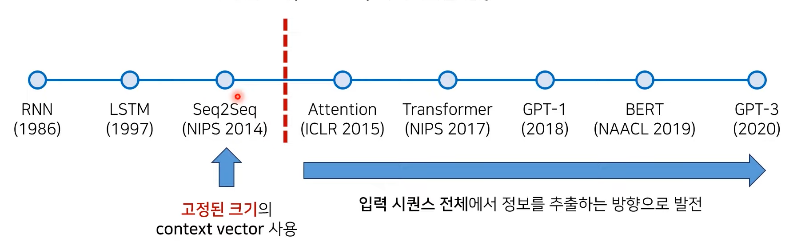
딥러닝 기반의 NLP 발전 과정
-
Transformer 기반으로 고성능 모델이 많아짐
- GPT: Decoder of Transformer
- BERT: Encoder of Transformer
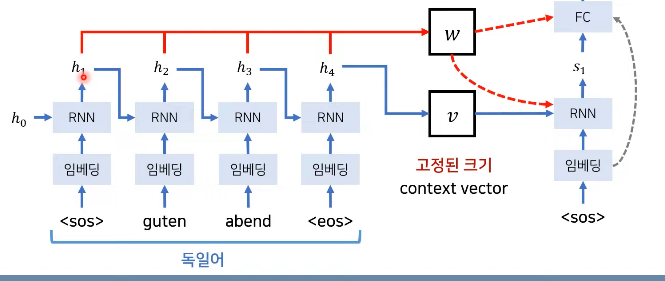
기존 Seq2Seq의 한계점
: Context vector에 문장 정보 압축 -> 병목 현상 발생하여 성능하락.
: 디코터가 context vector 매번 참고 -> 정보 손실 줄어든다(허나, 하나의 벡터로 압축)
: 즉, context vector가 너무 많은 정보를 갖고 있기에 성능 저하를 일으킴.
- 해결 방안: 최신 GPU 이용, 소스 문장의 출력 정보를 입력에다가 넣기!
*Seq2Seq with Attention
: 디코더는 인코더의 모든 출력 참고
: 가중치 벡터를 이용한다.
-
Decoder

: 모든 출력 중에서 어떤 중보가 중요한지 계산
-
i = 디코더가 처리중인 인덱스
-
j = 각각의 인코더 출력 인덱스
-
h = hidden state
-
-
시각화
: Attetion weight -> 출력이 어떤 입력 정보를 참고했는지 알 수 있다.
: 밝기가 높을 수록 확률이 높음
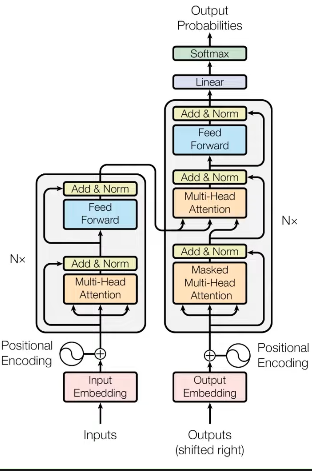
Transformer
-
현대 NLP에서 핵심.
-
RNN, CNN 필요 없다.
: Positional Encoding사용
-
BERT같은 향상된 네트워크 채택
-
인코더와 디코더로 구성
: Attention과정을 여러 레이어에서 반복
Transformer의 동작 원리
-
입력 값 임베딩
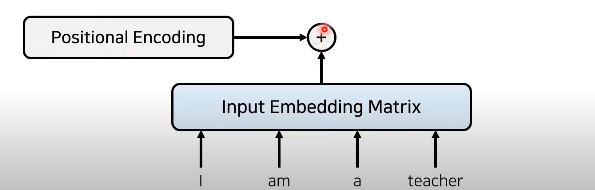
: RNN없이 위치 정보를 포함한 임베딩(Positional Encoding)
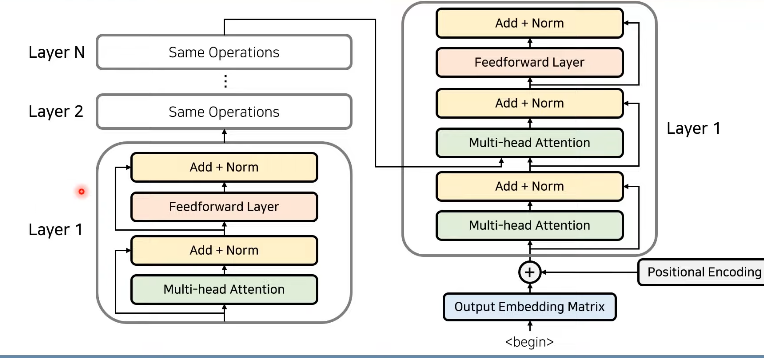
- 인코더
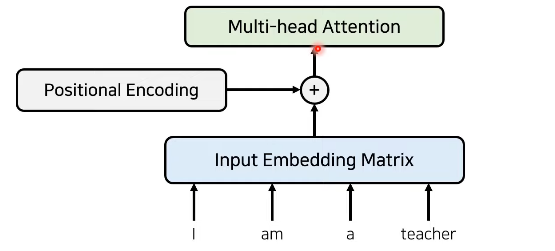
: 임베딩이 끝난 이후 attention진행
: 성능 향상을 위해 Residual Learning 사용(학습 난이도 낮고 수행속도 빨라짐)
: Attention 과 Normalization 반복
- 각 레이어는 서로 다른 파라미터.

-
인코더와 디코더
: 마지막 인코더 레이어의 출략 -> 모든 디코더 레이어에 입력
: RNN 사용안하고 인코더와 디코더를 다수 사용
: 가 나올 때까지 디코더 이용
-
Attention
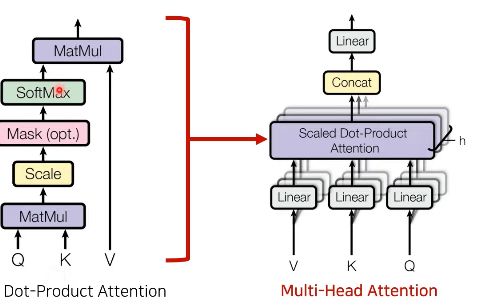
: Multi-Head Attention 레이어 사용

: 세가지 입력 요소
- Query
- Key
- Value
-
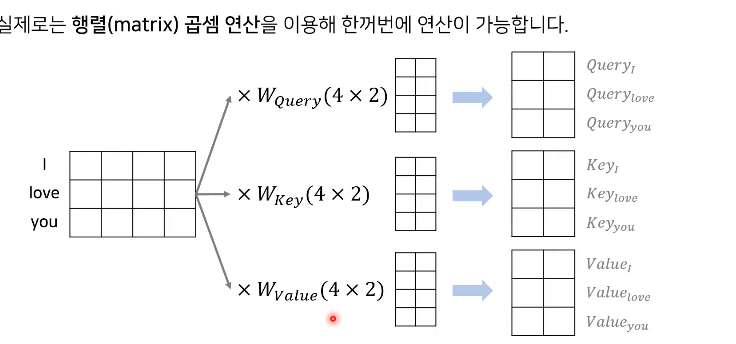
Query, Key, Value
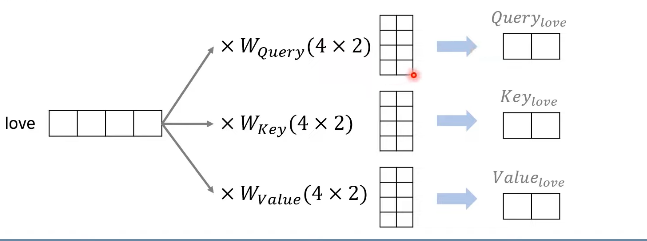
: 각 단어의 임베딩 이용해 생성
: 임베딩 차원 -> Query, Key, Value 차원
: 행렬
-
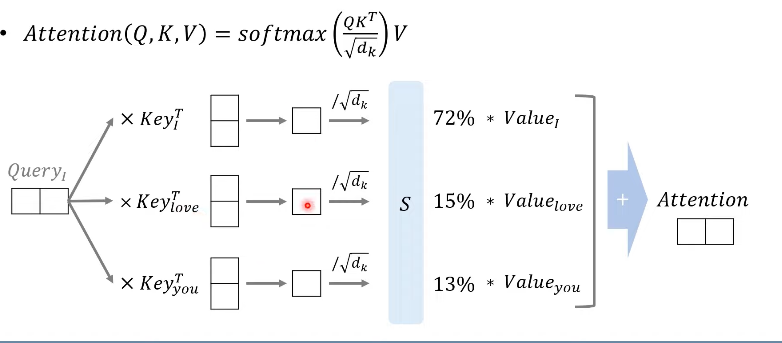
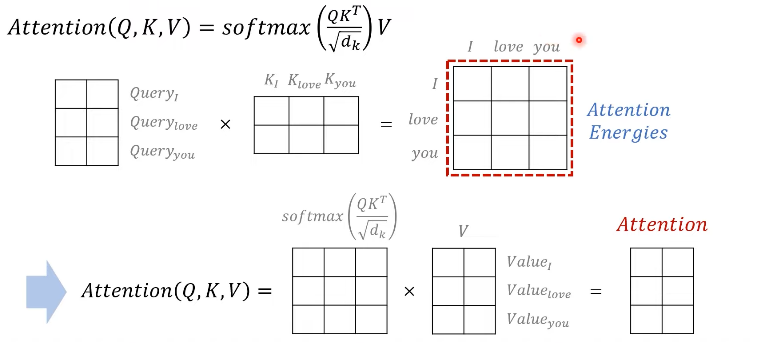
Scaled Dot-Product Attention
Attention Energies:
Flow:
Mask matrix(특정 단어 무시, 음수 무한 값 0-> softmax함수의 출력이 0%에 가까움)

-
Multi-Head Attention
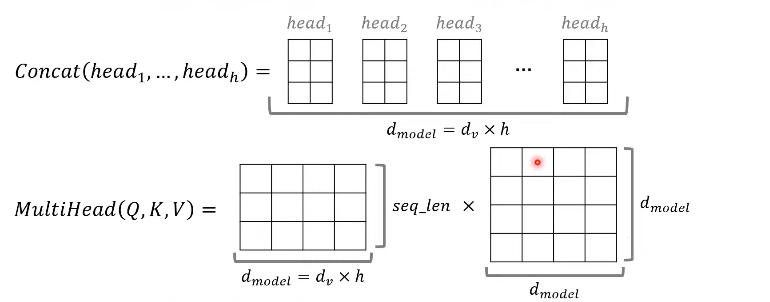
: MultiHead(Q,K,V) 수행 후 차원 유지.
-
Attention 종류
1) Encoder Self-Attention:
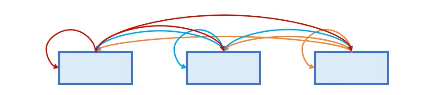
2) Masked Decoder Self-Attention:

3) Encoder-Decoder Attention:

-
Self-Attention
: 인코더 디코더에서 모두 사용
: 입력 문장에서 각 단어의 동의어가 있는지 계산한다.
-
Positional Encoding
: 상대적 위치 정보를 네트워크에 입력.
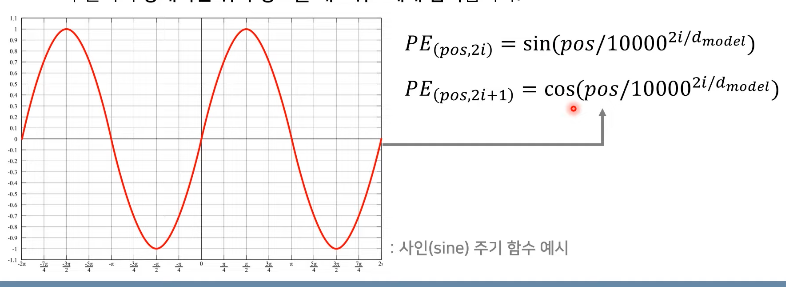
실질적 예시:
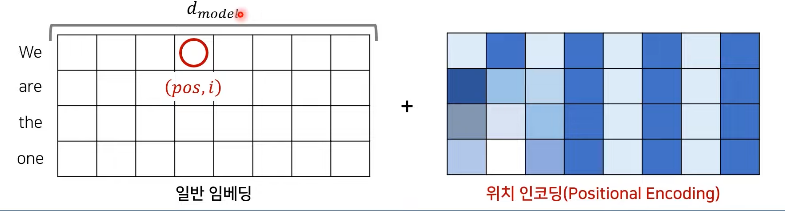
-
코드로 보기
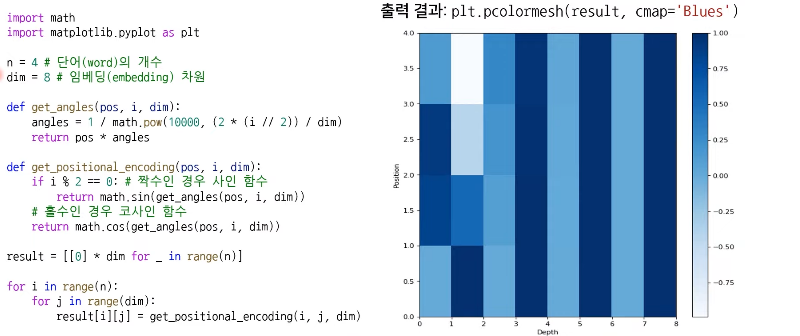
-
