Baseline: 링크텍스트
CODE: 링크텍스트
Super Resolution
-
정의: 저해상도 영상을 고해상도 영상으로 변환하는 작업
-
방식: 고해상도 이미지 준비 -> 특정 처리 과정 -> 저해상도 이미지 생성 -> 입력 -> 고해상도 이미지 복원
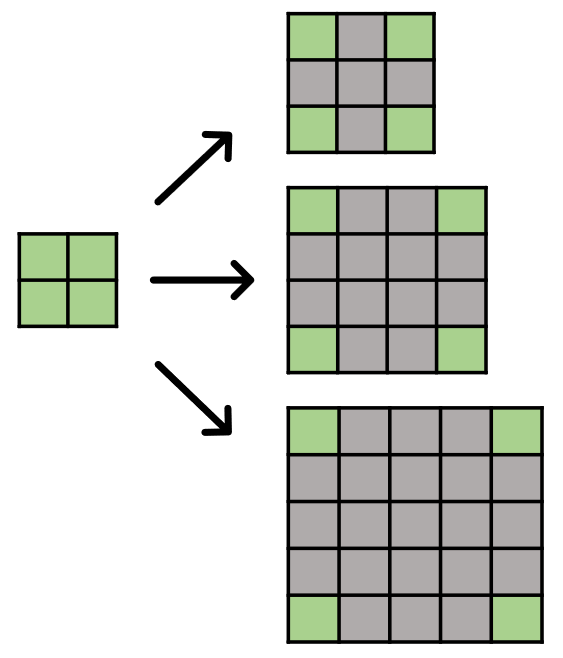
-
문제:
i) ill-posed(inverse) problem: 매우 다양한 경우의 수가 있다
ii) 복잡도: 제한된 정보를 이용해서 많은 정보를 만들어 낸다.
Interpolation
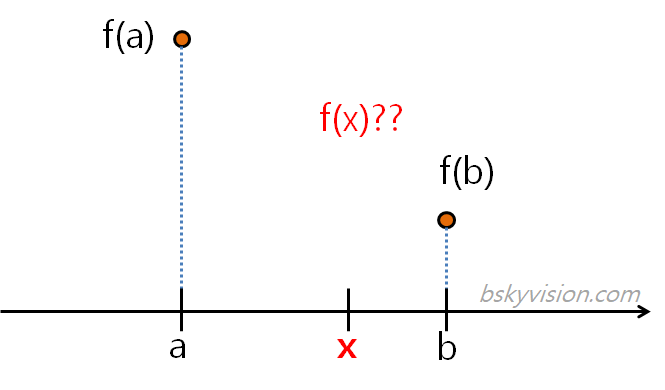
-
정의: 알려진 두 점 사이의 특정 지점에 대한 값 추정
-
특징: Super Resolution수행하는 가장 쉬운 방법
-
종류:
- Bilinear interpolation: Linear interpolation을 2차원으로 확장, 4개의 값을 이용
- Linear interpolation: 2개의 값 이용하여 새로운 픽셀 예측선형보간법(Linear interpolation)
-
두 점 사이에 직선을 그리고 그 선을 이용하여 추정
-
사잇값 정리
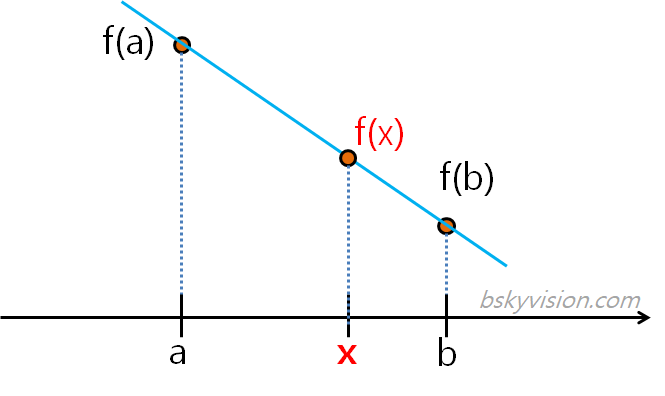
쌍선형보간법(bilinear interpolation)
-
선형 보간법을 2차원으로 확장시킨 것
-
이웃한 4 (2 * 2) 점을 참조
삼차 보간법(cubic interpolation)
- 3차 함수 사용
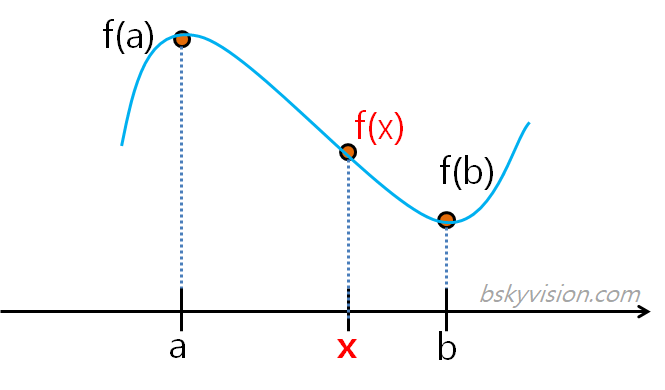
쌍삼차보간법(bicubic interpolation)
-
2차원으로 확장시킨 것이지만 원리 상의 차이는 없다
-
16(=4 * 4) 점 참조
SRCNN

-
순서
- 저해상도 이미지를 쌍삼차보간법을 통해 원하는 이미지 늘리기(입력 데이터)
- 3개의 convolutional layer 거침
- 고해상도 이미지생성
- 고해상도 이미지와 실제 고해상도 이미지 사이의 차이를 역전파하여 가중치 학습
-
용어 정리
-
Patch extraction and representation : 저해상도 이미지에서 patch를 추출한다.
-
Non-linear mapping : Patch를 다른 차원의 patch로 비선형 매핑한다.
-
Reconstruction : Patch로부터 고해상도 이미지를 생성한다.
-
-
손실함수 : MSE
SCRNN이후 발전된 모델
- VDSR
- 구현 방식은 SRCNN과 동일하나, convolutional layer를 20개 사용하고, 최종 고해상도 이미지 생성 직전에 처음 이미지 더하는 residual learning이용
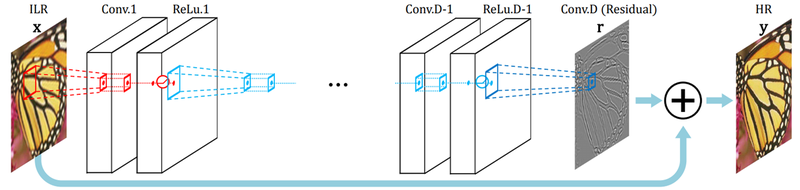
- RDN
- 저해상도 이미지 입력 시, 여러 단계 convolutional layer 거친 후 각 layer에서 나오는 출력 활용. 그리고 출력 결과로 생성된 특징을 화살표에 따라서 연산을 여러번 재활용해서 사용이 가능하다.
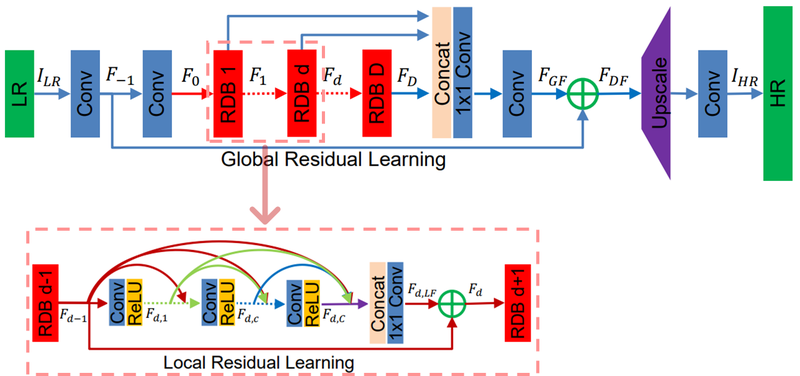
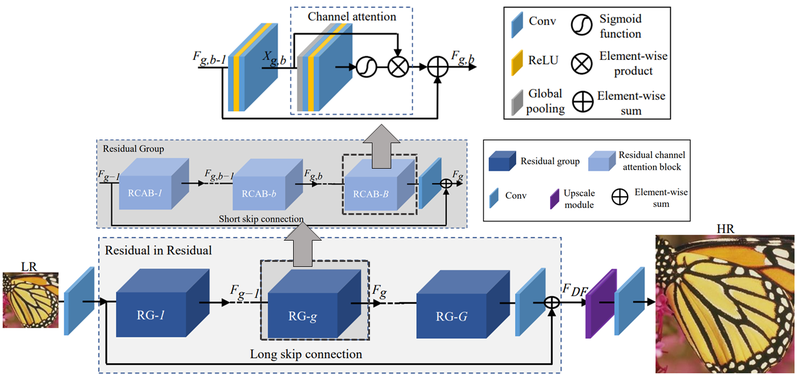
- RCAN
- convolutional layer의 결과를 각각의 특징맵 대상으로 한 해서 균일한 중요도를 갖는 것이 아니라 일부 중요한 채널에만 선택적 집중하도록 유도한다.
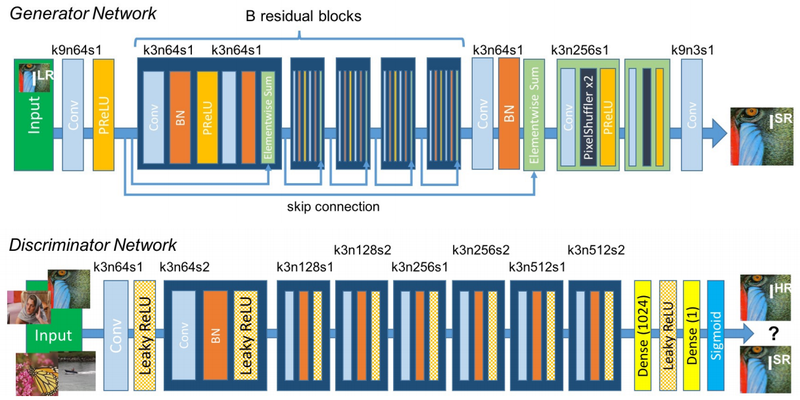
SRGAN(Super Resoultion + GAN)
- Photo- Realistic: 현실성 기반.
- loss function
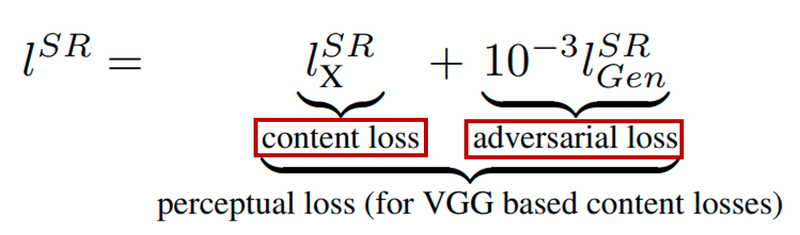
- content loss : generator을 이용해 얻은 가짜 고해상도 이미지를 실제 고해상도 이미지와 직접 비교하는 것이 아닌, 사전 학습된 VGG모델에 입력해 특성맵에서의 차이 계산
- adversarial loss:GAN의 loss
- perceptual loss: content loss + adversarial lossSRGAN 구현
-
Generator : 저해상도 이미지를 입력받아 고해상도 이미지 생성하여 구현됨, skip-connection가지고 Functional API 이용한다.
-
Convolutional layer: hyperparameter 설정 정보
-
k : kernel size
-
n: 사용 필터의 수
-
s: stride
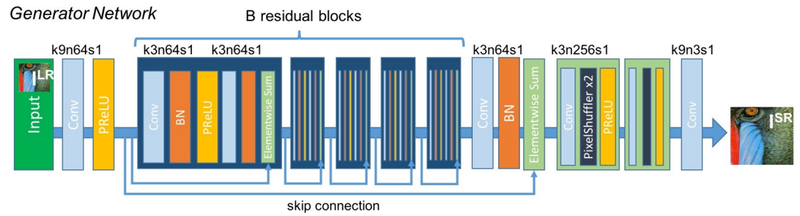
- CODE
from tensorflow.keras import Input, Model, layers
# 그림의 파란색 블록을 정의합니다.
def gene_base_block(x):
out = layers.Conv2D(64, 3, 1, "same")(x)
out = layers.BatchNormalization()(out)
out = layers.PReLU(shared_axes=[1,2])(out)
out = layers.Conv2D(64, 3, 1, "same")(out)
out = layers.BatchNormalization()(out)
return layers.Add()([x, out])
# 그림의 뒤쪽 연두색 블록을 정의합니다.
def upsample_block(x):
out = layers.Conv2D(256, 3, 1, "same")(x)
# 그림의 PixelShuffler 라고 쓰여진 부분을 아래와 같이 구현합니다.
out = layers.Lambda(lambda x: tf.nn.depth_to_space(x, 2))(out)
return layers.PReLU(shared_axes=[1,2])(out)
# 전체 Generator를 정의합니다.
def get_generator(input_shape=(None, None, 3)):
inputs = Input(input_shape)
out = layers.Conv2D(64, 9, 1, "same")(inputs)
out = residual = layers.PReLU(shared_axes=[1,2])(out)
for _ in range(5):
out = gene_base_block(out)
out = layers.Conv2D(64, 3, 1, "same")(out)
out = layers.BatchNormalization()(out)
out = layers.Add()([residual, out])
for _ in range(2):
out = upsample_block(out)
out = layers.Conv2D(3, 9, 1, "same", activation="tanh")(out)
return Model(inputs, out)PSNR과 SSIM
PSNR
-
영상 내 신호가 가질 수 있는 최대 신호에 대한 잡은 비율
-
영상 압축시, 화질 손실량에 대해 평가 목적
-
데시벨 단위
-
PSNR 수치가 높을 수록 원본 손실 적다
-
peak_signal_noise_ratio 메서드 이용
-
상한값이 없다
SSIM
-
영상의구조 정보 고려하여 구조 정보 변화시키지 않는 계산하기
-
SSIM이 높을 수록 원본 영상의 품질에 가깝다
-
structural_similarity 메서드 이용
-
0~1사이의 값을 가진다
