간단 코드: 링크텍스트
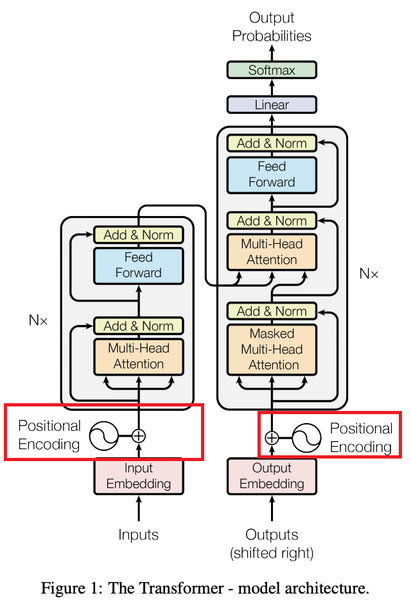
트랜스포머
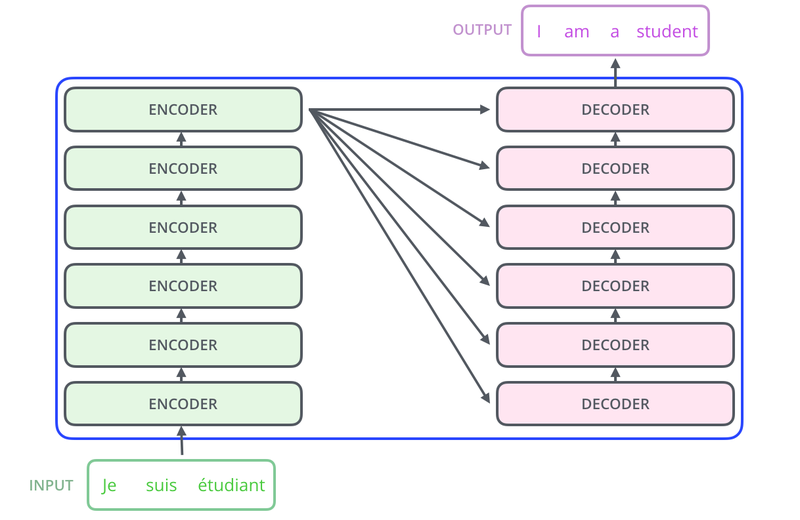
*병렬구조
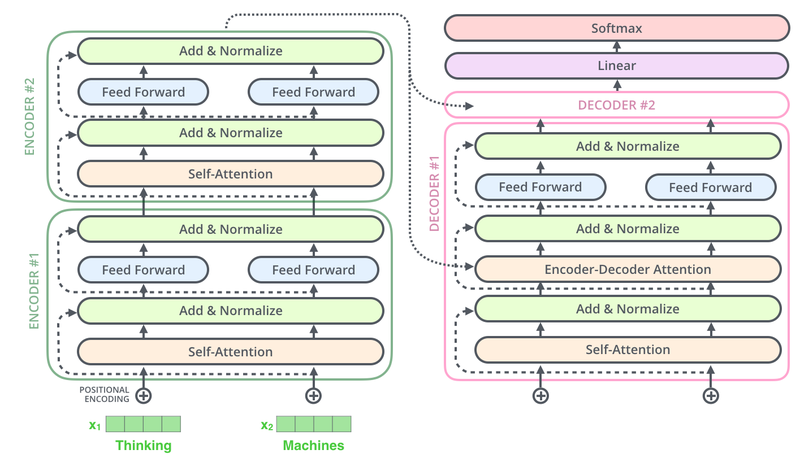
*내부 구조
*심층 구조
인코더
-
입력 문장이 들어간다
-
누적해서 올린 인코더의 층을 통해 정보 뽑기
인코더 층 만들기
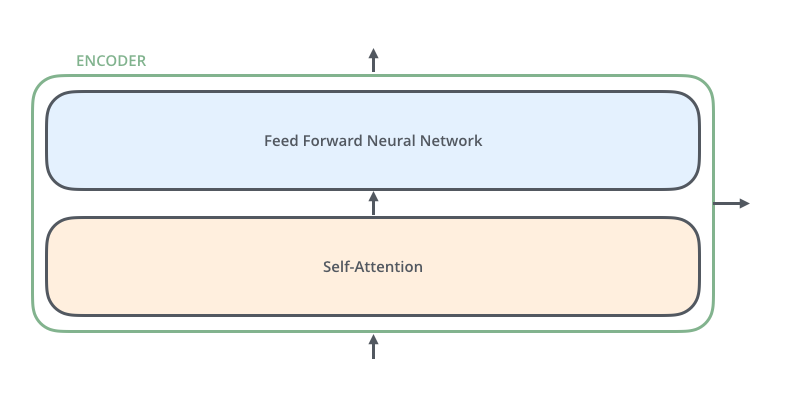
- 셀프 어텐션
- 멀티 헤드 어텐션으로 병렬적으로 이뤄짐
# 인코더 하나의 레이어를 함수로 구현.
# 이 하나의 레이어 안에는 두 개의 서브 레이어가 존재합니다.
def encoder_layer(units, d_model, num_heads, dropout, name="encoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
# 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 첫 번째 서브 레이어 : 멀티 헤드 어텐션 수행 (셀프 어텐션)
attention = MultiHeadAttention(
d_model, num_heads, name="attention")({
'query': inputs,
'key': inputs,
'value': inputs,
'mask': padding_mask
})
# 어텐션의 결과는 Dropout과 Layer Normalization이라는 훈련을 돕는 테크닉을 수행
attention = tf.keras.layers.Dropout(rate=dropout)(attention)
attention = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(inputs + attention)
# 두 번째 서브 레이어 : 2개의 완전연결층
outputs = tf.keras.layers.Dense(units=units, activation='relu')(attention)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 완전연결층의 결과는 Dropout과 LayerNormalization이라는 훈련을 돕는 테크닉을 수행
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention + outputs)
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)
print("슝=3")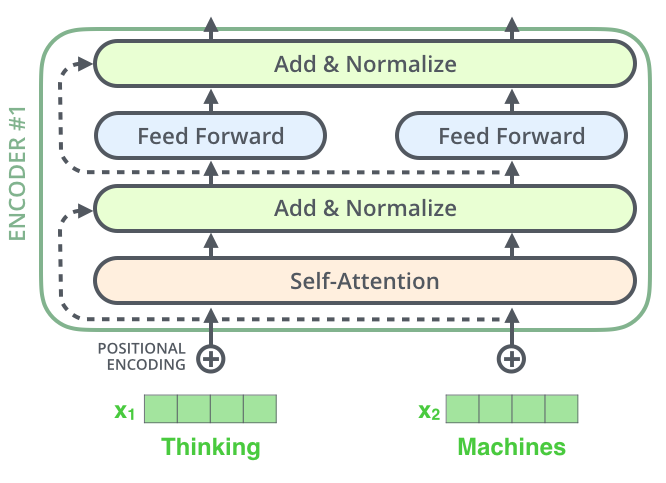
1-1. 인코더 층을 쌓아 인코더 만들기
-
임베딩 층과 포지셔널 인코딩 연결한 후 원하는 만큼 쌓으면 된다
-
Layer Normalization: 각 서브 층 이후에 훈련 돕는다.
-
num_layers : 하이퍼파라미터로 인코더 층 갯수
def encoder(vocab_size,
num_layers,
units,
d_model,
num_heads,
dropout,
name="encoder"):
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 임베딩 레이어
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
# 포지셔널 인코딩
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# num_layers만큼 쌓아올린 인코더의 층.
for i in range(num_layers):
outputs = encoder_layer(
units=units,
d_model=d_model,
num_heads=num_heads,
dropout=dropout,
name="encoder_layer_{}".format(i),
)([outputs, padding_mask])
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)
print("슝=3")- 피드 포워드 신경망
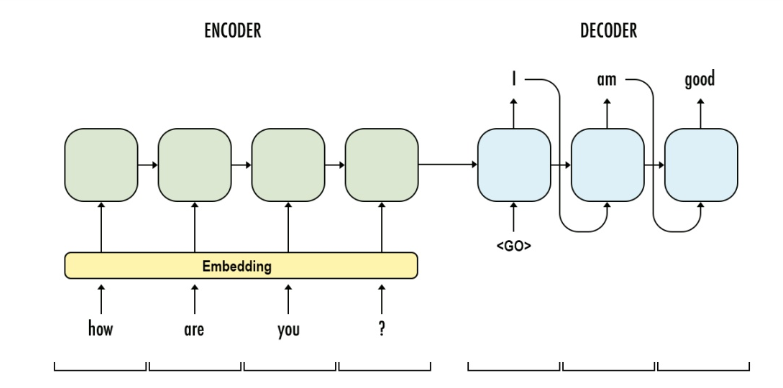
디코더
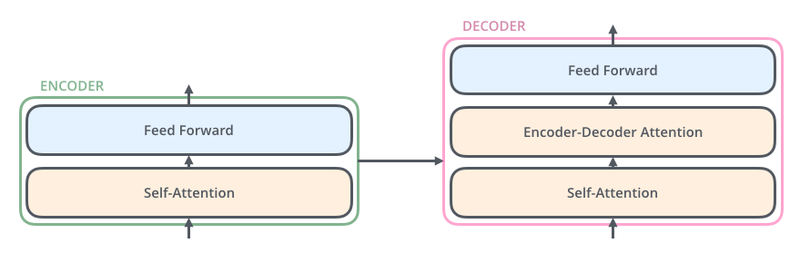
-
출력 문장 생성
-
누적해서 올린 디코더의 층을 통해 출력 문자의 단어 만들기
-
셀프 어텐션
-
인코더-디코더 어텐션
-
Query가 디코더의 벡터
-
Key 와 Value가 인코더의 벡터
-
스케이르 닷 프로덕트 어텐션을 멀티 헤드 어텐션으로 병렬적 수행
- 피드 포워드 신경망
- Code
# 디코더 하나의 레이어를 함수로 구현.
# 이 하나의 레이어 안에는 세 개의 서브 레이어가 존재합니다.
def decoder_layer(units, d_model, num_heads, dropout, name="decoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
enc_outputs = tf.keras.Input(shape=(None, d_model), name="encoder_outputs")
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name="look_ahead_mask")
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 첫 번째 서브 레이어 : 멀티 헤드 어텐션 수행 (셀프 어텐션)
attention1 = MultiHeadAttention(
d_model, num_heads, name="attention_1")(inputs={
'query': inputs,
'key': inputs,
'value': inputs,
'mask': look_ahead_mask
})
# 멀티 헤드 어텐션의 결과는 LayerNormalization이라는 훈련을 돕는 테크닉을 수행
attention1 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention1 + inputs)
# 두 번째 서브 레이어 : 마스크드 멀티 헤드 어텐션 수행 (인코더-디코더 어텐션)
attention2 = MultiHeadAttention(
d_model, num_heads, name="attention_2")(inputs={
'query': attention1,
'key': enc_outputs,
'value': enc_outputs,
'mask': padding_mask
})
# 마스크드 멀티 헤드 어텐션의 결과는
# Dropout과 LayerNormalization이라는 훈련을 돕는 테크닉을 수행
attention2 = tf.keras.layers.Dropout(rate=dropout)(attention2)
attention2 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention2 + attention1)
# 세 번째 서브 레이어 : 2개의 완전연결층
outputs = tf.keras.layers.Dense(units=units, activation='relu')(attention2)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 완전연결층의 결과는 Dropout과 LayerNormalization 수행
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(outputs + attention2)
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)
print("슝=3")- 디코더 층을 쌓아 디코더 만들기
- 임베딩 층과 포지셔널 인코딩 연결하여 원하는 만큼 쌓기
def decoder(vocab_size,
num_layers,
units,
d_model,
num_heads,
dropout,
name='decoder'):
inputs = tf.keras.Input(shape=(None,), name='inputs')
enc_outputs = tf.keras.Input(shape=(None, d_model), name='encoder_outputs')
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name='look_ahead_mask')
# 패딩 마스크
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 임베딩 레이어
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
# 포지셔널 인코딩
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
# Dropout이라는 훈련을 돕는 테크닉을 수행
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
for i in range(num_layers):
outputs = decoder_layer(
units=units,
d_model=d_model,
num_heads=num_heads,
dropout=dropout,
name='decoder_layer_{}'.format(i),
)(inputs=[outputs, enc_outputs, look_ahead_mask, padding_mask])
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)
print("슝=3")포지션 인코딩
-
임베딩 벡터로 변환하는 벡터화 과정 거친다
-
RNN계열과 유사하지만 다른 것이 있다. 그것은 임베딩 벡터에 값을 더해준 뒤에 입력으로 사용

-
문장에 있는 모든 단어를 한꺼번에 받기 때문에 어순 정보를 알 수 없으므로 몇 번째 어순으로 입력되었는지 추가로 알려주기 위해서이다.
-
삼각함수 덧셈정리 이용하여 단어의 순서 정보를 더해준다.
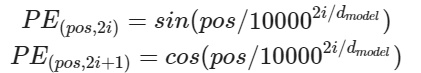
-
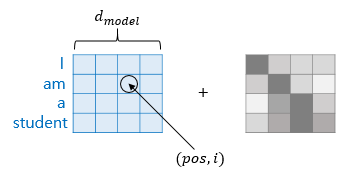
임베딩 벡터가 모여 만든 문장의 벡터 행렬과 포지셔널 인코딩 행렬의 덧셈 연산으로 이뤄짐
-
dmodel: 임베딩 벡터의 차원
-
pos: 입력 문장에서의 임베딩 벡터의 위치
-
i: 임베딩 벡터 내의 차원의 인덱스
어텐션
- 기본 구조
-
단어 정보를 함축한 벡터: 쿼리, 키, 값
-
단어 벡터: 임베딩 벡터가 아닌 트랜스포머의 여러 연산 거친 후의 벡터
-
(쿼리 - 키) 유사도 구하기
-
유사도 -> 값에 반영
-
모든 값을 더함 (= 어텐션 값)

- 트랜스포머에서 사용된 어텐션
2-1. 어텐션의 위치

2-2. 어텐션의 종류
-
인코더 셀프 어텐션: 인코더의 입력으로 들어간 문장 내 단어들이 서로 유사도 구함
-
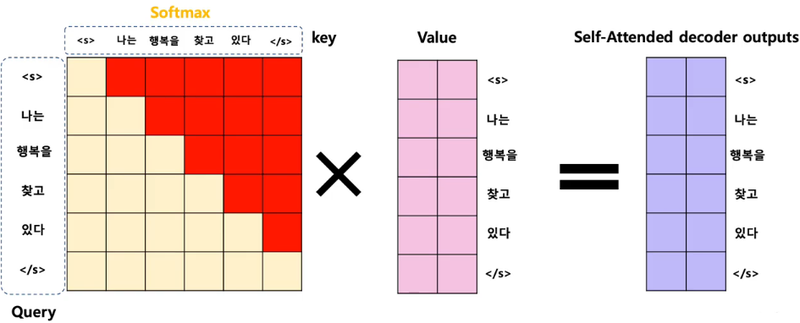
디코더 셀프 어텐션: 단어를 1개씩 생성하는 디코더가 이미 생성된 앞 단어들과의 유사도 구함
-
(인코더-디코더) 어텐션: 디코더의 예측성을 높이기 위해 인코더에 입력된 단어들과의 유사도 구하기

- 셀프 어텐션
- 유사도를 구하는 대상이 현재 문장 내의 단어들(대명사를 쓸 때 필요할 듯)

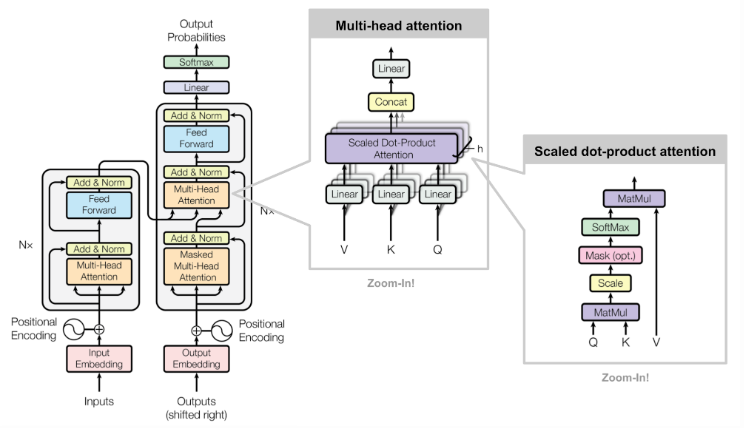
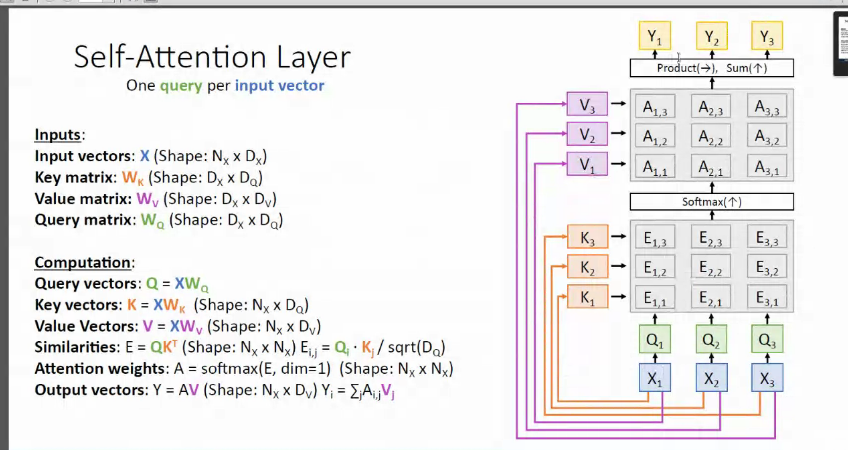
- Scaled Dot Product Attention
- 트랜스포머에서 어텐션 값 구하는 방법

-
Q,K,V는 단어벡터를 행으로 하는 문장 행렬
-
벡터의 내적은 벡터의 유사도 의미
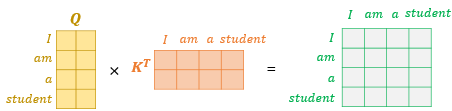
-
스케일링: 특정 값을 분모로 사용하여 값의 크기 조절
- 유사도 Normalization(with softmax): 0~1사이의 값 [유사도 구하는 과정]-
문장 행렬 V 곱하기 : 어텐션 값 얻는다.

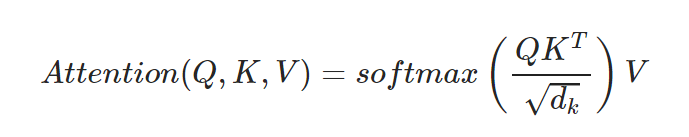
-
-
CODE
# 스케일드 닷 프로덕트 어텐션 함수
def scaled_dot_product_attention(query, key, value, mask):
# 어텐션 가중치는 Q와 K의 닷 프로덕트
matmul_qk = tf.matmul(query, key, transpose_b=True)
# 가중치를 정규화
depth = tf.cast(tf.shape(key)[-1], tf.float32)
logits = matmul_qk / tf.math.sqrt(depth)
# 패딩에 마스크 추가
if mask is not None:
logits += (mask * -1e9)
# softmax적용
attention_weights = tf.nn.softmax(logits, axis=-1)
# 최종 어텐션은 가중치와 V의 닷 프로덕트
output = tf.matmul(attention_weights, value)
return output
print("슝=3")- 병렬 처리
-
num_heads: 병렬적으로 몇 개의 어텐션 연산 수행할지 결정하는 하이퍼파라미터, 수 만큼 쪼개어 어텐션을 수행하고 num_heads의 개수만큼 어텐션 값 행렬을 다시 하나로 concatenate한다.
-
d_model: 임베딩 벡터의 차원
-
문장 행렬의 크기: 문장의 길이(행), d_model(열)
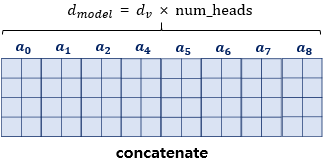
- 멀티-헤드 어텐션
-
병렬처리 시 얻을 수 있는 효과
-
한 번의 어텐션 수행을 하면 놓칠 수 있는 정보를 놓치지 않게 됩니다.
-
어텐션이 서로 다른 셀프 어텐션 결과를 얻을 수 있게 됨
- CODE
import tensorflow as tf
import tensorflow_datasets as tfds
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, name="multi_head_attention"):
super(MultiHeadAttention, self).__init__(name=name)
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.query_dense = tf.keras.layers.Dense(units=d_model)
self.key_dense = tf.keras.layers.Dense(units=d_model)
self.value_dense = tf.keras.layers.Dense(units=d_model)
self.dense = tf.keras.layers.Dense(units=d_model)
def split_heads(self, inputs, batch_size):
inputs = tf.reshape(
inputs, shape=(batch_size, -1, self.num_heads, self.depth))
return tf.transpose(inputs, perm=[0, 2, 1, 3])
def call(self, inputs):
query, key, value, mask = inputs['query'], inputs['key'], inputs[
'value'], inputs['mask']
batch_size = tf.shape(query)[0]
# Q, K, V에 각각 Dense를 적용합니다
query = self.query_dense(query)
key = self.key_dense(key)
value = self.value_dense(value)
# 병렬 연산을 위한 머리를 여러 개 만듭니다
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
# 스케일드 닷 프로덕트 어텐션 함수
scaled_attention = scaled_dot_product_attention(query, key, value, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
# 어텐션 연산 후에 각 결과를 다시 연결(concatenate)합니다
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model))
# 최종 결과에도 Dense를 한 번 더 적용합니다
outputs = self.dense(concat_attention)
return outputs
print("슝=3")마스킹(Masking)
- 정의: 특정 값들을 가려 실제 연산에 방해되지 않게함
패딩 마스킹
-
서로 문장의 길이가 다를 때 길이를 맞춰줌
-
0은 실제 의미는 없기 때문에 연산 시 제외한다.
- 숫자가 0이 부분 체크한 벡터 리턴- 숫자가 0인 위치에서만 1이 나온다
- 숫자가 0이 아닌 위치에서는 숫자 0인 벡터 출력
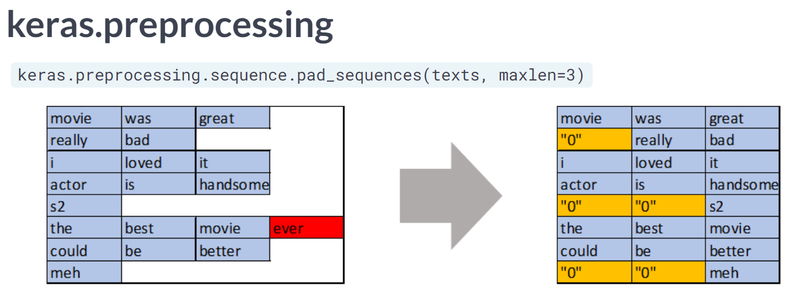
-
케라스의 pad_sequences() 시각화
룩 어헤드 마스킹(다음 단어 가리기)
-
문장 단위 입력이라서 다음 단어 예측이 가능하다
-
이전 단어를 기반으로 다음 단어 예측 훈련시키기
-
위의 문제를 해결하는 법으로, 다음에 나올 단어를 참고하지 않도록 가리는 방법으로 Query 단어 뒤에 나오는 Key단어들에 대해서 마스킹한다