특징
1.Imperceptibility:정상적인 이미지처럼 보임
2.Misclassification: 타겟 클래스로 잘못 분류하도록 유도
3.Strongly certified: 전혀 문제가없는 정상적인 이미지인 것처럼 느낌.허나 실제로는 공격 준비인 것.
논문 핵심 아이디어
어떤 이미지가 결정 경계로부터 멀리 떨어져있다면,
분류기는 노이즈를 섞은 이미지에 대해 같은 레이블로 분류합니다. 이렇게 하면 Certification defender는 수학적으로는 높은 의미가 있으나 보안적 관점으로 봤을 때 아직 부족하다는 것을 말하는 논문입니다.
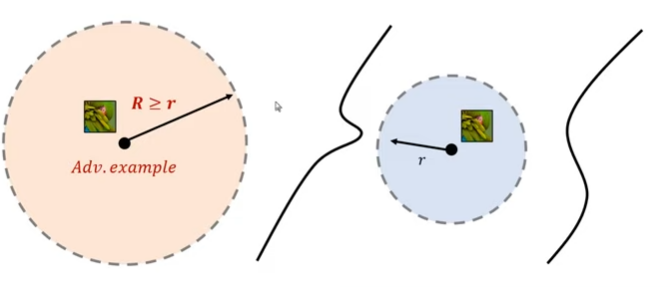
연구 배경
1.적대적 예제 (Adversarial Examples)
:인간의 눈에 띄지 않게 변형된 데이터로 뉴럴 네트워크의
부정확한 결과를 유도한다.
2.적대적 학습(Adversarial Training)
:적대적 예제 현상을막기 위해서 만들어진 것으로
adversarial example을 학습 데이터로 이용하여 뉴럴 네트워크를 강건하게 만든다.
:방어는 잘함
:단점은- 강한 adversarial example을 학습데이터로 구현하기가 힘들다
:해결점은 있으나 더 강한 것이 들어올 땐 속수무책. 즉 완전한 해결은 아니다.
:현재 해결 (PGD를 통해서 Local solution로 학습)
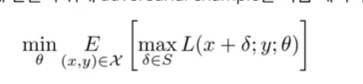
-파란색: local solution, 초록색: Global solution
3.인증된 적대적 강건성(Certified Adversarial Robustness)
:2번이 해결하지 못한 부분을 해결하기 위해 나타남.
:입력 이미지가 주어졌을 때, 특정한 크기 Lp-boundary안에서는 adversarial example이 만들어 질 수 없도록 하는 방어 기법 유형이다.
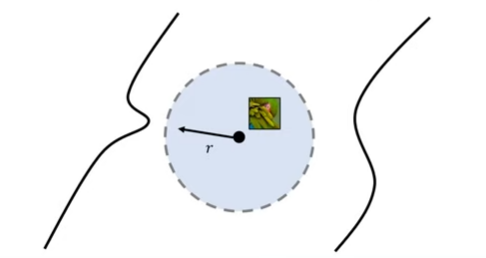
4.Randomize Smoothing
:3번 방식의 효율성 극대화.
: 기존 이미지에 특정 노이즈를 섞어서 학습을 시킨다.
:L2 norm bounded 안에서 보장되는 방식
:직관적으로 보았을 때는 decision boundary를 넓힘으로
방어하는 쪽을 속여서 공격이 가능하다.
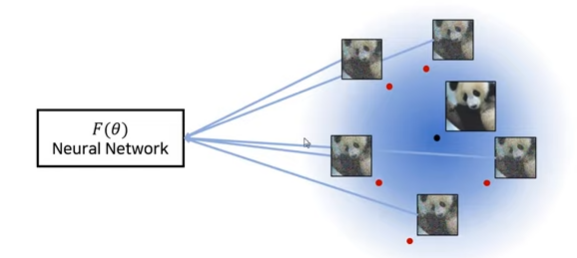
: 학습된 데이터 평가
i)학습된 데이터에 가우시안 노이즈를 섞어서
ii)f가 가장 많은 빈도로 내뱉는 클래스 결과
iii)inference 한다.(Monte Carlo algorithm)
iv)특정 이미지가 특정 범위 내에서 아무리 움직여도
Adversarial Examples이 발생하지 않음.
5.CROWN-IBP
: L- infinite norm bounded 범위에서 이용
PGD attack
:최적화 문제를 해결하기 위해서 만든 것
: 입시론 보다 작으면서 Loss값을 크게 만드는 것
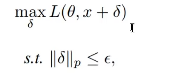
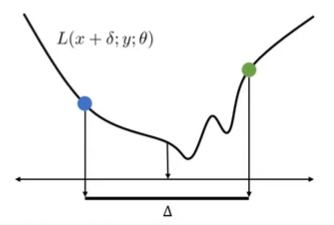
논문의 objective function
:PGD attack에게 필요한 제한 조건들을 무시하고 조금 더 실생활에 쓸 수 있게 만들어줌.
max L: 특정 클래스로 잘 분류되기 위해서 공격목적.

Dissim: 얼마나 다른지를 의미하는 부분
CV에서 그림자부분이 나오도록함
전체가 밝아지거나 어둡게 만든다
TV: Tootal veriations으로 smoothing기법을 사용하여 노이지를 제거한다
인접한 픽셀끼리의 차이로 계산.
Loss term을 통해서 차이를 줄임
인접한 픽셀 값이 유사해지게 되어 variation이 줄어듦.

C :Color Regularizer로 불리며, total variation이 커지지 않도록 해준다.
각 색상 채널별로 평균값을 구한 후 작게 만든다.
각 픽셀의 평균 변화량 제한.

논문의 Attack methods
i) 1-channel attack
:RGB 컬러를 각 픽셀별로 동일하게 만들어 greyscale로 만든다.
ii)3-channel attack
:RGB 컬러를 각 픽셀별로 유사하게 만드는 방식
:constraint가 적기 떄문에 공격을 잘 당함
iii) 공격을 안 당하기 위해서 이 공식 이용
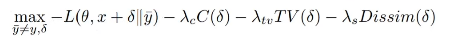
Ablation study of the attack parameters
i)The number of SGD steps needed
30 SGD steps.
ii)The importance of 람다s
iii)Alternatively using 1-channel attacks
iv) the effect of 람다tv
람다tv = 0.3
Conclusion
Adversarial examples가 large-norm perturbations를 갖게 하여 decision boundary많이 벗어나도록하면 크기 제한을
갖지 않게 되어 certified ro-bustness를 속일 수 있다.
이 논문은 Shadow attack를 통해서 위의 방식대로 했을 때
효과적으로 속일 수 있었다.
그리고 certificably robust classifiers는 수학적으로는 유의미한 가치가 있으나 이미지부분에서는 크게 유의미하지 못하고 한계점이 있다.
