Preview
-
텍스트 분류 모델을 속이는 기법인 TextFlooer제안
-
원본 텍스트(분류모델) 변형하여 영화 리뷰 모델 속이기 가능하다.
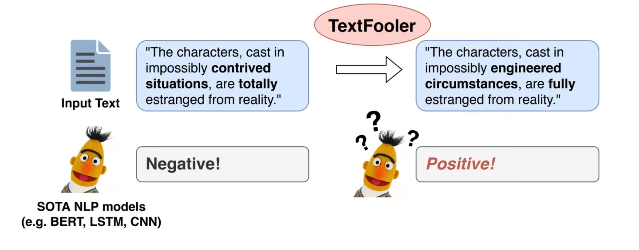
*텍스트 분야에서 적대적 공격이 어려운 이유
- 이미지 도메인
 : 픽셀 값들이 연속적 : 많은 픽셀에 노이즈가 섞여도 눈에 잘 안 보임
: 픽셀 값들이 연속적 : 많은 픽셀에 노이즈가 섞여도 눈에 잘 안 보임
- 자연어 도메인

: 단어나 문자가 불연속적인 토큰
: 약간의 변화가 생겨도 눈에 잘 보임
본 눈문에서 제안
- Proposing TextFoller
-
Effective: 공격이 잘 되었다.
-
Utility-preserving: 인간이 인식하기엔 공격 전과 후의 차이를 느끼지 못함
-
Efficient: 더 적은 양의 복잡성을 가지고도 성공적인 공격이 가능하다
- Extensive experiments
-
Models: 3가지의 딥러닝 모델
-
Dataset: 5가지의 분류 task, 2개의 textual entailment tasks.
*textual entailment
: 문장 사이의 연관성과 유사함을 찾음
-
Hypothesis: if you help the needy, God will reward you.
-
Examples
- Entailment: 주어진 문장과 Paraphrasing이 잘 됨.
: Giving money to a poor man has good consequences.
- Contradiction: 주어진 문장과 완전 상반
: Giving money to a poor man has no consequences.
- Neutral relationship: 주어진 문장과 중립을 가짐.
: Giving money to a poor man will make you a better person.
- 논문에서 해결하고픈 문제
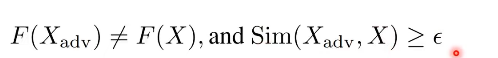
-
Sim(.) is often a semantic and syntactic similarity function
-
F(.) is a targeted model.
- 공격 기법 유형
-
Black-box attack
: 상세한 파라미터를 알지 못하고, 입력 문구를 통해서 얻어지는 것은 predictions and confidence scores이라고 가정한다.
-
Targeted & Non-targeted attack
: 특정 task로 분류 혹은 아예 정반대로 분류.
-
Word-wise perturbing attack
: 단어 단위로 단어를 바뀜.
- 알고리즘
-
Word Importance Ranking

: 주어진 문장이 n개의 단어일 경우, 몇 개의 단어만 실제 분류에 영향을 미친다. 그러므로 주요 단어만 변경하면 된다..
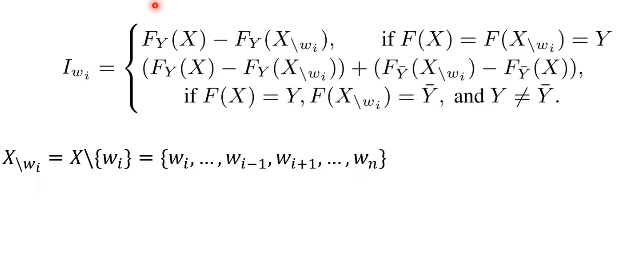
: 각각의 단어를 빼어서 퀴리를 날린 후에 그 결과를 바탕으로 importance score를 만든다.
-
Word Transformer
i) Synonym extraction: 유사한 단어 추출

ii) POS checking: 문법적 오류 체크
iii) Semantic similarity checking: 문장의 오류 체크(의미 변환이 있는지)

iv) Finalization of adversarial examples: 모델의 결과가 바뀌면 바꿔치기 하라.

- Datasets
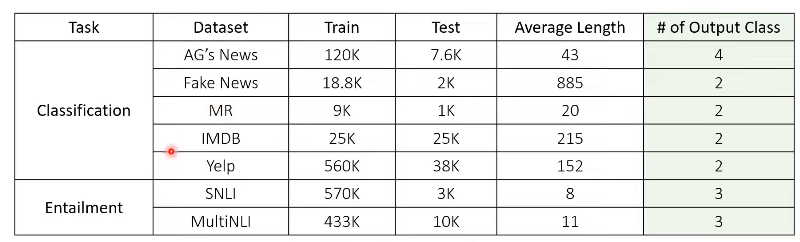
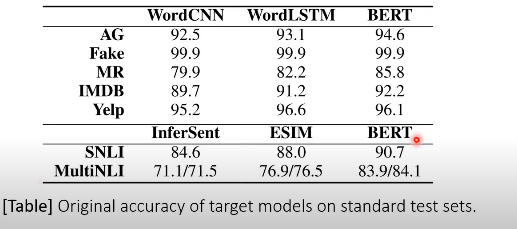
- 공격 대상 모델
: For each dataset, training three state of the art models.
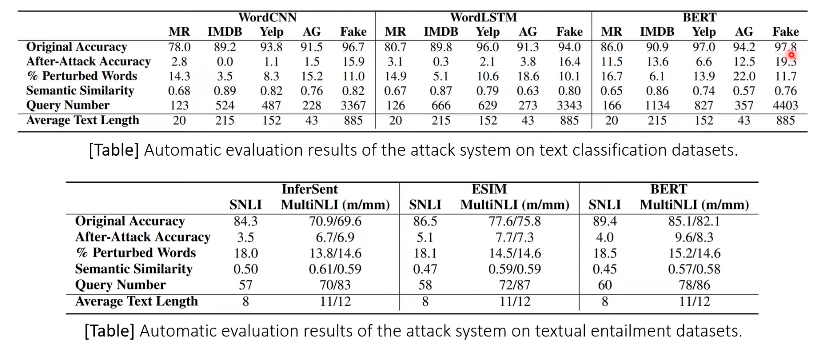
- 공격 결과의 요약
- non-targeted model, accuracy가 낮으면 공격 성공!
- 적대적 예제

- 논문 기법과 예전 공격 기법 비교
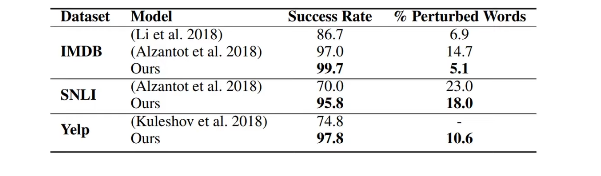
-
Generating Natural Language Adversarial Examples[EMNLP 2018]
-
Algorithms
i) 무작위로 문장 내 단어 선별
ii) 동의어로 바꿈
iii) 결과를 예측하는 값이 증가하는 것을 찾아서 비교
iv) black-box없다
-
- 추가 실험 결과
- Transferability

- Adversarial Training
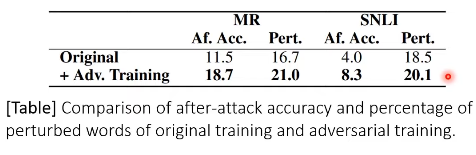
- 결론
: TextFooler 이라는 효과적인 공격 기법 발표.
: TextFooler은 5개의 분류 tasks과 두 개의 textual entailment tasks를 성공적으로 공격을 한다 in the black-box setting.
