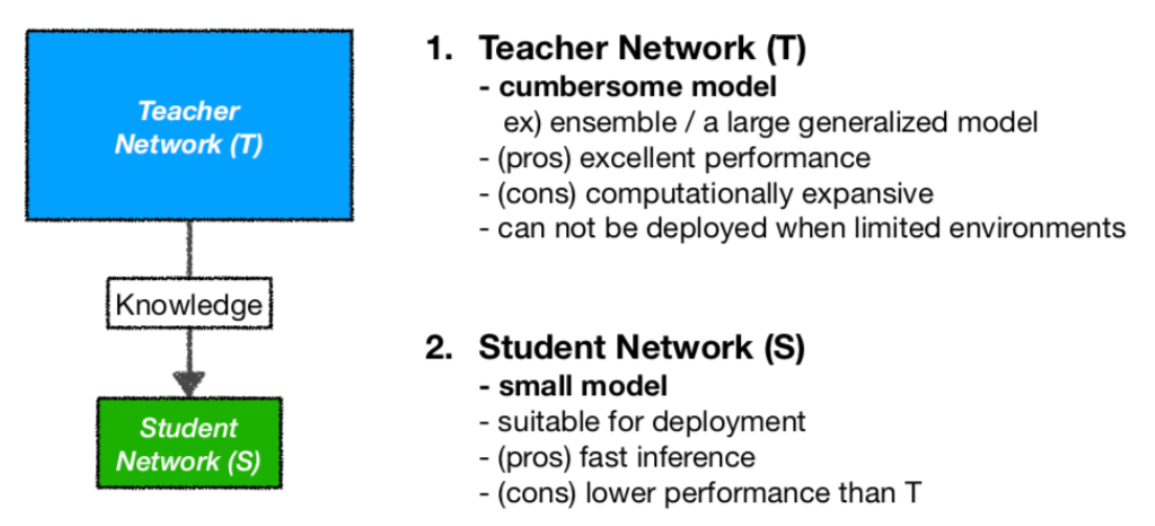
Knowledge Distillation
Knowledge Distillation란
우리말로 지식 증류로 잘 학습된 큰 네트워크(Teacher Network)의 지식을 작은 네트워크(Student Network)에 전달하는 것
1. Knowledge Distillation 개요

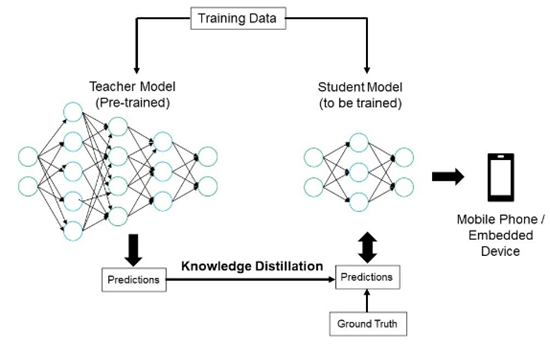
다수의 큰 네트워크들인 전문가(Experts, Teacher) 모델에서 출력은 일반적으로 특정 레이블에 대한 하나의 확률값 만을 나타내지만, 이를 확률값들의 분포 형태로 변형하여, 숙련가(Specialist, Student) 모델의 학습 시에 모델의 Loss와 전문가 모델의 Loss를 동시에 반영하는 형태로 숙련가 모델을 학습에 활용
➡ mnist 데이터셋에서 숫자 2의 경우 3, 7의 확률이 약간씩 존재할 시 숫자 2가 3,7과 유사하다는 정보를 학생모델에 전달
Teacher model에서 정보를 얻는 방식은 다음과 같이 분류할 수 있음
- Response-Based Knowledge - 최종만 빼내는 경우
- Feature-Based Knowledge - 중간중간 layer의 결과를 빼내어 student에게 넘겨주는 경우
- Relation-Based Knowledge - 데이터 간의 정보(input layer), 여러 feature들간의 정보(hint layers), 출력 결과 간의 정보(output layer)처럼 특정 데이터 혹은 feature 간의 정보를 활용한 경우
2. Knowledge Distillation 적용 과정
1) Soft Label
○ 일반적으로, 이미지 클래스 분류와 같은 task는 신경망의 마지막 softmax 레이어를 통해 각 클래스의 확률값을 출력하게 되는데, 예측한 클래스 이외의 값을 주의 깊게 보게 하도록 하기 위함
○ 우리가 예측하려고 하는 사진이 강아지인 것은 알겠는데 자동차나 젖소보다 고양이에 더 가까운 형태를 띠고 있다는 것을 알 수 있게 하는 것
○ 이를 위해 출력값의 분포를 좀 더 soft하게 만들어 이 값들을 이용


2) distillation loss
위에서 정의한 soft target은 결국 큰 모델(T)의 지식을 의미하는데, 큰 모델(T)을 학습을 시킨 후 작은 모델(S)을 다음과 같은 손실함수를 통해 학습시킴
3. 관련 논문
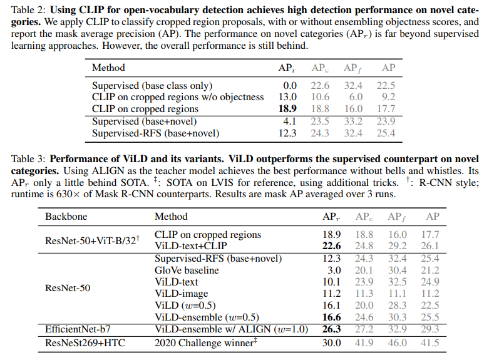
○ vision-language model의 정보를 증류하여 supervision model의 성능을 뛰어넘는 결과를 보임
○ 방법
*새로운 객체의 지역화 (localization of novel objects)
*사전학습된 텍스트 임베딩으로 학습 (ViLD-text)
*사전학습된 이미지 임베딩으로 학습 (ViLD-image) -> Knowledge Distillation
Reference
