첫 시작
머신러닝이던 딥러닝이던 가장 먼저해야할 것은 필요할 라이브러리 호출입니다. 물론 보통은 필요한 경우 부르면서 사용합니다.
하지만 Numpy, pandas, matplotlib, seaborn과 같은 아주 기초적인 것은 먼저 호출 후에 사용하는 것을 권장합니다. 왜냐하면, 무조건 쓰이거든요
캐글 타이타닉이란?
-
역사상 최대 해난사고 데이터
-
탑승객의 생존여부 예측 모델을 구하는 것이 핵심입니다.
Flow
-
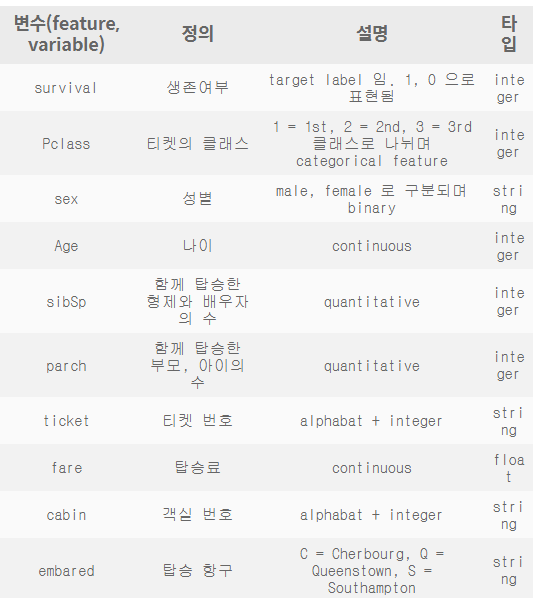
데이터 셋 확인
-
정제 데이터
-
Null data(수정 필요)
-
-
탐색적 데이터 분석(EDA)
- feature 분석 및 상관관계 파악
- 시각화 툴을 이용하여 insight얻기
-
feature Engineering
-
모델 성능 높이기 위한 것
-
one-hot encoding, class로 나누기, 구간 나누기, 텍스트 처리등 시도
-
-
Model 만들기
- 머신러닝: sklearn을 사용
- 딥너링: Tensorflow, Pytorch
-
모델 학습 및 예측
-
trainset을 가지고 모델 학습
-
testset를 가지고 prediction
-
-
모델 평가
-
예측 성능이 원하는 수준인지 판단
-
문제에 따라 모델을 평가한느 방식이 달라짐
-
학습된 모델이 무엇을 학습하는지 확인
-
#필요한 라이브러리 호출
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#항상 쓰는 것이 좋음
#seaborn scheme를 세팅하여 graph의 font size를 지정할 필요없다.
#즉, seaborn의 font_scale를 사용하면 편하다
plt.style.use('seaborn')
sns.set(font_scale=2.5)
import missingno as msno
#ignore warnings
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline#데이터 확인
df_train = pd.read_csv('./input/train.csv')
df_test = pd.read_csv('./input/test.csv')df_train.head()#train데이터 상위 5개 추출
df_train.describe()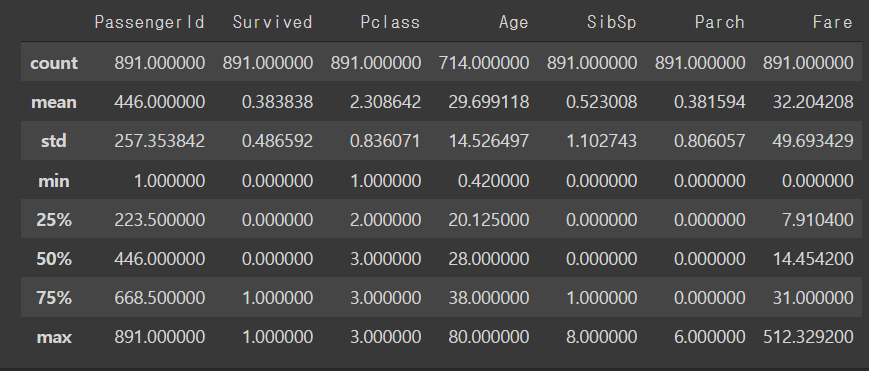
df_test.describe()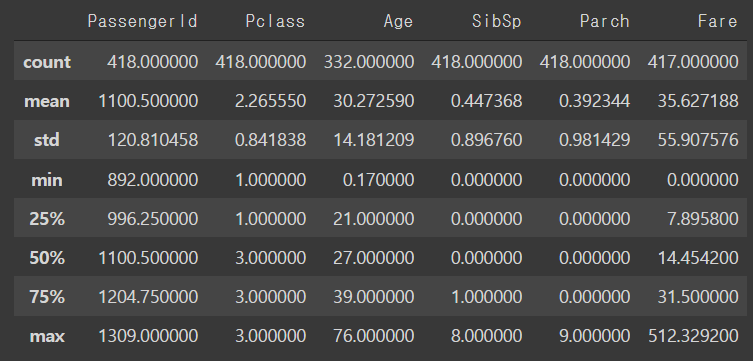
Null data check
-
Train
-
Age: 약 20%
-
Cabin::약 80%
-
Embarked: 약 22%
-
-
Test
-
Age: 약 20%
-
Cabin::약 80%
-
for col in df_train.columns:
msg = 'coluumn: {:>10}\t Percent of NaN value: {:.2f}%'.format(col, 100 * (df_train[col].isnull().sum()/ df_train[col].shape[0]))
print(msg)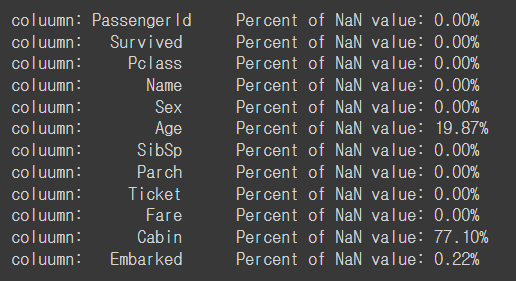
for col in df_test.columns:
msg = 'column: {:>10}\t Percent of NaN value: {:.2f}%'.format(col, 100 * (df_test[col].isnull().sum()/df_test[col].shape[0]))
print(msg)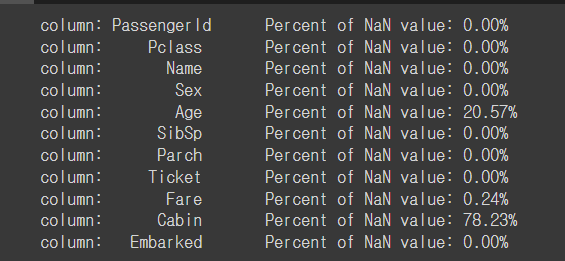
#msno라이브러리를 통해서 null data 시각적으로 보기
msno.matrix(df=df_train.iloc[:, :], figsize=(8,8), color=(0.8, 0.5, 0.2))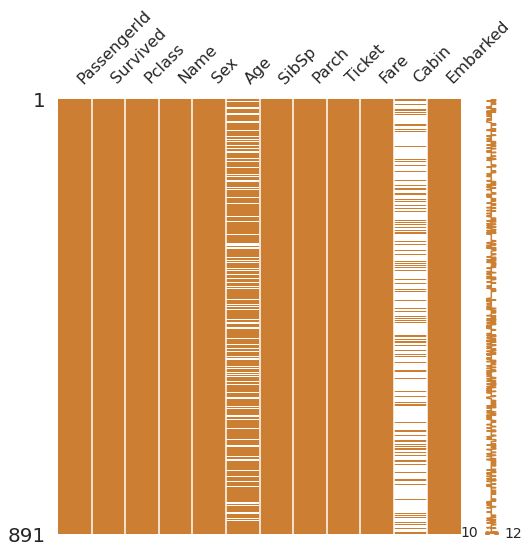
msno.bar(df=df_train.iloc[:, :], figsize=(8,8), color=(0.8,0.5,0.2))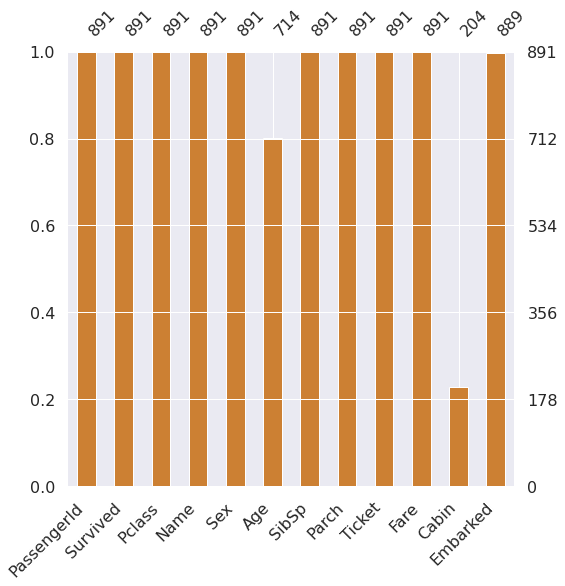
msno.bar(df=df_test.iloc[:, :], figsize = (8,8), color =( 0.8,0.5,0.2))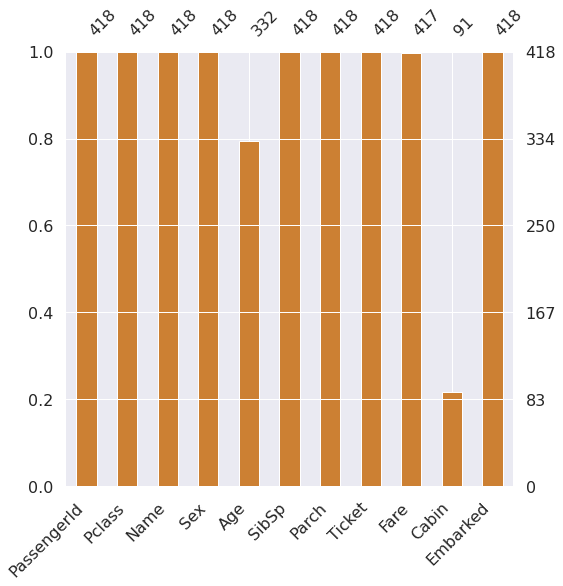
Target label확인
-
target label이 어떤 distribution 확인
-
binary classification경우 1과 0의 분포에 따라서 모델 평가 방식 달라짐
f, ax = plt.subplots(1, 2, figsize =(18,8))
df_train['Survived'].value_counts().plot.pie(explode=[0,0.1], autopct = '%1.1f%%', ax=ax[0], shadow=True)
ax[0].set_title('Pie chart - Survived')
ax[0].set_ylabel('')
sns.countplot('Survived', data=df_train, ax=ax[1])
ax[1].set_title('Bar chart - Survived')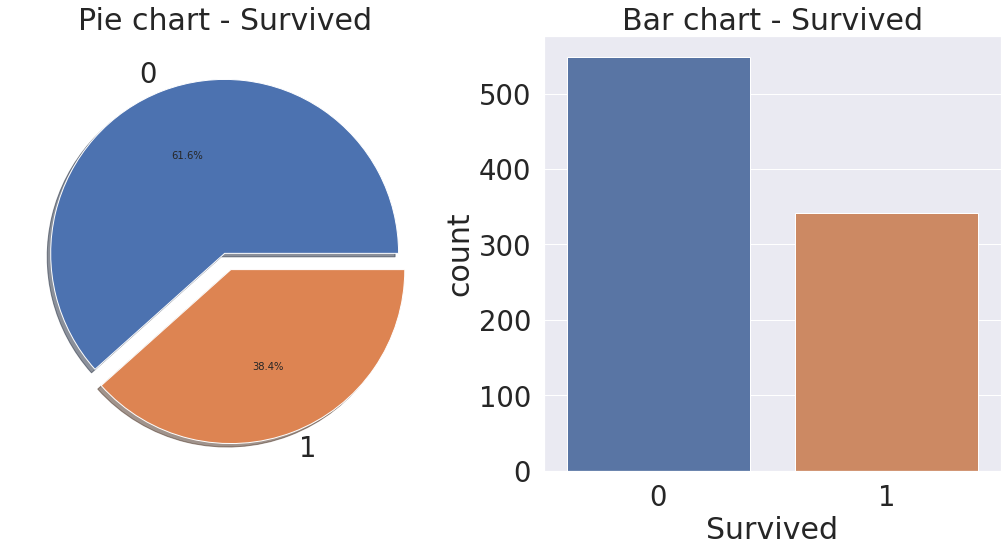

성장을 도울 아카이빙 블로그