[경진대회] 자전거 대여 수요 예측
이번 포스팅에서는 본격적인 경진대회 관련 글을 작성할 예정이다.
우선 이번 포스팅이 kaggle 경진대회에 처음 참가해보는 포스팅이니만큼 경진대회 세부 메뉴를 알아보고 안내사항을 숙지하는 내용을 작성할 것이다.
1. 경진대회 이해
-
대회 개요: 자전거 대여 수요 예측 경진대회(Bike Sharing Demand Competition)는 2014년 5월에서 2015년 5월까지 약 1년 동안 개최되었으며 총 3,242팀이 참가했다.
-
대회 유형: 이 대회는 플레이그라운드 대회(playground competition)이다.
-
난이도 및 참가자: 플레이그라운드 대회는 난이도가 낮은 연습용 대회로써 입문자도 참가할 수 있는 난이도이다.
-
보상 및 학습 가치: 플레이그라운드 대회는 상금과 메달은 없지만 입문자가 프로세스를 익히고 실력을 키우기에 좋은 대회이다.
-
제공 데이터 기간: 주어진 데이터는 2011년부터 2012년까지 2년간의 자전거 대여 데이터이다.
-
데이터 기록 간격: 대여 데이터는 한 시간 간격으로 기록되어 있다.
-
훈련 데이터 범위: 훈련 데이터는 매달 1일부터 19일까지의 기록이다.
-
테스트 데이터 범위: 테스트 데이터는 매달 20일부터 월말까지의 기록이다.
-
피처 설명: 피처는 대여 날짜, 시간, 요일, 계절, 날씨, 실제 온도, 체감 온도, 습도, 풍속, 회원 여부이다.
-
문제 유형: 이 데이터를 활용해 시간별 자전거 대여 수량을 예측하면 된다. 예측할 값이 범주형 데이터가 아니므로 이 대회는 회귀 문제에 속한다.
피처와 타깃값이란?
피처(feature) : 원하는 값을 예측하기 위해 활용하는 데이터를 의미한다.
- 독립 변수
- 대여 날짜, 시간, 요일, 계절, 날씨, 온도
타깃값(target value) : 예측해야 할 값
- 종속 변수
- 대여 수량
전체 데이터 크기가 1.1MB로 작고, 피처 수도 적어 몸풀기용으로 적합한 대회이다.
본 운동 전 준비 운동을 해야 하듯이 이 대회를 통해 몸을 한번 풀어보자.
2. 경진대회 접속 방법 및 세부 메뉴
이번 포스팅에서만 경진대회 접속 방법 및 세부 메뉴에 관한 정보를 작성하고, 이후 경진대회들에서는 중요 내용만 작성할 것이다.
이에 따라 이번 기회에 잘 익혀둘 것이다.
2.1 경진대회 접속 방법
우선 캐글 홈페이지 상단에 검색창에서

"bike sharing demand"라고 입력해 검색한다.
이어서 Competition영역에서 가장 위에 나타난 경진대회를 클릭한다.
검색창
그럼 이제 다음과 같이 자전거 대여 수요 예측 경진대회 메인 페이지가 뜬다.
메인 페이지
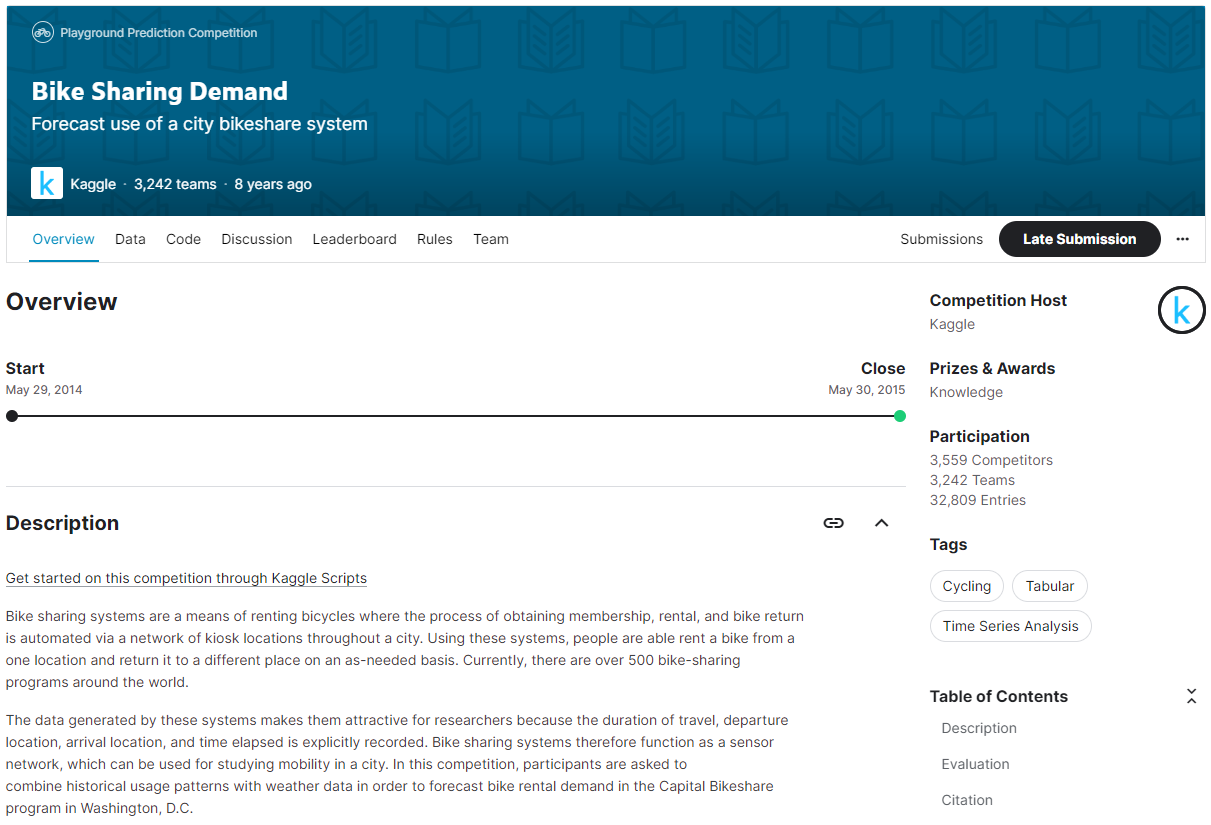
경진대회 제목

경진대회 제목 바로 밑에는 다음 그림처럼 주최 측, 참여한 팀 수, 대회종료 시기가 표시되어 있다.

2.2 경진대회 메뉴 설명
Overview 메뉴
Overview는 경진대회 전반을 소개하는 메뉴이며, Description란에 경진대회 소개글이 있다.
이는 경진대회에 참여하기 전, 가장 먼저 읽어야 하는 페이지이다.
Acknowledgements란에는 ~~~
Overview Menu
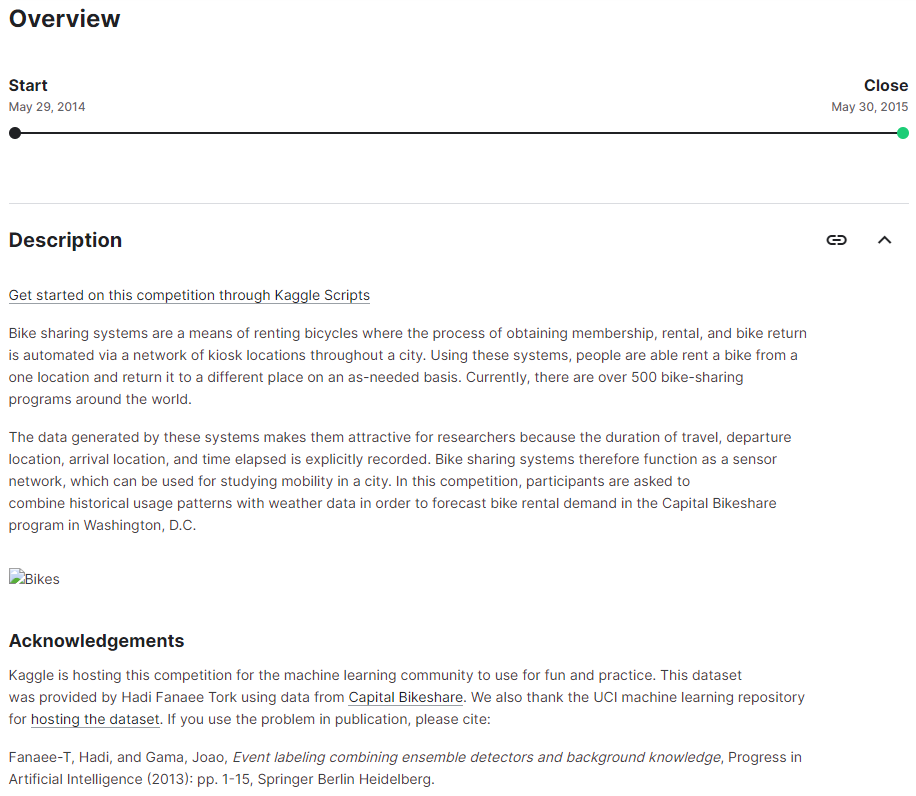
Evaluation란에는 평가지표와 제출 형식을 설명한다.
평가 지표는 등수를 매기는 데 사용되므로 주의 깊게 봐야한다.

본 대회의 평가 지표는 RMSLE(Root Mean Squared Logarithmic Error)이다.
제출 형식은 일시(datetime)과 대여 수량(count)으로 구성되어 있고, 일시는 1시간 간격으로 기록돼 있으며, 대여 수량은 모두 0이다.
추후 만든 모델로 대여 수량을 예측해 값을 바꿔주면 된다.
즉, 구해야 하는 값은 일시별 대여 수량. 이 형식대로 파일로 만들어 제출해야 함.
Data 메뉴
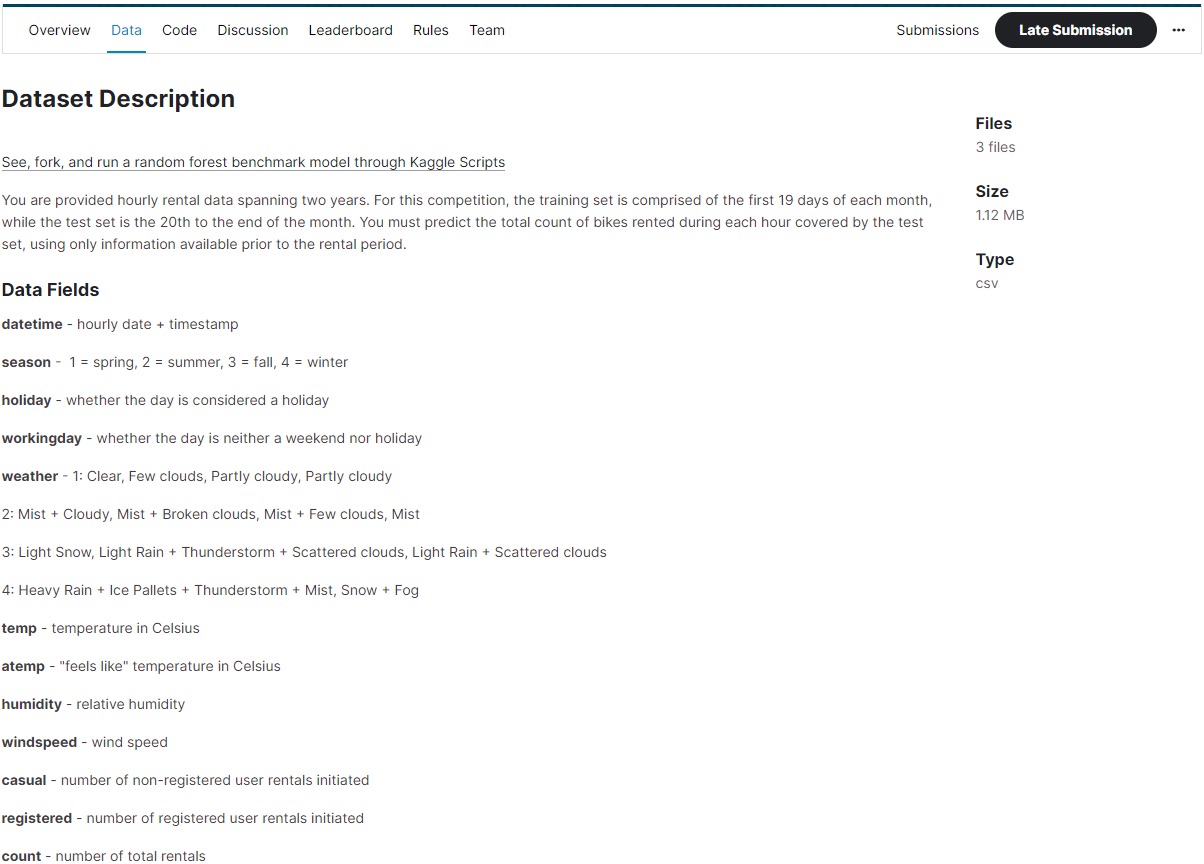
Overview의 내용을 모두 숙지했다면 다음으로는 Data 메뉴를 봐야 한다.
이는 경진대회가 제공하는 데이터에 대해 설명해놓은 메뉴이다.
어떤 피처를 사용해 어떤 값을 예측해야 하는지 설명되어 있으므로 유의해서 읽어봐야 한다.
Data 메뉴
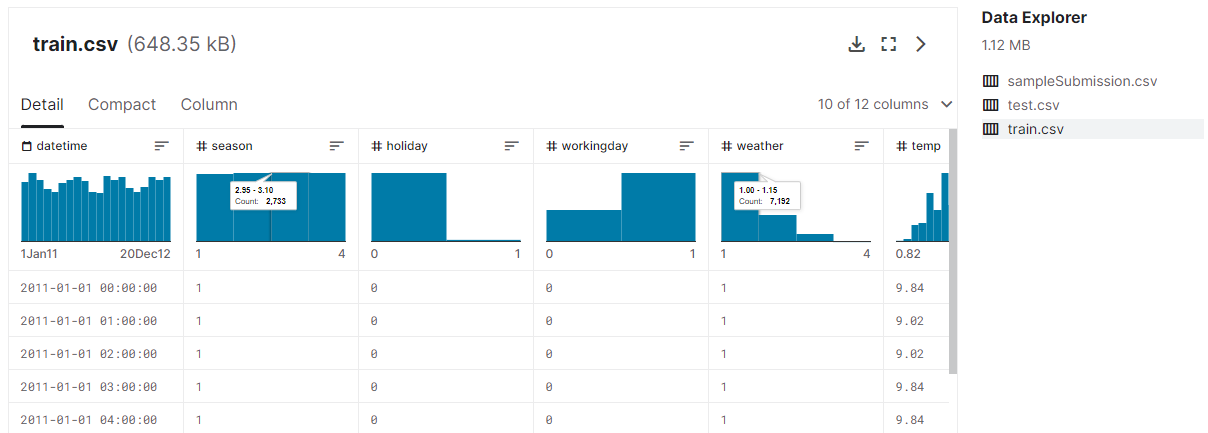
Data 메뉴 하단에는 Data Explorer라는 항목이 있는데, 이곳에서 데이터를 미리 살펴볼 수도 있다.
Data Explorer 메뉴
- 데이터 파일을 클릭하면 해당 데이터에 관한 정보를 표시해준다.
- [Detail] 탭에서는 피처별 분포도와 실제값을 볼 수있다.
- [Compact] 탭에서는 분포도 없이 실제값만 테이블 형태로 제공한다.
- [Column] 탭에서는 피처별 통계를 볼 수 있다.
추가적으로 Data Explorer 메뉴의 [Column] 탭의 화면을 자세히 보면,
Data Explorer 메뉴의 [Column] 탭
다음과 같이 왼쪽에는 값의 분포를 보여주는 막대 그래프가, 오른쪽에는 몇 가지 통계를 보여준다.
이 통계는 다시 두 영역으로 나뉜다.
Valid,Mismatched,Missing이 세 항목은 모든 feature의 공통 요소이다.
Valid와Mismatched는 해당 feature에 사전 정의된 값이 잘 들어가 있는지를 표시한다.
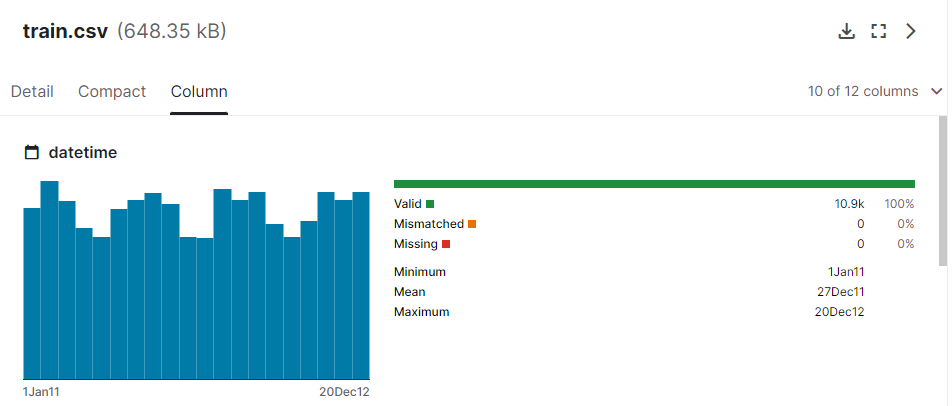
Valid는 사전 정의된 값으로 기록된 값의 비율을 표시Mismatched는 사전 정의된 값으로 매칭되지 않는 값을 비율을 표시
But, Kaggle에서는 사전 정의를 어떻게 했는지 그렇게 중요한 요소가 아니므로 이 두 갑(Valid, Mismatched)는 크게 신경쓰지 않아도 된다!
Missing: 결측값 비율
- 해당 featrue의 데이터 타입에 따라 다른 정보로 채워진다.
- 실수형 or 정수형 feature : 평균, 표준편차, 최솟값, 25%값, 중간값, 75%값, 최댓값도 보여준다.
- 범주형 feature : 고윳값 개수, 최빈값을 보여준다.
- 위 그림은 날짜(datetime)을 나타내는 타입이기 때문에 최솟값, 중앙값, 최댓값을 표시한다.
지금까지는 [Data] 메뉴 아래쪽의 [Data explorer] 기능을 알아보았다.
[Data Explorer]를 활용하면 시각화를 직접 해보지 않고도 어느 정도 수준까지는 데이터를 훑어볼 수 있다.
하지만, 처음 보는 데이터에서 원하는 정보를 자유롭게 뽑아보려면 직접 시각화해보는 연습이 필요하다 !!!
이에 따라 포스팅이 진행되면서 코드로 하나하나 시각화를 진행해볼 것!!!
Code 메뉴
[Code] 메뉴에서는 다른 참가자가 공유한 코드(노트북)을 볼 수 있다.
Code 메뉴
추천순(Most Votes) 혹은 점수순(Best Score)으로 정렬해 상위권 코드 위주로 참고하면 된다.
[All]탭에서는 본인을 포함한 모든 참가자가 공유한 코드를 볼 수 있다.
[Your Work]탭에서는 본인이 작성한 코드만 볼 수 있다.
코드를 만들 때, 공유 여보를
Private혹은Public으로 설정할 수 있다.
(Private으로 설정 시 나 자신만 볼 수 있고,Public으로 설정 시 다른 참가자도 볼 수 있다.)
코드를 Public으로 설정해 공유하면 캐글 규정에 따라 아파치 2.0 라이선스가 적용된다.
아파치 2.0 라이선스는 누구나 해당 소프트웨어에서 파생된 프로그램을 만들 수 있으며 저작권을 양도, 전송할 수 있는 라이선스 규정이다.
따라서 `[Code]메뉴에 공유된 다른 참가자의 코드는 자유롭게 사용할 수 있다.
Discussion 메뉴
Discussion 메뉴
경진대회에서 좋은 성적을 내기 위해서는 [Discussion] 메뉴도 잘 활용해야 한다.
새로 알게된 insight, 주의사항, 질의응답 등 경진대회에 도움되는 내용이 많이 올라오기 때문이다.
특히 경진대회가 끝나면 상위권 캐글러들이 자신의 문제해결 노하우를 공개한다.
추전순으로 정렬해 상위권 글을 쭉 읽어보는 것이 좋다!!!
Leaderboard 메뉴
Leaderboard 메뉴

[Leaderboard] 메뉴에서는 참가자의 등수와 점수를 확인할 수 있다.
각 행에 순위, 팀명, 팀원, 점수, 결과 제출 횟수(Entries), 최종 결과 제출 시기(Last), 공유한 코드순으로 표시되어 있다.
해당 팀이 코드를 Public으로 공개하지 않으면 Code 열에는 아무것도 표시되지 않는다.
자전거 수요 예측 경진대회의 리더보드는 특수한 형태를 갖는다.
그렇기 때문에 일반적인 리더보드를 기준으로 먼저 설명하겠다.
일반적인 경진대회 Leaderboard 메뉴
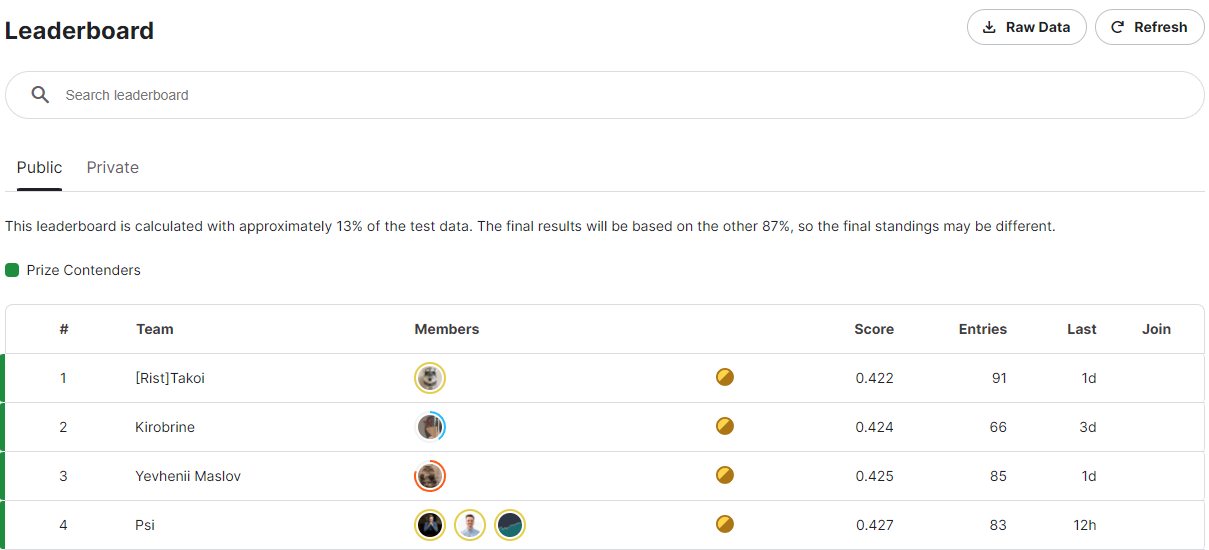
경진대회에서는 예측할 때, test data를 사용한다.
그런데 test data "전체"를 사용해 점수를 매기는 시기는 대회 종료 직후이다.
한편 대회 종료 전까지는 보통 "일부" test data만 사용해 점수를 매긴다.
이 점수는 "Public Leaderboard"에서 확인할 수 있다.
즉, Public Leaderboard는 대회 종료 전까지 대략적인 점수와 등수를 확인하는 곳이다.
대회 종료 후에는 test data 전체를 사용해 매긴 점수와 등수를 "Public Leaderboard"에서 확인할 수 있다.
최종적으로는
Private Leaderboard를 기준으로 메달과 상금을 수여한다.
대회 종료 전후 평가점수 산출에 사용되는 테스트 데이터 차이
출처 [캐글 안내서] ❸캐글러들은 머신러닝 딥러닝 문제를 어떻게 풀까?
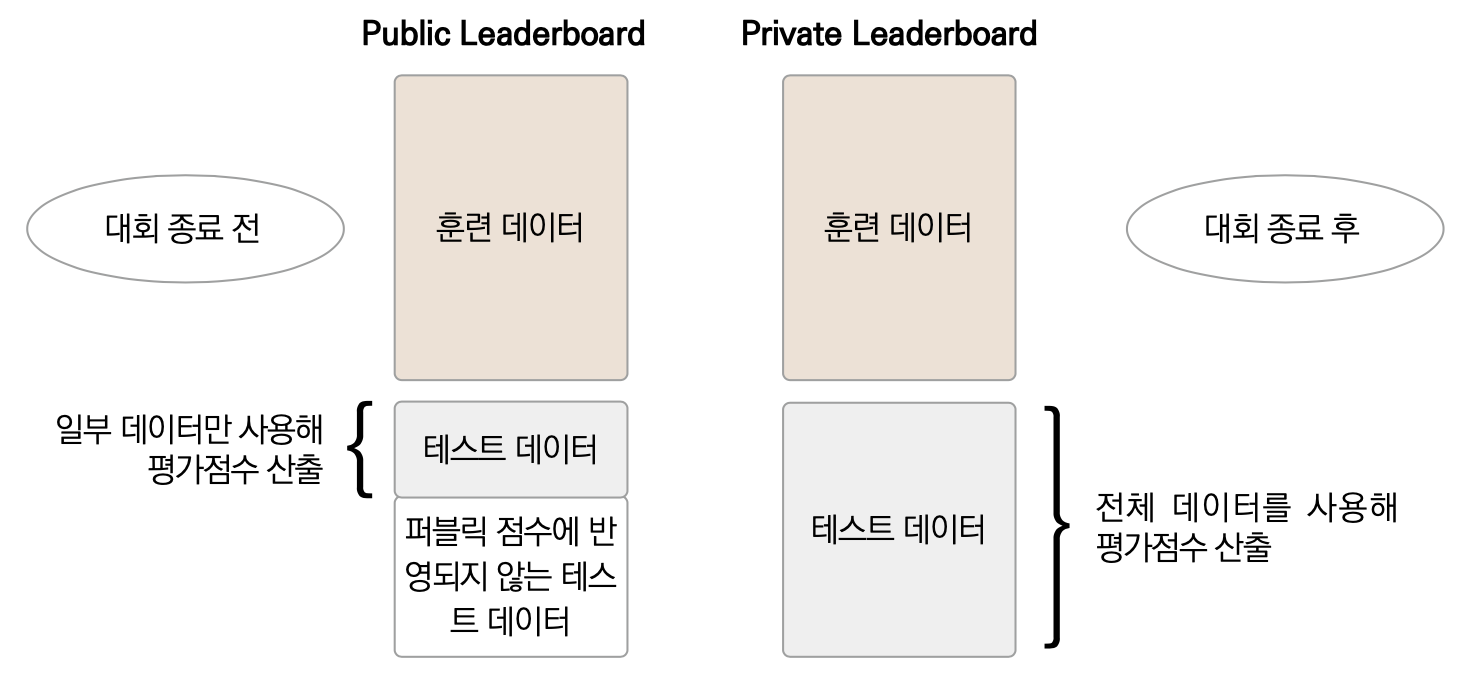
Public Leaderboard에서 등수가 높더라도, Private Leaderboard에서 등수가 떨어질수도 있고, 등수가 올라갈수도 있다.
두 리더보드의 등수 차이가 큰 경우가 많을 때 shake-up이 심하다고 한다.
shake-up이 심한 대회도 많기 때문에 Public Leaderboard에 집착할 필요는 없다!!!
다시 돌아와서, 자전거 수요 예측 경진대회는 둘의 차이가 없다.
Private Leaderboard와 Public Leaderboard 모두 test data 전체를 사용해 점수를 매겼기 때문이다.
그래서 Private Leaderboard와 Public Leaderboard메뉴가 나누어져 있지 않다.
이는 연습용 대회라서 그렇고, 극히 예외적인 경우이다.
Rules 메뉴
[Rules]메뉴에서는 대회 규정을 볼 수 있다.
대회에 참가하기 위해서는 규정에 동의해야 하며, 규정을 읽어보고 [I Understand and Accept]버튼을 클릭하면 된다.
이미 다른 메뉴에서 동의를 했다면 "You have accepted the rules for this competition. Good luck!"이라는 문구가 뜬다.
경진대회 Rules 메뉴
대회마다 규정은 다른데, 몇 가지만 주의하면 된다.
- Private Code를 팀원 외 다른 참가자와 공유하면 안 된다. 이를 걸리면 참가 자격이 박탈된다.
- 외부 데이터 사용이 불가능한 대회에서는 Kaggle에서 제공한 데이터만 사용해야 한다.
- 사전 훈련된(Pre-trained) 외부 모델 사용을 불허하는 대회에서는 본인이 훈련한 모델만 사용해야 한다.
하지 말라고 규정한 것은 하지 않고, 상식선에서 지킬 것만 잘 지키자!!!
Team 메뉴
[Team] 메뉴에서는 팀을 꾸밀 수 있다. 초대하고 싶은 팀이나 캐글러 이름을 입력한 뒤, [Request Merge]를 누르면 초대가 된다.
(대회에 이미 참가한 사람만 초대할 수 있다.)
초대받은 사람은 본인의 [Team] 메뉴에서 Join This Team을 클릭하면 수락이 된다.
Team Name에서 팀명을 지정하면 리더보드에서 해당 팀명으로 표시된다.
팀원은 최대 5명까지 꾸릴 수 있으며, 팀원 목록에서 초대된 팀원을 볼 수 있다.
Wrap Up
지금까지 Kaggle의 경진대회에 참가하고, 다양한 기능들에 대해서 알아보았다.
이제 다음 포스팅 부터는 본격적으로 자전거 수요 예측 경진대회의 탐색적 데이터 분석부터 시작할 예정이다.
기존에 DACON 플랫폼만 사용해보다가 이번에 인공지능 경진대회 조상급인 Kaggle을 사용해보니까 색달랐고, 앞으로 더 익숙해져야겠다고 생각했다.
