결정 트리
머신러닝 알고리즘 중 가장 직관적으로 이해하기 쉬운 알고리즘으로 데이터에 있는 규칙을 학습하여 찾아내 트리(Tree)기반의 분류 규칙을 만드는 것
쉽게 생각하면 스무고개 게임과 유사하여 if, else를 통해 규칙을 찾아내 데이터를 점진적으로 나누는 것으로 아래의 그림과 같다.
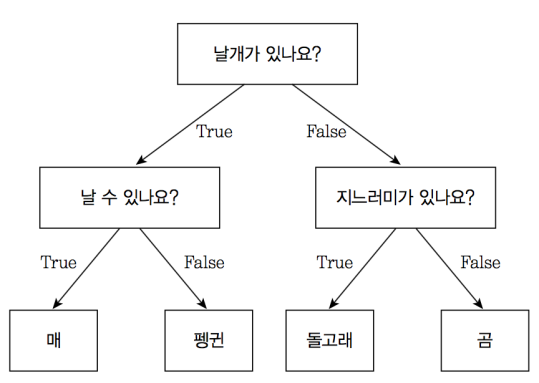
전체 데이터를 질문에 따라 나누어 최종적으로 더이상 나눌 수 없는 상태에 이르는 것이 결정 트리의 목적이다.
그림의 각 네모칸을 노드라고 칭하며 데이터를 나누는 노드 즉 위 그림의 질문에 해당하는 노드를 규칙 노드라고 하며 매, 펭귄, 돌고래, 곰에 해당하는 노드를 리프 노드(결정된 분류값)이라고 한다.
리프 노드를 더 세분화하려면 할 수 있지만(ex: 곰->반달 가슴곰, 불곰, 회색곰...) 규칙 노드가 추가되면 될 수록 분류 모델이 복잡해지며 이는 모델의 과적합으로 이어질 가능성이 높으며 결정트리의 예측 성능이 저하될 수 있다.
따라서 가능한 한 적은 결정노드로 높은 예측 정확도를 가지려면 데이터를 분류할 때 최대한 많은 데이터 세트가 해당 분류에 속할 수 있도록 결정 노드의 규칙이 정해져야한다.
분류가 잘 되었는지 판단하는 기준
위에서 말했듯이 최대한 적은 적은 개수의 규칙노드로 나누어진 데이터가 비슷한 종류의 데이터로 이루어지는 상태에서 균일도를 측정하기 위한 방법으로 엔트로피 기반의 정보 이득(Information Gain)과 지니 계수가 있다.
정보 이득: 주어진 데이터 집합의 혼잡도를 의미하는데 서로 다른 데이터가 섞여있으면 데이터의 엔트로피가 높고 같은 값이 섞여있으면 엔트로피가 낮다. 정보 이득 지수는 엔트로피 지수를 1에서 뺀 값이다. 즉 정보이득이 높은 속성을 기준으로 분할한다.
지니계수: 경제학세어 불평등 지수를 나타낼때 사용하는 계수로 0이 가장 평등하고 1이 가장 불평등하다. 머신러닝에 적용될 때는 지니 계수가 낮을 수록 균일도가 높은 것으로 해석한다.
결정 트리의 특징
장점
1)정보의 균일도를 기반으로 하고 있기 때문에 알고리즘이 쉽고 직관적이다
-어떤 규칙 노드와 리프 노드를 통해 만들어져 있는지
알 수 있기 때문에 이해하기 쉬우며 시각화를 통해 표현이 가능하다.
2)정보의 균일도만을 생각하면 되기 때문에 각 피처의 스케일링과 정규화 같은 전처리 작업이 필요 없다.
단점
1)과적합의 위험이 크기 때문에 모델의 정확도가 떨어질 수 있음
- 균일도를 높이기 위해 규칙 노드를 많이 만들면 만들 수록 모델이 복잡해지며 과적합의 위험이 크다.
