Preview
-
LSTM활용한 효율적인 Seq2Seq제안
-
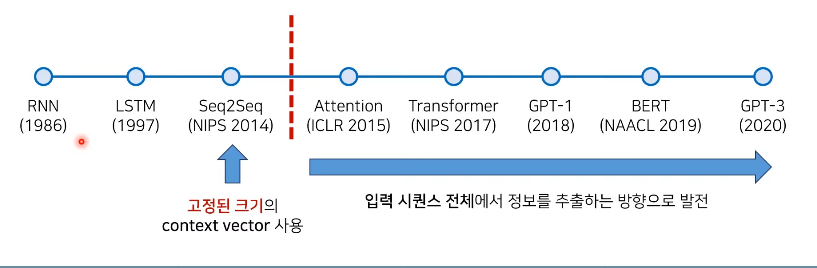
Seq2Seq는 기계 번역의 돌파구 역할
-
현재는 Transformer 아키텍처 이용
-
GPT : Transformer의 디코더
-
BEQR: Transformer의 인코더
-
언어모델
: 시퀀스에 확률을 부여하는 모델
: 특정한 상황에서의 적절한 문장이나 단어 예측
: 하나의 문장은 여러 개의 단어로 구성

: Chain Rule

-
통계적 언어 모델
: 카운트 기반의 접근.(과거)
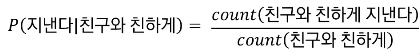
- 단점: 실제 세계에선 이걸 구현하려면 너무나 큰 데이터가 필요하다.
: N-gram 언어 모델(현재, 해결)
: 인접한 일부 단어만 고려하는 아이디어
-
전통적인 RNN 기반의 번역 과정
- 입력과 출력의 크기가 같다
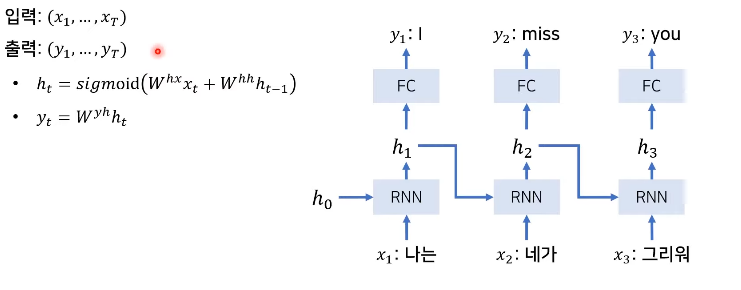
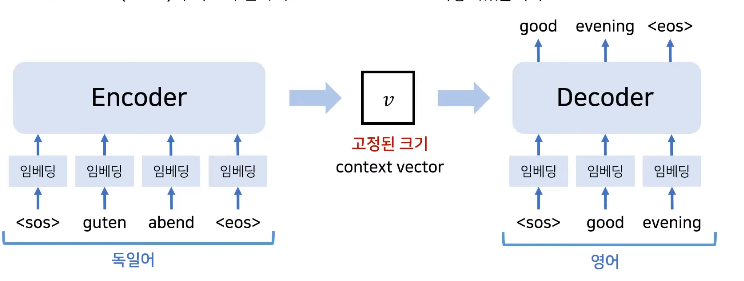
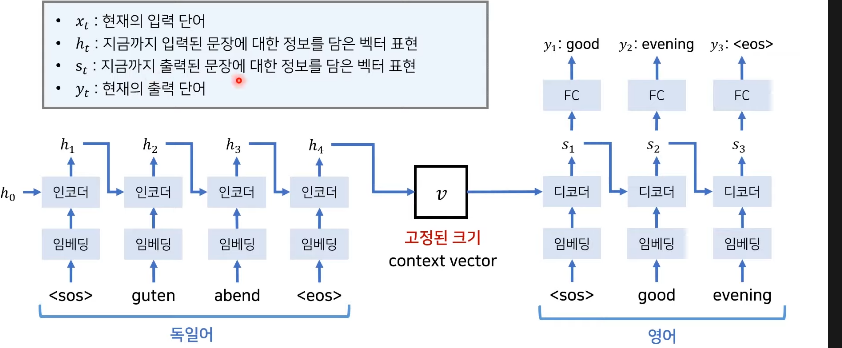
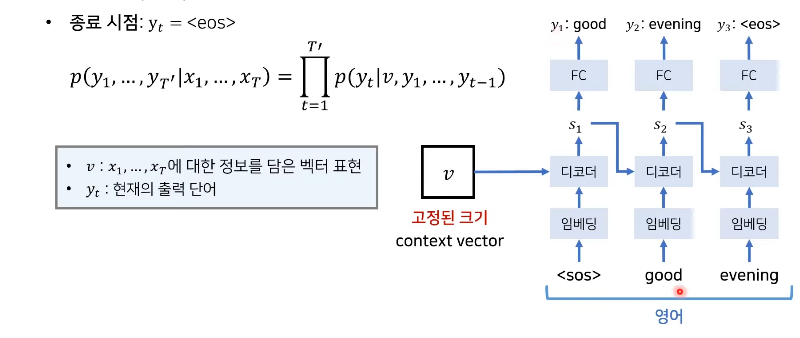
RNN 기반의 Sequence to Sequence
: 초기 RNN기반 모델의 한계점을 극복하기 위해 인코더가 고정된 문맥 벡터 추출.(by LSTM)
: 디코더로 번역 결과 추론
: 인코더의 마지막 hidden state만을 문맥 벡터로 사용.
: 인코더와 디코더는 서로 다른파라미터(W)를 가짐

: 실제 처리 과정
Seq2Seq의 성능 개선 포인트
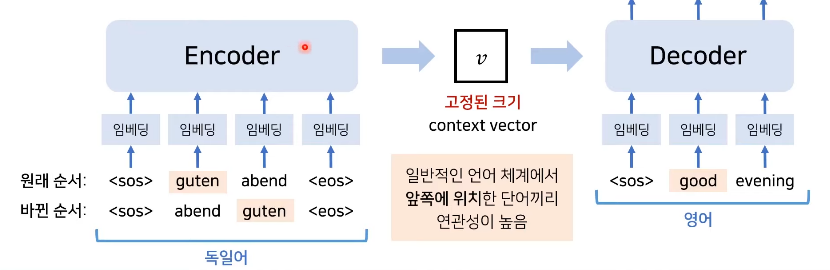
- LSTM활용 및입력 문장의 순서 뒤집기
: 더 높은 정확도를 보임
: 입력 문장의 순서를 거꾸로 함(이러한 이유로 한국어로 번역하는 게 어렵거나 가끔 번역기를 돌렸을 때 이상한 문장이 나오는 이유가 될 수도 있을까요.?)
: 출력 문장의 순서는 바뀌지 않음
: EOS - End of sequence
논문
-
Sequence learning
-
LSTM(multilayered layer) --> Encoder & Incoder
-
LSTM -> SMT -> RERANK ->> 성능 좋아짐!
-
LSTM -> 입력 문자의 순서를 바뀜 -> 성능 좋아짐( 학습 난이도를 낮춰주기 때문이다)
Introduction
-
NN with conventional statistical models -> 복잡한 함수 학습
-
과거에는 입력과 출력의 차원이 같게 해줘서 처리를 했기 때문에 speech recognition and machine translation 같은 시퀀스 문제가 있었습니다.
-
LSTM -> obtain large fixed- dimensional verctor representation(Encoder)
--> output sequence of the vector(Decoder) -> 긴 문장 처리 가능하다.
The Model
-
수학적 표현
-
sequence of inputs : 단어의 수만큼
-
sequence of outputs (in a standard RNN)
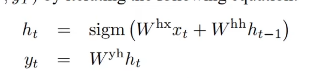
-
Encoder 파트와 Decoder 파트의 RNN(used in a fixed-sized vector)이 따로 사용이 될 수 있음. 서로 다른 파라미터를 가짐
-
입력 != 출력 이어도 됨
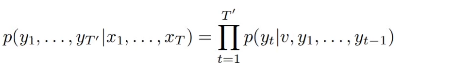
-
layer의 중첩이 가능함.
-
입력 문자의 단어 순서 바뀜 --> 성능 강화!
Experiments
- SMT 추가로 인해 성능 증가
*Dataset details
-
많은 수의 데이터가 있다
-
고정된 크기의 단어 사진 이용
-
단어를 특정 벡터의 차원으로 만든다.(160000)
*Decoding and Rescoring
-
S = source
-
T = target
-
Training objective :
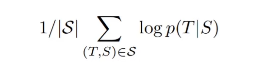
-
학습이 끝난 후 (타켓 sentece returned)
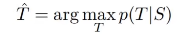
*Reversing the Source Sentences
: 앞에 부분에 단어에서는 성능이 좋겠지만 뒤쪽 부분의 단어는 성능이 좋지 않음 허나
이러한 단점에도 불구하고 장점이 너무 크다!
*Training details
-
LSTMs: 4 layers
-
Word embeddings : 1000 dimensional
-
input vocabulary : 160000
-
output vocabulary: 80000
-
LSTM의 파라미터 : -0.08~ + 0.08 (uniform distribution)
-
Use stochastic gradient descent withou momentum
-
diminsh learning rate
-
batch sizes : 128개
-
padding ->> 효능 줄어든다 --> same length in minibatch -> 학습 속도 늘어난다
- Result


Model Analysis by PCA
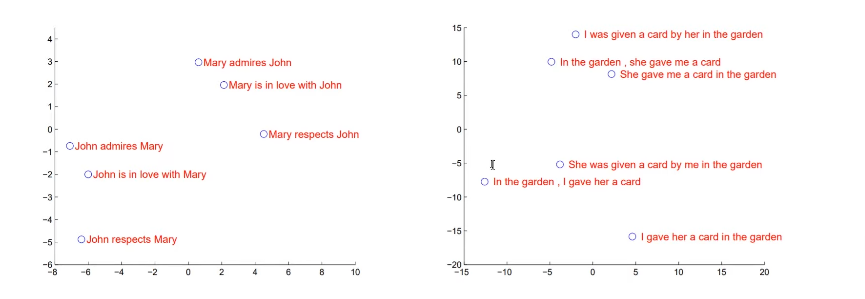
Conclusion
LSTM -> Encoder -> context vector -> Decoder ->번역 결과 나온다
코드 실습
