Q-learning이란
모델 없이 학습하는 강화학습 방법 중에 하나이다.
지금부터 Q-learning을 목적지를 찾아가는 과정을 통해 설명해보겠다.
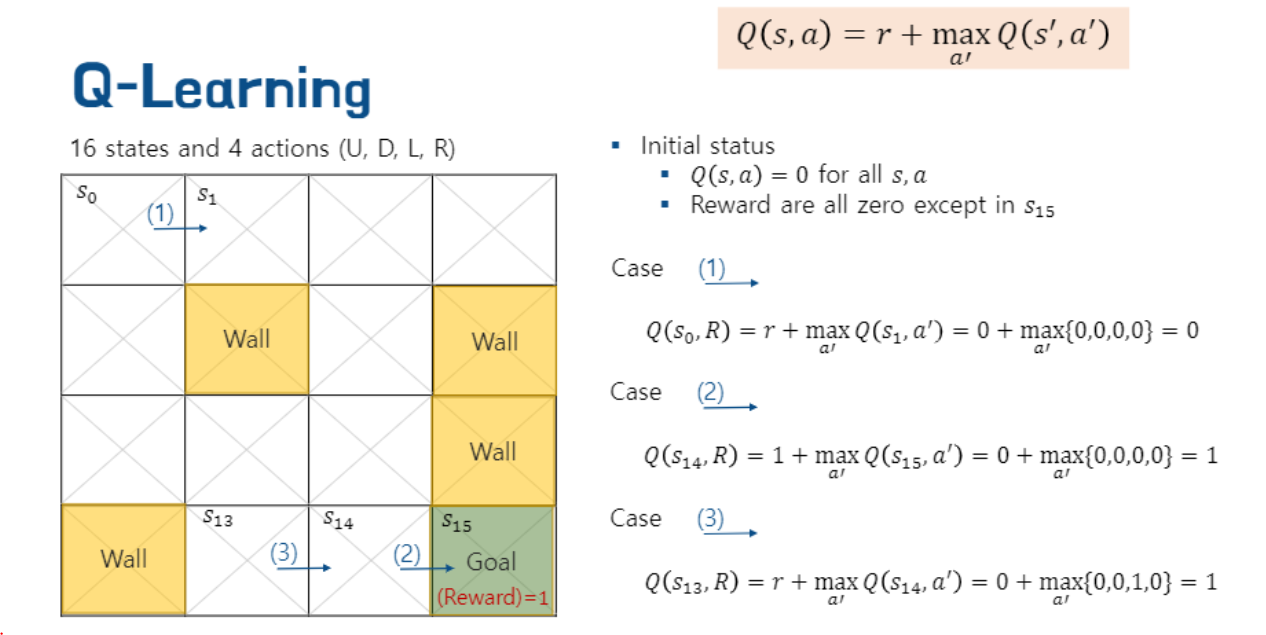
먼저 Q는 일종의 우리가 어디로 가야하는 지 알려주는 조언자라고 생각해보자

Q : "휴먼 저를 믿으십시오"
Q는 우리가 어디로 가야하는지 Reward를 통해 알려준다.
북쪽, 동쪽, 남쪽, 서쪽 중 reward가 높은 곳으로 가면된다.Q에는 현재 step과 action을 넣어준다.
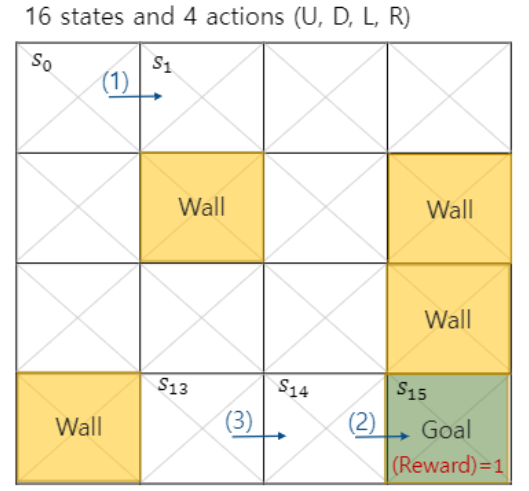
step은 매 단계를 의미하며 지도 s0에서 s15까지 이동할 것이다.
action은 동서남북 4방향 중 가장 value가 높은 곳을 선택하여 이동하는 것을 의미한다.
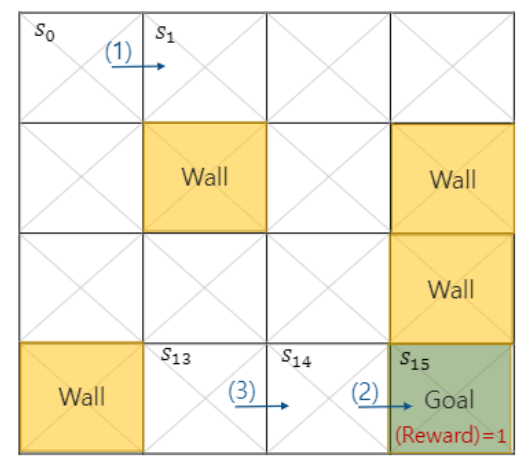
그러면 Wall이라고 적힌 부분을 제외하고 어떻게 s0에서 목적지까지 갈 수 있을까?
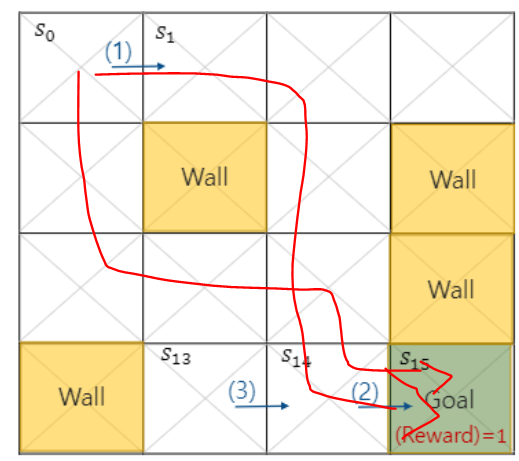
아마 가장 빠르게 가는 방법은 7스텝을 거쳐 가는 방법일 것이다.
하지만 우리는 어떠한 모델도 없이 컴퓨터가 학습하는 방법으로 이동할 예정이다.
그리고 컴퓨터는 wall에 도달하면 0점으로 다시 시작하고
오직 Goal에 도착해야 보상으로 1점을 얻는다.
이런 보상을 통해 강화학습이 가능하다.
이제 우리는 다음 단계의 값을 이미 알고 있다고 가정하자.
바로
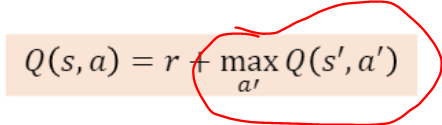
이 부분을 말이다.
이렇게 생각해볼 수도 있다.
s15부터 거꾸로 시작하는 것이다.
s14의 경우 (북 0점, 동 1점, 남 0점, 서 0점)
왜냐하면 step 14에서는 동쪽으로 가야지 목적지에 도달하기 때문에
a14로 동쪽을 선택한 경우에만 1점을 받는다.
반면 maxQ(s15, a15) = {0,0,0,0} 이다. 왜냐하면 목적지에 도달했기 때문에 어딜 가든 0점이다.
위 식에서 Q(s14, a14) = reward(1) + maxQ(s15, a15) = 1일 것이다.
Q : "step 14에서는 동쪽으로 가는게 맞습니다. "
만약 내가 s13에 있다면 어떻게 될까?

Q(s13, a13)의 경우
Q(s13, 동쪽 선택 시) = reward(0) + maxQ{0,1,0,0} = 1
이런식으로 뒷쪽 값을 안다고 가정하고 우리는 s0까지 선을 그을 수 있다.
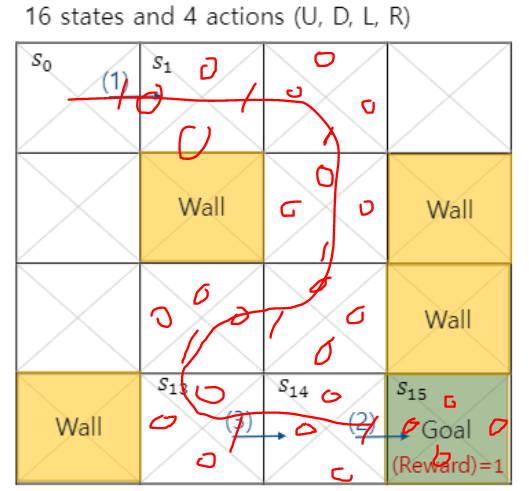
그런데 처음에 가장 빠르게 갈 수 있는 step은 7이었는데 우리가 찾은 값은 9step이다.
어떻게 하면 더욱 빠르게 갈 수 있을까?
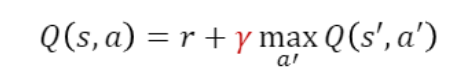
바로 다음에 받을 보상을 discount 시켜버리면 된다.
예를 들어 discount factor가 0.9라고 하자.
처음으로 돌아가서 현재 우리가 s14에 있을 때 Q에게 묻는다.
Q : "휴먼 s14에서는 Q(s14, 동쪽) = reward는 1이고 다음 maxQ(action)는 0.9*{0,0,0,0} 이므로 두개 더해서 1입니다. 동쪽으로 가십쇼"
현재 우리가 s13에 있다면?
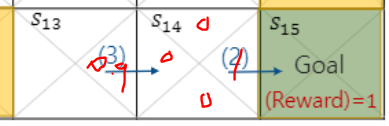
Q : "휴먼 s13에서는 Q(s14, 동쪽) = reward는 0이고 다음 maxQ(action)는 0.9*{0,1,0,0} 이므로 두개 더해서 0.9입니다. 동쪽으로 가십쇼"
우리가 방금까지만 해도 올바른 길을 찾는 값이 모두 1이었다면 이제는 멀리 돌아갈 수록 0.9씩 제곱되어 멀리 돌아갈수록 목적지에 도착 시 얻는 reward가 줄어든다. 그렇게 되면 강화학습을 통해서 reward가 가장 높은 값을 찾게 되고 이는 곧 가장 빠른 길을 찾을 수 있게 되는 것이다.

