Intro
이변량 자료와 상관계수
두 변수가 모두 질적인 자료인 경우
첫 번째 자료는 범주가 r개그리고 두 번째 자료는 c개의 범주로 구성이 되어 있을 때 두 개의 변수를 동시에 고려하면 행렬의 형태로 나타나는데 이 행렬을 표로 요약한 것을 r x c 분할표, 영어로는 r x c contingency table이라고 부릅니다.
*분할표
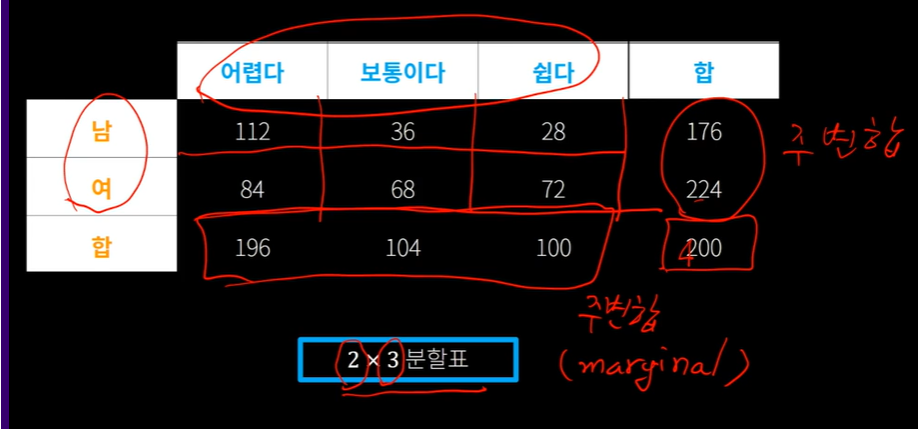
통계학개론을 수강하는 400명의 학생들에게 시험을 본 후 문제 수준에 대해서 조사 했습니다.
첫 번째 변수로 학생을 남녀라는 category로 하겠습니다.
그 다음 두 번째 변수로 시험문제의 수준에 대해서 세 개의 category를 생각 했습니다.
어렵다, 보통이다, 쉽다.
그러면 첫 번째 변수가 두 개의 category 두 번째 변수가 세 개의 category 이니까 2 x 3 분할표를 그릴 수 있습니다.
그래서 이런 2 x 3 행렬의 형태로 주어지고 주변합이 나와 있습니다.
두 변수 모두 양적인 경우

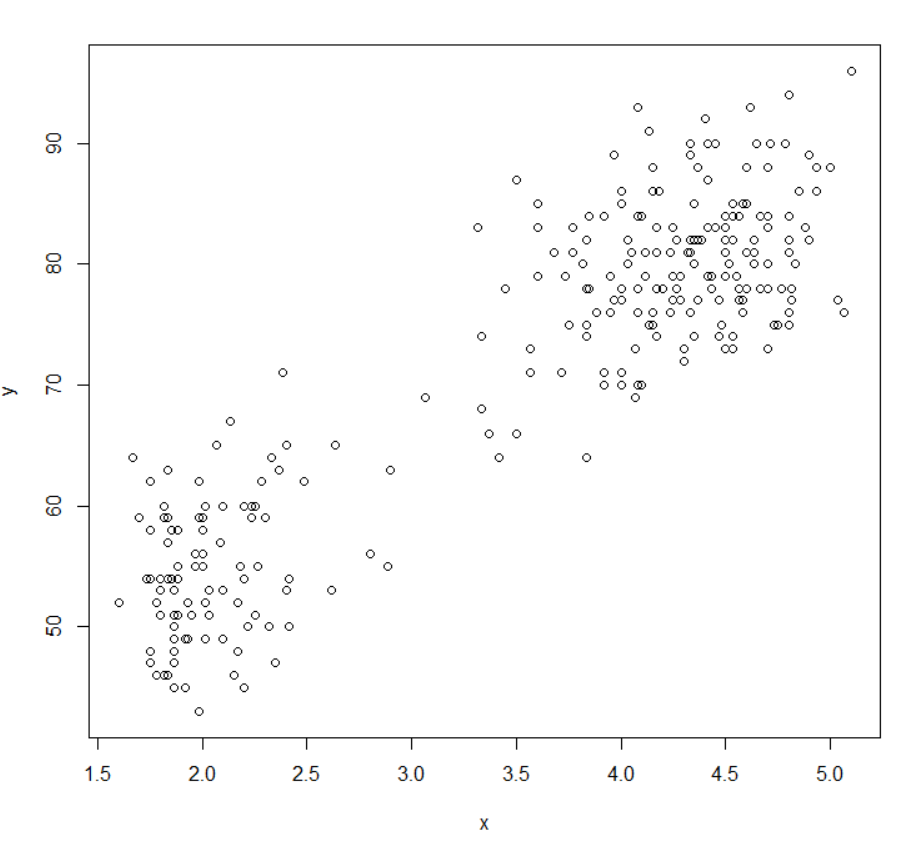
산점도(scatter diagram)
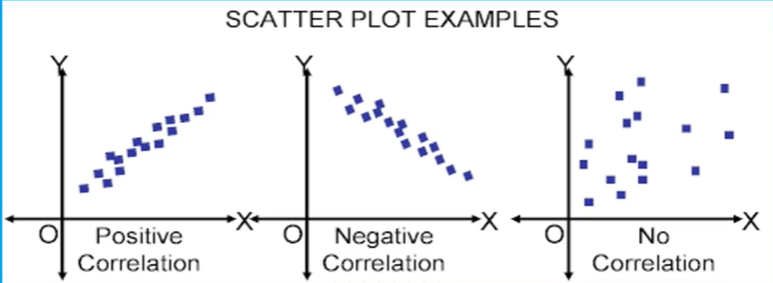
산점도는 2차원 평면에 각 변수의 값에 해당하는 점을 찍은 그림이므로 그래서 2차원 평면에 점을 찍어서 그림을 그리면 하나의 변수는 x축에 또 다른 변수는 y축에 점을 찍을 수 있습니다.
그래서 산점도를 그리다보면 x값이 증가할 때 y값이 증가하는 형태가 있을 수도 있고, 반대로 x 값이 증가할 때 y 값이 감소하는 이런 형태의 산점도를 볼 수가 있고, x값이 증가하든 감소하든 관계없이 y값이 임의로 나타나는 경우가 있습니다.
그래서 이렇게 증가하는 추세에 있는 것을 Positive Correlation이라고 부르고,
그 반대인 경우를 Negative Correlation, 그리고 아무런 규칙 없이 이런 형태로 나타나는 것을 No Correlation이라고 부릅니다.
허위상관과 잠복변수(spurious correlation and lurking variable)
이변량 양적 자료인 경우 산점도를 그리고 상관계수를 계산하지만 그 결과만을 가지고 결론을 내려서는 굉장히 위험하다하는 의미에서 허위상관이라고 합니다.
허위상관을 spurious correaltion, 잠복변수를 lurking variable이라고 부릅니다.
그렇다면 어떤 것이 허위상관이며 어떤 것이 잠복변수인가?
예
*허위상관

이 경우에 잠복변수 lurking variable은 인구가 되므로 이제 이변량 양적변수에 대한 상관관계를 단순히 숫자만 가지고 섯부른 결론을 내려서는 곤란합니다.
결론적으로, ‘어떤 잠복변수가 없는가?’ ‘이것이 허위 상관인지 아닌가?’를 반드시 확인을 하셔야 합니다.
**표본 상관계수(sample correlation coefficent)
두 변수의 선형적 함수를 관꼐를 나타내는 측도로 표본상관계수는 두 변수의 선형적인 함수관계만 나타내지 만약에 두 변수간의 어떤 비선형적인 관계가 있을 경우 분명히 이 두 변수 간에는 함수적 관계가 있지만 상관계수를 구하면 거의 0에 가깝게 나옵니다.
고로, 비선형적인 것은 그 함수관계를 표본상관계수를 통해서 발견할 수 없습니다.
그래서 이 표본 상관계수라는 것은 어디까지나 두 변수간의 선형적인 관계만을 나타내는 척도임을 꼭 명심하기 바랍니다.
표본상관계수는 이런 공식으로 계산됩니다.

여기서 앞으로 가끔 사용하게 될 기호로서 Sxx는 xi에다가 평균을 뺀 것을 제곱해서 다 합한 것이고 Syy, Sxy 도 비슷하게 정의가 되므로 Sxx 에 n-1을 나누어 주는 값을 생각을 하면 이게 바로 x라는 변수에 대한 표본 분산이 될 것입니다.
마찬가지로 표본 y에 대한 표본분산이 되고 이것은 x,y 두 변수에 대한 표본 공분산이 됩니다.
따라서, 이 식을 해석을 하자면 분자는 x, y에 대한 표본 공분산이고, 분모는 각 변수의 표본분산 에 제곱근을 취한 형태입니다.
R을 이용하여 이변량 자료 살펴보기
> data()
> x <- faithful$eruptions # faithful에 있는 eruption이라는 자료로 eruption이라는 자료는 271개로 구성된 자료
> y <- faithful$waiting #aiting을 y
> plot(x,y) #plot은 이차원 평면에 그림을 그리는데 x축은 x값, y축은 y값으로 그림을 그리고 명령어를 실행하면 이렇게 그림이 그려지고 x값이 분출시간이고 y값이 waiting time입니다.
> cor(x,y) #그림을 보시면 양의 상관관계가 있다는 것을 알 수 있고 구체적으로 표본상관계수를 계산하기 위해서는 cor(correlation)이라고 치시면 됩니다.
[1] 0.9008112 #높은 상관 관계