Introduction
Feature analysis
Feature engineering
Modeling
#라이브러리 호출
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from collections import Counter
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier, ExtraTreesClassifier, VotingClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold, learning_curve
sns.set(style='white', context='notebook', palette='deep')Load and Check data
load data
#load data
train = pd.read_csv('./input/train.csv')
test = pd.read_csv('./input/test.csv')
IDtest = test["PassengerId"]Outlier detection
# Outlier detection
def detect_outliers(df,n,features):
"""
Takes a dataframe df of features and returns a list of the indices
corresponding to the observations containing more than n outliers according
to the Tukey method.
"""
outlier_indices = []
# iterate over features(columns)
for col in features:
# 1st quartile (25%)
Q1 = np.percentile(df[col], 25)
# 3rd quartile (75%)
Q3 = np.percentile(df[col],75)
# Interquartile range (IQR)
IQR = Q3 - Q1
# outlier step
outlier_step = 1.5 * IQR
# Determine a list of indices of outliers for feature col
outlier_list_col = df[(df[col] < Q1 - outlier_step) | (df[col] > Q3 + outlier_step )].index
# append the found outlier indices for col to the list of outlier indices
outlier_indices.extend(outlier_list_col)
# select observations containing more than 2 outliers
outlier_indices = Counter(outlier_indices)
multiple_outliers = list( k for k, v in outlier_indices.items() if v > n )
return multiple_outliers
# detect outliers from Age, SibSp , Parch and Fare
Outliers_to_drop = detect_outliers(train,2,["Age","SibSp","Parch","Fare"])train.loc[Outliers_to_drop] # show the outliers rows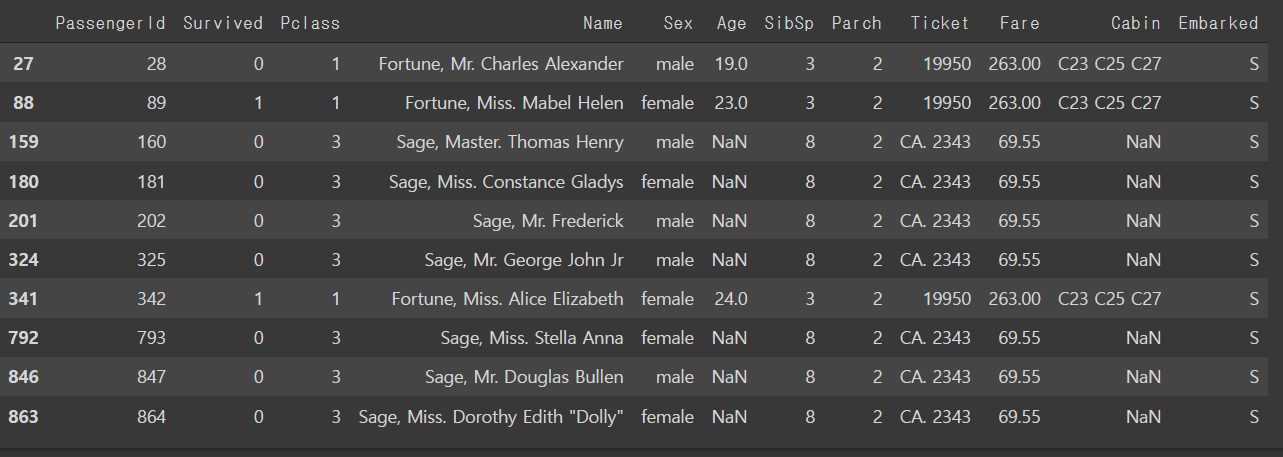
#Drop outliers
train = train.drop(Outliers_to_drop, axis = 0).reset_index(drop=True)joining train and test set
#joining train and test set
train_len = len(train)
dataset = pd.concat(objs=[train, test], axis=0).reset_index(drop=True)check for null and missing values
#check for null and missing values
#Fill empty and NaNs values with NaN
dataset = dataset.fillna(np.nan)
#check for null values
dataset.isnull().sum()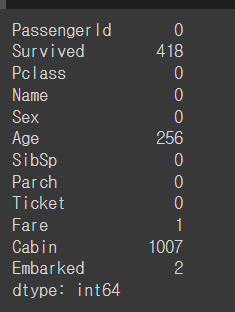
#Infos
train.info()
train.isnull().sum()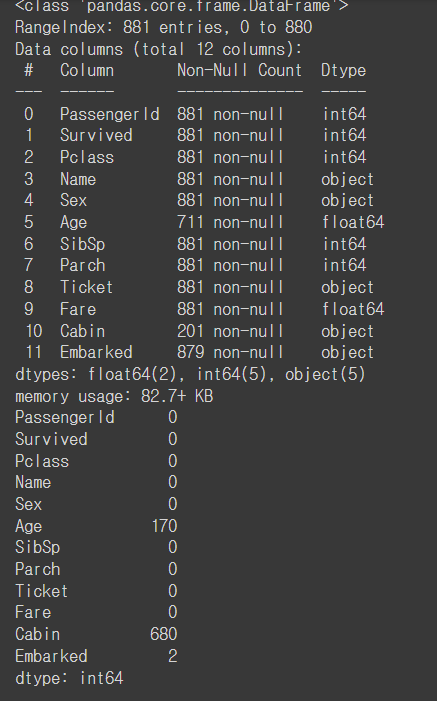
train.head()
train.dtypes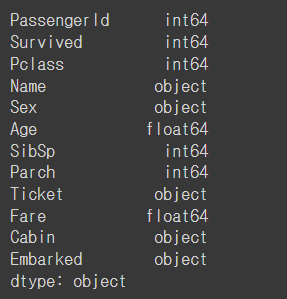
## Summarize data
train.describe()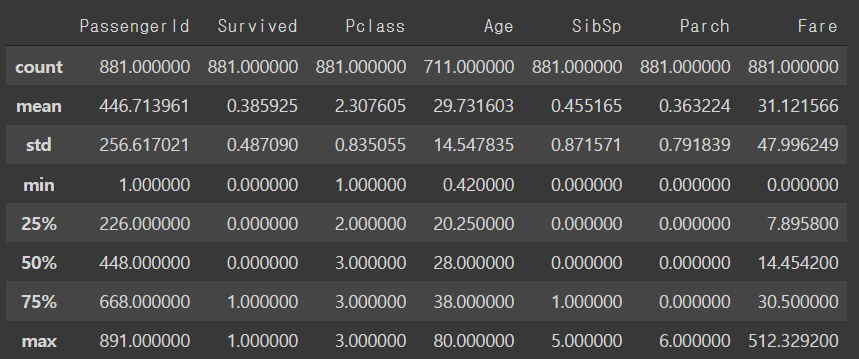
Feature analysis
Numerical values
#Correlation matrix between numerical values (SibSp Parch Age and Fare values) and Survived
g = sns.heatmap(train[['Survived','SibSp','Parch','Age','Fare']].corr(),annot=True, fmt= ".2f", cmap = "coolwarm")
#SibSP
g= sns.factorplot(x="SibSp", y="Survived", data=train, kind="bar",size=6 , palette = "muted")
g.despine(left=True)
g = g.set_ylabels("survival probability")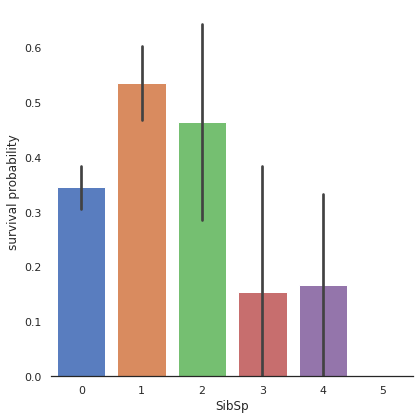
#Parch
g = sns.factorplot(x="Parch", y ="Survived", data=train,kind="bar",size=6,palette="muted")
g.despine(left=True)
g = g.set_ylabels("survival probability")
#Age
g = sns.FacetGrid(train, col="Survived")
g = g.map(sns.distplot, "Age")
# Explore Age distibution
g = sns.kdeplot(train["Age"][(train["Survived"] == 0) & (train["Age"].notnull())], color="Red", shade = True)
g = sns.kdeplot(train["Age"][(train["Survived"] == 1) & (train["Age"].notnull())], ax =g, color="Blue", shade= True)
g.set_xlabel("Age")
g.set_ylabel("Frequency")
g = g.legend(["Not Survived","Survived"])
#Fare
dataset["Fare"].isnull().sum() # 1dataset["Fare"] = dataset["Fare"].fillna(dataset["Fare"].median())g = sns.distplot(dataset["Fare"], color="m",label="Skewness : %.2f"%(dataset["Fare"].skew()))
g = g.legend(loc="best")
dataset["Fare"] = dataset["Fare"].map(lambda i: np.log(i) if i > 0 else 0)g = sns.distplot(dataset["Fare"], color="b", label = "Skewness : %.2f"%(dataset['Fare'].skew()))
g = g.legend(loc="best")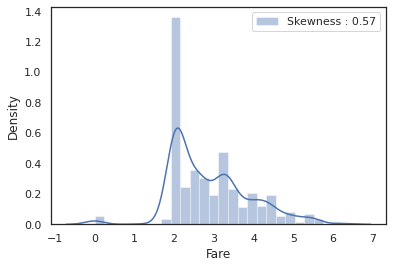
Categorical values
#sex
g = sns.barplot(x="Sex",y="Survived",data=train)
g = g.set_ylabel("Survival Probability")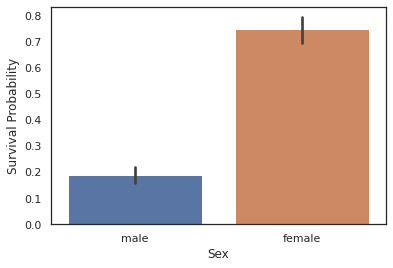
train[["Sex","Survived"]].groupby("Sex").mean()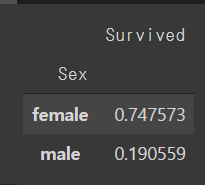
#Pclass
g = sns.factorplot(x="Pclass", y="Survived", data= train, kind="bar",size =6,palette="muted")
g.despine(left=True)
g = g.set_ylabels("Survival probability")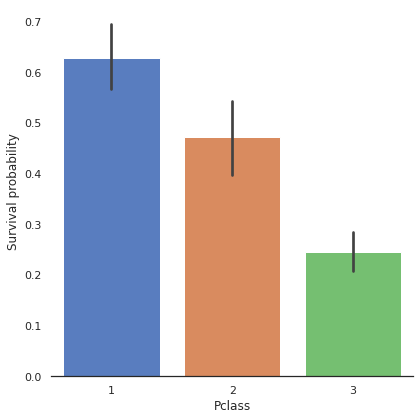
# Explore Pclass vs Survived by Sex
g = sns.factorplot(x="Pclass", y="Survived", hue="Sex", data=train,
size=6, kind="bar", palette="muted")
g.despine(left=True)
g = g.set_ylabels("survival probability")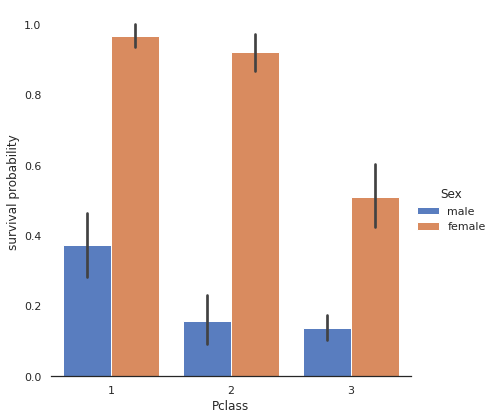
#Embarked
dataset['Embarked'].isnull().sum() #2dataset["Embarked"] = dataset["Embarked"].fillna("S")g = sns.factorplot(x="Embarked", y="Survived", data=train, size=6, kind="bar", palette="muted")
g.despine(left=True)
g = g.set_ylabels("survival probability")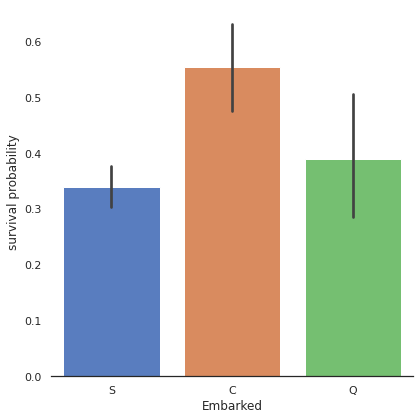
g = sns.factorplot("Pclass", col="Embarked", data=train, size=6, kind="count", palette="muted")
g.despine(left=True)
g = g.set_ylabels("Count")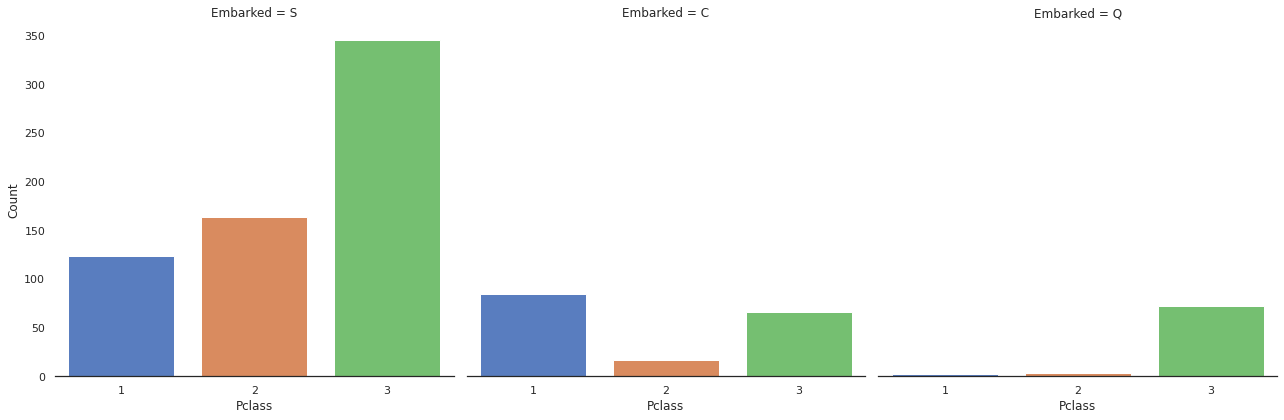

성장을 도울 아카이빙 블로그