 웹 스토리지는 클라이언트에 데이터를 저장하기 위한 두 가지 객체를 제공합니다.
window.localStorage : 만료 날짜가 없는 데이터를 저장할 때 쓰입니다.
window.sessionStorage : 세션이 있는 데이터를 저장할 때 쓰입니다. (브라우저 탭을 닫으면 손실되는 것을 의도한 데이터를 저장할 때 쓰입니다.)
해당 코드는 웹 스토리지를 사용하기 이전에 해당 브라우저의 버전이 웹 스토리지를 지원하는지 확인하고자 할 때 쓰이는 코드입니다. 먼저 웹 스토리지가 존재하는지 확인을 한 다음에, 웹 스토리지에 무엇을 저장할 지 결정하여 조건문 안에 작성을 합니다.
웹 스토리지를 활용한 대표적인 기능
웹 스토리지를 활용한 대표적인 기능은 다양하게 존재합니다. 먼저, 브라우저 컨텍스트 내에서 저장한 데이터를 가지고 활용할 수 있기 때문에 복구 및 백업에 관련된 기능에 주로 사용이 됩니다.
블로그 글을 작성하다가 사용자가 창을 벗어난 경우 관련 작성 내용을 복구하거나 백업해주는 기능
사용자가 입력 form을 통해 정보를 입력하다 페이지에서 벗어난 경우 복구 및 백업해주는 기능
현재 읽은 글의 히스토리 저장(카운팅, 혹은 읽은 글 표시 등으로 활용)
브라우저렌더링
브라우저 렌더링에서 렌더링(rendering)이란 HTML, CSS, JavaScript 등 개발자가 작성한 문서가 브라우저에서 출력되는 과정을 의미합니다. 현존하는 브라우저마다 다르지만, 브라우저는 기본적으로 렌더링을 수행하는 렌더링 엔진을 가지고 있습니다.
브라우저 렌더링 과정
아래는 브라우저가 렌더링이 되는 과정을 간단히 도식화한 것입니다.
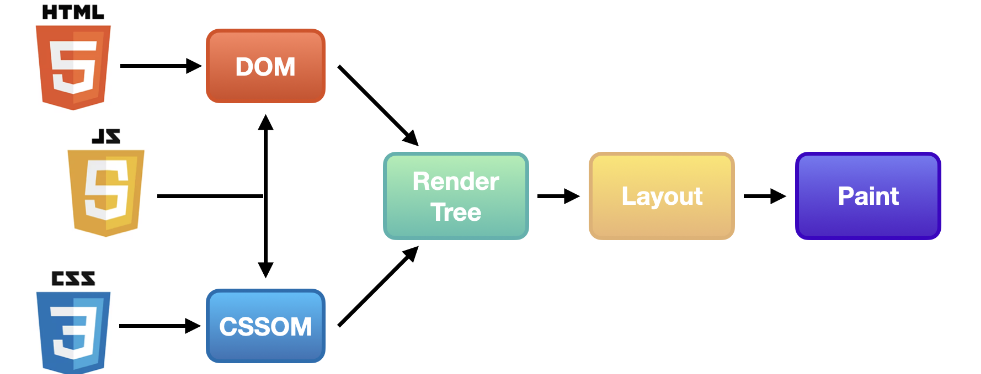
렌더링 과정은 이렇게 설명할 수 있습니다.
- 사용자가 브라우저를 통해 웹 사이트에 접속합니다.
2 브라우저는 서버로부터 HTML, CSS, JavaScript와 같은 웹사이트에 필요한 리소스를 다운 받습니다.
3 렌더링 엔진은 전달받은 HTML 문서를 파싱(parsing)해 DOM(Document Object Model, 문서 객체 모델) 트리를 만듭니다.
4 이어서 다운 받은 외부 CSS 파일과 함께 포함된 스타일 요소를 파싱(parsing)해 CSSOM(CSS Object Model, CSS 객체 모델) 트리를 만듭니다.
5 만든 DOM 트리와 CSSOM 트리를 결합해 Render 트리를 구축합니다.
6 레이아웃 과정을 통해 각 요소를 어디에 배치할 지 결정합니다.
7 레이아웃 과정이 끝나면 UI 백엔드에서 Render 트리를 화면에 그리기 시작합니다. 이 과정을 paint라고 합니다.
이제부터 렌더링 과정에 쓰이는 개념들을 알아보도록 하겠습니다.
파싱(Parsing)
파싱이란 프로그래밍 언어로 작성된 파일을 실행시키기 위해 구문 분석(syntax analysis)을 하는 단계입니다. 이런 파싱을 파서(parser)가 진행하며, 일종의 인터프리터나 컴파일러 구성 요소 가운데 하나입니다. 파서는 HTML 파일의 코드를 문법적 의미를 갖는 최소 단위인 토큰(token)으로 한 번 분해하고, 이 토큰들을 문법적 의미와 구조에 따라 노드(node)라는 요소로 바꿉니다. 노드들은 상하 관계에 따라 하나의 트리를 형성하는데 이를 파스 트리(parse tree), 혹은 문법 트리(syntax tree)라고 부릅니다.
문서 파싱(document parsing)은 브라우저가 코드를 이해하고 사용할 수 있는 구조로 변환하는 것을 의미합니다. 렌더링 과정에서는 HTML 파일을 바탕으로 DOM 트리를 구축하고 및 CSS 파일로 CSSOM 트리를 만드는 것을 파싱한다고 표현합니다.
브라우저는 HTML 문서를 받아들자마자 DOM 트리로 파싱합니다. 이때 HTML 토큰이 만들어지는데, 이 토큰에는 시작 태그와 마침 태그가 포함되고, 속성 이름과 값도 포함이 됩니다. 이런 토큰으로 변한 입력 값은 파서에 의해 노드가 되고, 최종적으로 트리 구조의 DOM으로 구성이 됩니다.
브라우저는 HTML 문서를 파싱하면서 CSS스타일을 만날 경우 텍스트를 CSS 스타일링 레이아웃과 페인팅에 사용하는 데이터 구조인 CSSOM 트리로 파싱하고, 태그를 만날 경우 렌더링을 차단하면서 HTML 파싱 또한 중단합니다. 이어 script 파일을 다운 받아 파싱하고 실행시킨 뒤 다시 HTML 파일을 파싱하기 시작합니다.
파싱은 문서에 작성된 언어 또는 형식의 규칙에 따르는데 파싱할 수 있는 모든 형식은 정해진 용어와 구문 규칙에 따라야 합니다. 따라서 형식을 잘 갖춘 문서라면 파싱 과정은 직관적이고 빠르게 진행됩니다.
이제부터 한 HTML 파일을 통해 DOM 트리, CSSOM 트리, Render 트리에 대해 살펴보도록 하겠습니다.
DOM Tree
DOM은 HTML문서의 요소들의 중첩 관계를 기반으로 노드들을 트리 구조로 구성한 것을 의미하며, Document Object Model의 줄임말입니다. 브라우저는 JavaScript 언어만 알아듣기 때문에 HTML의 태그나 속성들을 이해하지 못합니다. 또한 응답으로 받아온 HTML 문서는 텍스트로만 이뤄져 있습니다. 그래서 이해할 수 있는 형태인 객체로 바꿔준 것이 바로 DOM 트리입니다.
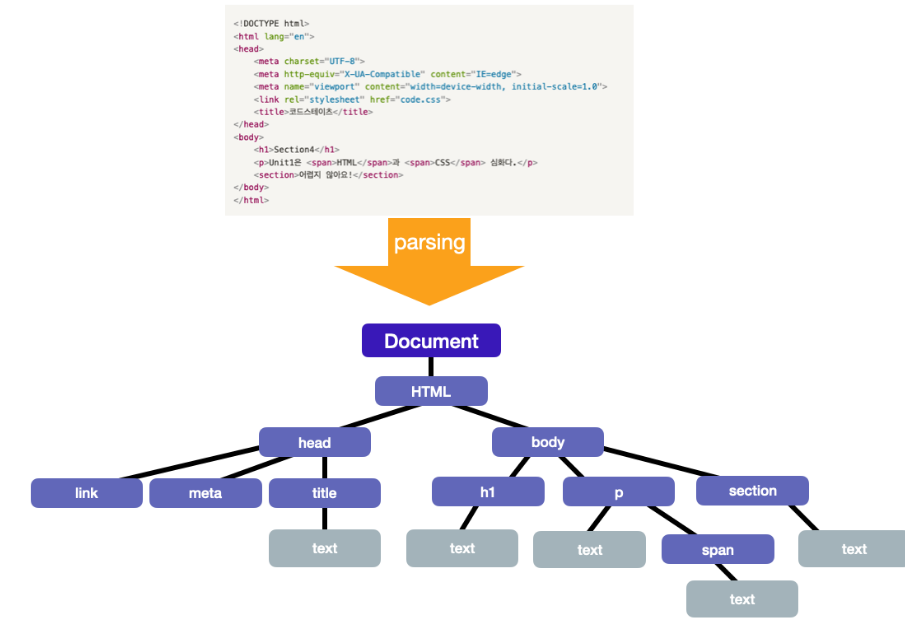
CSSOM Tree
html 파일을 DOM 트리로 파싱하던 브라우저는 ,
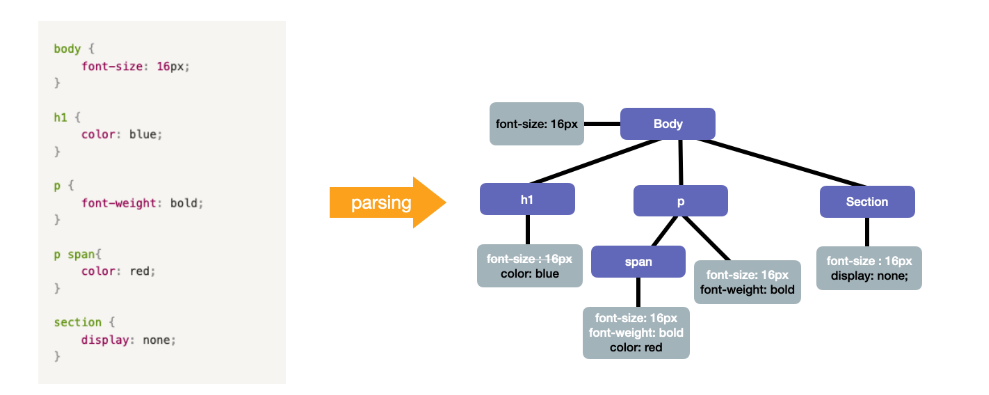
[그림] CSS 파일을 CSSOM 트리로 변환하면 이렇게 나옵니다.
하나 알아둬야 할 부분은 CSS는 부모의 속성을 자식이 상속 받는다는 점입니다. 예를 들어 body가 부모 요소이고 font-size가 16px인 속성을 가지고 있는데, 그 밑에 있는 p는 자식 요소이기 때문에 부모 요소인 body가 갖고 있던 속성을 상속 받으면서 동시에 자신이 가지고 있는 속성인font-weight 속성까지 가지므로 2개의 속성을 갖게 된다는 점입니다.
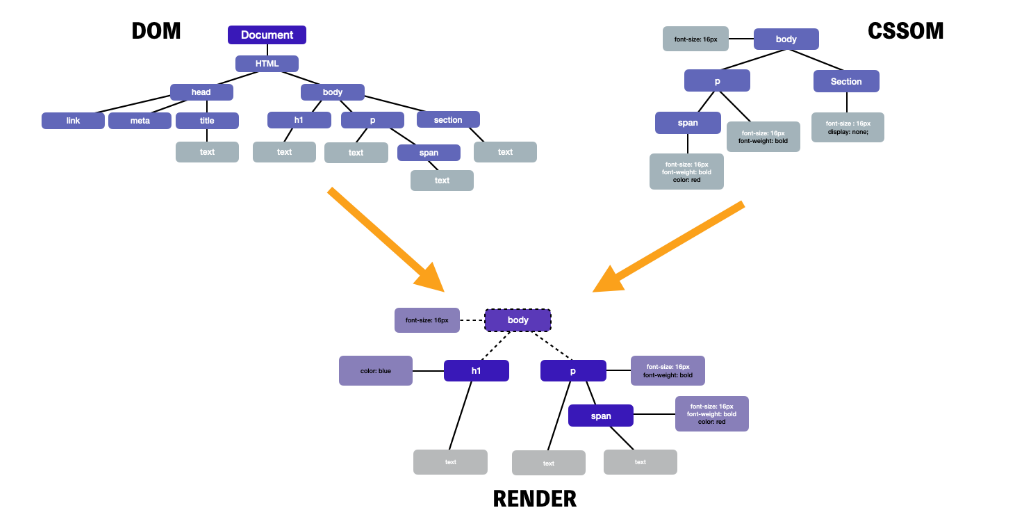
렌더 트리(Render Tree)
DOM 트리와 CSSOM 트리는 트리 구조로 되어 있기 때문에 비슷하게 생겼지만, 애초에 리소스부터 틀린 서로 다른 속성을 가진 독립적인 트리입니다. 그렇기 때문에 브라우저 위에 웹사이트를 표시하기 위해서는 이 둘을 합치는 작업이 반드시 필요합니다.
렌더 트리는 이름처럼 렌더링을 목적으로 만들어지는 트리입니다. 렌더링은 사용자에게 브라우저가 보여주고자 하는 화면을 그리는 과정이므로, 보이지 않을 요소들은 이 트리에 포함시키지 않습니다.
레이아웃
브라우저 렌더링에서 “레이아웃” 과정은 우리가 웹 개발에서 평소 말하는 웹 페이지 레이아웃 짜기, 디자이너들의 레이아웃과는 다른 개념입니다. 여기서 말하는 레이아웃은 렌더트리를 기반으로 HTML 요소의 레이아웃(위치, 크기 등)을 계산하여 브라우저 화면 어디에 배치할 지 결정하는 과정입니다.
위의 그림에서도 볼 수 있듯이 DOM, CSSOM에 있던 속성들이 합쳐서 렌더 트리를 구성하는 것을 볼 수 있습니다. 그러나 아직까지 렌더 트리는 텍스트로 구성된 객체로만 보입니다. 페인팅이라는 작업을 거쳐야지 브라우저 위의 화면으로 그려지게 됩니다.
아시다시피 렌더 트리에는 CSSOM 트리에 있던 속성들이 합쳐져 있습니다. 따라서 렌더 트리에는 요소들의 크기, 혹은 위치에 관련된 정보들이 들어 있습니다. 하지만 아직까지 이 정보들은 그저 각 요소에 관련된 정보일 뿐, 전체 화면에서 정확히 어디에 위치하는가에 대해서는 알지 못합니다. 이런 계산을 브라우저의 렌더링 엔진이 합니다. 브라우저는 각 요소들이 전체 화면에서 어디에, 어떤 크기로, 어떻게 배치가 되어야 하는지 파악하기 위해 렌더트리를 위에서 아래로 읽어 내려갑니다. 그리고 모든 값은 절대적인 단위인 px 값으로 변환됩니다.
페인팅
위치에 대한 계산을 마치면 이제 화면에 보여주기 위해 브라우저는 화면 위에 레이아웃에서 결정된 대로 그림을 그리기 시작합니다. 브라우저 화면은 픽셀이라고 하는 작은 점들로 구성되어 있습니다. 각 정보를 가진 픽셀들이 모여 하나의 화면을 구성하는 것입니다. 페인팅은 이런 픽셀에 대한 정보들을 바탕으로 픽셀을 채워나가는 과정이며, 이 과정까지 해내야 텍스트에 불과했던 HTML 파일의 내용들이 이미지화된 모습으로 브라우저 화면에 띄워지는 것입니다.
리플로우(Reflow)와 리페인트(Repaint)
만약에 사용자가 브라우저 화면을 늘리거나 줄이는 등 크기를 조절하거나, 다른 사이트로 이동을 하는 등 화면에 요소가 추가 되거나 삭제, 혹은 아예 다른 요소들을 불러와야 하는 상황이 생기면 당연히 화면에 있던 요소들의 크기가 바뀌게 됩니다.
사용자의 입장에서는 당연한 과정이지만, 이렇게 화면에 나타나는 모습을 바꾸기 위해서는 모든 요소의 위치와 크기를 다시 계산하고, 다시 그려 보여주어야 합니다. 이런 식으로 어떤 웹 인터랙션으로 인해 앞서 보았던 렌더링 과정의 레이아웃을 반복해 수행하는 것을 리플로우, 페인트 과정을 반복해 수행하는 것을 리페인트라고 합니다.
const div = document.createElement('div');
document.body.append(div);
div.textContent = 'hello world';
위의 코드는 div요소를 생성하고 body에 해당 요소를 붙인 뒤 ‘hello world’라는 텍스트를 추가하는 간단한 코드입니다. 이미 지난 섹션에서 학습하셨듯이, 여러분은 JavaScript를 통해 DOM을 조작하는 방법을 알고 있으며, CSS 또한 이런 방식으로 조작할 수 있다는 것 또한 알고 계실 겁니다. 이렇게 JavaScript 조작을 통해 변경이 일어나면, DOM 트리를 다시 구성하는 것을 시작해 CSSOM과 합쳐 새 렌더 트리를 생성합니다. 그리고 레이아웃과 페인트 과정을 또 다시 거쳐 화면에 보여줍니다. DOM 조작은 리플로우, 리페인트가 일어나는 대표적인 예시입니다.
리플로우와 리페인트의 최적화
사용자의 눈에 일련의 과정이 부드럽게 처리 되려면 초당 60 프레임은 반드시 유지시켜야 합니다. 이는 TOAST에서 WebRender를 소개하면서 나오는 개념이기도 합니다. TOAST에서도 WebRender를 설명하기 위해 사용한 예시지만, 너무나 찰떡인 예시기 때문에 예시로 플립북을 들어보겠습니다. 플립북은 이름은 생소하실 테지만 실제로 보면 아! 이거? 라고 생각이 드실 겁니다.
반응형 웹
현대에 들어서서 이제 너무나도 많은 기기들이 출시가 되었습니다. 그렇기 때문에 기기들의 디스플레이의 종류에 반응해 그에 맞도록 적절히 UI 요소들이 배치되도록 설계하는 능력 또한 프론트엔드 엔지니어에게 요구되고 있습니다. 이번 챕터에서는 반응형 웹에 대해 알아보도록 하겠습니다.
반응형 웹의 탄생 배경
과거의 웹사이트들은 데스크탑 컴퓨터를 통해서 이용하는 경우가 대부분이었습니다. 웹사이트를 제작하는 개발자들은 데스크탑에 최적화된 화면만 구성하면 이용자들이 웹사이트를 이용하는데에는 불편함이 없었습니다.
이후 전자기기의 발전으로 인해 데스크탑 뿐만 아니라 태블릿, 스마트폰 등의 전자기기에서 웹에 접속할 수 있게 되었지만, 전자기기들의 화면의 크기가 다양한 탓에 여러가지 버전의 웹페이지를 만들어야 하는 경우가 발생하게 됩니다. 이러한 불편함을 해결하기 위해 반응형 웹페이지가 탄생합니다.
반응형 웹이란
반응형 웹 디자인이란 여러 장치의 다양한 특성에 대응하는 하나의 웹 문서 또는 사이트로써 브라우저의 크기(스크린의 크기, 디바이스의 종류)에 실시간으로 반응하여 크기에 따라 레이아웃이 변하는 웹 사이트를 의미합니다. 즉, 하나의 소스 코드로 모든 스크린에 최적화된 웹 사이트를 구축할 수 있는 방법론, 디바이스 종류에 따라 웹페이지의 크기가 자동적으로 재조정되는 것이죠.
그래서 사이트를 이루는 소스 코드는 하나지만 접속하는 스크린 사이즈에 따라 레이아웃을 유동적으로 달리 보여줍니다.
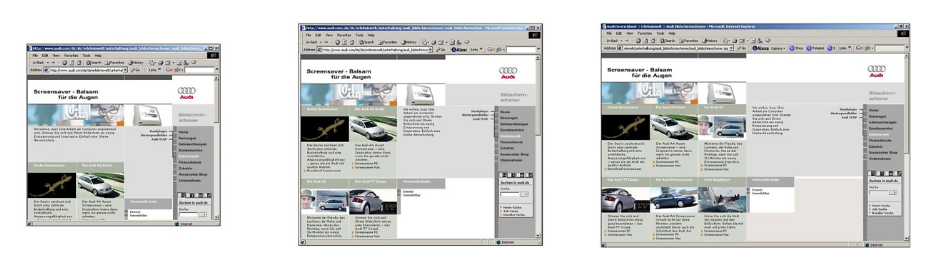
[그림] 최초의 반응형 웹
최초의 반응형 웹 사이트는 2002년에 론칭한 아우디닷컴(Audi.com)입니다. 애플사가 최초로 아이폰을 선보인 것이 2007년 6월이고, CSS 미디어 쿼리와 같은 핵심적 기술들이 2009년 초반이 되어서야 정착되기 시작했음을 고려하면 최초의 반응형 웹 사이트가 이례적으로 빠른 시기에 등장했음을 알 수 있습니다.
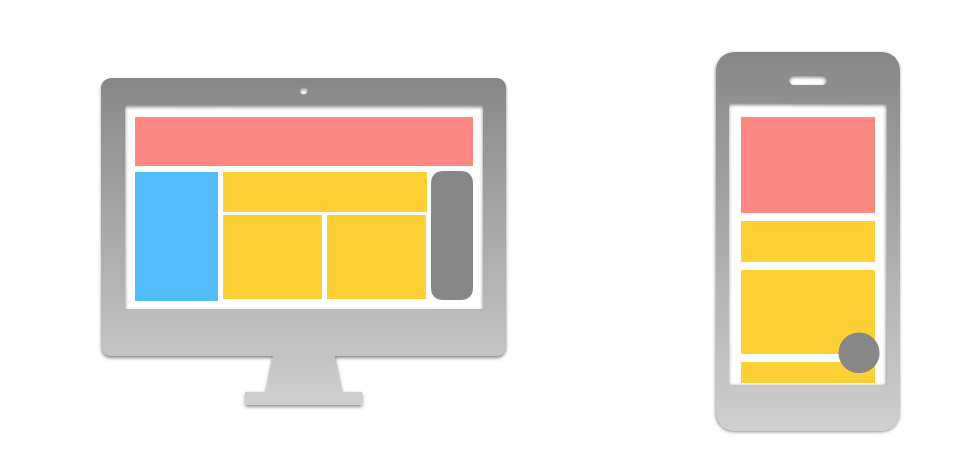
[그림] 이제는 모바일 기기에서 어떻게 보일 지를 먼저 고려하며 웹을 디자인하게 되었습니다.
반응형 웹에서 빼놓을 수 없는 개념은 모바일 퍼스트라는 개념입니다. 모바일 퍼스트(mobile first)란 (Luke Wroblewski)가 최초로 주장한 철학이자 전략이며, 사용자 경험(UX)을 디자인할 때 모바일일 경우에 최우선으로 초점을 맞춰 디자인하는 것입니다.
현재는 데스크탑 유저보다 모바일 유저가 공유하는 정보가 많다는 것은 부정할 수 없는 사실입니다. 실제로 일부 마케터들은 이미 모바일 유저를 겨냥한 서비스를 지원하고 있습니다. 그렇다고 모바일 웹 버전을 늘리는 수준으로만 데스크탑 웹을 구축해서는 안 됩니다. 따라서 현재 보다 효율적으로 PC부터 아이패드, 태블릿PC, 스마트폰까지 총망라하는 반응형웹을 구조하는 기술력이 주목받고 있습니다.
반응형 웹의 특징
이런 반응형 웹은 특징이 있습니다.
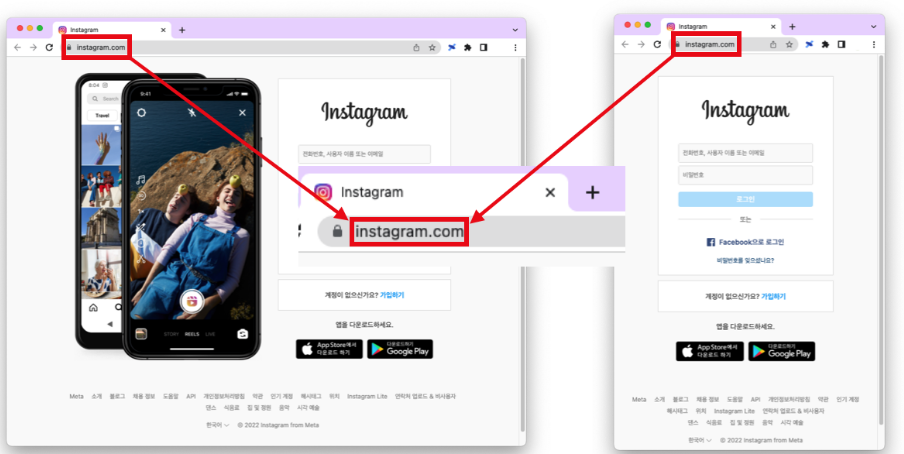
[그림] 인스타그램 : 하나의 URL을 기반으로 화면이 바뀌는 대표적인 예시
반응형 웹은 위의 예시처럼 하나의 URL을 기반으로 화면이 바뀝니다. 반응형 웹 디자인은 유연한 레이아웃에 대응하여 항상 최적의 화면을 제공함으로써 다양한 스크린 사이즈를 지닌 디바이스에 적응할 수 있습니다.
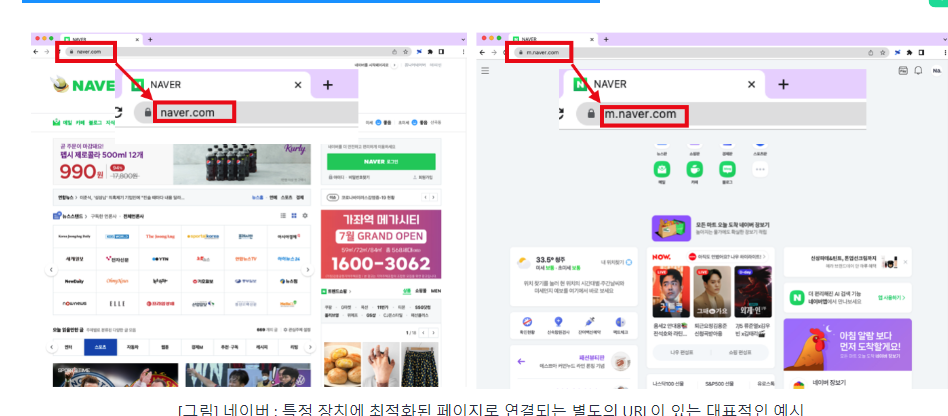
그러나 위의 예시처럼 특정 장치에 최적화된 페이지로 연결되는 별도의 URL이 있다면 반응형 웹이라고 부르지 않습니다. 특정 장치에 연결이 되는 별도의 URL은 모바일의 경우 대개 m.domainname.com 같은 식으로, 도메인 앞에 모바일을 의미하는 “m”을 붙임으로써 구분합니다. 특정 장치에 연결이 되는 별도의 URL과 화면이 구비된 웹 사이트의 경우, 데스크탑 버전의 웹 사이트를 띄운 브라우저를 줄였을 때 반응하지 않는다는 특징이 있습니다.
이러한 반응형 웹에는 장점과 단점이 동시에 공존하고 있습니다.
장점, 효율적인 유지보수
하나의 콘텐츠에 오직 하나의 HTML 소스만 있기 때문에 하나의 소스를 수정하면 모든 스크린 사이즈에 맞춰 컨텐츠가 최적화되기 때문에 유지보수가 효율적 입니다. 웹페이지 내용을 수정해야 할 때도 하나의 페이지에서만 적용해도 동일하게 반영되고, 하나의 소스 코드로 관리가 가능하기 때문에 초기 개발 비용 및 유지 관리 비용의 절감 효과를 가져올 수 있습니다. 또한 사용자 입장에서도 기기에 구애받지 않고 항상 최적의 화면을 경험할 수 있게 됩니다.
장점, 검색엔진(SEO) 최적화 유리
검색엔진 최적화(SEO)에 유리해 검색 결과에서 상위권에 나타나게 할 수 있습니다. 반응형 웹은 하나의 URL을 기반으로 화면이 바뀌므로 PC용 URL과 모바일용 URL이 동일합니다. 따라서 검색 포털 등 광고를 통한 사용자 접속을 효율적으로 관리할 수 있습니다.
단점, 사이트의 속도 저하
그러나 이런 모바일 환경에서도 적응하게끔 만들어진 반응형 웹은 모바일을 전용으로 하는 사이트에 비해 무겁습니다. 반응형 웹 디자인은 읽어들여야 할 소스가 많아 불필요하게 많은 데이터를 소비하기 때문에 이는 사이트 속도와 직결이 됩니다. 로딩의 속도나 이미지 리사이징의 문제로 성능이 떨어질 수 있으며, 실제로 사용하지 않은 자원을 전송 받거나 실제 사용되는 이미지보다 더 큰 이미지를 사용할 수 있습니다.
단점, 웹브라우저 호환성 문제
웹 브라우저의 호환성의 문제가 있을 수 있습니다. 현재 존재하는 웹 브라우저는 스펙 및 사양이 제각기 다르기 때문에 하나의 웹 브라우저에서는 잘 반응하던 HTML 소스가 다른 웹 브라우저에서는 디자인이 깨지는 경우가 발생할 수 있습니다. 또한 CSS3의 특성상 인터넷 익스플로러(IE) 8 버전 이하에서는 사용이 불가능 해집니다. 이런 문제 때문에 디자인의 자유도가 떨어지며, 100% 맞춤 디자인이 어렵다는 점이 발생합니다.
반응형 웹은 장점이 매우 많으나 단점 또한 존재하는 기술입니다. 따라서 훌륭한 프론트엔드 엔지니어가 되기 위해서는 항상 사이트 속도를 향상시키기 위해 이미지를 최적화 해야 하며, 효율적인 네비게이션 제공 방법 외에도 다양한 사항들을 고려해야만 합니다.
