초보자 입장에서 쓴 글입니다.
추천 시스템은 이제는 거의 대부분의 서비스에서 활용되고 있다. 넷플릭스의 영상 추천 서비스는 내가 본 시청 기록물과 관심이 있는 주제를 보고 비슷한 사람은 어떤 영상을 봤는지 확인하여 ai가 그 사람이 본 영상을 제안하는 방식이다.
이 기술에 활용되는 방법이 Matrix Factorization(행렬 분해법)이다.
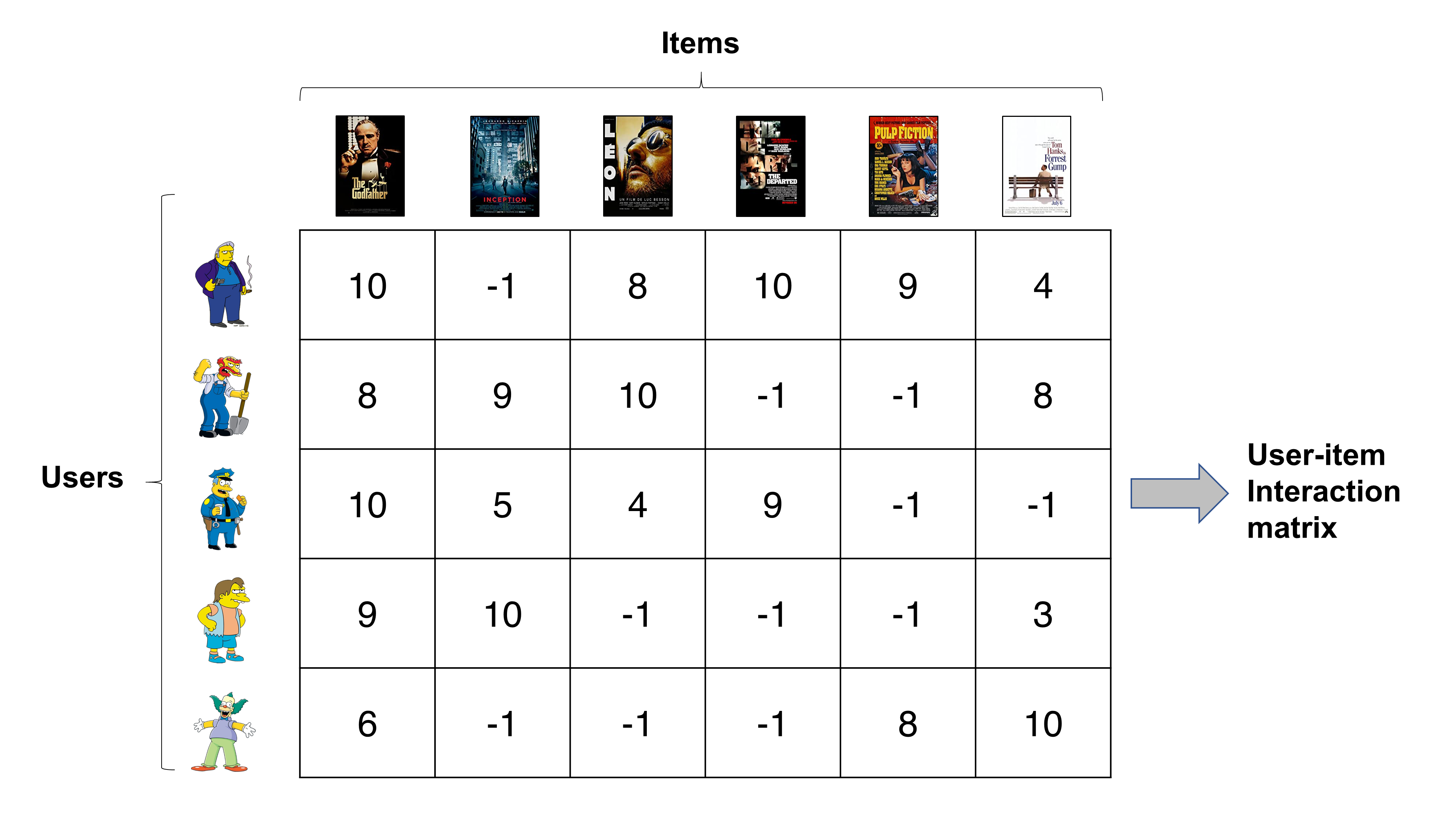
각 열은 각기 다른 영화(item)를 의미하며
각 행은 각기 다른 유저가 영화에 매긴 점수를 의미한다.
이렇게 보면 직관적이어서 이해하기 쉽다.
이제 행렬 분해를 들어가보면
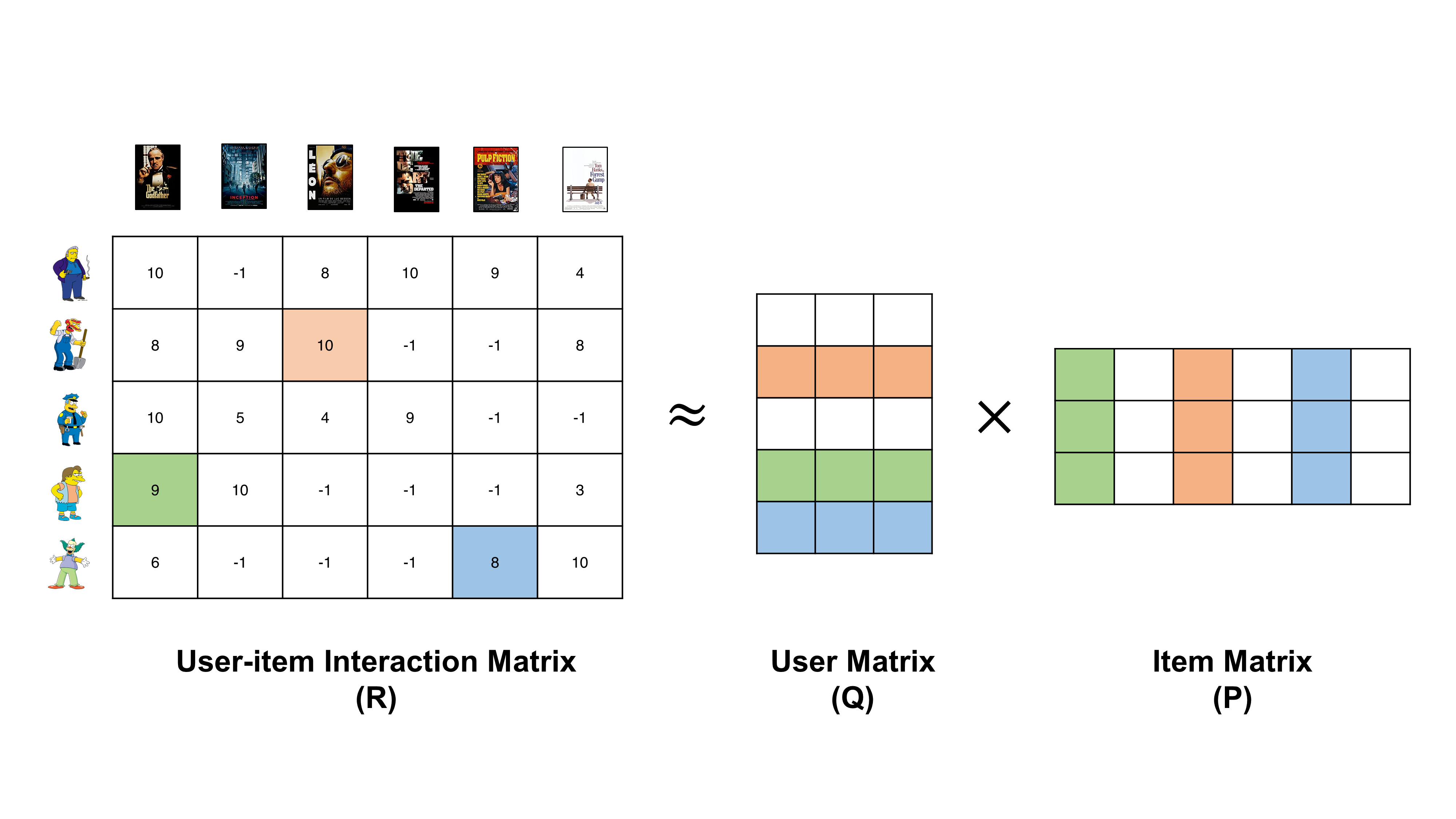
유저 아이템 interaction 행렬이 유저와 아이템 행렬로 분해가 되었다.
아마도 분해가 된다면 각 행렬의 내부에는 어떤 내용이 있을지 궁금할텐데..
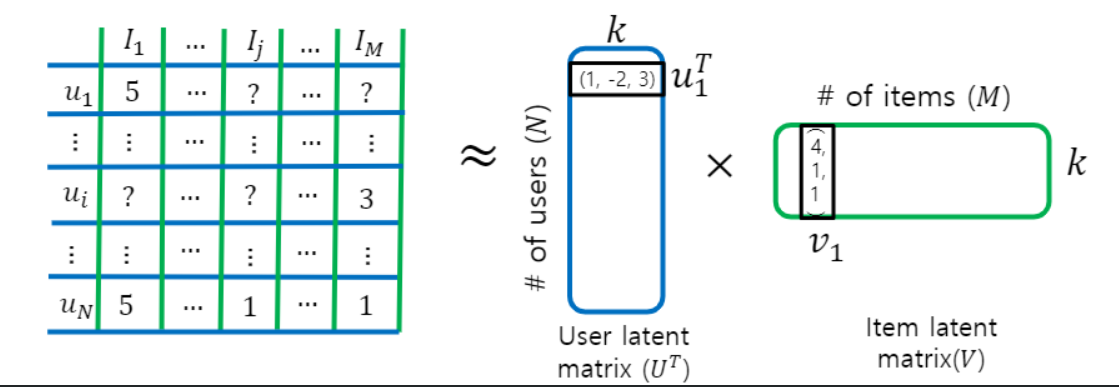
그건 유저와 아이템에 대한 학습된 특징이 들어있는 것으로 이를 활용해 다른 유저-아이템 행렬의 다른 공백을 추측하는데 활용한다.
그래서 다시 이전으로 돌아가서
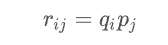
유저-아이템 행렬에 들어있는 r(ij)는 유저 매트릭스 q에 들어있는 i번째 행과 아이템 매트릭스 p에 들어있는 j번째 열의 곱이다.
AI는 일단 채워진 것들 즉, 이미 넷플릭스를 이용하는 유저들이 봤던 기록을 활용해서 빈칸이 있는 다른 유저들의 예상 평점을 추측할 수 있는 것이다.
그러면 ai의 오류를 줄이기 위한 식은 무엇일까
Optimization
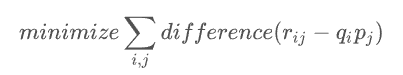
실제 유저가 매긴 평점 r(ij)와 인공지능이 예측한 q(i)p(i) 의 차이를 줄이는 식이다.
이렇게 마무리 하면 너무 좋겠지만
gradient descent 과정을 거치며 오차를 줄이는 과정이 필요하다....
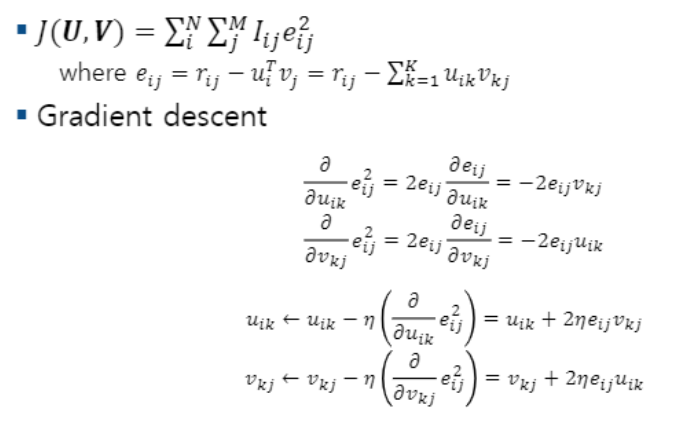
U = 유저 V = 아이템
I(ij) = 값이 1이면 i번째 유저가 j번째 영화에 점수를 매겼다는 의미이다. 0이면 매기지 않았고
e(ij)는 실제 평점에서 인공지능이 분해한 매트릭스의 곱을 뺀 것으로 약간 오차라고 보면 된다.
이걸 다듬는 과정을 gradient descent라고 한다.
방금 그 오차의 제곱을 유저 u(ik)로 편미분하고
아이템 v(ik)로 편미분하고
결국엔 u(ik)와 v(ik)를 계속해서 업데이트 해나가며
오차 범위를 줄인다.
이 간단한 식 안에 저런 내용이 포함된 것이다..
